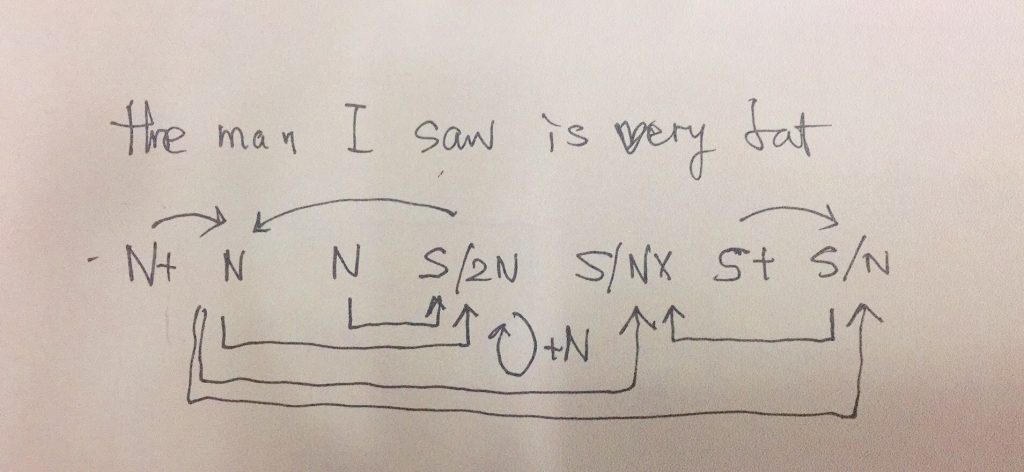聊一聊中文切词的 heuristics
李:
NLP 论文中常出现的一个术语 heuristics 怎么翻译好呢?想了 30 年了,用到的时候还是夹杂这个英文词,因为想不到一个合适的译法。最近想,大概是翻译成 “倾向性” 比较好。说的是某种统计上的趋向,而不是规律。
白:
启发式
李:
30年前,我有个同门学长乔毅常常鼓捣一些专业翻译,有一天他来跟我商量,问:“这篇说的是 heuristic 方法的 NLP,查了一下词典,是启发式,可这启发式翻译出来,等于没翻译,没人懂怎么启发的。到底 heuristics 是个什么方法?”
魯:
有些时候是ad hoc的意思
白:
翻俗了就是“偏方”。有例外的标配。
李:
当时我们琢磨半天,觉得所谓启发式,就是某种条件 (constraints),有时候甚至叫原则(note:原则都是有例外的),不是通常的 rule,因为 rule 隐含的意思是铁律,而这个“启发式”说的就是一种有漏洞的条件,经验总结出来的某个东西,模模糊糊是有统计支持的。明知有漏洞,但还挺实用。就这么个东西,困扰了我机器翻译专家30年。不是不明白,是明白了也还是不知道该怎么翻译。岂止一名之立旬月踟蹰,这是一辈踟蹰一名不立。
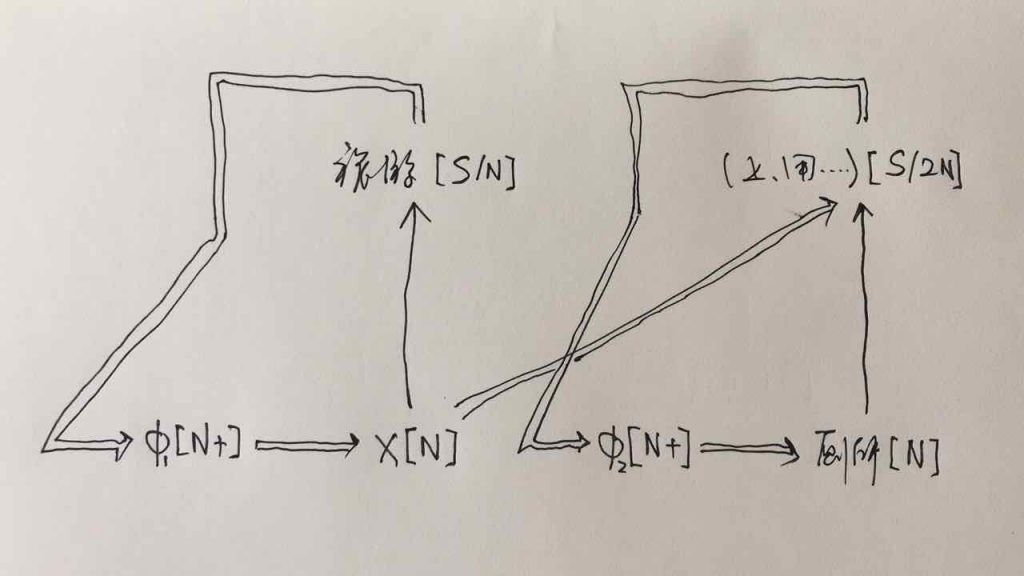
以上算是开场白。今天就来说说切词中总结出来的一些 heuristics。咱们倒过来说这事儿。把 input 想象成一个 ngram。首先说一条总的:切词中最大的 heuristic 是最大匹配原则,这是天则。
咱们来具体看看 ngram 的情形:
(1) 如果 input 是一个汉字 (unigram),当然就是一个词:因为无词可切。这是废话,但也不失为一个 heuristic,因为切词算法的最后一招就是 把字(语言学上术语是“词素”)当成词,可以保障100%召回率(recall)。因为汉字是非常有限的集合(【康熙字典】多少字来着?),可以枚举。所以废话(或常识)背后也有深刻的道理的。显然这个 heuristic 是有漏洞的,但是我们总可以用它来兜底。漏洞譬如那些所谓 bound morphemes:蝴,尴,它们理论上是不能成词的,如果万一被切词程序输出为词了,很可能是一个 bug(譬如原文在 “尴尬” 之间夹杂了空格或其他符号造成这种结果,或者原文说的就是这个汉字,不是指这个概念词素,那算是 legit 的 meta-word)。无论如何,切词模块在工程上和算法上几乎没有人不用这个 heuristic。
(2) 如果 input 是两个字(bigram) AB,而 AB 在词典里面,heuristic 告诉我们 AB 就是应该切出来的词。这个heuristic 是直接从最大匹配原则来的,几乎每个系统都这么办,尽管它当然有漏洞。漏洞就是所谓 hidden ambiguity, 理论上的 exhaustive tokenizations 中不能排除的 A/B 这种切词法。以前我们举过关于 hidden ambiguity “难过” 的 minimmal pair 的例子(见【立委科普:歧义parsing的休眠唤醒机制再探】):
这/个/孩子/很/难过
这/条/河/很/难/过。
其实,利用汉字作为 meta-words 的语用情形的话,一切的 ngram 都可以有一个违反最大匹配原则揭示 hidden ambiguity 的通例模式,是:
【ngram 】是n个汉字。
尴/是/一/个/汉字/。
尴/尬/是/两/个/汉字/。(尴/是/其一/,/尬/是/其二/。)
不/尴/尬/是/三/个/汉字/。
尴/不/尴/尬/是/四/个/汉字/。
尴/尬/不/尴/尬/是/五/个/汉字/。
.........
虽然 100 个系统有 99 个半都明知这个 heuristic 有理论上的漏洞,而且也有实践中的反例,但是都心知肚明地 follow 这个最大趋势。因为好汉不吃眼前亏啊。在切词这种早期阶段,不 follow 这条带来的麻烦太大。识时务者为俊杰,英雄狗熊在这一点其实所见皆同,说明世界上傻子并没有那么多,除了“傻得像博士”。譬如我博士论文中就倡导过用 exhaustive tokenizations 的结果来 feed a Chinese HPSG chart parser, 有意违反这一原则,把 hidden ambiguity 从一开始就暴露出来,来证明句法或更大的 上下文 对于完美切词的重要作用。理论上没有问题,实践中也弄出了个可以应付博士学位的玩具系统(【钩沉:博士阶段的汉语HPSG研究】),但到了工业应用,立马就精明起来,随大流,从了 最大匹配的 heuristic。
白:
“马可波罗的海外奇遇”
李:
哈, “马可波罗”, “波罗的海”,4-grams 哎,人名和地名打起来了,也是奇例 。
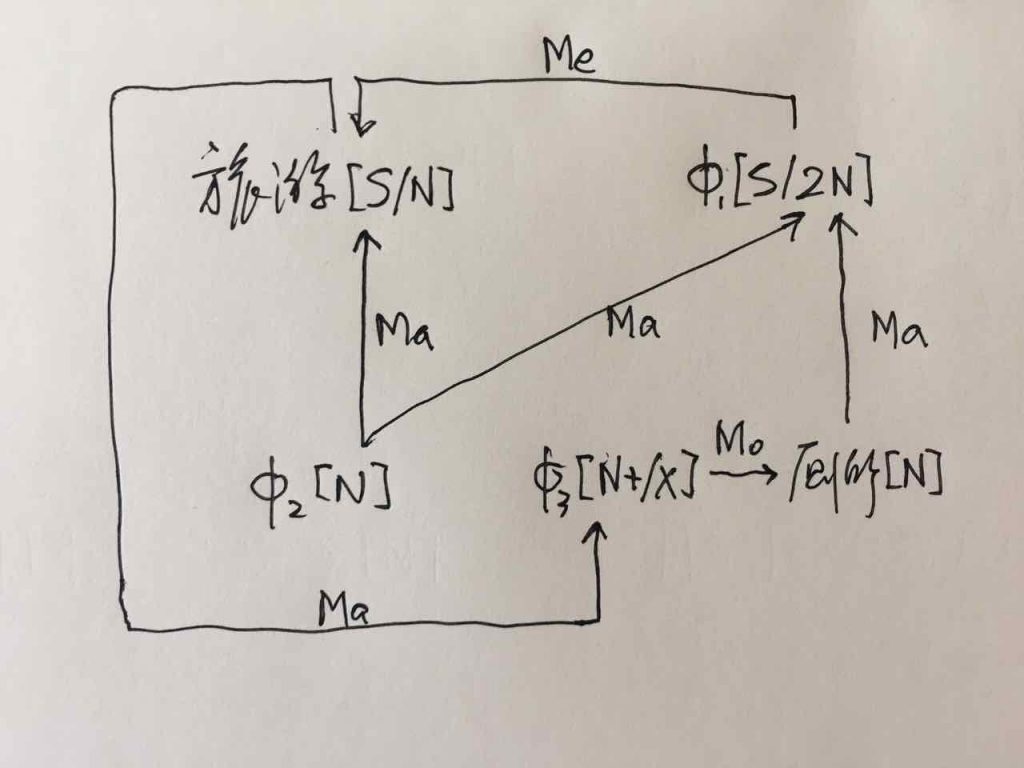
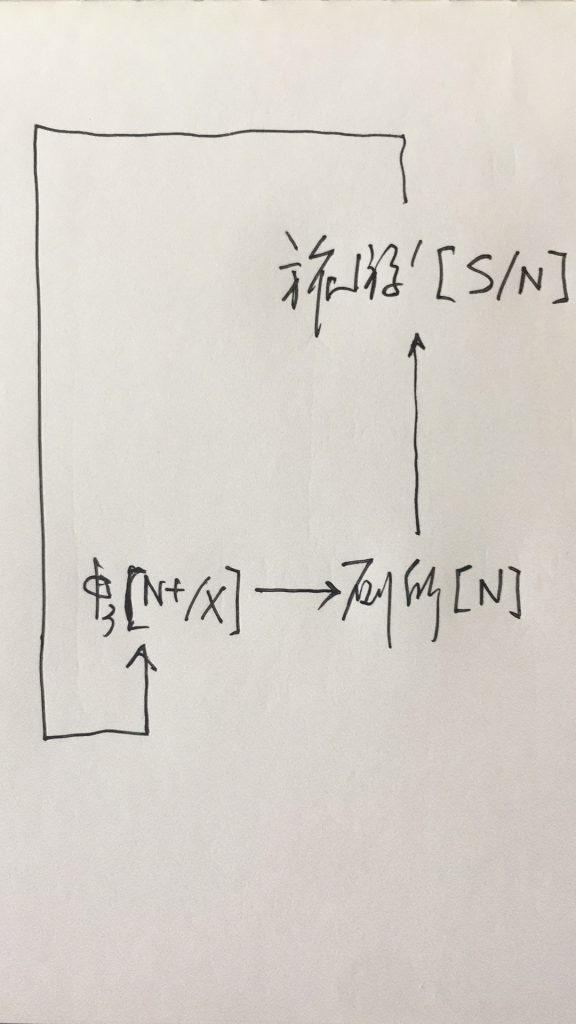
回头说 hidden ambiguity,N多年后,我们还是高明了一些,退了一步,说,好好好,好汉不吃眼前亏,咱们还是 follow 这个最大匹配原则,但可以留个后门啊。后门就取名为休眠唤醒,《李白对话录》中多篇有论,有方法,有例示(【结构歧义的休眠唤醒演义】 )。这算是在理论和实践中找到了一个比较合适的折中,不至于面对 hidden ambiguity 的“切词命门”完全不作为。
白:
谁说切词的结果一定是流,不能是图?谁说即便是流,切的时候啥样,用的时候也必须啥样?谁说即便是流、即便用的时候跟切的时候也一样,但在更大上下文范围内发现用错了的时候必须不能反悔?
李:
白老师说的几点都对。但很长时间很多人并没有认识这么清。
接着练,(3) 如果input是三个字(trigram) ABC,heuristic 是怎么体现的呢?首先根据最大匹配heuristic,排除了 A/B/C,先踢出局。剩下有 AB 与 BC 的较量,如果二者都在词典的话。这时候,heuristic 说,汉语的二字词并不是都有相同的紧密度,即便用最粗线条的二分法,也可以给一些二字词比其他二字词更大的权重来解决这场三角关系(triangle)的危机。忘了说了,如果 ABC 在词典的话,AB 和 BC 都出局了,毫无疑问,因为最大匹配永远是切词阶段最大的原则。例外怎么办?后期休眠唤醒。
(4) 如果是四个字的 input(4-gram)ABCD,hueristic 又是怎样实施的呢?(别急,这么论事貌似进入了死循环,但其实胜利曙光已经在望,bear with me a bit)。根据最大匹配这个最高原则,ABCD 如果在词典(譬如成语),句号。ABCD 中任何一个连续的 bigram 如果在词典成词的话,A/B/C/D 也出局了,根据的还是最大匹配的 heuristic(或其变种,最少词数原则)。那么还剩下什么?如果是 ABC 和 CD 在词典,两家打架, heuristic 说,两家人家打架,人多者胜, ABC 胜过 CD(就是说,可以假定权重 heuristic 让位给词长 heuristic)。同理, AB 败于 BCD,其他的情形都是显而易见的,AB/CD instead of A/B/CD, AB/C/D and A/B/C/D,不赘述。
白:
如果ML,满大街都是heuristic。
李:
所以说 heuristic 应该翻译为 (有统计基础的)趋向性。学习也好,根据 heuristics 硬编码实现也好,总之是要 follow,不要与潮流作对,除了傻博士。
(5) 如果 input 是 5个字(5-gram)ABCDE,ABC and CDE can fight: if ABC is considered to carry more weight, then ABC wins. 后面的话不用说了。到了 5-gram,可以收网了。
其实迄今绝大多数切词算法,大多依据的是 local evidence,5-gram 几乎是 local 的最大跨度了。因此搞定了 5-gram 以内的 heuristics 的相互作用的原理,也就搞定了切词,虽然理论上所有的 heuristics 都是筛子一样,漏洞百出。这一点儿不影响我们前行和做 real life 系统。
金:
@wei 老师,想请教一下您对于深度学习做分词的观点:训练语料为手工分词文本,将文字按单字逐个输入,输出是结合输入语境对文字进行分词的结果。
李:
据说深度学习分词,精准度有突破。有突破我也不会用。除非有谁教会我如何简单地 debug,如何快速领域化。何况早就过了这一村了,工具架构算法齐全,不再需要与它纠缠了。
金:
如何领域化?在特定领域操作?
白:
让领域的人再标注领域的文本,不就领域化了
李:
不愿标注呢?或 cannot afford 标注呢?错了怎么 debug?再加大标注量,重新来过?重新训练可以保证对症下药解决我面对的 bug reports 吗?
金:
嗯,看过之前您的文章,关于统计和规则之间的渊源。如果就用深度学习一个模型,是这样。最大匹配的话,错误如何修正呢?
白:
都已经是锦上添花了,再错能错哪儿去
李:
明明就是个词典打架的事儿,非要标注文本。词典是有限的,而文本是无限的。
白:
领域会突破词典。
李:
那是领域词典的习得问题(lexicon/term acuqisition),是个更实惠的活计。相比之下,领域标注分词不是个划算的事儿。
白:
未登录词也得分。领域会引进新的heuristic,使得通用成问题的地方不是问题。做减法。
李:
手工标注海量数据是一种不讲效率的办法,人类举一反三,标注反着来,是举三返一,不对,其实是举30也很难返一,隔靴搔痒。幸亏它有几个优点。一个是提高就业率,简单劳动,而且白领,有利于维稳和安定团结。另一个是为不愿意进入领域的人做自封的领域专家铺路。管它什么领域,管它什么任务,只要你给我标注,我就用三板斧进入领域。
白:
不利于语言学家的就业率,也是罪过
金:
二位老师的观点有深度,
李:
不仅是语言、语言学和语言学家,所有领域专家都有遭遇。不求甚解于是风行。天上掉下一块鸟屎,都会砸到一个速成的领域专家头上,譬如不懂语言学的计算语言学专家。
白:
背后的逻辑是不与虎谋皮。没那么简单这事儿。
金:
数据标注得有领域专家来做标准呢。
李:
要是可以选择的话,不自由毋宁死。可惜领域专家没有这个气节。乐不颠颠地为精算师去制定标准,然后让他们成为高高在上的超领域专家。
白:
“孙国峰硕士毕业于著名的清华五道口,后师从社科院金融研究所李扬成为金融学博士。他硕士毕业后便参与了中国外汇交易中心及公开市场的建设,并从此肩负起货币政策的实施、制定、监管之责,与中国金融市场及市场中的一代一代的交易们一起成长。”
看看这段话,“硕士”极容易被当成“孙国峰”的称呼性同位语。
金:
这个就是环境的作用了,不是我们能左右的。
吕:
孙国峰,硕士毕业于著名的清华五道口 ....
金:
我想到一个和目前情况类似的人,最早著书的人,是不是大部分是领域专家,因为国家,因为文化,因为其他原因投身著书行业,把知识标准化,流传下去?
白:
@金 这样的是例外吧。
金:
我只是想到这个情况,而且更极端的是这群人因为生存因素,去著书,还有可能从谷底爬上巅峰(可能故事听多了)
白:
@金 楼歪了,言归正传吧
所有的交叉歧义、组合歧义,其实在词典定好以后就是铁案了,一定能仅从词典就机械地自动遍历枚举所有情况,这是学术界早有的定论。
问题之一在概率分布。领域无关相当于先验分布,领域相关相当于后验分布。后验分布如果明显不同于先验分布,领域知识就有优势,否则就没优势。
阮:
比如说医疗领域,会有一些特殊的词,也会有特殊实体,句法的话,应该也是符合自然语言句法的,但分布应该不太一样。 我需要重新完全标注语料呢,还是标注一部分?标数据这事,谁来做,也确实很头疼。语言学家觉得和他们没关系,也看不太懂。而医学更加不知道标语料为何物。
白:
问题之二在未登录词。你说再多词典没定义都是扯,只要影响应用,没人会听你的。所以做好构词法,应付未登录词是刚需。神经是不分登录词未登录词的,就是说如果ABC、ABD都没见过,语料里标注了ABC,神经是有可能学会ABD的。并不是说要分词只有词典化一条路。而构词法是里,分词是表。学会构词法可能首先是通过分词体现出来的。神经不是“仅”学分词,而是“同时”在学构词法。比如“中证协”标注了,“中保协”没标注。神经可以学会“中保协”正确分词,但并不说明“中保协”一定在词典里。
李:
学构词法有个悖论。学会不在词典的词可能对于粗线条的任务有好处,但对于分析和理解自然语言没有什么好处,你必须同时学会这些不在词典的词的可计算的信息部件才算数,譬如句法 features,概念语义及其在本体链条上的位置,等。对于自然语言 parsing 和 understanding,切词的目的就是要获取关于该词的词典信息,作为进一步分析的基础。现在分了词了,却没有对应的词典词条,那不是白分?这就是我说的悖论。
今天遇到一个好玩的:上交所有 ...,分词为 上交所/有。
白:
交叉歧义。长词优先。
李:
我实习生说 错了,她坚持改过来:上交/所有
原来她心里想的是:上交 所有 不义之财。我说难道你不知道,上交所 有 个 大名鼎鼎 的 白老师?
白:
严正声明:上交所没有不义之财。
李:
此地无银啊?
“上交所”在90后的头脑里是个未登录词,未登录的或可免责。如一不留神道破天机,纯属意外。明儿让她进来给白老师赔罪。
吕:
哈哈哈
金:
有趣
巴:
学生菜鸟一枚,特来给白老师赔罪。
请各位老师多多指教啦~
白:
@巴拉巴拉 应该找上交所的CFO,我前CTO不管这段。
巴:
哈哈哈哈,总之是妄言了,先赔罪总是对的。
白:
@巴拉巴拉 这群有意思,可以偷到很多艺
讨论NLP居然如此欢乐,也是醉了
唐:
Heuristic=educated guess, or sub-optimum solution, 这个在算法界没有歧异呀!
ngram取5就能处理大多数问题。 我们在网络安全上学习domain name也是这么用的。
李:
唐老师给个权威标准译法吧。
启发式 不中。
洪:
“上交所有不义财!“
如何正确词划开?
分词若有人使坏,
上交所的脸吓白。
李:
今年是金融反腐年,据说金融腐败和金融政变是关系到党国生死存亡的。
唐:
个人认为: heuristic 翻译成“次优解“更好。
李:
问题是 很多时候 必须遵循。次优的言下之意是不要遵循,应该追求更优的。除了傻博士 大家都明白,次优往往就是最优。
唐:
次优的意思是,大多数要用因为找不到最优。
李:
在给定时间空间 次优就是最优。
唐:
5-ngram对中、英文分词有效,对其他主要语种是否也有效?
李:
很多浅层的任务,如分词和POS,都是主要靠 local evidence,5-gram 基本上就是 local 的一个比较恰当的定义上限。
唐:
你今天的博文解答了我的一个问题: 为什么dns domain name分析只要5-ngram就行了!真是他山之玉可以攻石
【相关】