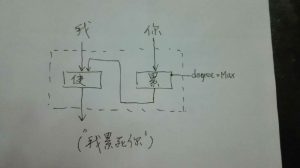
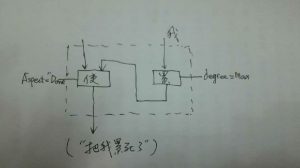
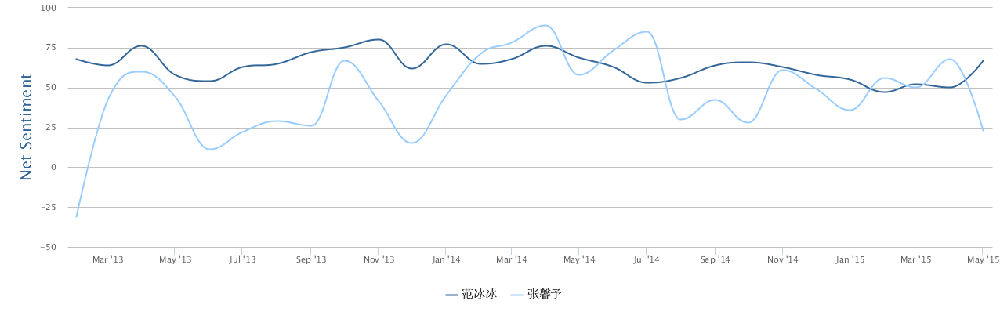
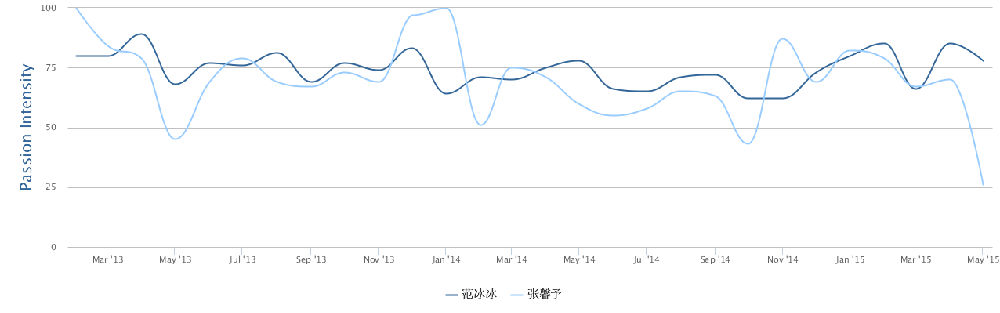
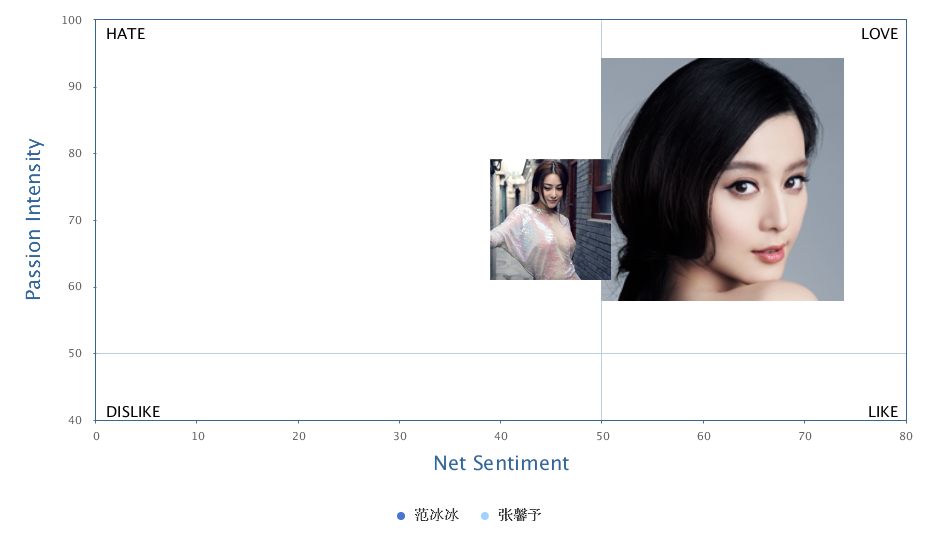
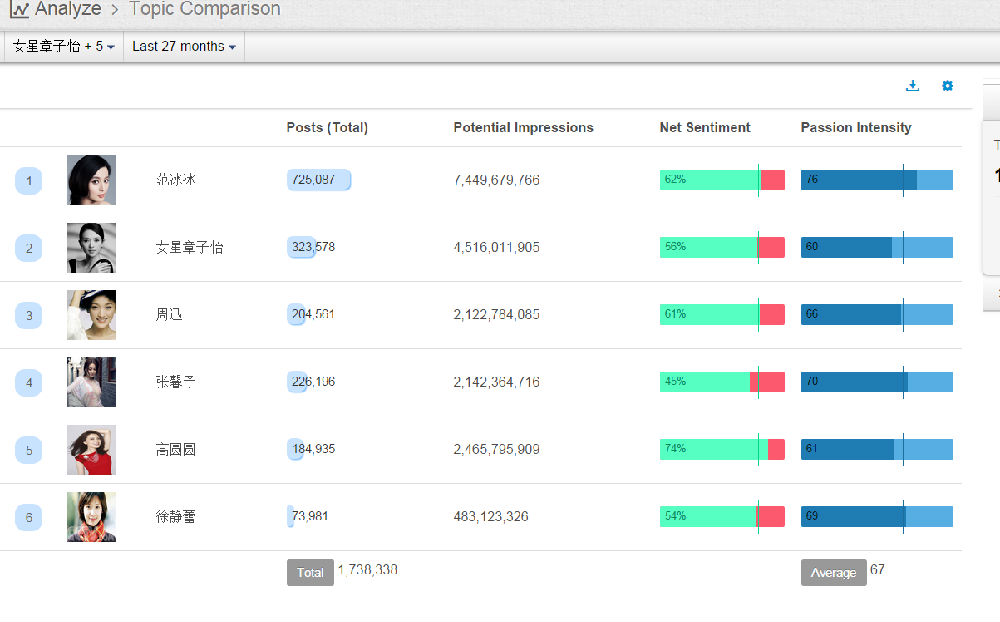
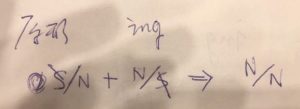我: 汉语的裸体准成语:你不理财,财不理你。穿上小词的衣服就是:你(如果)不理财,财(就)不理你:如果 ... 就...。也可以穿戴更多一点:(如果)你不理财(的话),(那么)财(就)不(会)理你:如果 ... 的话 / 如果 ... 那么 ... 等。)穿得越多,越没有歧义,越容易理解,当然也越容易电脑处理。可是国人觉得那样不简约,不能显示我语之性感。
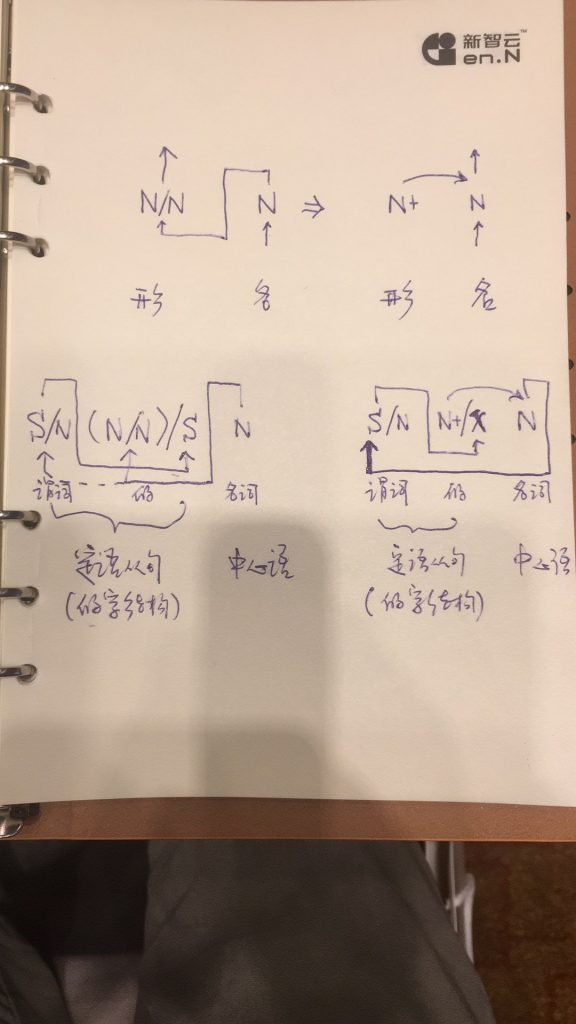
现代汉语的框式结构是非常漂亮的小词结构,漂亮在它不仅给了左括号,也没忘记右括号,这样一来,边界歧义的问题就消弭了。这个框式手段,是比西方语言更高明的显性形式,应予大力推广,以彰显我语严谨的一面。框式结构更多的例子有:因为 ... 所以;虽然 ... 但是;在 ... 中/上/下/间。
顾: 英语也有省略小词: no pain, no gain.
我: 语言是线性表达,因此常常有边界不清晰的问题存在。数学语言(譬如公式)也是线性的,想到的办法就是括号。汉语不知道哪个年代发明的这个框式手段,基本就是括号的意思。这个很高明。
顾: 而且似乎某些高能人群倾向于省略小词。例如华尔街投行和硅谷人士的某些交流中,如果小词太多反而被鄙视,被认为不简洁不性感,这大概是人性,不是中国独有。举一例,出自Liar's Poker, 某trader跳槽,老板以忠诚挽留,他回答,
“You want loyalty, hire a cocker spaniel”
我: 有了框式结构,语言不仅清晰了,而且灵活了。灵活是因为左右括号如此明晰,以致于可以放宽括号内成分的句法条件。
Nick: 可以处理括号的都是什么自动机?我理论忘光了。
我:多层括号需要的是中心递归,就是乔姆斯基的 CFG,有限状态不能对付n层括号。上面的汉语案例大多只使用单层括号,没有用到括号的嵌套("如果...的话" 与 “如果......那么”可以算有了一层嵌套,左括号共用一个小词“如果”,右括号不同,可以放在两个模块层去做),不需要栈结构,不需要递归和回溯。
白: 有限状态加计数器,是毛毛虫,可以对付括号,保证线速。
顾: 注意这里主从句之间是逗号,不是问号。我刚才特定去书里查对了没错。
RW: long time no see 是华尔街英语的典范!
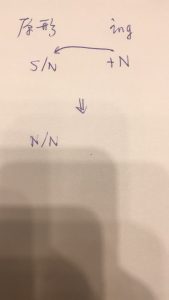
我: 成语不怕,成语都是可枚举的、有限的,就是个存贮记忆问题。成语的极致就是编码,包括密电码,acronyms 如 IBM,ABC 就是密码式成语。成语是NLP中不用讨论的话题。可以讨论的是,产生式“类成语”,譬如“一X就Y”(如 一抓就灵,一放就乱), "不X不Y"(如,不见不散,不服不行)。这个有点讨厌,因为词典对付不了,可是又不符合一般的句法,通常用词驱动小的规则来对付。(小规则是大规则的例外。)
顾: 但某些高能人群,尤其是科学家和教授,尤其是在思辨场合下,小词就少有省略。而汉语在写数学教材时,也多用小词。因此是否用小词跟语言用途也有关,愚以为不能否认汉语追求简洁优美是弱点,也不能认为汉语不善加小词或准确表达概念和逻辑。
我: 还是有个程度吧,汉语小词常可省略,总体上就是一个爱裸奔的东方美女。
顾: 偶爱裸体美女。
我: 偶也爱裸女,东方的尤甚,因为亲切,可是 ...... 欧化句式侵入后,白话文运动以来,可以看到一种加小词的趋向,小词在汉语发展道路上开始产生影响了。是吃了伊甸园的智慧树的果子知羞了?
顾: long time no see 据认为是汉语入侵英语之后产生的,只是大家觉得自然,英美人也用了。这个语句困扰我很久,在网上查了据说是如此,但未必是严肃考证。
我: long time no see 是最直接的展示我东方裸体美女的一个案例。西人突然悟过来,原来语言可以如此简洁,这样地不遮不掩啊。他们觉得可以接受,是因为赶巧这对应了一个常用的语用(pragmatic)场景,朋友见面时候的套话之一,不分中外。在有语用的帮助下,句法可以马虎一些,这也是这类新成语(熟语)形成的背后理由。
RW: 我只在老外和中国人打招呼时听他们说过,没见过他们互相之间用过。因此,我觉得他们没有接受这是一个常规用法。
顾: 另外,我觉得如果要分析理解语言,也不能拘泥于句子结构。句子之间的含义同样重要,如果过于依赖小词,可能难以将句中和句间的关联统一理解。而如果看句子之间的联系理解,英文在句间小词也很少用。
我: 用语义(隐性形式)当然好,但是不容易写一个形式化的系统去 parse 啊。用小词(显性形式)的话,那就好办多了。
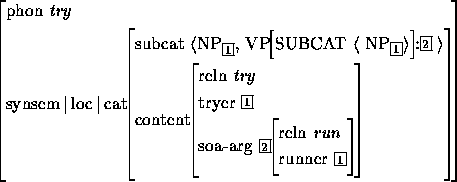
白: 伟哥还是说说“我是县长”是怎么hold住的吧。问题的实质是,有限状态自动机没有lookahead 能力,如果语义跟着同步走,有很多构造(合一)会是明显浪费的。
Nick: @wei 白老师问:"我是县长派来的"
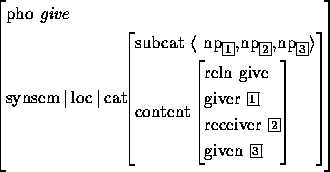
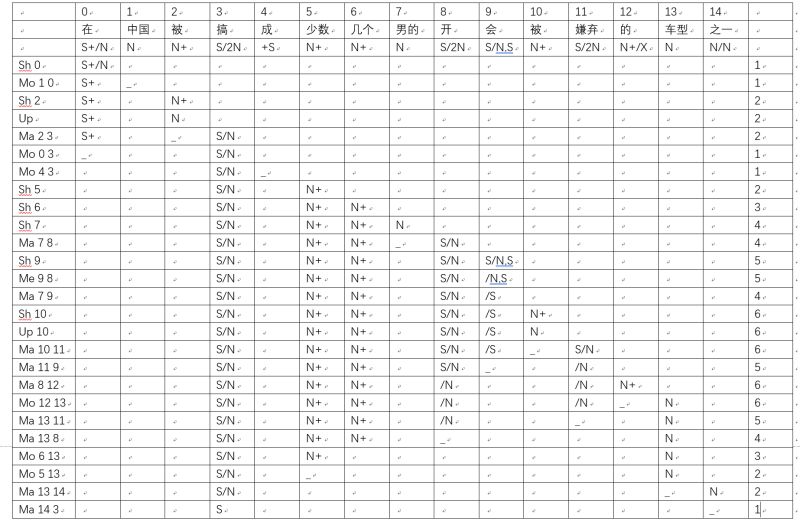
我: “的字结构”很讨厌。大体上就是英语的 what-clause 对应的句法形式。但比 what-clause 还难缠,因为该死 “的” 字太 overloaded 了。
雷: 中心嵌套也可以是线性的?
白: 某些可以是,全集不是。比如,a^nb^n,可以线性parse。
我: 当然可以线性,除非嵌套是无限层。如果是无限层,栈也要溢出的,无论memory多大。中心嵌套本质上不是 “人话”,这个我和白老师有共识。乔姆斯基之谬,以此为最。
雷: 问题是有些text有冷不丁的多层。有些国内的新闻稿有。
我: 举例,看是人话还是数学?
雷: 当然我们可以排除这些极少数。有些翻译有。
我: 用递归回溯对付嵌套,不过是理论上的漂亮,没有多少实践的意义。
白: 记得everybody likes somebody转换成否定式很难搞。基本归到不是人话一类。
我: 不是人话,就不理睬它!语言中要抓的现象那么多,什么时候能轮到中心嵌套?
白: “我是县长派来的”,是人话,还没揭锅呢
我: I am the one who was sent by the county mayor,这大体是对应的英语吧。英语的 what-clause 只能用于物,不能用于人。“苹果是县长送来的”,the apple is what the county mayor sent
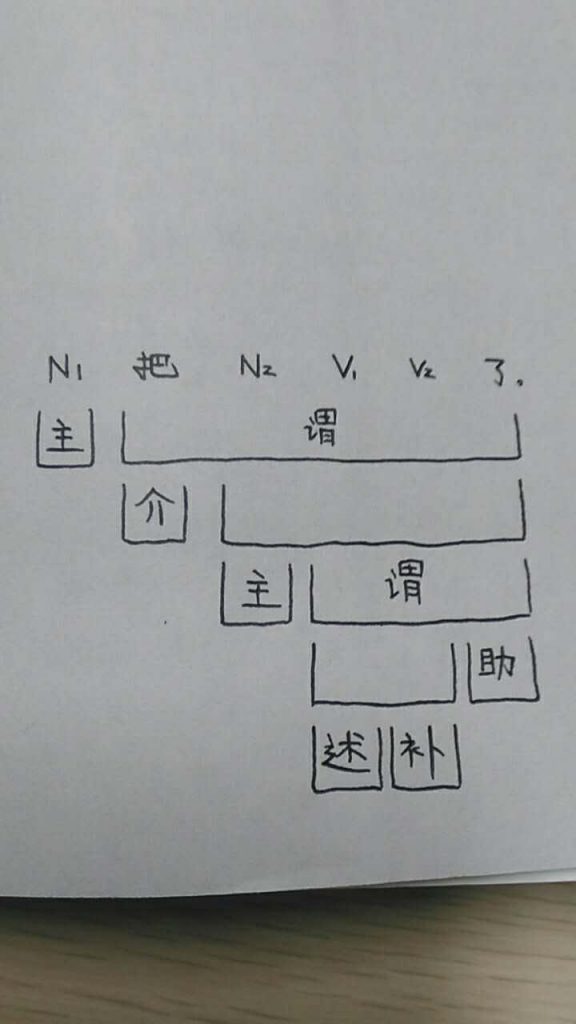
白: 我的问题不是翻译,是有限状态木有lookahead能力,局部生成“我是县长”的问题咋避免。
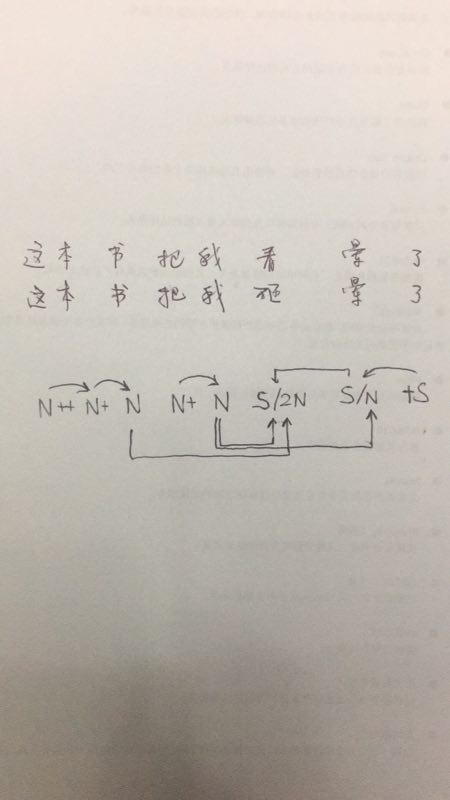
我: 避免不难。不过就是加大规则的长度而已。有限状态的规则可以任意加长后条件(post-condition)。至于前条件(precondition)比较麻烦,因为前条件改变了 matching 的起点,容易乱套。
白: 短的规则还在啊。根据哪一条,长的压制短的?
我: 对,叫 longest principle,这是所有matching的基本原则,无论是词典查询还是模式匹配。有两个方法来用后条件:(1)加长后条件,以确保 pattern 本身是要抓取的对象,譬如第一近似就是 check 县长后面不是动词。(2)加长后条件来排除例外:这样的规则是没有结论的规则,就是为了排除例外的。这样一来,下一条短规则就可以成功,而且没有误抓的困恼了。
白: 除非你那已经不是纯FSA了。纯FSA只看当前吃进字符做决策。往后check就相当于LR(k)了。
我: 我的 FSA 从来不是纯的,是 FSA++。这个昨天就说过的,我随时要求我的工程师去对这个 formalism 做各种扩展,直到他们抱怨影响了线性速度为止。
白: 那就不奇怪了。
我: 在做 NLP 平台过程中,会有很多的扩展才好应对自然语言parsing的需要。很多人以为一个标准的 formalism 拿来用就好了,那哪行?也因此,编译器只能是内部自己实现(built in house),而不能使用 off-shelf 的,因为后者你根本无法扩充,也难以优化速度。
雷: LR或RR都是线性的。
白: 对。我还以为发生奇迹了呢。
我: 不是奇迹么?抓到老鼠就是奇迹。
白:套用一句潮话:这不科学呀。
我: 如果标准的 formalism 不能碰的话,那么有经验的设计师与一个新毕业生比,就没有任何优势了。我们说生姜老的辣,就是因为老生姜可以很容易把经验的需要转化成软件的 specs,而新手搞不清如何去定义。白老师,“这不科学啊” 的批评声音我常听到。一个是来自我太太,在日常生活中,她一个本科生经常对我这个首席(科学家)呵斥,你一点不讲科学!另一个是来自我一个短暂时期的老板,这个老板是学界主流,她看我写的 proposal,说这里面缺乏 science。我心里说,邓小平也没有 science,他不是把一个大国也治理了,烹小鲜而已。
白: 白猫黑猫拿到耗子都是科学的,狗拿到耗子就略微那个了点,所以澄清不是狗拿的还是很有必要的。
雷: @wei 白老师追求的是形式美。你的是工程美。两者一直你拖我拉的往前走。
我: 狗啊猫啊,是主观定位,无所谓呀,FSA,还是 FSA++,标签而已。我看自然语言是俯视的,成了习惯。太阳底下没有新鲜事儿,因为见到的语言现象太多了。
白: 总是要交流的呀。
我: 当然,也不能乱来,前提是任何"不科学"的扩展,不能最后引致灾难:一个是速度的灾难。一个是不可维护、不可持续发展的灾难。如果这两点可以掌控,就问题不大了。对速度我很敏感,愿意为此自我束缚手脚,只要证明某个扩展影响了线性速度的本性,我就投降,然后选择折衷方案。
雷: 抛弃中心嵌套,cfg就是线性的。
我: cfg 的痛点还不是中心嵌套导致的速度问题,根本缺陷在单层,眉毛鼻子一把抓,不分共性与个性,这才是致命的。
白: 我天天玩工程,不过我们的工程师如果突然说他使用了某个形式化机制但其实不纯粹,我还是会跟他较真的。狗肉好吃,不能成为挂羊头的理由。
Nick: 赞同白老师。spagetti对大工程不行。
我: 你们是主流,站着说话不腰疼。不挂羊头, 语言学家早死绝了。我17个政府项目全部是挂羊头得到的。
Nick: 伟哥可能有绝活,不愿说。
我: 绝活有,细节不谈,谈原则。原则就是,你要做精算师或工程师的老板,而不是相反。绝大多数语言学家没这个底气,只能打下手,做资料员。
雷: nlp的难点或苦活不在parsing,而是知识工程方面的整合。
白: 上下通气。
雷: 呵呵,形象。
白: 米国股市里有知识工程概念股么?
顾: 这是大数据啊!Data Thinker可以。。。(此处省略一千字)
Nick: 中国有?
白: 木有。讯飞在往这方面发展,但眼下不是。
我: 挂羊头卖狗肉的故事在这里:《在美国写基金申请的酸甜苦辣》。Quote:
说到含金量,其实很多课题,特别是面向应用的课题,并不是什么高精尖的火箭技术(not rocket science),不可能要求一个申请预示某种突破。撰写申请的人是游说方,有责任 highlight 自己的提议里面的亮点,谈方案远景的时候少不了这个突破那个革命的说辞,多少迎合了政府主管部门好大喜功的心态,但实际上很少有多少研究项目会包含那么多闪光的思想和科学研究的革命性转变。(纯科学的研究,突破也不多吧,更何况应用型研究。)应用领域“奇迹”的发生往往植根于细节的积累(所谓 the Devil is in the details),而不是原理上的突破。而对于问题领域的细节,我是有把握的。这是我的长处,也是我提出科研方案比较让人信服的原因。有的时候,不得不有迎合“时尚”的考量,譬如领域里正流行 bootstrapping 等机器自学习的算法,虽然很不成熟,难以解决实际问题,但是基金报告列上它对申请的批准是有益的。不用担心所提议的听上去时尚的方案最后不工作,由于科研的探索性质,最终的解决方案完全可以是另一种路子。说直白了就是,挂羊头卖狗肉不是诚实的科研态度,但是羊头狗头都挂上以后再卖狗肉就没有问题。绝不可以一棵树上吊死。
我: 不挂羊头,必死无疑,生存之道决定的。同意雷司令 parsing 问题解决后,真正的关键在挖掘(知识工程)以及最终建立预测模型。
白:NLP应用场景是很考验想象力的。
我: 非结构数据突然结构化了。面对结构的海洋,传统的数据挖掘需要拓展才好应对。挖掘目前做得很浅,就是 retrieval 里面的一个小东西,凑合事儿。parsing 是见树,mining 才见林。以前没有条件见林子 mining 没有实验基地,限制了它的发展和深入。如今不同了。
昨天与xiaoyun还谈到这个,我们都觉得,哪怕只利用 parsing 的一个部分,譬如只做SVO(主谓宾),理论上也是对所有现存关键词技术所驱动的应用的一个颠覆,因为突然多了一个维度。以前所做的不过是 baseline 而已,如今只要有大数据、大计算、大存储,再加上mining,那么凡是关键词技术生存的地方都可以革命,包括搜索、分类、聚合为基础的等等的应用。这个总体趋向是明晰的,条件也基本成熟,现在是考验想象力的时候,然后就是脚踏实地一个应用一个应用的去做
白: 还是要想新的商业模式,革关键词的命,从商业角度未必成立。关键词是拿来卖的,你把人命革了,卖什么?总要有个替代品吧,总不会卖FSA吧。
我: 革命不是杀头,parsing 对关键词,就是爱因斯坦对牛顿。到了语义语用层,关键词,或者叫驱动词(driving words),也是不可或缺的。
Nick: 卖regex到也不见得不可能。
我: 抽取挖掘搜索,往往需要两条腿,一条是关键词,另一条就是结构。如果 regex 可以卖了,离开直接卖 parse 就不远了。
其实我们的 power users 已经开始要求直接用简化的 parse 去满足他的信息需求了。用户是可以训练出来的。我们整整一代人都被关键词训练过、洗脑过了。以致于当自然语言接口技术刚刚尝试的时候,不少用户抱怨说:关键词多简单,跟机器说话,要自然语言干嘛?Power users 在简单的关键词之上用 boolean query 的很多,有些 query 看上去又臭又长又难看,不也忍受了。也见到过创业者,就是用 domain ontology 加上 keyword boolean 作为技术基础,也满足了一个 niche market 的需求而生存的。
Nick: 这是说的哪家公司?
我: 两年前在北京调研时候遇到的,名字忘记了。他们一点也不保守,把 query 直接给我们看,我心想这是一目了然啊,很容易复制的。可贵的是,他们先一步找到了那个市场需求,定义了那个 niche market,也找到了客户,后去就是那些 queries 的库不断更新维护而已。
我: @Nick 说,spagetti对大工程不行。Google 搜索是大工程吧,看一下里面的 spagetti: http://blog.sciencenet.cn/blog-362400-804469.html
原载:《泥沙龙笔记:铿锵众人行,parsing 可以颠覆关键词吗?》
【相关】