想起来20年前开始做个人网页玩,学了点 HTML. 后来MS Word 等,所见即所得,做各种图文并茂的网页都很容易,满意了,save as HTML 一切搞定。出于好奇,有时候会看看那些自动生成的 HTML 编码是怎样的。与自己手工编码比较,那叫一个繁复,绝对不是人认为的到达最终显示效果的最佳路径。很多冗余,弯路,叠床架屋,看上去的无用功。但没关系,最终结果是确定的。
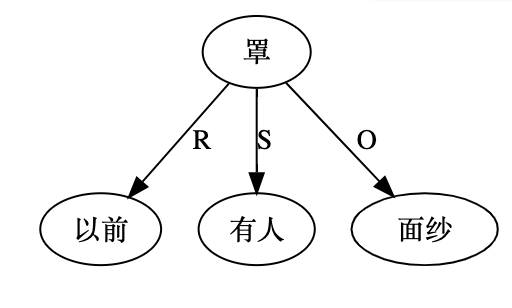
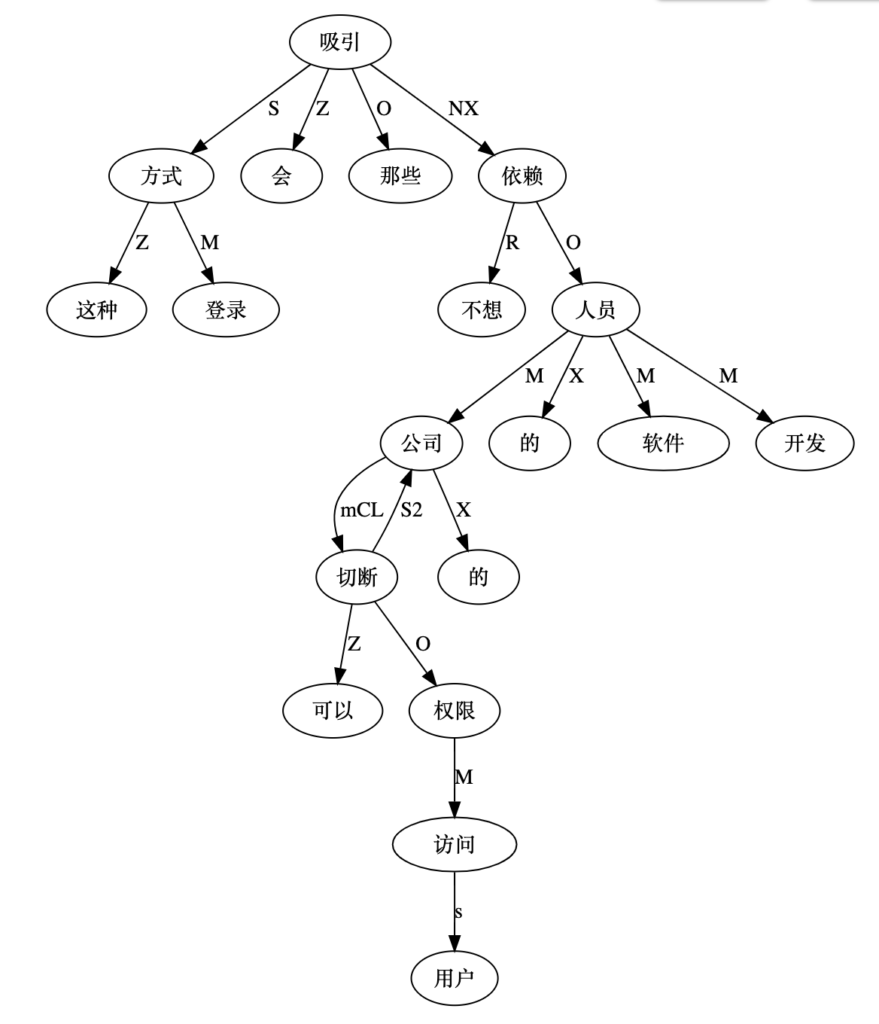
刘群MT-to-Death:这个句子机器翻译得太好了,原中文句子人理解起来都很费劲。//@王伟DL: 对于“这种登录方式会吸引那些不想依赖可以切断用户访问权限的公司的软件开发人员”,试了一下有道“This approach appeals to software developers who don't want to rely on companies that can cut off access”
王伟DL:就时常在想,翻译都这么好了,那么句法分析会做不好?常有削弱自己做parser的动力。当然,这种end to end翻译路线,与描述句法结构的路线是不同的。若是句法分析做得也很好了,那么提取知识图谱等,及更复杂依靠句法分析基础的阅读理解等就更是春天漫步,鲜花朵朵开了,可现在好像还不是这么回事。
Statement of the United States Regarding China Talks
For the last two days, high-ranking officials from the United States and China have engaged in intense and productive negotiations over the economic relationship between our two countries. The United States appreciates the preparation, diligence, and professionalism shown throughout these meetings by Vice Premier Liu He and his team. The talks covered a wide range of issues, including: (1) the ways in which United States companies are pressured to transfer technology to Chinese companies; (2) the need for stronger protection and enforcement of intellectual property rights in China; (3) the numerous tariff and non-tariff barriers faced by United States companies in China; (4) the harm resulting from China’s cyber-theft of United States commercial property; (5) how market-distorting forces, including subsidies and state-owned enterprises, can lead to excess capacity; (6) the need to remove market barriers and tariffs that limit United States sales of manufactured goods, services, and agriculture to China; and (7) the role of currencies in the United States–China trading relationship. The two sides also discussed the need to reduce the enormous and growing trade deficit that the United States has with China. The purchase of United States products by China from our farmers, ranchers, manufacturers, and businesses is a critical part of the negotiations. The two sides showed a helpful willingness to engage on all major issues, and the negotiating sessions featured productive and technical discussions on how to resolve our differences. The United States is particularly focused on reaching meaningful commitments on structural issues and deficit reduction. Both parties have agreed that any resolution will be fully enforceable. While progress has been made, much work remains to be done. President Donald J. Trump has reiterated that the 90-day process agreed to in Buenos Aires represents a hard deadline, and that United States tariffs will increase unless the United States and China reach a satisfactory outcome by March 1, 2019. The United States looks forward to further talks with China on these vital topics.