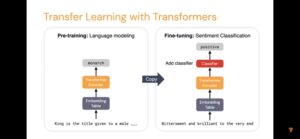
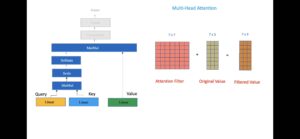
谢谢小编整理成文字,我也做了认真校订与补充(尤其是冷启动低代码部分)。
https://mp.weixin.qq.com/s/UHcVXvXlRYajcYgG6cV8rw
分享嘉宾:李维博士 NLP scientist
编辑整理:陈昱彤 纽约大学
出品平台:DataFunTalk
导读:NLP (自然语言处理) 技术的深入发展主要有两条路线,第一个是基于符号规则的深度解析模型,第二个是基于神经的深度学习预训练模型。今天分享的内容是从领域落地的角度,对上述两条路线进行介绍和对比。首先,从人工智能的历史和发展现状来谈谈两种不同方法的异同及其互补作用。值得注意的是,两种方法殊途同归,基础模型及其架构也越来越趋向于平行和一致:都是多层架构、数据驱动,赋能下游NLP落地。最后我们会强调当前领域内的低代码趋势,并介绍金融领域深度解析路线落地应用场景的相关实践。
今天的介绍主要围绕下面四点展开:
NLP历史和现状
殊途同归的符号与神经
低代码是趋势,也是王道
NLP“半自动驾驶”实践
01
NLP历史和现状
1. NLP近代史
人工智能是从符号AI(Symbolic)开始发展的,最初的NLP是基于符号规则的系统。过去30来年,机器学习经历了两次主要浪潮,第一次是从30年前开始的以统计为基础的传统机器学习模型的兴起,第二次是约10年前开始的深度学习革命。深度学习的一声炮响送来了监督学习的杀手级武器,横扫了感知智能各个方向,从图像到语音等AI落地领域。目前的研究热点转向以NLP为中心的认知智能模型。深度学习在NLP中的一个典型成功案例就是神经机器翻译,在源源不断的人工翻译语料库的驱动下,神经机器翻译的精度基本达到人类翻译的专家水平了。与主流机器学习一波又一波的热潮相对照,符号规则系统早已退出了学术界主流舞台,但符号AI模型和NLP规则系统却从来没有退出过工业界的实际应用。
2. NLP之痛:领域落地的知识瓶颈
NLP最大的痛点一直是领域落地必须面对的知识瓶颈,这在两个道路上有着不同的具体表现:
① 监督学习(特别是深度学习)需要大量带标数据
无论是什么领域的监督学习落地都需要大量带标签的数据来训练模型,但是领域场景中常常只有大量原生数据,而缺乏带标数据。深度学习迄今无法规模化落地各个领域,其瓶颈就在于需要大量的手工标注数据,而且一旦任务有所变化,那么之前的标注难以复用,标注必须重新来过。当然,这些相对简单重复的数据工作所需要的标注人员门槛较低,属于低级劳动。
② 符号模型需要高质量手工规则代码
符号模型的NLP落地需要根据不同任务,人工地编写相应的代码。虽然手写代码不像数据标注一样需要大量的劳动,而是技术人才的少量高级劳动,但马克思的劳动价值理论告诉我们,少量的高级劳动和大量的低级劳动是等价的。无论把知识体现在海量标注数据中还是直接凝聚转化为知识规则,重要的是,两条路线都面对NLP落地的知识瓶颈。
Image
3. NLP的现状
① 突破的曙光
令人欣慰的是,我们已经看到了突破瓶颈的曙光。在深度学习方面,近几年非常热门的解决方案是预训练的自主学习模型。预训练模型的最大特点是它不依赖标注数据,它是从源源不断的原生数据(raw data)学习来构建超大规模的基础模型。作为上游的预训练模型可以支持下游的各种不同的NLP任务,这就大大减轻了下游NLP任务对标注数据的要求。预训练大模型在学术界上取得了突破性的进展,很多NLP任务赛道的数据质量被刷新,但目前基本上还局限在研究界。工业应用上要将预训练模型落地到各个细分领域并且实现规模化普及,还有不少挑战,估计至少有五到十年的路要走。
另一方面,深度解析赋能NLP落地的符号模型也取得突破性进展,工业应用之路已经完全打通了。架构上,我们第一步用深度解析器(Deep parser)去消化语言,解析器可以将任何一个领域的非结构化文本转化为结构化的数据。第⼆步是在结构化的基础上做下游的自然语言任务,其实就是一种结构映射工作,把语言解析的逻辑结构映射到下游领域落地的任务结构上去。上层的解析器做得很厚,要做几十层模块来应对语言的千变万化,但下游的模型只需要做得很薄,两三层就可以解决问题。预训练模型和深度解析器的功能差不多,虽然表示手段不同,但都是对于自然语言现象的不同层次模式的捕捉。深度解析的下游NLP落地大致相当于深度学习下游的输出层(Output layer)。
Image
② Deep parsing 是符号NLP应用的核武器
为什么说 Deep parsing 是符号 NLP 应用的核武器呢?因为人类语言无论如何千变万化,其中必然隐藏着相同的逻辑结构。深度解析几十年的实践表明我们可以先把语言进行消化,解码(decode)出不同表达背后的逻辑结构(logical form)。比如下图示例中同一事件的各种表述,在解析消化之后表示为相同的逻辑主谓宾(SVO)结构:“Apple(S), release(V),iphone2.0(O)”。有了逻辑结构后我们就能以低代码开发领域落地映射的规则,以一当百地将这类结构用于不同目标上,而不需要在NLP应用层面去应对千变万化的语言表层变体。因此,NLP 应用场景的落地就能快速实现。
Image
02
殊途同归的符号与神经
1. 架构上的殊途同归
从AI历史发展趋势看,符号和神经是殊途同归的。创新方面也有惊人的平行性和相似性。
符号派走的是理性主义的路线,而神经网络和统计模型是属于经验主义的。本来理性主义的符号是排斥自底而上数据驱动的,但多年实践下来发现,在实际应用当中排斥数据驱动的理性主义方法往往捉襟见肘,可以在实验室做个玩具系统,却很难规模化实施。所以,我们在工业应用道路上深耕多年的符号践行者,实际上拥抱经验主义的做法,特别是数据驱动。符号主义走出实验室,在应用中落地开花的创新,与对数据的拥抱是分不开的。这种借鉴了经验主义方法论的符号路线还是保留了符号固有的一些优异特性,为符号主义的生存发展以及对于主流神经模型的补足提供了价值基础。
具体说来,符号是人类智慧和知识的载体,因为人类的思维以及知识积淀都是以符号及其逻辑的形式承载的(人类语言就是最大的符号)。所谓符号主义AI,实质是把符号表达方式在模型化的过程中贯彻到底,从符号规则系统的内部表示看,就是一种带有符号节点的图表示(graph),结构图中的关系表示也是符号化的,譬如句法树。这样的符号表示,好处是透明化和可解释性,软件的开发维护可以做到定点纠错。符号模型的开发也不需要依赖标注数据。这些优异特性是符号主义真正的价值所在。
神经模型就不⼀样了,它有“符号不耐症”。神经模型的两端(end-to-end)当然是符号,这没有办法,因为任何神经模型都是要给人用的,需要对用户和开发者友好,两端的接口上,它自然绕不开符号。但神经系统内部必须首先使用独热编码(one-hot encoding)、词嵌入(word embedding)等方法把符号转换为向量,才能实现模型内部的计算性。现在的潮流是使用预训练通过模型内部的各种向量来计算表示符号序列中隐含的不同层次的模式。然后下游的NLP落地任务一以贯之,同样是对这些人类看不懂的内部向量表示(所谓 tensor)进行监督计算,最终映射到输出层的符号。
Image
从架构及其内部数据流走向来看,这两种模型其实是非常相似的(见上图)。不同的地方是符号模型里面是结构化的符号,表示信息的数据流是 graphs。而深度模型里面长长的隐藏层全部是向量,数据流是 tensors。值得指出的是,符号模型也是需要用多层的符号模块一层一层匹配,更新内部结构才能取得好的效果。经典教科书中介绍的乔姆斯基风格的上下文无关文法(context free grammar)所对应的模型却是单层解析器(典型的实现算法是chart-parsing),就很难走出实验室。这就好像⼀开始陷在单层陷阱里面的神经网络一样,单层模型是很难捕捉自然语言的多样性的。这样看来,符号模型的多层创新和神经网络的多层革命也是类似的。这不仅仅是巧合,这实际上是面对真实世界,符号和神经在方法论上的殊途同归。
2. 方法论上的殊途同归
就NLP而言,创新的符号模型和主流深度学习都是深层模型,因为二者都要面对错综复杂的语言表层符号的组合爆炸现象,解构符号现象背后的层层语义。单层模型没有足够的空间和弹性来容纳和消化自然语言。在我们的实践中,英文的parser需要50层左右才能搞定,对于更加复杂的中文则需要大约100层解析才比较充裕自如。自底而上由浅入深的多层化解析把种种难缠的语言现象分而治之,使深层解析器的准确度基本达到专家的水平,从而为赋能下游NLP落地创造扎实的逻辑基础和结构条件。深层解析与神经前馈网络类似,也使用了经由pipeline多层模块的数据流,其内部表达方式是线性结构(linear representation)与图结构(graph representation)结合的符号化表示。它本质上与多层神经网络里面的向量空间(vector space)所表达的语义(semantics)是同质的,只不过编码的形式不⼀样。
总之,在我看来,理性主义不拥抱经验主义方法论,由数据驱动层层推进,实践中是行不通的,更谈不上规模化领域落地。符号与神经各自独立发展,却在架构与方法论上殊途同归,表现出惊人的相似性。这绝不是巧合,而是由客观世界的复杂性所决定的。两条路线上的深层模型,最后的目标也是一致的,都是为了克服知识瓶颈。真正理解透这一点,需要观察对比两条路线各自的短板。
Image
3. 神经与符号各自的短板
一般而言,最为成功的端到端神经网络系统的短板是对输出端标注数据的依赖,这是迄今深度学习在横扫感知智能图像与语音等应用后,一直未能在认知智能的各领域场景规模化落地的根本障碍。在数字化信息时代,领域场景并不缺乏原生的文本数据,但大多数场景都存在严重缺乏标注数据的情况,这使得深度神经难以规模化领域落地,巧妇难为无米之炊。
为了克服这个瓶颈,自监督学习(self-supervised learning)的方法及其预训练模型开始兴盛起来。自监督学习的奇妙之处是它本质上其实是监督学习,从而可以利用成熟的监督学习的算法实现,但它学习的对象却是几乎无限的原生数据,不受人工标注数据的资源限制。就NLP而言,自学习的预训练模型,无论BERT还是GPT3风格的模型,都是从语言学习语言,都是海量数据训练出的超大模型,以此减轻下游NLP任务对于海量标注的需求。
这里说一下从语言学习语言的预训练原理。为什么说预训练也是监督学习呢?人说的每一个句子实际上都是在对词语序列进行合法标注。语言之所以为语言,是因为语言单位组合成句背后是有规律的,它是由文法和用法习惯所决定,因此千变万化的句子才可以被人类自己解构和理解。与此对照,随机的词汇组合是“非语言”。预训练学习出来的所谓语言模型,本意是首先在语言与非语言之间划线,然后对于语言现象本身学习其上下文的模式,这一切所利用的,是人类无时不在制造的语言数据。换句话说,自学习中,监督学习搭的是语言数据自然生成的顺风车。
自学习的好处是什么?好处在于数字时代中互联网的语料库是无穷无尽的,把质量稍高一些的文本都喂进模型里,就得到了我们现在拥有的那些超大模型。大厂有强大的算力,不断推出各种超大规模的语言预训练模型,希望引领NLP的应用落地。这些模型跟我们花了很多年做的深层解析器(deep parser)是差不多的,具有相同的消化自然语言及其结构的使命。
符号系统的短板是它的编码门槛高,那么解析器应用的出路是什么?出路是低代码、冷启动、半自动、流程化。编码门槛高分成两部分,⼀部分是核心引擎(即deep parser),这部分难以做到低代码。不过核心引擎是⼀锤子买卖,做好了核心引擎就相当于用符号的方法写出了一个自学习的预训练模型。应用时解析器的部分基本不需要改动,只需要在下游做简单的两三层编码,将解析结果映射成应用所需要的输出即可。我们强调的冷启动主要是指下游NLP落地,典型的任务就是领域信息抽取和文本挖掘。冷启动就是不需要大量的标注数据,只需要⼀点种子就可以推进下游NLP快速领域化落地。半自动流程化,是让机器以及开发环境去提示开发人员怎么做。目前,利用深度解析器进行半自动NLP领域落地的道路已经打通了,实践中一再被验证。当然,符号NLP算法的通用性自然不如深度学习的自学习模型,譬如,NLP符号模型的创新很难拓展到语音和图像上。这⼀点与深度学习不⼀样,深度学习算法及其架构的通用性强,可以把在NLP领域创新突破的同⼀套方法论,基础模型和设计思想用到图像,语音等各种AI问题领域。不过,相对而言,图像与语音基本是已经解决了的AI问题领域,关键还是要在NLP内部快速实现规模化领域落地,保障深度解析对于不同领域的通用性,而这一点正是我们过去几年探索的成绩及其价值所在。
Image
Image
4. 天问:神经可以终结符号吗?
NLP正处于AI历史上最激荡人心的时刻。它没有被攻克(领域上尚未规模化普及),但我们已经看到了曙光,神经与符号都显示出领域化的可行性与赋能潜力。
三十年来主流研究重心⼀边倒在统计和机器学习上,神经革命让钟摆摆得越来越高,一直没有回落到符号的迹象。有人会好奇符号主义是不是将被终结了?
我的第一个感觉是,符号被终结的可能性并不为零。监督学习的神经奇迹曾经在感知智能与机器翻译当中发生过,超出了所有人当年的预料。因此,自学习支持规模化领域落地的奇迹也不是绝无可能发生。当预训练模型在赋能NLP下游任务,普遍达到神经机器翻译颠覆符号翻译的程度时,我个人觉得就可以接受符号被终结的趋向和结论。但现在断言这种可能性,为时尚早,按照目前的技术发展和资源投入的程度,大概5-10年内可以看清。虽然我不相信⼀条路线会把另⼀条路线在各领域应用中全面取代,但如果AI能在神经的大旗下真地⼀统天下,人类一同走入通用智能(AGI)的高点,岂不是一件乐事,这才叫,不废江河万古流。但这是小概率事件。
更大的可能我觉得应该是神经与符号长期并存,逐渐开始更深的相互融合,取长补短,既包括符号子系统与神经子系统的松耦合,更包括符号与神经模块内部的紧耦合(例如内部表示中符号图与向量的相互转换)。我们知道,符号与神经的区别性特征在于其内部表示的不同,一边是结构符号,一边是向量空间。紧耦合方向非常有诱惑力,虽举步维艰,但一直有人在不懈探索。有专家认为符号神经的深度紧耦合可能是下一代人工智能的真正突破点,甚至可能开启通用智能的新时代。
这里附带提个思考题:上帝用的是向量还是符号?外星人呢?
当然没有标准答案。但我心里倾向于这样回答:上帝应该是用向量的,但外星人不能免俗:他们与咱们人类一样,用的是符号(语言)。至于外星语的符号用的是什么编码载体,声音还是图形,则不确定。
03
低代码是趋势,也是王道
1. NLP低代码潮流
最后想强调的是NLP低代码的潮流,它是从AI开源平台的兴起开始的。当今互联网各大厂都在建立推广自己的深度学习平台,谷歌的TENSORFLOW,脸书的PYTORCH,等等。各种平台级工具箱和软件包也在开源社区流行,有KERAS的神经网络框架,还有SCIKIT-LEARN这样非常成熟的包括几乎所有统计模型的软件库。现在做模型就像玩积木一样,你可以用短短几行代码去调用这些库很快实现一个原型系统,刚毕业的大学生研究生也能很快实现一个像样的模型。
符号NLP这方面其实也有不少进展,我们做的多层NLP符号平台也是在半自动、冷启动、低代码和流程化的路上。其目标是把编写NLP代码的人从“码农”转化为判官,以高精度低召回的样例规则代码为起点,通过检验数据质量的变化决定符号规则的泛化路径及其迭代更新。这种低代码的开发流程在一系列不同领域的落地应用实践中验证了其有效性,使得NLP代码开发的效率至少提升了一个量级,从以前的几周时间缩短为几天。
2. 数据科学与工程的兴起
AI低代码趋势的标志之一是数据科学的兴起。这几年来,很多大学顺应市场需求,开设了数据科学(Data Science)专业,批量培养知识工程师。目前,数据科学专业有些杂,大体上一半是计算机的课程,另一半是不同领域的实践教学。它训练你在不同领域方向上将AI低代码能力与领域数据处理结合起来,完成一些领域应用。这标志着NLP和AI从学术的象牙塔里走了出来,逐步汇入各行各业的应用场景。各种开源低代码平台、工具和社区的推广,使得学习的门槛也降低了。在线教育如火如荼,也顺势而起,专精数据科学培训的datacamp上就有上百万人在学习相应技术课程。AI数据科学在行业落地应用的前景在接下来的十年中会越来越普及,低代码人力储备也逐步准备好了。有意思的是,前几年AI热引起的风投热度开始明显降温,但这与其说是AI泡沫破灭了,不如说是对于AI规模化领域落地和普及的预期过高,不了解AI的自身发展的真实趋势。上一波赶上了感知智能大爆发潮流的资本,有耐心和机缘赶上认知智能今后10年中的爆发节点吗?
04
NLP“半自动驾驶”
1. 半自动符号NLP的设计哲学
以上算是务虚,下面回到符号NLP创新的务实话题,讲述一下NLP老司机的半自动“驾驶”,结合本论坛的金融主题,介绍符号NLP在金融领域的落地中的实践。NLP落地金融与我们在法律、电力、航空、客服等应用场景的领域化工作一样,围绕一个相同的开发理念和设计哲学:数据驱动,但不依赖标注数据;无米可以,有稻即成:解析器作为碾稻成米的核武器,无米之炊可成。
具体说来,低代码半自动可以从样例种子开始。只要有“种子”就可以全自动地生成规则,并且在生成规则的基础上实行半自动的规则泛化流程。泛化的方式分为上下文泛化和词节点泛化两大类,其中上下文可以灵活应用图结构上下文与线性上下文(例如窗口限制)。词节点泛化带入本体知识库,包括常识的逻辑推理链条加持。泛化路径由系统内部自动配置确定可选项,由知识工程师(开发者)从可选项中选择进行。这就让纯粹手工的规则编码流程,转变为半自动的代码调整过程,大大减轻了代码开发成本以及知识工程师的培训成本。
NLP落地领域作为一项软件知识工程,整个流程遵循软件开发的best practice,包括建立和维护代码迭代更新的质量管控标准和措施,保证在不依赖标注数据条件下的数据质量。监督学习所依赖的标注数据黄金标准,被知识工程师的数据比对与判定代替,码农从而成为判官,半自动监督指导符号系统上线前的迭代开发以及上线后的维护开发。半自动模式下,只需要使用样例种子来冷启动符号规则的开发过程,系统自动提示调整泛化的路径。知识工程师从代码的细节解放出来,以人机互动的方式实现符号系统的快速领域化。目前我们已经在多语言(10多种欧洲和亚洲主要语言)和多领域(金融、法律、电力、航空、客服等)的不同场景落地,用的都是这套数据驱动的方法论:低代码、冷启动、半自动、流程化。
Image
2. 半自动符号NLP的实践
实践部分咱们以金融NLP落地为例。金融领域的特点是句子比较长、信息点多、关系复杂,一个两句话的例子中可能就有30多种关系需要抽取。但好在句子的模式比较固定,目标关系的抽取步骤是内部先消化成同一个结构,然后再把结构映射(map)到输出端去建立关系及其角色。属于图结构的匹配和映射。
Image
Image
经年打磨的深度解析引擎对各领域保持稳定。但在该核心引擎应用到具体领域的时候,有一个步骤是保障引擎领域化的关键,就是领域词典的加持。事实上,那些开源的深度学习训练出来的解析器(斯坦福parser,谷歌SyntaxNet,等)之所以至今没有规模化的领域应用成果,主要瓶颈就是难以适配领域化数据。这些在通用数据上训练出来的解析器虽然质量接近专家水平,但对于数据非常敏感,一旦数据场景偏离原训练数据,数据质量常常悬崖式下跌,不堪使用,其主要原因就是面临领域新词的挑战。训练模型缺乏外加词汇的加持手段,加上解析器的输出沿用社区标准(类似PennTree)只提供结构图,并不提供词节点的语义特征及其本体知识链条的支持,这就使得下游NLP很难落地。我们的多层符号解析模型克服了上述缺点,下游NLP任务继承核心引擎的所有信息和知识,用的是同样的机制和符号语言,从而打开了快速领域产品化的大门。
领域词典分为两部分,一部分是领域新词发现(或利用领域已有的开源词汇资源)。我们通过领域原生数据的N元组聚类获得候选领域词汇,然后经过噪音过滤等过程与系统内基础词典及其本体知识库对接。在金融领域,新词发现获得了三万N字新词或词组(9>N>2)。领域词汇的另一个来源是用户词典,这个规模小得多,但可以在开发过程中随时增补修改,可以更加灵活地配合引擎的领域化开发工作。
在词节点泛化路径中,内部有现成的本体知识库(HowNet的精简版)及其上下位路径去帮助泛化。在上下文约束条件的调整中,系统预先设置好了通过图关系或窗口限制的两条上下文泛化路径,只要点击就能调用。泛化过程与深度学习系统的梯度下降的原理类似,只不过符号系统的“拟合”按照系统设计者根据内部知识和经验预定的泛化路径来进行,路径节点是离散的有限集合,一条样例规则大约经过10-20次泛化迭代可以定形。无论节点泛化还是上下文泛化都具有可解释性。每一步泛化迭代都在由原生数据组成的开发集中得到验证,以此保障迭代开发的数据质量。金融实体与关系的抽取就相当于深度学习网络的输出层,由一些简单的抽取规则组成(见图),规则模式的条件是词和上下文之间发生的窗口关系(例如Win9,9词窗口)或者语法关系(例如Link1,一层关系,即直接依存关系)约束。系统自动提示约束条件的可选项,最后由在开发集上的回归质量测试决定一个选项在精度与召回上的表现。表现不够格就回滚到前一个状态重新尝试其他泛化路径,如此循环。主要理念是用半自动的系统提示的方法把⼀个很紧的规则松绑到恰到好处,让系统在精度和召回中做出合理平衡。这种方法可以概括正例排除反例,提高精度,同时在泛化中自然加强系统的召回(recall)与鲁棒。
Image
Image
总结一下,半自动流程化NLP落地的主要优点是不再依赖标注数据。基于结构和理解的冷启动低代码路线具有普适性和跨领域的优点。不足则是低代码并不是无代码,依旧需要一些代码纠错技能,但培训门槛则大大降低了。
05
精彩问答
Q1: 您在做parsing的时候使用的标签体系是否有统一的标准,在哪里可以学习呢?
A1:标签体系是有传承的,不是Penn Treebank那套标签体系,因为虽然Penn Treebank是符号领域中的社区黄金标准,但我们知道其中有很多的固有缺陷,落地实践用起来也不够方便。根本的标签是从 Dependency grammar这路继承发扬下来的。在我的NLP频道 (liweinlp.com) 的许多样例的后面,都配有这些标签的简单说明。句法语义的关系标签集合不大,粗线条的parsing标签不到10个,细线条的标签总数也就几十个。但是词概念的标签集合则大得多,我们用到的大约2000左右标签,包含了HowNet的核心本体特征。
Q2: 同一层解析中不同规则的优先级是完全基于语言专家知识来确定的吗,也就是确定性的非概率的吗?
A2: 对,是确定性的、非概率的,但在确定性中对于不确定性有⼀种包容。包容是指在非确定的情况下,不在特别关键点的时候,系统先把它包住。⽐如在某些节点中有词汇歧义,但这个歧义不是你所要做的任务急迫需要解决的问题,这时就可以先包住,等到条件成熟时再对付它。结构歧义也同样有包容的手段。我们虽然在pipeline的数据流里是用确定性方法往下传递数据结构,但里面同时蕴含了包容下来的不确定性或歧义。系统装备中有我们称为“睡眠唤醒”的机制,可以从事局部结构的重建、修正或再造,在宏观条件成熟的时候,例如在后期更大的上下文背景条件下,重新展开局部结构进行重建或覆盖。
Image
今天的分享就到这里,谢谢大家。
【相关】
NLP 新纪元来临了吗?
《我看好超大生成模型的创造前途》
李维 郭进《自然语言处理答问》(商务印书馆 2020)
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
【语义计算:李白对话录系列】
【置顶:立委NLP博文一览】
《朝华午拾》总目录