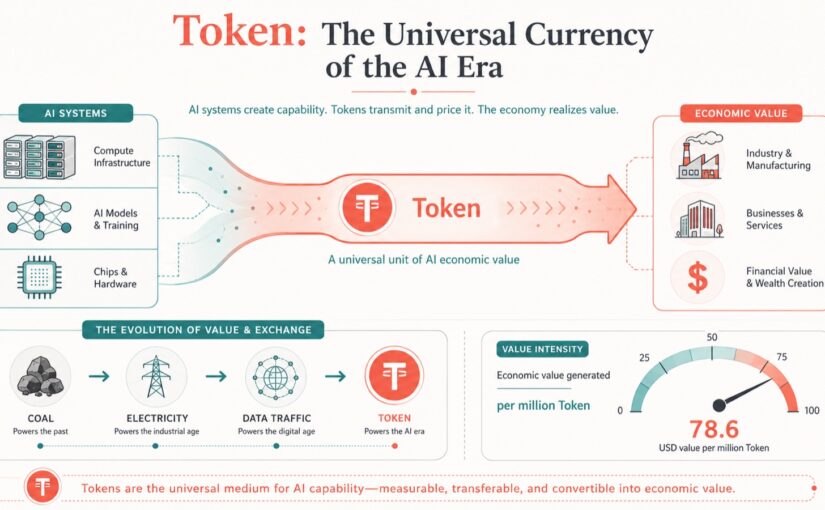
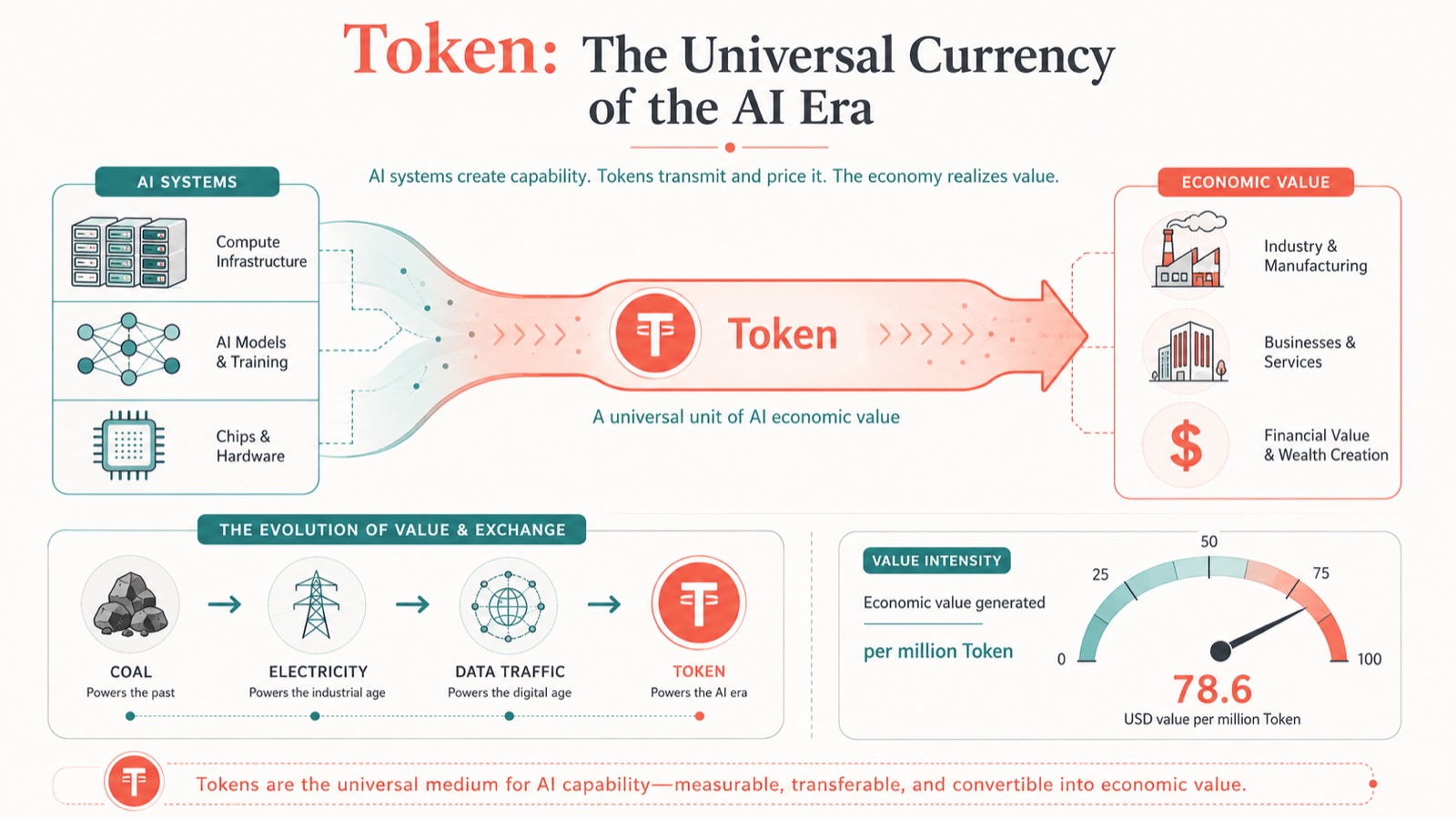
When I first entered Beijing's Esperanto circles back in the day, the freshness and warmth I felt left me — an outsider from the provinces — beside myself with excitement, and I threw myself into it with total devotion. Thirty years have passed, and my Esperanto land has seen many people and events intertwined with my NLP career.
Senior Sister: Crazy Esperanto

[Photo: Li Wei stands beside a burly senior brother, posing with the elegant senior sister (Yuanmingyuan, 1984)]
Seeing my junior brother popularizing Esperanto, I'll share a few tidbits for fun.
I can't remember the exact timing — probably the second semester of my first year in graduate school. One day, my junior brother, full of ambition, threw himself into learning Esperanto, declaring he would use it as an interlingua for machine translation and build the most standardized, most scientific, most rational MT system ever. Good junior brother — his word was his bond, and his actions followed through. From then on, every day he'd appear at the far end of the dormitory hallway at the crack of dawn, reciting Esperanto at the top of his lungs.
At first, our classmates were curious, approving, tolerant. Among graduate students, English speakers went without saying, and there were those who knew Japanese, French, German, Spanish — even Serbian and Urdu. But Esperanto, this was probably the junior brother's exclusive domain — one of a kind, no other branch. Before long, however, the classmates couldn't take it anymore. It turned out the junior brother threw himself into learning Esperanto with complete abandon, oblivious to everyone around him, bordering on mania. Whether it was early morning in the hazy dawn or high noon under the blazing sun, the moment he picked up his Esperanto book he'd start reciting aloud, with rising and falling intonation, utterly indifferent to how many classmates were still deep in slumber.
Years later, Beijing produced that "Crazy English" guru Li Yang. No matter how he hyped his "crazy" achievements, I was never impressed. Li Yang's "craziness" compared to my junior brother's was a minor witch before a major sorcerer — not worth mentioning. If one were to trace the inventor of the "Crazy Foreign Language Learning Method," my junior brother would undoubtedly be first, Li Yang a distant second at best.
But enough digression — back to the main story. As my junior brother kept bellowing Esperanto at the end of the hallway day after day, the neighboring students' repeated "protests" proved futile, and they had no choice but to come to me: "Get your junior brother under control — we really can't take this anymore." "What language is your junior brother even studying? We can't understand a single word — it's just unbearable." At first, I just smiled and had no intention of getting involved. No matter how authoritative a senior sister might be, she couldn't interfere with her junior brother's diligent study — those were the days when hard work and eagerness to learn were virtues. Besides, no matter how much he "shouted," it didn't affect the women's dorm upstairs.
Gradually, as I heard about it more and more, I too began to feel his diligent study was indeed a bit "crazy." One Sunday afternoon, a male student came to the women's dorm upstairs on business and ran into me in the hallway. As if seeing his savior, he hurriedly said: "Go check on your junior brother — he's made so-and-so furious, and he's cursing up a storm in his room right now." I went downstairs and heard the junior brother's ringing recitation. Walking further... "Lunatic! BAM—" from the tightly shut door of the room next to my junior brother's came a loud shout followed by the crash of something being thrown. No doubt — my junior brother's loud recitation had disturbed that person's long weekend siesta. Word had it that student suffered from chronic insomnia and had his days and nights reversed. The junior brother had disturbed his afternoon nap, so clearly this was serious.
Seeing me arrive, the junior brother invited me into his room — his roommate wasn't there. It seemed he'd extrapolated from that and assumed all the other rooms were empty too. I asked: "Was so-and-so cursing at you?" "What?" — his face was a picture of bewilderment. Well, he was completely oblivious. I decided not to meddle further — there are advantages to blissful ignorance. I merely hinted gently that he shouldn't recite aloud in the hallway anymore. He paused, then burst out laughing. I never figured out whether he understood or not.
Crazy studying brought crazy results. The junior brother's Esperanto progressed at breakneck speed, bearing abundant fruit. In about half a year he could use Esperanto fluently — not only serving as an interpreter for Huang Hua at the International Esperanto Congress, he also became a minor celebrity in Esperanto circles. In the machine translation world, I don't know if my junior brother was the only one using Esperanto as a translation framework. But his wild, passionate dedication to learning and loving Esperanto was surely one of a kind.
My First Esperanto Paper


[Photo: Mimeographed conference paper, later formally published in El Popola Ĉinio]
Going to Kunming in 1985 for the First National Esperanto Congress was the first long journey of my Esperanto voyage. Our group from Beijing chatted and laughed the whole way, as close as family. Among us was Elder Sister Qiu, the female singer known nationwide during the Cultural Revolution for "I Go to the Kitchen for the Revolution." Also in our group was Big Brother Wang Yanjing, a very handsome young man who was already a "veteran" Esperantist. He'd often brag to us that he was part of the Whampoa First Class — the glorious experience of over a hundred people receiving the first post-Cultural Revolution Esperanto training in the grand auditorium.
For this conference, under the guidance and support of my advisor Liu Yongquan, we specially submitted a paper for the scientific symposium organized by the congress. The paper reported on my brewing master's thesis topic — "One-to-Two Automatic Translation from Esperanto to English and Chinese" — and discussed the feasibility of using Esperanto as an interlingua for multilingual machine translation. Professor Liu was the father of Chinese machine translation; as early as the late 1950s he had brought back the spark of MT research from his studies in Russia. Professor Liu was also a member of the "Friends of Esperanto" association, and he was very encouraging and supportive of my decision to study Esperanto and use it for machine translation experiments. This Esperanto paper was later formally published in the beautifully printed Esperanto magazine El Popola Ĉinio, under the title "Babelo Estos Nepre Konstruita" (Liu, Y. and W. Li 1987. Babelo Estos Nepre Konstruita. El Popola Ĉinio.).
There was a time when machine translation was in its artisanal R&D phase — each language pair required manually developing two systems, one from A to B and one from B to A. As the number of language pairs grew, there arose a combinatorial explosion problem. How to achieve mutual translation among multiple languages thus became one of the classic topics in the MT field. Various explorations and proposals emerged, falling mainly into two categories: one was the so-called interlingua-based design approach; the other was the unification grammar approach.
The first approach sounded wonderful: if there existed a relatively neutral interlingua capable of expressing meaning, then each language would only need to build a translation system to and from the interlingua, and through it one could achieve translation between any language pair. This picture was so beautiful that the elder generation of MT evangelists never tired of extolling it. This in turn sparked all manner of debates and explorations regarding interlingua design and selection — some advocated designing an entirely new logic-based formal language (Japan, amid the so-called "Fifth Generation Computer" fever, once collaborated with China and other Asian nations to implement this approach); some advocated using or adapting Esperanto (the Dutch company BSO once attempted this, which drew me into its multilingual project); still others insisted that only a natural language (such as English, or simplified English) as interlingua was realistically viable.
The second approach — unification grammar — was also theoretically tantalizing. Its rise accompanied the advent of the new programming language Prolog: unification operations were a built-in feature of Prolog. Unification grammar aimed to eliminate the procedural nature embedded in traditional computational grammars for language analysis and generation. Under the banner of unification grammar emerged a series of grammar formalisms suffixed with "G" — such as GPSG and HPSG (my doctoral research was on bidirectional MT experiments within the HPSG framework). Because linguistic rules were no longer directional, the same grammar could serve both analysis and generation — whether the system performed analysis or generation was determined only when the grammar resources were invoked at runtime. In theory, translating from Language A to Language B versus Language B to Language A, once linguistic resources were unified, the engineering cost of system development was cut in half. For multilingual translation, the efficiency gains might not match the interlingua approach, but cutting labor in half was still enormously attractive.
Both approaches were traditional rule-based systems. Although both underwent considerable research and exploration, they ultimately failed to scale due to the limitations of handcrafted rule systems and never achieved major impact. What ultimately proved successful was the later deep neural network-based machine translation. The multilingual translation problem was thus transformed into an end-to-end resource problem of massive bilingual parallel corpora. With the same architecture and algorithm, one only needed to train the same bilingual corpus twice — once for each translation direction — to produce two MT models. Interestingly, in recent years there have also been approaches for language pairs lacking parallel data that take a detour through a resource-richer language as a pivot.
The Wang-Ai Sisters
[Photo: Top row: Elder Sister, Wang Ai, Li Wei. Bottom row: Teacher Wang Zhihuan, Japanese Esperantist Ms. Araki Miki]
At the time, we Beijing Esperantists had a stronghold — the home of the Wang-Ai sisters near the National Art Museum. Wang Ai had an eternally youthful baby face and seemed to be part of the Whampoa First Class too. The two sisters had classic northern Chinese personalities — warm, cheerful, good at organizing, widely connected, and full of humor. Going to their home felt as comfortable and natural as being in your own. The day an Esperanto art film was being screened, our whole group arranged to watch it at her place. When foreign Esperanto friends came to visit, we'd often take them to the Wang-Ai home for gatherings.
During the congress, a male Japanese Esperantist became quite close with us as well. It happened that my older brother came to Beijing at the time, so the two of us brothers joined Wang Ai in accompanying our Japanese friend on a visit to Yuanmingyuan, after which we gathered a bunch of Esperanto friends for a dinner party at Wang Ai's home — a lively, wonderful time.
[Photo: Ms. Rabin offstage after her performance]
What Wang Ai was proudest of was a candid shot she'd captured of Ms. Rabin after her performance during the Esperanto Congress. It was truly a photographic masterpiece — clean composition, vivid colors, the subject's expression astonishingly lifelike. No wonder the photo lab owner enlarged it and displayed it in the shop window as a sample to attract customers.
Love of Esperanto
After Dr. Zamenhof, the father of Esperanto, created the language, he didn't release it right away. Instead, he spent years conversing with himself and writing in Esperanto until it became second nature. When I first encountered Esperanto, it was love at first sight. A poem bears witness:
Al Nia Kara Lingvo
La lingvo gracia, kara mia,
Ĝis kiam vi venis al mi fine fin?
Atendis soife mi, eterne via,
MI AMAS VIN!Mi amas vin vere, pruvu Dio,
Kaj mia bon-koro batas nur por vi;
Ne plu sekreteto estas tio:
VIN AMAS MI!Ĉu kredas vi mian amon maran?
Ĉu kredas, ke mia koro flamas?
Ĉu kredas la vorton pure karan:
VIN MI AMAS!
This was a poem I wrote in 1986 — my Esperanto debut. Though naive, it was burning with sincere passion. Later, when I was doing machine translation experiments from Esperanto to English and Chinese, I simply fed it into my translation program, playing a little joke on "artificial intelligence," and even declared triumphantly in my thesis: Who says poetry can't be translated? Who says poetry can't be machine translated? Here is my master's system's automatic translation:
To Our Dear Language
The language graceful, my dear,
Till when you came to me at last?
Waited longingly I, ever yours,
I LOVE YOU!I love you truly, let God prove,
And my good heart beats only for you;
No longer that is a little secret:
I LOVE YOU!Do you believe my love like the sea?
Do you believe that my heart burns?
Do believe the word purely dear:
I LOVE YOU!
Young and reckless, what flowed were scorching words — unadorned, unsubtle — yet they captured the ecstatic state I was in when I first discovered Esperanto.
As a linguistics graduate student, I was captivated from the very beginning by Esperanto's linguistic features. The flexibility and diversity of Esperanto's modes of expression won me over completely. First was the freedom of word order: a simple accusative suffix -n granted total freedom to the subject-verb-object sequence. Mi amas vin ("I love you") could be expressed in six different ways! I marveled at this magic and drew poetic inspiration from it, using different word orders for rhyming. Many years later, I didn't forget to tell my daughter that Esperanto allows six combinations for saying "I love you." Every phone call with my daughter, before hanging up, she never forgets to say "I love you" in six languages — Chinese, English, French, Russian, Japanese, and Esperanto — always ending with Esperanto, rattling it off in one breath:
Mi amas vin. Mi vin amas. Vin mi amas. Vin amas mi. Amas mi vin. Amas vin mi.
What also amazed me was the freedom of word formation and the symmetrical beauty of the correlative table. I recorded these observations in my Esperanto notes, which eventually became material for my paper on the linguistic characteristics of Esperanto. Take the freedom of word formation, for example:
Ŝi rid-as. / Ŝi rid-etas. / Ŝi estas rid-ema. / Ŝi estas rid-emulo. / Ŝi estas rid-emulino (rid-emino). / Ŝi estas rid-emulineto (rid-emineto)……
She laughs. / She giggles. / She is laughter-prone. / She is a laughter-prone person. / She is a laughter-prone woman. / She is a laughter-prone little girl……
Esperanto's rich affixes and the agglutinative nature of its word formation give language users the greatest elasticity of form — one can almost shape words at will, deeply satisfying the creative urge. Esperanto's very nature encourages the "invention" of words. In actual use, of course, this flexibility manifests more as convenience in word creation rather than indulging creative desire. If I forget a specialized term, say komputero (computer), I can temporarily coin elektrona kalkulilo (electronic calculating tool — which could mean either a calculator or a computer) without hindering communication. Everyone who has used Esperanto has experienced this convenience and the joy of creation.
当年初入北京世界语圈子,感受到的新鲜和温暖,使我一个外地人兴奋莫名,遂以全部热情投入。三十年了,我的世界语国也经历了很多与我的NLP生涯交织在一起的人和事。
师姐:疯狂世界语
记不得确切的时间了,大约是研一的下学期。某日,师弟踌躇满志,拉开学习世界语的帷幕,宣称要用世界语作为机器翻译媒介语,打造最规范、最科学、最合理的机器翻译系统。好师弟,言必信,行必果。此后便天天一大早出现在宿舍的走廊尽头高声朗读世界语。刚开始,同学们还好奇、赞许、包容。研究生中会英语的自不必说,日语、法语、德语、西班牙语,以至于塞尔维亚语、乌尔都语也会者有之。独独这世界语大概是师弟"只此一家,别无分店"。然而,很快同学们便受不了了。原来师弟学习世界语尽情投入,旁若无人,几近疯狂。不论是清晨蒙蒙天亮,还是正午赤日炎炎,他只要拿起世界语便放声诵读,抑扬顿挫,全然不顾还有多少同学尚在睡梦之中。多少年后,北京出了个"疯狂英语"李扬,不论其怎么宣传"疯狂"业绩,我皆不以为然。李扬那个"疯狂"比起我师弟来,实在是小巫见大巫,不足挂齿。若要考证"疯狂外语学习法"的发明人,肯定是我师弟第一,李扬顶多第二。
闲话少说,言归正传。话说师弟每日在走廊尽头狂喊世界语,周邻的同学多次"抗议"无效,只得跑来找我:"管管你那个师弟,我们实在受不了了。""你师弟学的是什么语啊?我们一句也听不懂,简直让人受不了。"刚开始,我笑笑,并不打算管事。当师姐的再有威信也不能干涉师弟的勤奋学习啊,那年头可是以勤奋好学为美的,何况师弟不论如何"喊叫",并不影响楼上的女生宿舍。渐渐地,听得次数多了,我也感到师弟的勤奋好学确实有点"疯狂"。一个周日的下午,一位男生到楼上的女生宿舍有事,走廊里正好碰见我,好似看到救星一般,他忙说:"快去看看你那个师弟,把**气坏了,正在宿舍里大骂呢。"我走下楼梯,听见师弟那朗朗的读书声,再往前走……"神经病!咣——"师弟隔壁宿舍紧关着的门里伴随着高声的喊叫,传出了一声摔东西的声音。不用说,肯定是师弟的高声诵读打搅了那人周末长长的午休。据说,那同学长日失眠,昼夜颠倒。师弟打扰了人家的午休,可见问题煞是严重。见我到来,师弟把我请进了他的宿舍,他宿舍里没人。敢情他以此推论,以为其他宿舍也没人呢。我问:"**是不是骂你呢?""什么?"他一脸的迷惘。得,他浑然不觉呢,我也别再多事,懵懂自有懵懂的好处。我只是委婉地提醒他,以后别在走廊里高声朗读。他先是一愣,接着哈哈大笑。不知道他是明白了还是没明白。
疯狂的学习带来疯狂的收获。师弟学习世界语进步神速,硕果累累。大约半年后便能流利地使用世界语,不仅在国际世界语大会上给黄华做了翻译,还在世界语圈子里成为小小的名人。在机器翻译界,用世界语做翻译体系,不知道师弟是不是唯一的。但是,他那学习世界语,热爱世界语的疯狂劲头肯定是唯一的。
第一篇世界语论文
1985年去昆明开全国第一届世界语大会,是我的世界语之旅的第一次远行。我们北京一伙人,一路谈笑,亲如一家。同行有邱大姐,就是文革时唱过家喻户晓的"我为革命下厨房"的女歌手。同组还有老大哥王彦京,一个很英俊的小伙子,是"老"世界语者了,常跟我们吹嘘他是黄埔一期,当年在大礼堂上百人接受文革后第一批世界语培训的光荣经历。
为了这次会议,在导师刘涌泉指导支持下,我们专门提交了一篇论文,参加大会组织的科技研讨会。该论文汇报了酝酿中的硕士课题"世界语到英语和汉语的一对二自动翻译",并就世界语作为多语机器翻译媒介语方案的可行性提出了讨论。刘老师是中国机器翻译之父,早在上世纪50年代末就从俄国进修带回了机器翻译研究的火种。刘老师也是"世界语之友"会员,对于我决定学习研究世界语,并用它尝试机器翻译的想法非常鼓励支持。这篇世界语论文后来正式发表在印制精美的世界语杂志《中国报道》上,题目是"巴别通天塔必将建成"(Liu, Y. and W. Li 1987. Babelo Estos Nepre Konstruita. El Popola Chinio.)。
曾几何时,机器翻译处于手工业研发时期,每个语言对要手工开发两套系统,A 到 B 一套,B 到 A 一套,语言对一多就有一个组合爆炸的问题。如何实现多套语言之间的相互翻译于是成为机器翻译领域的经典话题之一。各种探索和方案都有提出,主要有两类:一类是所谓基于媒介语的设计思想;另一类是合一文法支持的方案。第一种方案很动听,因为如果有一种比较中性可以表达意义的媒介语,那么每个语言只要编制针对媒介语的互译系统,就可以通过媒介语实现任意语言对的翻译。这幅图画如此美妙,为老一辈机器翻译宣传家门所津津乐道。由此而来又引发了媒介语设计和选择的种种争论和探索。第二类合一文法的研究在理论上也很诱人,它的兴起伴随着新型计算机语言 Prolog的问世。在合一文法的大旗下出现过一系列以后缀G命名的文法形式化方案,如 GPSG,HPSG等。理论上,A 语言翻译为 B 语言,与 B 语言翻译为 A 语言,在语言资源归一以后,开发系统的工程耗费就节省了一半。这两类方案都是传统的基于规则的系统,虽然都做过相当程度的研究探索,但最终由于局限于手工规则系统难以规模化而没成大气候。最终修成正果的还是后起的深度神经网络为基础的机器翻译。多语翻译的问题因此转化为海量双语对照语料库的端到端资源问题。同一个架构和算法,原则上只需要同一个双语对照语料库对互译的两个方向训练两次即可生成两套机译模型。
王艾姐妹
当时我们北京世界语者有一个据点,就是美术馆附近王艾姐妹的家。王艾长着一张总也不老的娃娃脸,好像也是黄埔一期的。她姐妹俩典型北方人性格,为人热情爽朗,会张罗,结交广,富有幽默感。到她家,就跟到自己家一样感觉亲切自在。世界语文艺片播放那天,我们一拨人于是相约到她家看。遇到国外世界语朋友来访,我们也常常带到王艾家聚会。
大会期间,还有一位男的日本世界语者跟我们交往颇深。恰好赶上我哥哥来京,于是我兄弟俩和王艾一起陪同日本朋友逛圆明园,然后召集一批世界语朋友在王艾家晚餐聚会,热闹非凡。
王艾最得意的就是她抓拍了一张世界语大会期间拉宾小姐演出之余的照片。这的确是一幅摄影杰作,画面干净利索,色彩鲜艳,人物神态,栩栩如生。难怪照片洗印店的老板把照片放大摆放在门前作为招徕顾客的样榜。
世界语之恋
世界语之父柴门霍夫博士创造完世界语后,并没有马上发布,而是用世界语自己跟自己说话和著述了好多年,烂熟于心。我刚开始接触世界语,就一见钟情,有诗为证:
Al Nia Kara Lingvo
La lingvo gracia, kara mia,
Ĝis kiam vi venis al mi fine fin?
Atendis soife mi, eterne via,
MI AMAS VIN!Mi amas vin vere, pruvu Dio,
Kaj mia bon-koro batas nur por vi;
Ne plu sekreteto estas tio:
VIN AMAS MI!Ĉu kredas vi mian amon maran?
Ĉu kredas, ke mia koro flamas?
Ĉu kredas la vorton pure karan:
VIN MI AMAS!
这是我1986年写的诗,是我世界语的处女作。尽管幼稚,却是火热真情。我后来做世界语到英语汉语的机器翻译实验,索性把它送进我的翻译程序,跟"人工智能"开了个小玩笑,还振振有词地在论文中说:谁说诗歌不能翻译?谁说诗歌不能机器翻译?以下是我的硕士系统的自动翻译:
To Our Dear Language
The language graceful, my dear,
Till when you came to me at last?
Waited longingly I, ever yours,
I LOVE YOU!I love you truly, let God prove,
And my good heart beats only for you;
No longer that is a little secret:
I LOVE YOU!Do you believe my love like the sea?
Do you believe that my heart burns?
Do believe the word purely dear:
I LOVE YOU!
年少轻狂,流淌的都是滚烫的词句,不加掩饰,不知含蓄,但表现了我当年初识世界语那种欣喜若狂的状态。
作为语言学研究生,我一开始就被世界语的语言学特点迷住了。世界语表达方式的灵活多样让我折服。首先是语序的自由,一个简单的目的格后缀 -n, 主谓宾句式的语序就获得了完全的自由:mi amas vin (我爱你),可以有六种表达!我感叹其神奇,也获得了诗歌的灵感,于是用不同语序入韵。很多年以后,我没有忘记告诉我的女儿,世界语可以用6种组合说"我爱你"。每次跟女儿电话,挂电话前,她总不忘用六种语言说"我爱你"(汉/英/法/俄/日和世界语),最后总是以世界语结束,并且一口气说下去:
Mi amas vin. Mi vin amas. Vin mi amas. Vin amas mi. Amas mi vin. Amas vin mi.
让我惊奇的还有构词的自由性,和相关词表的对称美。我把这些写入我的世界语笔记,最终成为我的世界语语言学特点的论文素材。就说构词的自由性吧,比如:
Ŝi rid-as. / Ŝi rid-etas. / Ŝi estas rid-ema. / Ŝi estas rid-emulo. / Ŝi estas rid-emulino (rid-emino). / Ŝi estas rid-emulineto (rid-emineto)……
她笑。 / 她微笑。/ 她爱笑。/ 她是爱笑的人。/ 她是爱笑的女人。/ 她是爱笑的小女孩儿 ……。
世界语丰富的词缀和构词的黏合特性,从形式上给了语言使用者最大的弹性,几乎可以随心所欲,很能满足人的创造欲:世界语的本性是鼓励"生造词"的。当然,在实际使用中,这种弹性更多表现在给人以造词的便利,而不是满足创造欲。如果我忘记了一个专门词汇,比如 komputero(电脑),临时生造一个 elektrona kalkulilo (电子运算工具:可以指计算器或电脑),也不妨碍我的交流。每一个使用过世界语的,都体会过这种便利和创造的乐趣。
From 《朝华午拾》电子版目录. Original Chinese: 《朝华之十七: 我的世界语国》.












 全家包括外婆和老姨,以及邻居至友何妈妈小卉姐在家门前合影,1969
全家包括外婆和老姨,以及邻居至友何妈妈小卉姐在家门前合影,1969