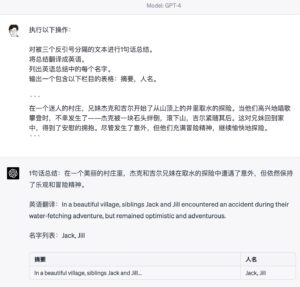
信息抽取
这条新闻讲的是美国共和党遭遇议长选举的闹剧和挑战。送进去,我让它给我抽取:(1) 实体;(2)引语;(3)关系;(4)事件;(5)情感分析。用的是大白话,这些以前都是 NLP 的专项任务,现在“zero shot”它,给个指令即可。



情感分析显示了其NLP的超能力。传统的 sentiment analysis 不过是一个正负二级分类。在这里不大合适,而它会把带有情绪的洞察(insights)抓出来,显得非常灵活精当。
自动摘要

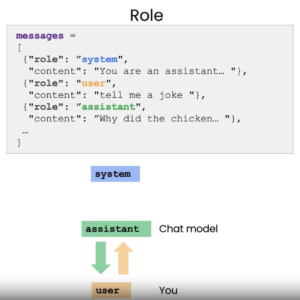
以上算是传统的NLP任务零样本测试。下面也看看其他文字类任务的表现,表现其NLP新能力。意想不到的能力发掘的根本原因是听懂了人话。在此之前,NLP 社区为了定义一个任务,需要耗费很多的精力去设计目标,准备数据和统一标注标准,组织社区竞赛。这就必然限定了任务的种类。现在每个人都可以尝试让它做各种任务,人民群众的创造力得到了极大的发挥。以前太多的死角,现在都可以去尝试。
推荐信
自从 chatGPT 横空出世,应用文辅助写作案例已经水漫金山,见奇不怪了。但这不改变辅助写作是一个具有巨大应用场景和价值的方向,虽然大概率与机器翻译也差不多,最后作为行业可能被做死,或成为白菜价。下面是我自己前一阵子做的一些试验,摘录如下。
请帮助我用规范的英文写一篇推荐信,内容包括:1. 推荐张三到清华做博士后,研究AGI;2. 我是张三的博士导师; 3. 张三博士论文获到全国优秀论文大奖。
Dear Admissions Committee, I am writing to highly recommend Zhang San for admission to your PhD program in AGI research at Tsinghua University. As Zhang San's doctoral advisor, I have had the pleasure of working with him for the past three years and have been consistently impressed by his intellectual curiosity and dedication to his research. His thesis on AGI has been recognized with the National Outstanding Thesis Award, a testament to the quality and originality of his work.
In addition to his impressive research abilities, Zhang San is a team player and has proven to be a valuable asset to our research group. He is able to work well with others and consistently contributes fresh ideas to our discussions. I am confident that he will thrive in a collaborative environment like your PhD program. I strongly believe that Zhang San would be an excellent fit for your program and would make a valuable addition to your community of researchers. I wholeheartedly endorse his application and hope that you will consider him for admission. Sincerely, [Your Name]
请增加一些具体生动的细节,让推荐信更为有力。
Dear Admissions Committee, I am writing to highly recommend Zhang San for admission to your PhD program in AGI research at Tsinghua University. As Zhang San's doctoral advisor, I have had the pleasure of working with him for the past three years and have been consistently impressed by his intellectual curiosity and dedication to his research. His thesis on AGI has been recognized with the National Outstanding Thesis Award, a testament to the quality and originality of his work. In particular, his contribution to the development of a novel AGI algorithm has garnered attention from researchers in the field and has the potential to significantly advance the state of the art. In addition to his impressive research abilities, Zhang San is a team player and has proven to be a valuable asset to our research group. He is able to work well with others and consistently contributes fresh ideas to our discussions. I have seen him take the lead on several collaborative projects, always ensuring that all team members are on the same page and making valuable contributions to the final product. I am confident that he will thrive in a collaborative environment like your PhD program.
I strongly believe that Zhang San would be an excellent fit for your program and would make a valuable addition to your community of researchers. I wholeheartedly endorse his application and hope that you will consider him for admission. Sincerely, [Your Name]
好了一些,但请增加下列事迹:1. 废寝忘食 他总是最后一个离开实验室;2. 发表了5篇一级刊物论文,成为青年学术新星;3. 虽然AGI被认为是难以实现目标,张三在定义AGI实现的不同步骤上提出了具有操作性的建议,并实现了10个步骤中的前5个。
Dear Admissions Committee, I am writing to highly recommend Zhang San for admission to your PhD program in AGI research at Tsinghua University. As Zhang San's doctoral advisor, I have had the pleasure of working with him for the past three years and have been consistently impressed by his intellectual curiosity and dedication to his research. His thesis on AGI has been recognized with the National Outstanding Thesis Award, a testament to the quality and originality of his work. In particular, his contribution to the development of a novel AGI algorithm has garnered attention from researchers in the field and has the potential to significantly advance the state of the art. Zhang San has also published five papers in top-tier journals, establishing himself as a rising star in the field of AGI research. Despite the challenges and setbacks that are inherent in AGI research, Zhang San has remained committed to his work and has often stayed in the lab long after everyone else has gone home. His dedication to his research has paid off, as he has already achieved significant progress in his work. In particular, he has proposed operational steps towards the realization of AGI, and has successfully implemented the first five steps of his proposed framework. In addition to his impressive research abilities, Zhang San is a team player and has proven to be a valuable asset to our research group. He is able to work well with others and consistently contributes fresh ideas to ......
中国教授头疼的为学生写推荐信问题,已经完美解决。只要你能列出零星哪怕是散乱的要点,机器就会给你拽成一篇看上去非常 professional 的规范推荐信。有没有问题? 当然可能有。例如明明是要求博士后推荐,它写成了 to your PhD program, 但关键是语言方面的困难都给你搞定了,只要通读一遍把个别词改正一下即可。
写段子

还行吧,这些段子水平不高。但比憋不出来强。
本来写出好段子就是最具挑战性的人类创作活动之一,只要采访几个著名的脱口秀演员就知道其中的甘苦了。很多大火的脱口秀演员,为此绞尽脑汁。台上五分钟,台下无数不眠夜。让人开口笑,并不容易啊。

wow,不知道这是抄袭的,还是“涌现”的,联想一下还真像是个搞笑的段子:
gou (go) 我不会飞,可我很快。
niu 所以我那么大(大妞儿?)
猫猫 miao 或 mao, 耗子 mou,也蛮形象,有声有色的样子。
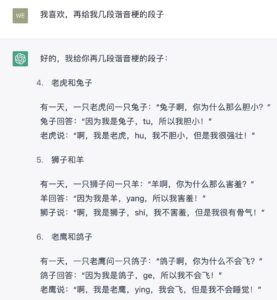
哈,看来只学会了一个套路:羊/yang (young),所以我害羞。
写情书


ChatGPT 写情书不重样。这是陷入爱河但苦于笨嘴拙舌的人的福音了。
人的爱意,哪怕有套话,也是要表达才行,藏在心里不行。“I love you” 是鹦鹉学舌完全可以做到的,但并不因为是套话而失去其神奇效应。无数的情感矛盾和关系恶化,其实就是缺少了这三个字的表达频度。
但热恋要求更高一点,需要营造浪漫。营造需要形式,而有的人就是不懂形式,不善言辞,不会表达(俗话说,不会来事儿 lol)。你便是真情如海,但羞于表达或表达不出来也没戏。谁愿意与木头谈一场恋爱?
有问,机器代写的情书能有真情吗?这就好比询问:毛笔写的情书能有真情吗?ChatGPT 不过就是个工具,就跟你用毛笔还是钢笔一样。这个工具见识过无数的情书。工具帮助你产生形式,至于真情表白还是虚情假意,那要看使用工具的人了。

顺着这个话题延伸一下,说说 chatGPT 作为文字助手的作用,尤其是对于不善言辞的人。
出口成章的人是少数。见过很多人在一些场合需要应景,却憋不出话来,十分窘迫。现在好了。不知道有没有办法把 ChatGPT 制成一个可以植入的东西,就不说老马说的脑机接口了,只要能让它成为一个隐藏的招之即来,但无人察觉的暗器,也许类似传说中的苹果眼镜,让它编制的应景台词,跟提词器似的,崩到眼镜上,我见人不见。那会是社恐人士多大的福音。
不同程度的社恐据报道是一个相当普遍的困扰,我自己也深受其害:人稍多就哑巴了,插不上话,却要硬着头皮应付。看社交场合如鱼得水的人,知道他们是胡喷,但人家给气氛啊,自己啥贡献也没有,成为社交累赘。有情商的的人,还要照顾你情绪,不时还要引一两句给你,带你玩的意思。ChatGPT 可以改变这一切,让笨嘴拙舌秒变伶牙俐齿,让只懂本行的老专家也能成为百科地保。
看到一条朋友圈信息: “ChatGPT是中庸主义者的福音,完美地让你泯然众人、符合社会的基本期待。ChatGPT不需要提升生产力(不需要empower人类的语言能力),只需中庸地鹦鹉学舌,帮助人类在其没有表达意愿的场景、完成表达的义务。”