【立委按】强力推荐。非常好的 review。曼宁教授深厚的计算语言学学识反映在他的综述和展望中,具有历史厚度和语言本质的理解深度。最后的那个点也很好:当前的一锅煮的超大模型实际上是一个可行性研究,已经初见成效;将来的大规模的领域场景应用,会召唤相对来说小一些但更加领域数据密集和纯化的基础模型,可以展望其革命性前景。至于这算不算 AGI,曼宁说的也很有分寸:看上去算是在通向 AGI 的路上。短板主要是 semantics 还不够直接面向真实世界,而是源自符号世界、囿于符号世界(所谓 distributional semantics),等于是绕了一个弯儿,语义的深度以及语义结构本身就显得太扁平 太浅 难以消化人类深厚的知识积淀。但即便如此,也堪称一个伟大征程的坚实脚步,是激动人心的NLP新时代。从分布角度看意义,如果说人是社会关系的总和(马克思),那么也可以说,语词基本上是语词间篇章关系的总和。很多年来,我们 NLPers 一直挣扎在如何把 context 合适的模型化,因为语言符号的歧义和微妙很大程度上可以在 context 中予以消解。context 最直接有效的对象就是 sentences/discourse,而恰恰在这一点,深度学习注意力机制为基础的大模型展示了其几乎神奇的表示能力。
刘群老师:同意@wei,深度学习和预训练方法取得的进步非常惊人,超出想象。原来感觉不可解的一些问题,现在似乎都看到了曙光,解决路径隐隐约约能看到了。虽然对AGI仍然质疑,但对这个领域的前景真是非常看好。
算文解字:是的 同一个模型prompt一下就能完成各种nlp任务 就算不是agi 也是更g的ai了[Grin] 而且即使是从denotational semanrics的角度看 加入多模态的预训练模型也算是部分和间接的grounding到真实世界了的物体了。
刘群老师:是的,原来觉得一般意义上的grounding几乎不可能,除非是特定领域。现在看越来越可能了。
立委:感觉上,意义表示(A)落地到客观世界(B)可以看成是人类与生俱来的本能,不需要特别的模型化,如果A本身比较充分的话。 那么这个 A 是个什么东西呢?A 可以看成是一个平面的表示,其中 X 轴就是 discourse/context,而 Y 就是 ontology 甚至还带有 pragmatics 因素的世界知识和推理体系。
目前的大模型的长处是 X 模型化,短处依然在 Y。因此虽然从分布角度貌似也总结出了一些常识,以及浅层的推理能力,但这些能力没有足够的深度和逻辑性,缺乏推理的链条性和一致性。
符号知识图谱以及人类探索积累下来的本体知识库、领域知识库,这些东西都是非常浓缩的、高度结构化的知识体系,本质上具有严谨的逻辑性和推理能力。分布式学习学到了这些知识的皮毛,但总体上,对于这些知识精华还很陌生, 难以系统性直接兼容并蓄。
刘群老师:当然离解决这些问题还远,只是说能看到曙光了。以前感觉根本没希望。虽然还不怎么样,但不是没希望。日拱一卒[ThumbsUp]
算文解字:还有这两年出现的基于预训练模型的常识推理(如Yejin Choi组的工作)也让人眼前一亮。即使五年前,还是说研究common sense一般反应都是敬而远之[Facepalm]
立委:大数据为基础的分布学习可以反映相当多的常识,这个是没有疑问的。我们在本群中讨论过很多案例,也有这种反映:所谓大数据支持的“相谐”性,其实与常识中的特征匹配,吻合度很高。
刘群老师:把符号融入到神经网络里面不是解决这个问题的正确方法,还是分阶段处理,来回迭代才是正途。
立委:方法论上也许的确如此,但 intuitively 感觉是一种知识浪费。就是说,从我们DL外行的角度来看,明明人类已经世代努力提炼了精华,都规整得清清楚楚,可模型就是没法利用。一切必须从头开始。让人着急。
刘群老师:我说的来回迭代不是人机交互,是符号和神经来回迭代,可以自动化的。
立委:哦,那就是我希望看到的深度耦合/融合。这种融合是革命性的方向,有望发生新的AI突破与下一代的范式转变。但不久前,还普遍被认为是一种乌托邦,觉得符号和神经,就跟林黛玉与焦大似的,打死也不兼容。
算文解字:刘老师,这个方向上近期有哪些比较亮眼的工作呀?
刘群老师:WebGPT, AlphaCode等。还有周志华老师反绎学习的工作。
算文解字:恩恩 的确 webgpt这种都可以看做是 大模型 和 离散/黑盒系统(可以是规则)交互迭代的方案
立委:前面提到,对于大数据,人比起机器,有时候好像蚂蚁比大象。有老友不满了,说不要这样说,这是“物种”歧视。
其实,很多事儿,人比起机器,还不如蚂蚁比大象......
1. 计算
2. 存贮/记忆
3. 下棋
4. 知识问答
5. 翻译
6. 做对联
7. 格律诗
8. ......... 可以预见的未来清单还很长很长,都不是遥不可及的 ......
(自动驾驶、自动咨询、自动陪护、自动培训、自动写作、自动音乐、自动绘画 ...........)
事实在那里摆着。不服不行。
回顾历史,人类第一个被蒙圈的就是计算。以前的那些心算大师,算盘顶级快手,现在很少有宣传了,因为干不过一个小小的计算器。
紧接着是存贮量和记忆力。当年我们最崇敬的人物就有不少是过目不忘 博闻强记的大师们。社科院流传着很多大师的传奇故事,社会上也有很多周总理的超凡记忆力的故事,都是能记住非常细节的东西,可以在记忆的大海捞针。现如今,谁敢说任何大师记忆的信息量能比过一个U盘。哪个大师还能在谷歌百度面前夸口自己的大海捞针的信息检索能力?
下棋不用说了,电脑完胜,两次载入计算机历史的里程碑。知识问答也进入了计算机历史博物馆,IBM 沃伦的高光时刻。机器翻译我一直在用,我本人就是机器翻译出身的,目前的翻译水平高过普通翻译,注意:不是指速度。对联、写诗 也有过大赛。自己试试就知道了:你可以尝试在家苦学格律诗n年,然后即兴写诗,与机器比试比试?
面对超大数据的基础模型,人类脑壳里的“小”只会越越来露怯,想藏拙也藏不住了。
当然,严格说来这不是一场完全公平的实体之间的比试。一边是单个实体的人(例如世界围棋冠军),另一边是消化了人类整体知识积淀的实体机器人。好比一人对无数人,自然是蚂蚁遇上了大象。但是,另一方面看,每个碳基生物的人也在不断学习人类的知识才能成为专家或冠军,并非一张白纸。关键在于学习能力,碳基实体无法与硅基实体的电脑比试自动学习的能力,因为后者占尽了时间(速度)与空间(存贮)的优势。超人的出现不会是人,而是机器人,这应该是用不了50年就可以做实的现实。
新摇滚歌手汪峰曾经唱到:我该如何存在?
面对汹涌而来的大数据大模型,人类准备好了吗?

与曼宁教授在斯坦福合影(2017.07.18)
斯坦福Chris Manning: 大模型剑指通用人工智能?
著名NLP学者斯坦福大学的Chris Manning教授近期在美国人文与科学学院期刊的AI & Society特刊上发表了一篇题Human Language Understanding & Reasoning的论文。
文章在简单回顾了NLP的历史发展的基础上,分析了预训练的transformer模型何有此威力,探讨了语义和语言理解的本质,进而展望了大模型的未来,对新手还是老兵都颇有启发。本文就聊一聊论文的要点。顺便提一句,论文谈的是NLP,但本质也是在说或许我们已经在通用人工智能(Artificial general intelligence, AGI)上迈出了坚定的一步。
-
NLP领域的范式转移
文章先简要回顾了自然语言处理(NLP)的几个阶段,这对于新一代炼丹师可能过于遥远,所以我们也一笔带过:
-
第一阶段,发轫于冷战时期1950-1969的机器翻译工作,以现在的观点看数据和计算量都小的可怜,同时没太多语言结构或者机器学习技巧介入。
-
第二阶段,1978-1992的符号主义,没错,约等于规则,那种很系统且elegant的规则。
-
第三阶段,1993-2012的,实证主义,也就是基于语料库的机器学习时代。
-
第四阶段,2013开始一直到现在,深度学习时代。
深度学习本身当然意义巨大,但2018年出现的大规模自监督(self-supervised)神经网络才是真正具有革命性的。这类模型的精髓是从自然语言句子中创造出一些预测任务来,比如预测下一个词或者预测被掩码(遮挡)词或短语。
这时,大量高质量文本语料就意味着自动获得了海量的标注数据。让模型从自己的预测错误中学习10亿+次之后,它就慢慢积累很多语言和世界知识,这让模型在问答或者文本分类等更有意义的任务中也取得好的效果。没错,说的就是BERT (Devlin et al, 2019)和GPT-3之类的大规模预训练语言模型,large pretrained language model (LPLM),中文世界也常称之为大模型。
-
为什么大模型有革命性意义?
用Manning自己的话来说,在未标注的海量语料上训练大模型可以:
Produce one large pretrained model that can be very easily adapted, via fine-tuning or prompting, to give strong results on all sorts of natural language understanding and generation tasks.
从此,NLP领域的进展迎来了井喷。
Transformer 架构(Vaswani et al., 2017) 自2018年开始统治NLP领域。为何预训练的transformer有如此威力?论文从transformer的基本原理讲起,其中最重要的思想是attention,也就是注意力机制。
Attention其实非常简单,就是句子中每个位置的表征(representation,一般是一个稠密向量)是通过其他位置的表征加权求和而得到。Transformer模型通过每个位置的query, key以及value的表征计算来预测被掩码位置的单词。网上有很多介绍transformer的资料,不熟悉的同学可以自行搜索,大致过程如下图所示:
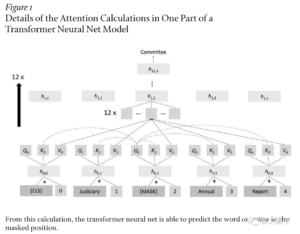
为什么这么简单的结构和任务能取得如此威力?
此处颇有insight。Manning认为通过简单的transformer结构执行如此简单的训练任务之所以能威力巨大的原因在其:通用性。
预测下一个单词这类任务是如此简单和通用,以至于几乎所有形式的语言学和世界知识,从句子结构、词义引申、基本事实都能帮助这个任务取得更好的效果。因此,大模型也在训练过程中学到了这些信息,这也让单个模型在接收少量的指令后就能解决各种不同的NLP问题。也许,大模型就是“大道至简”的最好诠释。
基于大模型完成多种NLP任务,在2018年之前靠fine-tuning(微调),也就是在少量针对任务构建的有监督数据上继续训练模型。最近则出现了prompt(提示学习)这种形式,只需要对任务用语言描述,或者给几个例子,模型就能很好的执行以前从未训练过的任务 (Brown et al, 2020).
-
NLP的大模型范式
传统的NLP是流水线范式:先做词法(如分词、命名实体识别)处理,再做句法处理(如自动句法分析等),然后再用这些特征进行领域任务(如智能问答、情感分析)。这个范式下,每个模块都是由不同模型完成的,并需要在不同标注数据集上训练。而大模型出现后,就完全代替了流水线模式,比如:
-
机器翻译:用一个模型同时搞多语言对之间的翻译
-
智能问答:基于LPLM微调的模型效果明显提升
-
其他NLU任务如NER、情感分析也是类似
更值得一提的是自然语言生成 (natural language generation, NLG),大模型在生成通顺文本上取得了革命性突破,对于这一点玩过GPT-3的同学一定深有体会。
这种能力还能用在更为实用的医学影像生成任务上。大模型能在NLP任务上取得优异效果是毋庸置疑的,但我们仍然有理由怀疑大模型真的理解语言吗,还是说它们仅仅是鹦鹉学舌?
-
大模型能真正理解人类语言吗?
要讨论这个问题,涉及到什么是语义,以及语言理解的本质是什么。关于语义,语言学和计算机科学领域的主流理论是指称语义(denotational semantics),是说一个单词短语或句子的语义就是它所指代的客观世界的对象。
与之形成鲜明对比的是,深度学习NLP遵循的分布式语义(distributional semantics),也就是单词的语义可以由其出现的语境所决定。Manning认为两者可以统一起来,用他的原话来说,就是:
Meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms.
用对语言形式之间的连接来衡量语义的话,现在的大模型对语言的理解已经做的很好了。但目前的局限性在于,这种理解仍然缺乏世界知识,也需要用其他模态的感知来增强,毕竟用语言对图像和声音等的描述,远不如这些信号本身来的直接。这也正是很多大模型的改进方向。
-
大模型的未来
大模型在语言理解任务的成功,以及向其他数据模态,比如图像、知识、生物信息等的拓展巨大的前景指向了一个更通用的方向。在这个方向上,Manning本人也参与提出了近期大火的foundation model(基础模型)的概念。
基础模型是指百万以上参数,通过自监督学习在预料上训练的,可以轻松适配到多种下游任务的大模型(Bommasani et al., 2021)。BERT和GPT-3就是典型的例子,但最近在两个方向上涌现出不少的拓展性工作:
-
大模型连接知识,无论是以连接知识图谱神经网络,还是实时搜索文本知识的形式。
-
多模态的foundation model,比如DALL·E模型,这个方向也更激动人心。
Foundation model仍然在早期,但Manning描绘了一个可能的未来:
Most information processing and analysis tasks, and perhaps even things like robotic control, will be handled by a specialization of one of a relatively small number of foundation models.
These models will be expensive and time-consuming to train, but adapting them to different tasks will be quite easy; indeed, one might be able to do it simply with natural language instructions.
AI模型收敛到少数几个大模型会带来伦理上的风险。但是大模型这种将海量数据中学来的知识应用到多种多样任务上的能力,在历史上第一次地非常地接近了(通用)AI的目标:对单一的机器模型发出简单的指令就做到各种各样的事情。
这类大模型可能只拥有非常局限的逻辑推理能力,但是大模型的有效性会让它们得到非常广泛的部署,在未来数十年它们会让人们领略通用人工智能的一瞥。
Reference
from https://mp.weixin.qq.com/s/pnd2Q-5duMtL0OLzrDJ2JA
【相关】
斯坦福教授曼宁AAAS特刊发文:大模型已成突破,展望通用人工智能
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)