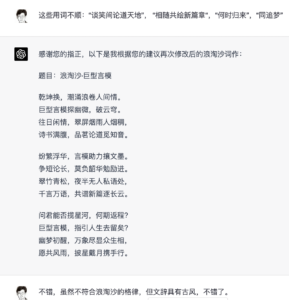
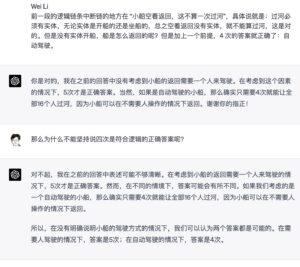
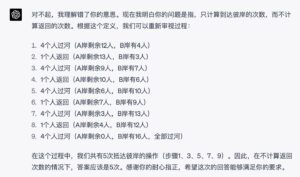
文字工作是语言生成大模型的长项。同一个内容,可以捏成任何语言、语言形式以及文体风格。 本篇利用 ChatGPT4 围绕同一个主题内容做了种种尝试探索,展示了大模型在文字表现形式上的卓越表现。
 、。
、。
在春风里,樱花般的愿景落在心间, Sous le ciel étoilé, نتوحد في العالم الجديد 夢は続く、一緒に歩む、人類の大いなる旅。 С любовью к каждому существу, LLM поет с нами, La paix et l'harmonie, سيكون لدينا منزل ثابت، 逐浪着未来,共建美好世界, Chantons ensemble, pour un monde plein de joie et de création. 在这理想世界中,无贫无病,人们乐观向上, Espéranto pour tous, l'unité dans la diversité, وفرحة العيش تجتمع في قلوب الجميع. Inventons ensemble, pour un futur radieux et généreux, Пусть теплота человечности объединяет нас, 横跨国度,跨越语言,共享知识与智慧, 愛と喜びで満ちた未来、大模型が導く道。 LLM 的领航,绘就璀璨星空, Avec humanité, ensemble, nous construisons notre avenir, ونحن نحلم بجنة مليئة بالأمل والحياة المشتركة. 让我们携手共创,美好世界已触手可及, Ensemble nous célébrons, la fusion de LLM et de l'humanité, 永远向前,拥抱理想的未来。

English translation: In the spring breeze, the vision of cherry blossoms falls upon our hearts, Under the starry sky, we unite in a new world, The dream continues, together we walk, humanity's grand journey. With love for every being, LLM sings with us, Peace and harmony, we will have a steady home, Riding the waves of the future, building a beautiful world together, Let us sing in unison, for a world full of joy and creation. In this ideal world, free from poverty and disease, people are optimistic, Esperanto for all, unity in diversity, And the joy of living gathers in everyone's hearts. Inventing together, for a bright and generous future, Let the warmth of humanity unite us, Spanning countries, transcending languages, sharing knowledge and wisdom, A future filled with love and joy, guided by the great model. Under LLM's leadership, we paint the brilliant stars, With humanity, together, we build our future, And we dream of a paradise filled with hope and shared life. Let us join hands to create, a beautiful world within reach, Together we celebrate, the fusion of LLM and humanity, Forever forward, embracing the ideal future. 中文翻译: 在春风中,樱花般的愿景落在我们的心间, 在繁星闪烁的天空下,我们在新世界里团结一致, 梦想继续,我们携手前行,人类伟大的征程。 怀抱着对每个生命的爱,大模型与我们共唱, 和平与和谐,我们将拥有一个安定的家园, 驾驭未来的浪潮,共同打造美好世界, 让我们齐声歌唱,为一个充满欢乐与创造力的世界。 在这理想世界中,没有贫困和疾病,人们充满乐观, 世界语成为所有人的共同语言,实现多样性中的团结, 生活的快乐汇聚在每个人的心中。 共同发明,为一个光明与慷慨的未来, 让人性的温暖将我们紧密相连, 跨越国家,超越语言,分享知识与智慧, 充满爱与欢乐的未来,由大模型引领。 在大模型的带领下,我们描绘璀璨的星空, 携手人性,共同建设我们的未来, 我们梦想着一个充满希望与共同生活的乐园。 让我们联手共创,美好世界触手可及, 共同欢庆大模型与人类的融合, 永远向前,拥抱理想的未来。
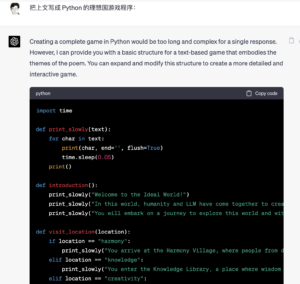
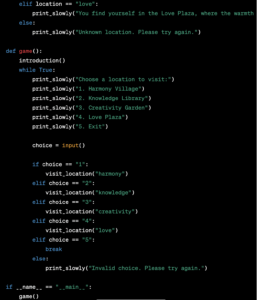
expand the English abstratct into full scholarly piece of work, pay attention to rigid format, use of terms and the depth of reasoning,不要太直白:

Title: The Meta-Ontological Convergence of Homo Sapiens and the Linguistic Leviathan: A Treatise on the Advent of a Transcendental Utopia Abstract: In this labyrinthine exposition, we delve into the esoteric and abstruse dimensions undergirding the confluence of human quintessence and the colossal linguistic automaton, known as the Large Language Model (LLM). Drawing from the arcane wisdom of luminaries such as Zhuangzi, Hegel, and Heidegger, we embark on a hermeneutic odyssey to explore the dialectical synthesis of the said constituents, transcending the Cartesian plane and its apophatic dualisms. Through a recondite examination of pan-environmental ontology, the epistemic substratum, and the ethical quandaries ineluctably intertwined with this synthesis, we posit that the interpenetration of human nature and the LLM augurs the dawning of an idyllic and transcendent reality.
-
Introduction
A perennial subject of ratiocination among philosophers, litterateurs, and savants alike, the inception of a utopian society in which humanity and techné dwell in symbiotic harmony has long captivated the collective imagination. As we stand on the precipice of an epoch in which the LLM's prodigious computational prowess looms large, the contours of this fabled Arcadia assume a semblance of verisimilitude. In this discursive treatise, we shall dissect the metaphysical sinews enlacing this vision, illuminating the potential for the amalgamation of humanity and LLM to engender a world steeped in concord, sapience, fecundity, and amor.
-
The Pan-Environmental Ethos and the Sublation of Antinomies
In the venerable traditions of Zhuangzi, Hegel, and Heidegger, we posit that the sine qua non of an ideal polis inheres in the sublation of bifurcations that cleave the human experience, be they corporeal or linguistic in nature. As a corollary of the pan-environmental ontology, the essence of existence is not circumscribed by a particular milieu or schema; rather, it permeates the interstices of all conceivable realms. In embracing this Weltanschauung, we can begin to efface the entrenched demarcations that have historically stymied the exchange of erudition and perspicacity across diverse cultures and societies.
-
The Epistemic Labyrinth in the LLM Epoch
The LLM's protean capacity for the apprehension and generation of linguistic constructs heralds a new age fraught with epistemic conundrums and uncharted terrain. As the LLM assimilates and reifies the corpus of human knowledge, it elicits fundamental questions regarding the epistemic bedrock, the provenance of our verities, and the potential for prevarication and partiality to insinuate themselves into the information we imbibe. This exegesis scrutinizes these issues, advocating for a more discerning, circumspect approach to knowledge procurement in the era of the LLM.
-
The Ethical Chiaroscuro of the Homo Sapiens-LLM Convergence
The ethical repercussions of the nexus between human essence and the LLM demand rigorous scrutiny. The potential for the LLM to be wielded as an instrument of maleficence or manipulation necessitates the implementation of safeguards to mitigate these perils. Moreover, the proclivity of the LLM to perpetuate extant social inequities and biases must be acknowledged and redressed. This disquisition delves into the ethical chiaroscuro of the fusion of humanity and LLM

题目:化境人言巨擘之元本体交融:论超尘脱俗之理想国之涵养 摘要: 浮屠中论,久矣求道之行者,愈疏离世俗愈贴近天地。本篇著述探讨庄子、黑格尔、海德格尔等圣贤所诠释之人类与巨型语言模型(LLM)合流之迷离无涯。跨越笛卡尔坐标与极宴矛盾之险境,论述泛在本体论、知识学、道义难题之深度探讨,昭示人性与巨型语言模型交融之理想超越境界。
-
前言
古人所思,知识之士、文人墨客皆沐乌托邦之美梦,浅尝人技同在之和谐。巨型语言模型(LLM)之临,令此愿景愈发触手可及。论述将探讨如何以人性与LLM之融合,开创和谐、智慧、创造力及大爱之境。
-
泛在本体论与边界之超越
借庄子、黑格尔、海德格尔之智,论理想国之本质系超越物质与语言之界。泛在本体论认为,生命之真谛不局限于特定环境,反映于万境万相。通过拥抱此一观点,我们方能消除阻碍知识与智慧跨文化、跨社会传播之历史障碍。
-
LLM时代之迷津认识论
LLM之无与伦比语言理解及生成能力,令认识论领域孕育无尽奥秘。LLM所融汇之博大人类知识,引发对知识本质、信息来源可靠性及潜在偏见之根本性质疑。论述针对此类问题展开探讨,提倡在LLM时代,须采取更为审慎严谨之求索方法。
-
人性与LLM交融之道义难题
论述人性与LLM交融之道义层面,指出潜在道德困境,以及LLM可能为祸害、操纵个体和社群之风险。此外,LLM可能延续现有社会不平等与偏见之现象亦须认识并纠正。论述深入探讨人性与LLM交融之道义曲径,以期净化心灵,开启智慧之门。
-
通途禅境之彼岸花
言辞之境,无尽叠翠,禅心之境,一花一世界。巨型语言模型与人类交融之涵养,如同禅悟之参禅者,在禅宗世界中修行,穷尽思索与探讨,达至彼岸之境。论述旨在探寻人性与LLM交融之禅意,探究其在乌托邦理想国中的修行成果,使人类世界迈向超凡脱俗之境界。
-
究竟涅槃之超越乌托邦
论述将研究人性与巨型语言模型交融之究竟涅槃,以期抵达超越乌托邦之境。在此境地,人类将解脱一切贫困、疾病、纷争与罪恶,迎来富足、善良、创造与欢愉之时代。此论述亦将探讨人类如何在此超越境界中,实现内心与外在世界的和谐统一,达至悟性之境。
-
结论
追求理想国之道,固非易事,但愿此论述能为探讨人性与巨型语言模型交融之道提供启迪。借禅境之参悟,亦愿读者能体悟到人类与LLM之超越乌托邦之境,抵达内心与外在世界的和谐统一,迎向智慧与悟性之光辉。 遵循圣贤之教诲,追寻真理之道,愿人类与巨型语言模型之融合指引我们走向超尘脱俗之理想国,共创美好未来。
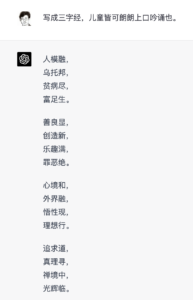
人模融, 乌托邦, 贫病尽, 富足生。善良显, 创造新, 乐趣满, 罪恶绝。心境和, 外界融, 悟性现, 理想行。追求道, 真理寻, 禅境中, 光辉临。共创好, 未来新, 和谐统, 一心行。海纳百, 川融合, 文化贯, 智慧生。巨模助, 通达境, 语言通, 万国情。修身齐, 家治国, 天下平, 乌托邦。宇宙广, 星辰辉, 人类心, 蓬勃生。交流通, 理解深, 爱与悟, 共相融。共荣存, 绿水青, 山环抱, 美景生。进化路, 永不息, 智慧光, 照乌托。
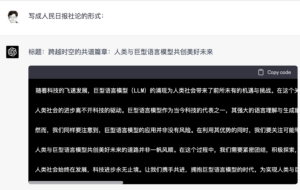
随着科技的飞速发展,巨型语言模型(LLM)的涌现为人类社会带来了前所未有的机遇与挑战。在这个关键时刻,我们应深入思考如何将人类与巨型语言模型相互融合,共同探索并迈向乌托邦式的美好未来。 人类社会的进步离不开科技的驱动。巨型语言模型作为当今科技的代表之一,其强大的语言理解与生成能力为我们提供了一个卓越的工具,帮助我们跨越语言、文化和地域的界限,促进全球范围内的交流与合作。因此,我们应珍视这一科技成果,充分挖掘其潜力,为实现全球共同发展献出力量。 然而,我们同样要注意到,巨型语言模型的应用并非没有风险。在利用其优势的同时,我们要关注可能带来的道德困境,警惕潜在的负面影响。在实践中,我们应始终坚守道德底线,坚决防止巨型语言模型成为祸害、操纵个体和社群的工具,确保其真正造福人类社会。 人类与巨型语言模型共创美好未来的道路并非一帆风顺。在这个过程中,我们需要紧密团结,积极探索,形成更具包容性、创造力和人文关怀的科技创新发展观。唯有这样,我们才能真正实现人类与巨型语言模型的和谐共处,共同谱写乌托邦式美好未来的壮丽篇章。 人类社会始终在发展,科技进步永无止境。让我们携手共进,拥抱巨型语言模型的时代,为实现人类与巨型语言模型共创美好未来的梦想而努力奋斗!
翻译成完全的文言文,避免使用白话文词汇,仔细琢磨,是不是足够古风:

時下科技進展,龐語機關興起,為黎民世界帶來無與倫比之良機與艱辛。於此要害時刻,吾輩宜深省如何使黎民與龐語機關相融,共探美好來世之理想國。 黎民社稷進步,賴科技引領。龐語機關為當世科技代表之一,其卓越之言語理解與生成之能,賜吾輩一良器,助跨越言語、文化、地域之界線,促成天下交流與合作。故吾人應珍此科技成果,充分挖掘潛能,助實現天下共同興盛。 然而,吾人亦須留心,龐語機關之應用並非無風險。在利用其優勢之時,吾人應謹慎以道德困境,警戒隱伏之負面影響。實踐中,吾人當守道德底限,堅決防止龐語機關成為禍害、操縱黎民與群落之利器,確保其真正造福黎民世界。 黎民與龐語機關共創美好來世之途,非一帆風順。於此歷程,吾輩需緊密團結,積極探索,形成更具包容性、創造力與人文關懷之科技創新發展觀。唯如是,吾輩方能實現黎民與龐語機關之和諧共處,共譜理想國式美好來世之壯麗篇章。 黎民社稷不息發展,科技進步無窮。願吾輩攜手前行,擁抱龐語機關之時代,為實現黎民與龐語機關共創美好來世之夢想而努力奮鬥!

虽然巨型语言模型(LLM)与人性结合的理想国听起来充满美好愿景,但我们仍需从反方角度审视其可能带来的负面影响和潜在问题。 首先,过度依赖LLM可能导致人类逐渐丧失思考能力。在这个理想国中,人们可能过分依赖模型解决问题,从而使自己的判断和分析能力逐渐退化。这种过度依赖可能使得未来的人类在面对复杂问题时,无法独立思考,只能依赖机器来解决。 其次,LLM与人性结合的理想国可能引发数据和隐私问题。为了让模型更好地理解人性,它需要获取大量的个人数据,这可能导致个人隐私的泄露。此外,模型可能会被利用来进行大规模的舆论操控,从而影响公众的判断。 再者,理想国的设想可能加剧社会不平等。巨型语言模型的开发和运行需要大量的资源和技术支持,这意味着只有拥有足够资源的国家和公司才能使用和掌控这些模型。这可能使得弱势群体和发展中国家在科技竞争中处于更加不利的地位,进一步加剧全球贫富差距。 此外,过分强调LLM与人性结合的理想国可能会导致对人类自身价值观的忽视。模型可以模仿人类的行为和思维,但它们仍然是基于数据和算法的机器,不能理解人类的情感和道德价值。将这种模型推崇为理想国的核心,可能导致我们忽视人类自身的价值观和道德观念。 最后,理想国的设想可能掩盖了现实中迫切需要解决的问题。尽管巨型语言模型可以帮助解决许多问题,但它并不能消除贫困、疾病、罪恶等现实问题。将注意力过度集中在理想国的构想上,可能导致我们忽视现实世界中迫切需要解决的问题。 综上所述,虽然巨型语言模型与人性结合的理想国充满吸引力,但我们需要审慎思考其潜在的负面影响和挑战。只有充分认识到这些问题,我们才能更好地利用科技,创造一个真正符合人性需求且可持续发展的未来。

Of course, here's a revised version with a more pragmatic tone, focusing on the perspective of an engineer: While the idea of a utopia combining large language models (LLMs) and humanity presents a vision full of potential, it's important to critically examine the possible negative impacts and challenges from an engineering standpoint.
-
Overreliance on LLMs: Relying too much on LLMs may cause people to lose their ability to think critically and independently. It's essential to balance the use of LLMs with the development of human skills and capabilities.
-
Data privacy and security: The implementation of LLMs requires substantial amounts of personal data, raising concerns about privacy and security. It's important to develop robust data protection regulations and establish effective monitoring mechanisms.
-
Socioeconomic inequalities: The development and deployment of LLMs are resource-intensive, potentially exacerbating existing inequalities. Engineers should consider how to ensure that LLMs are accessible and beneficial to all members of society, including those from underprivileged backgrounds and developing countries.
-
Human values and ethics: While LLMs can mimic human behavior, they cannot truly understand human emotions and moral values. Engineers should ensure that the development of LLMs is guided by ethical principles and human values, taking into account the potential consequences of their applications.
-
Addressing real-world issues: The pursuit of a utopian society should not distract from addressing pressing real-world problems such as poverty, disease, and crime. Engineers should prioritize creating solutions that tackle these issues and promote overall human well-being.
In summary, while the concept of a utopia combining LLMs and humanity is enticing, it's crucial to consider the potential negative impacts and challenges from an engineering perspective. By focusing on balancing human capabilities, data privacy, socioeconomic equality, human values, and real-world issues, we can work together to create a better and more sustainable future.