《人工智能研究人员声称机器学习是炼金术》
在领英上分享
马修·赫松梅。2018年5月3日上午3时
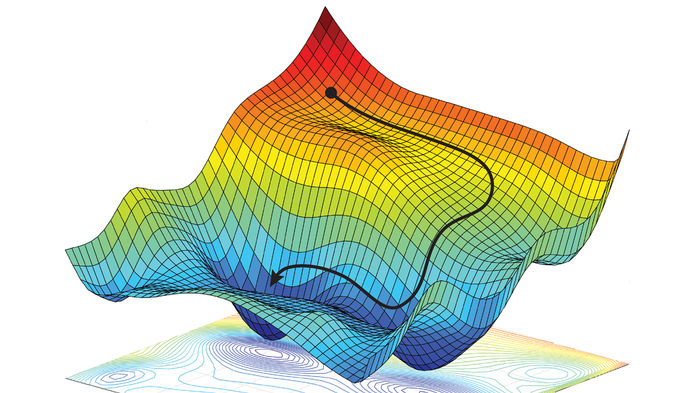
梯度下降依赖于试验和误差来优化算法,目标是3D场景中的最小值。亚历山大·阿米尼丹尼拉·鲁斯。麻省理工学院
Ali Rahimi是加州旧金山谷歌人工智能( AI )的研究人员,去年12月,他的研究领域受到了猛烈抨击,并获得了40秒钟的掌声。拉希米在AI会议上说,计算机通过反复试验学习的机器学习算法已经成为一种“炼金术”。他说,研究人员不知道为什么一些算法有效,而另一些算法无效,他们也没有严格的标准来选择一个人工智能体系结构而不是另一个。现在,在4月30日于加拿大温哥华举行的国际学术会议上,拉希米和他的合作者发表了一篇论文,记录了他们所看到的炼金术问题的例子,并提供了加强人工智能严谨性的处方。
拉希米说: “这是一个痛苦的领域。我们中的许多人都觉得我们在使用一种外星技术。”
这一问题与人工智能的再现性问题不同,后者由于实验和出版实践的不一致,研究人员无法相互复制结果。它也不同于机器学习中的“黑盒”或“可解释性”问题: 解释特定人工智能是如何得出结论的困难。正如Rahimi所说,“我试图区分机器学习系统是一个黑盒,而整个领域变成了一个黑盒。"
他说,如果不深入了解构建和培训新算法所需的基本工具,创建AIs的研究人员就像中世纪炼金术士一样,只能依靠道听途说。加州山景城Google的计算机科学家弗朗索瓦·乔莱特补充说: 人们被货物崇拜活动所吸引,依赖于“民间传说和魔法咒语”。例如,他说,他们采用pet方法来调整他们的AIs“学习率”——每次出错后一个算法能自我纠正多少——而不理解为什么一个算法比其他算法更好。在其他情况下,人工智能研究人员训练他们的算法只是在黑暗中跌跌撞撞。例如,它们实现所谓的“随机梯度下降”,以便优化算法的参数,以获得尽可能低的故障率。然而,尽管有数以千计的关于这一主题的学术论文,以及无数应用这一方法的方法,这一过程仍然依赖于反复试验。
rahimi的论文强调了可能导致的浪费精力和次优性能。例如,它指出,当其他研究人员从最先进的语言翻译算法中剔除了大部分复杂性时,它实际上更好、更有效地从英语翻译成德语或法语,这表明它的创造者并没有完全理解这些额外的部分对什么有好处。相反,伦敦Twitter的机器学习研究员费伦茨·胡塞尔说,有时候算法上附加的“铃铛和口哨”是唯一好的部分。他说,在某些情况下,算法的核心在技术上是有缺陷的,这意味着它的好结果“完全归功于应用在上面的其他技巧”。
rahimi为学习哪些算法最有效以及何时工作提供了一些建议。首先,他说,研究人员应该像翻译算法那样进行“消融研究”:一次删除一个算法的一部分,以查看每个组件的功能。他呼吁进行“切片分析”,其中详细分析算法的性能,以了解在某些领域的改进可能会在其他方面产生什么成本。他说,研究人员应该在许多不同的条件和设置下测试他们的算法,并且应该报告所有这些算法的性能。
加州大学伯克利分校的计算机科学家、拉希米炼金术主题演讲的合著者本·雷希特说,人工智能需要借用物理学的知识,在物理学中,研究人员经常把一个问题缩小为一个较小的“玩具问题”。他说:“物理学家在设计简单的实验来找出现象的解释方面很了不起。”。一些人工智能研究人员已经采取了这种方法,在处理大的彩色照片之前,对小的黑白手写字符的图像识别算法进行测试,以更好地理解算法的内在机理。
伦敦DeepMind公司的计算机科学家csaba szepesvari说,这个领域还需要减少对竞争性测试的重视。他说,目前,如果报告的算法超过了某个基准,发表论文的可能性要比论文揭示软件内部工作原理的可能性大。这就是花哨的翻译算法通过同行评审取得成功的原因。“科学的目的是创造知识,” 他说。“你想生产一些其他人可以接受和利用的东西。" "
不是每个人都同意拉希米和雷希特的批评。纽约Facebook首席人工智能科学家yann LeCun担心,把太多的精力从前沿技术转移到核心理解上,可能会减缓创新,阻碍人工智能在现实世界中的应用。“这不是炼金术,而是工程,” 他说。“工程总是凌乱的。"
雷希特认为这是一个有条不紊的冒险研究的地方。“我们都需要,”他说。“我们需要了解故障点在哪里,以便我们能够建立可靠的系统,我们必须开拓前沿,以便我们能够拥有更令人印象深刻的系统。"
张贴于:技术
搜狗MT(https://fanyi.sogou.com) 译自(translated from):
http://www.sciencemag.org/news/2018/05/ai-researchers-allege-machine-learning-alchemy?utm_source=sciencemagazine&utm_medium=facebook-text&utm_campaign=aialchemy-19247