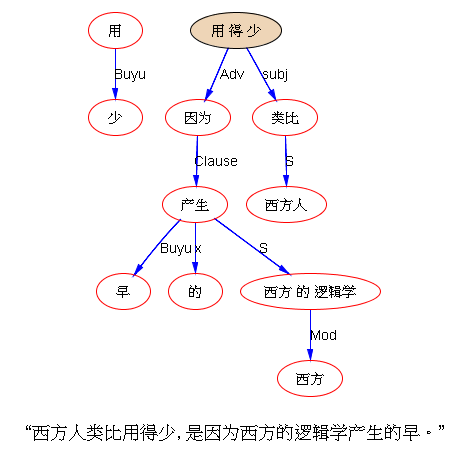
白: “西方人类比用得少,是因为西方的逻辑学产生的早。”
什么叫狗屎运?我的定义就是:
遇到一个找茬的顾客,看到他藏着陷阱的“自然语言”语句,心里有点没数,但测试自己的系统,一次通过了。
今天是个好日子,撞了一个狗屎运,不必 debug 了,因为此例就没有 bug。
当然,真是通不过,需要 debug 也没啥,所有的系统都不是一锤子买卖。只要这种 bug 是在你设计的框架内,有一个顺达的对症下药之路,而不是为了这个 bug,没完没了折腾系统。严格说,也可以找到瑕疵:理想的 parse 最好是对 “西方人” 耍个流氓,label 成 Topic,而不是 S,但这个 Topic 的流氓不见得比现在这个 parsing 强,半斤八两吧。现在的parsing 是把 “西方人类比”当成主语从句了。S 是主语,Subj 是主语从句。
对于半斤八两的句法分析路径 怎么判断对错?
一个包容的系统,就认可两者,因为其间的区别已经很 sutble 了,连人很多时候也糊涂。所谓包容的系统,指的是,在语用层面做产品需要语义落地的时候,parser 对此类现象给出的两个不同的路径,应该不影响落地。这个对于句法和语用 integrated 的系统,是没有问题的。后者可以也容易实现这种鲁棒性。对于汉语常见的 NP1+NP2+Pred 的现象,下列分析大都可以被包容:
(1) Topic + S + Pred
(2)[S + Pred] +Pred
when the second element can be Pred (V, A, or deverbal N)
(3) [Mod + S] Pred
包容的都是可以预见的,因为可以预见,因此可以应对,hence robustness
顺便做个广告,承蒙高博协助,立委 NLP (liweinlp)频道 再张大吉:
liweinlp.com