*Edited transcript from InfoQ's second DeepSeek series livestream featuring Dr. Wei Li, former VP of Engineering at Mobvoi's Large Language Model team, discussing R1 Zero's innovative contribution to democratizing reasoning models.*
DeepSeek's Greatest Achievement: Making Everything Transparent
InfoQ: "DeepSeek adheres to a pure reinforcement learning approach, but the industry often refers to RL as 'alchemy' - how did they make this process controllable and accessible? What's innovative about their reasoning paradigm?"
Dr. Li:** The reinforcement learning for reasoning models has long been an industry challenge. About six months ago, when Ilya and others declared the end of the pre-training era, it signaled that simply scaling up pre-trained models was no longer sufficient for performance improvements. The delayed release of GPT-5 is another indicator of pre-training's decline. As a result, the industry began seeking new growth paths, with on-the-fly reasoning models gaining momentum among leading teams until OpenAI released O1, the world's first reasoning large language model. DeepSeek's R1 then followed with its breakthrough success.
From the mysterious Q-Star project (reportedly causing dramatic internal conflicts at OpenAI) to the release of O1, reasoning models have been widely recognized as a new paradigm in AI. The core of this paradigm is enabling models' "slow thinking" capability, or System 2 as it is called, using reinforcement learning to enhance model intelligence in complex tasks. However, all of this was closed-source. OpenAI even deliberately created mystique around their chain-of-thought content. Apart from a few top players like Google and Anthropic quietly exploring and tracking this field, other teams knew very little about it.
DeepSeek's greatest achievement lies in making everything about LLMs transparent. They open-sourced their models and detailed technical papers, and weren't afraid to expose their thought of chains (CoTs) in the system. Through pure reinforcement learning, they proved that even without process control data, result-based control alone could achieve top-tier reasoning model performance. This breakthrough was like piercing through a paper window, showing the industry a feasible path to democratizing reinforcement learning.
InfoQ: The innovation in reasoning paradigm sounds abstract. Could you provide an example?
Dr. Li:** R1's paper is outstanding, arguably one of the finest in the large model field. It consists of two parts: one focusing on Zero research, which presents remarkable achievements in pure reinforcement learning for reasoning; the other detailing the practical R1 system, a top-tier production reasoning model. For R1's development, they considered practicality, balancing comprehensive performance, safety, and various practical considerations, detailing a four-stage training pipeline as best practice to help other teams understand and replicate their success.
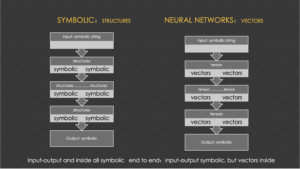
The most brilliant part is the Zero research. Zero proved a revolutionary point: contrary to traditional beliefs (or OpenAI's implied stance that reasoning requires step-by-step supervision), process supervision isn't actually necessary. Using only the final result against the "gold standard" as a supervision signal is sufficient to train the "slow thinking" process required for reasoning models.
This is Zero's greatest highlight and the origin of its name - it draws inspiration from AlphaZero's spirit. AlphaZero historically pioneered complete independence from human game records or experience, achieving zero human supervision reinforcement learning through self-play generated process data (state+move+score triplets). Similarly, DeepSeek's Zero research demonstrates that in reasoning tasks, models can autonomously generate internal process data - Chain of Thought (CoT) sequences - without human annotation.
Specifically, reasoning models initially focused on mathematics and coding because these domains have standard answers. Macroscopically, this is typical end-to-end supervised learning, as both input (math/coding problems) and output (answers/execution results) are fixed and known. However, the process from input to output is highly complex with significant information gaps, requiring a CoT bridge. Just as humans need to break down problems and think step by step when facing difficulties, models need this process too. DeepSeek's research found that models possess the ability to learn this deep thinking process autonomously if given sufficient time and space.
InfoQ: Dynamic reasoning paths sound like AI "drawing mind maps" - but how do you prevent it from going off track? Like suddenly writing poetry while coding?
Dr. Li:** Based on current evidence, this possibility is virtually non-existent or negligibly low. Before DeepSeek published their results and research details, many were puzzled about this point: wouldn't deep thinking go haywire with only result supervision and no process supervision? Without large-scale reinforcement learning experiments, this was indeed a significant concern. It's like flying a kite - you're holding just one string while letting it soar freely, worried it might nosedive.
These concerns proved unnecessary. The reason it doesn't go off track is that all this reasoning reinforcement learning, including self-generated reasoning CoTs, is built upon existing top-tier models (like V3). These models have already mastered coherent expression through massive data learning. This coherence implies orderliness, which, while not equivalent to pure logic, prevents completely unreasonable deviations. It is observed that fluent human speech typically reflects organized thinking.
InfoQ: On another note, compared to OpenAI's O1, DeepSeek R1 has another notable highlight in applying reasoning CoTs to language generation and style imitation. Could you elaborate on this?
Dr. Li:** When O1 was released, everyone knew it demonstrated significant improvements in mathematics and coding abilities, as standard tests revealed higher performance levels. What people didn't realize was that this reasoning ability, or "slow thinking" capability, excels not only in domains requiring strict logical reasoning but can also shine in traditional language tasks.
By nature, language ability has been a strength of large models - everyone knows they generate very fluent text, more native than natives. By the time we reached models like 4o or V3, their writing was already quite smooth, seemingly leaving little room for improvement. However, when asked to write classical poetry or imitate Lu Xun's writing style, previous models fell short. R1 solved these challenges. From a social impact perspective, this is actually quite remarkable and particularly noticeable.
Honestly, not many people are deeply concerned about mathematics or coding, although we know coding is a major direction for the coming years and automated programming can change the world. Everything in IT ultimately comes down to software; the digital world is built on software. If software development can transition from manual coding to model-assisted or even model-autonomous programming, this will greatly increase productivity. While this is visible to all, it's not as intuitive for ordinary people who more often face tasks like writing compelling articles.
When R1's humanities capabilities were discovered, not just geeks or software developers saw the benefits of reasoning models - ordinary people were excited too. Suddenly, anyone could claim to be a poet, writer, advisor or philosopher - the impact was tremendous. This wasn't felt with o1, perhaps because OpenAI didn't realize or at least didn't focus on this aspect of reasoning models. But while working on code and mathematical reasoning, DeepSeek must have internally realized that this "slow thinking" mechanism could also significantly improve writing abilities, especially in classical Chinese.
Everyone knows Chinese data isn't as rich as English data, so while previous models could write beautiful English poetry, they struggled with Tang poetry. This might be because Chinese data was insufficient in quantity or quality, preventing models from learning adequately. We always felt this was unfortunate - models would sometimes rhyme correctly, sometimes not, sometimes add or miss characters, not to mention tonal patterns to follow. DeepSeek clearly put effort into this area; their data quality must be significantly higher than industry standards. More significantly, they know how to transfer the CoT ability from science and technology to language and literature.
InfoQ: If you were to recommend a DeepSeek module most worth replicating for programmers, which would it be? Like those "Aha moments" claiming to replicate R1 for tens of dollars?
Dr. Li:** If I were to recommend a DeepSeek module most worth replicating for the programming community, it would be the Zero research-related components. This replication isn't about achieving comprehensive capabilities but rather verifying Zero research's key revelation - that machines can indeed autonomously learn. This is what OpenAI kept under wraps; perhaps they had figured it out earlier but chose not to disclose it.
Now, we've seen quite a number of different teams claimed to have reproduced R1's reflective capabilities with minimal resources. This isn't just an interesting experiment; more crucially, it marks the democratization of reasoning models. Previously, people didn't understand how reasoning models worked, only knowing that vast amounts of process data were needed for models to learn slow thinking. This was considered an almost insurmountable barrier because process data is hard to obtain, and reinforcement learning's instability and high data requirements confused and challenged many programmers.
But now, we know we can bypass this most difficult process data requirement and reproduce this "Aha moment" with limited resources, proving that slow-thinking capabilities can be learned autonomously by models. Based on this premise, if you're a domain expert, you might wonder: could these techniques achieve significant improvements in your field? This is entirely possible. Even the most powerful models (like V3 or 4o) only achieve 60-70% accuracy in specific scenarios without optimization, and experience tells us that without at least 80-85% accuracy, you can't launch a truly valuable system in real-life applications.
That is to say, between a large model's out-of-box results and actual valuable application deployment, there's a gap. Previously, our only method was collecting domain data for fine-tuning (SFT). Now, we have another path RL: following the reasoning model approach, letting systems fully utilize slow thinking capabilities during the reasoning phase to improve data quality to acceptable or even exceptional levels. This path seems to have been opened.
However, my programmer friends tell me that in their comparison experiments between fine-tuning (SFT) and DeepSeek-style reinforcement learning (RL), while RL indeed outperforms SFT, the computational cost for RL training is still far higher than SFT. The superior performance makes sense because SFT data is always very limited, while successfully reinforced RL self-generated data can far exceed SFT data volume.
InfoQ: Some say large models represent "brute force aesthetics," but OpenAI's former Chief Scientist and co-founder Ilya says pre-training has reached its limit. How do you view this? Is the emergence of reasoning models just adding another scaling law to brute force aesthetics?
Dr. Li:** This is more about a shift in technical focus and a paradigm change in technical innovation. Large models involve three major components: first, pre-training, which builds foundational capabilities by learning basic patterns from massive data; second, post-training, initially mainly fine-tuning - OpenAI early on used some reinforcement learning (like RLHF) for human preference alignment, but by Meta's time, they even abandoned typical PPO style RLHF for simpler DPO, as they, like many others, struggled with it. Finally, there's the reasoning phase, where models interact with users real-time after deployment.
The current situation with high-quality natural data is that pre-training has nearly exhausted all available quality resources. The industry began to notice data growth challenges, making performance improvements increasingly difficult. GPT-5's delayed release, reportedly yielding limited returns despite massive computational investment, suggests pre-training may have indeed hit a wall.
This led the industry to explore alternative AI growth curves. Reinforcement learning-based reasoning models emerged at center stage in this context: pure reinforcement learning should be added to post-training. Previous reinforcement learning relied on human preferences, but this time it's about giving models more thinking time before reaching answers, learning underlying chain of thought (CoT). While V3 was already doing well, it didn't cause as much social sensation until R1 appeared. DeepSeek truly broke through after the Chinese New Year, becoming the most discussed public topic and causing excitement and shock overseas. R1 and O1 represent a new paradigm. Before R1, only OpenAI's O1 existed as a reasoning model, seemingly unreachably advanced, with would-be-followers unsure how to follow. However, R1 not only reproduced O1's capabilities but did so with greater transparency and clarity. This contrast further highlighted R1's importance as an open-source model leader.
InfoQ: At first glance, DeepSeek seems like an engineering masterpiece. Why did it cause such global sensation? Its user acquisition speed (100 million in a week) surpassed ChatGPT's nuclear moment? What's its historical significance?
Dr. Li:** From my personal experience and observation, ChatGPT's explosion was a landmark event in large model development. Research insiders were following large models before ChatGPT, at least since GPT-3. When GPT-3's Playground appeared, we were already immersed in it, sensing an approaching storm. But from society's perspective, ChatGPT truly shocked everyone, exceeding all expectations, like an AI nuclear explosion.
I believe R1's emergence is the second major shock after ChatGPT. Of course, between ChatGPT and R1, other influential models appeared, like 4o - another remarkable milestone. While ChatGPT 3.5 was already so impressive, 4o proved it could be even better. Then came Sora, bringing shock with video capabilities in multi-modal LLMs. I personally also greatly appreciate Suno, the music model, making me feel like I could become a musician overnight.
If I were to rank them, R1's impact is second only to ChatGPT, perhaps even exceeding 4o and Sora's sensational effects. R1's impact feels similar to ChatGPT's initial appearance, creating the same addiction. While ChatGPT was groundbreaking and R1 a follower, albeit with innovative highlights sometimes surpassing previous models (like in classical poetry and style imitation), achieving such global impact as a follower is truly miraculous.
In terms of practical effects, R1's productization was amazingly successful. Gaining hundreds of millions of users in a week, it far broke ChatGPT's record and elevated society's AI awareness. Furthermore, regarding geopolitical influences on technology access, many domestic users had long desired access to the world's most advanced models like GPT series, Claude, or Gemini but often couldn't reach them. R1's appearance eliminated these concerns about domestic and international restrictions, contributing to its rapid global popularization.
InfoQ: What's your vision of AI programming's ultimate form? Is it programmers telling AI "make me a TikTok," and it outputs deployable code and operations plans?
Dr. Li:** There are always two types of people: skeptics and optimists. People like Ilya believe Artificial General Intelligence (AGI) is imminent and Artificial Super Intelligence (ASI) isn't far away, so the biggest concern now, according to him, is ensuring superintelligence safety.
Anthropic's CEO Dario predicts that within 3-5 years, large models will achieve real breakthroughs - not just the current impressive demonstrations, but revolutionary changes in societal productivity. Fundamentally, they're talking about AI's ability to scale replacement of both physical and intellectual human labor.
However, while large models are buzzing now, their practical applications haven't reached the level of the previous generation's mobile platforms. Previous super apps like Meituan, Didi, Xiaohongshu, and TikTok transformed major aspects of our daily lives, from basic necessities to communication and entertainment, maximally shortening the distance between suppliers and customers - value everyone of us feels daily. While playing with large models is interesting, their practical value at the lifestyle level isn't yet obvious; at best we're still on the verge of the coming AI application explosion.
Notably, DeepSeek's emergence has lowered large model application barriers, paving the way for scaled applications, though we haven't yet entered the era of true application explosion.
What will it look like when AI applications truly explode? I believe the ultimate goal, by nature of AI, is for LLMs to comprehensively replace humans in both intellectual and physical labor. Signs of large models impacting white-collar workers are already undoubtedly evident, with even programmers not an exempt. In physical labor, embodied intelligence is developing rapidly, with both humanoid robots and mechanical hands gradually replacing human physical work.
Of course, this brings side effects, like massive job displacement. How society adapts to this state of greatly developed productivity, but this is another discussion topic. But looking at AI's nature and ultimate goals, AI development could have two milestones: first, when it can replace 50% of human work, allowing half of society to maintain a decent, free life through social programs perhaps like Universal Basic Income (UBI) - this might mark the arrival of AGI (Artificial General Intelligence); second, when it replaces 90% of human work, possibly signifying the emergence of ASI (Artificial Super Intelligence) - a kind of technological utopia (or 'communism') in some sense.
These two milestones are my own verifiable definitions of AGI and ASI. I do not agree with the idea that while old jobs are replaced, more new jobs will be created by AI. It just does not make sense as any new jobs are also a mixture of human labor, destined to be replaced soon by super intelligence if they do emerge for time being.
This vision of AI's future development shows how DeepSeek's innovations in reasoning models might be just the beginning of a much larger transformation in how we think about work, society, and human potential in an AI-driven world.
【相关】