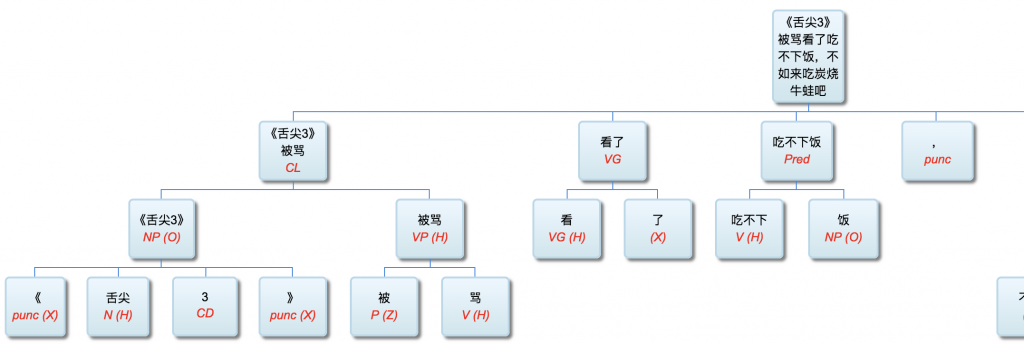
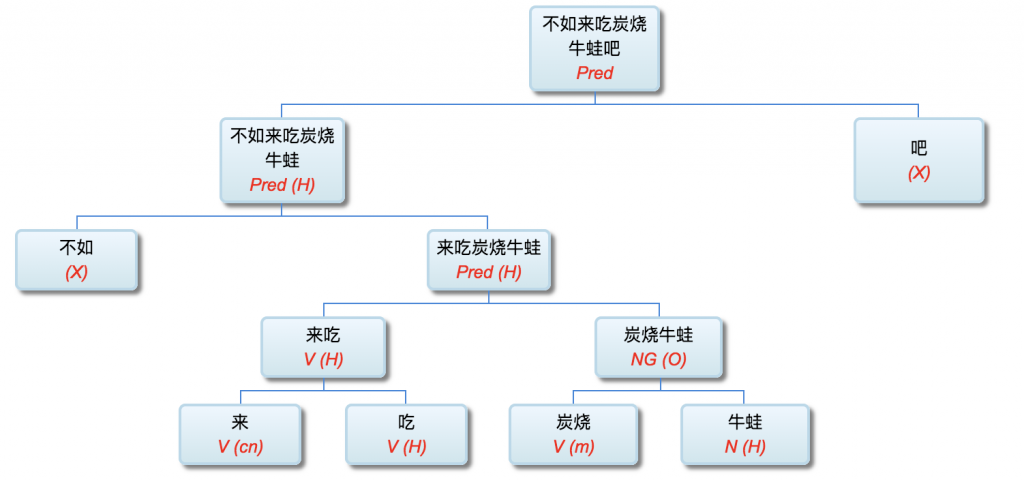
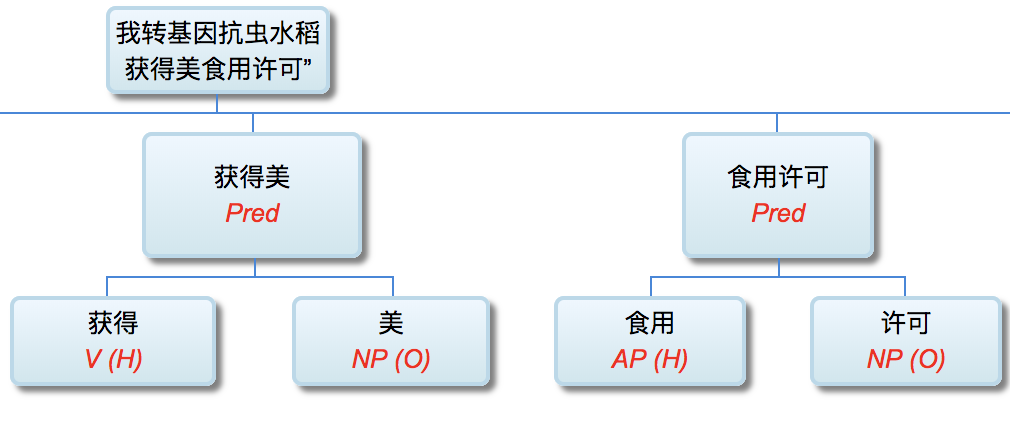
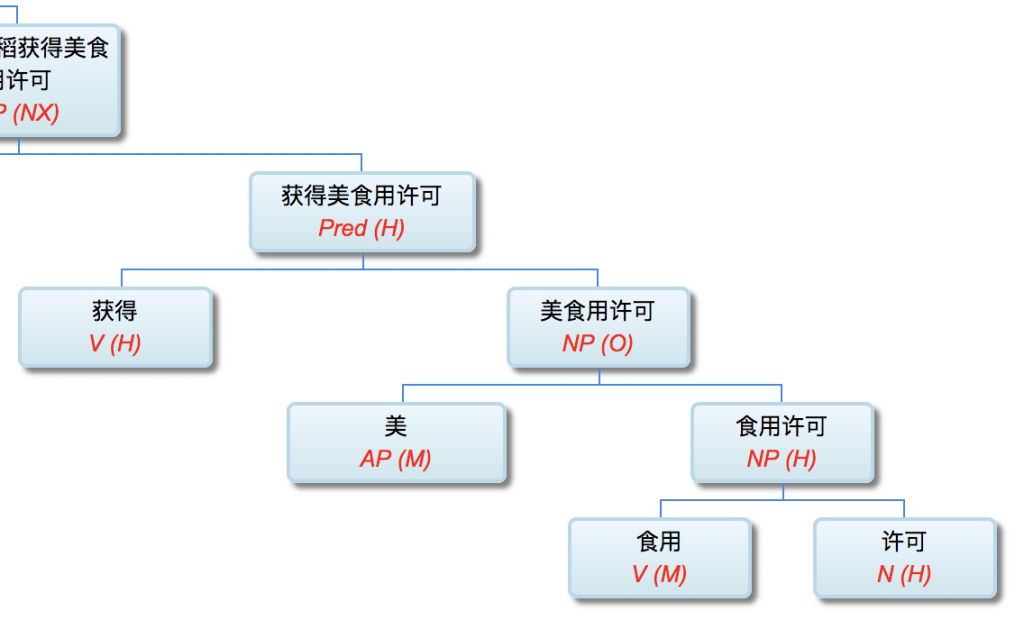
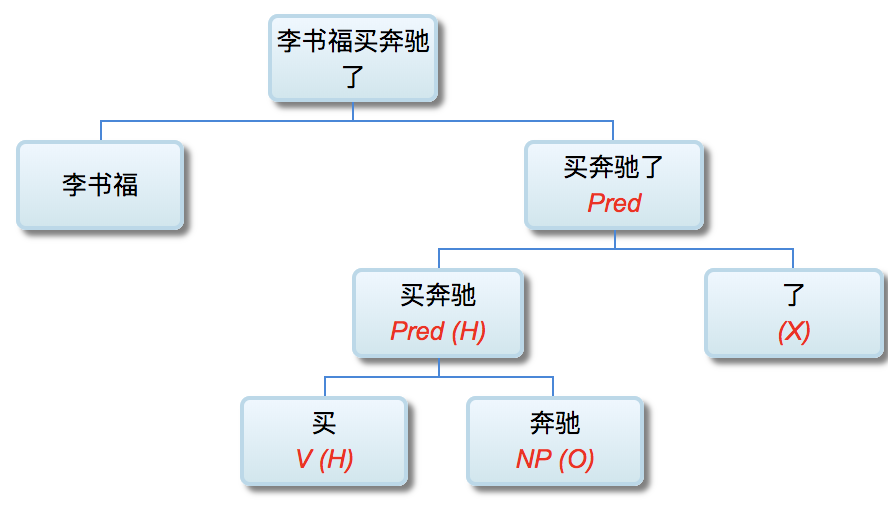
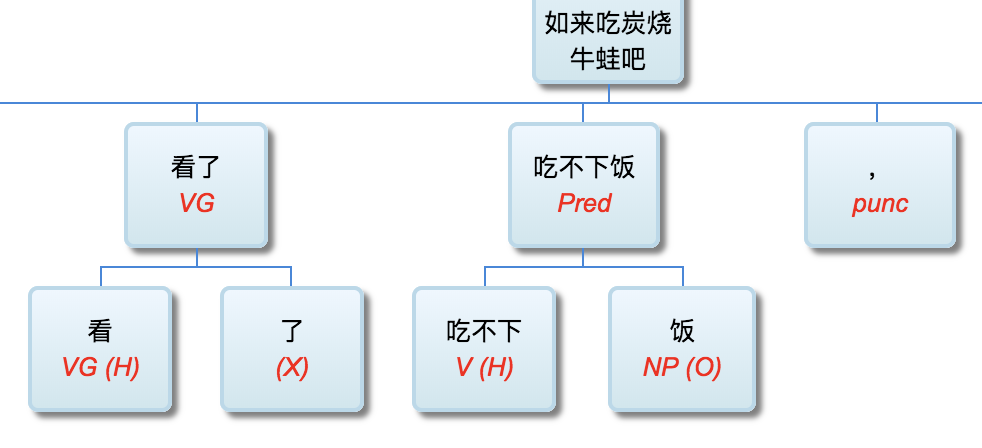
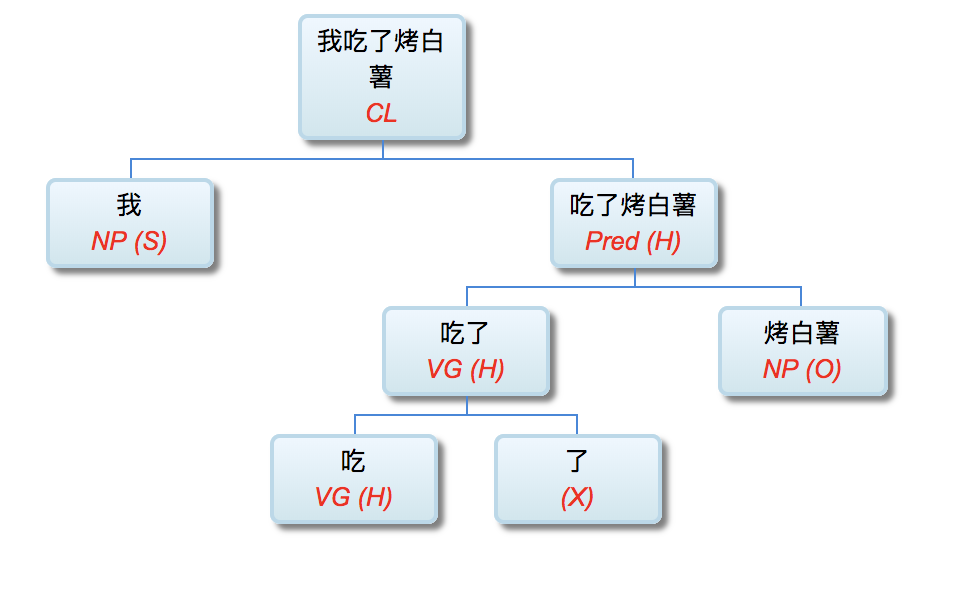
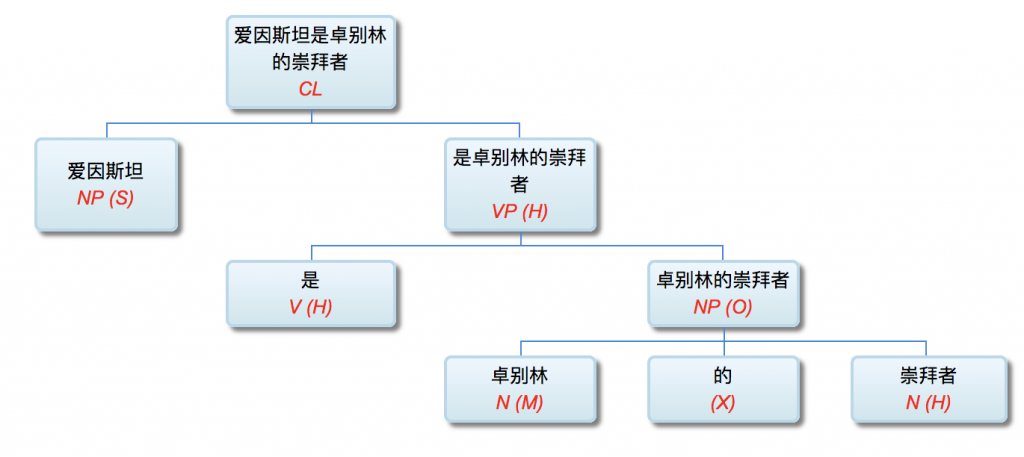
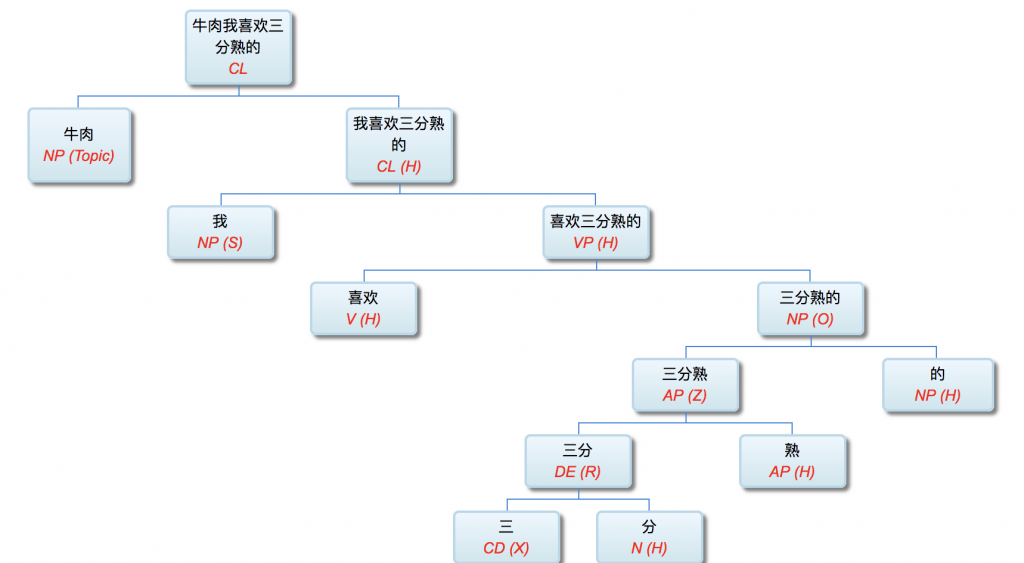
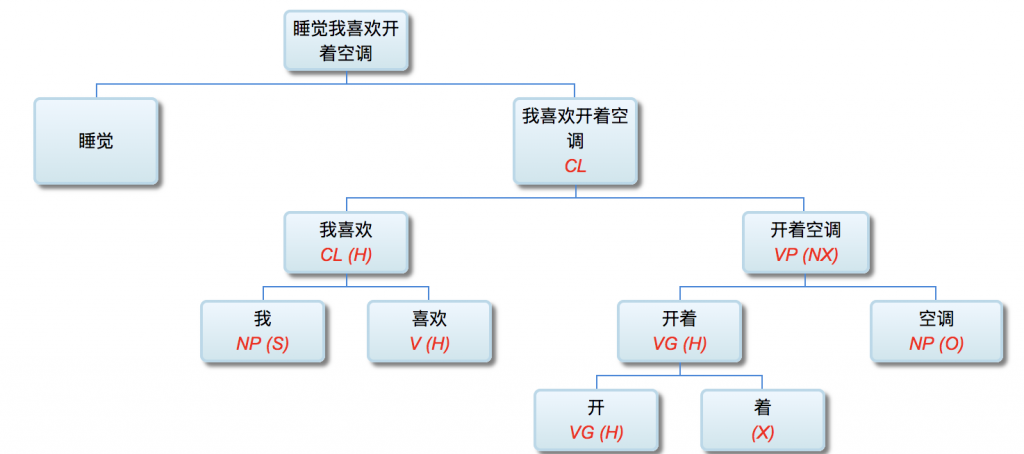
校长:
因为缅因州法条文少了个逗号,牛奶公司吃官司付出500万美金:
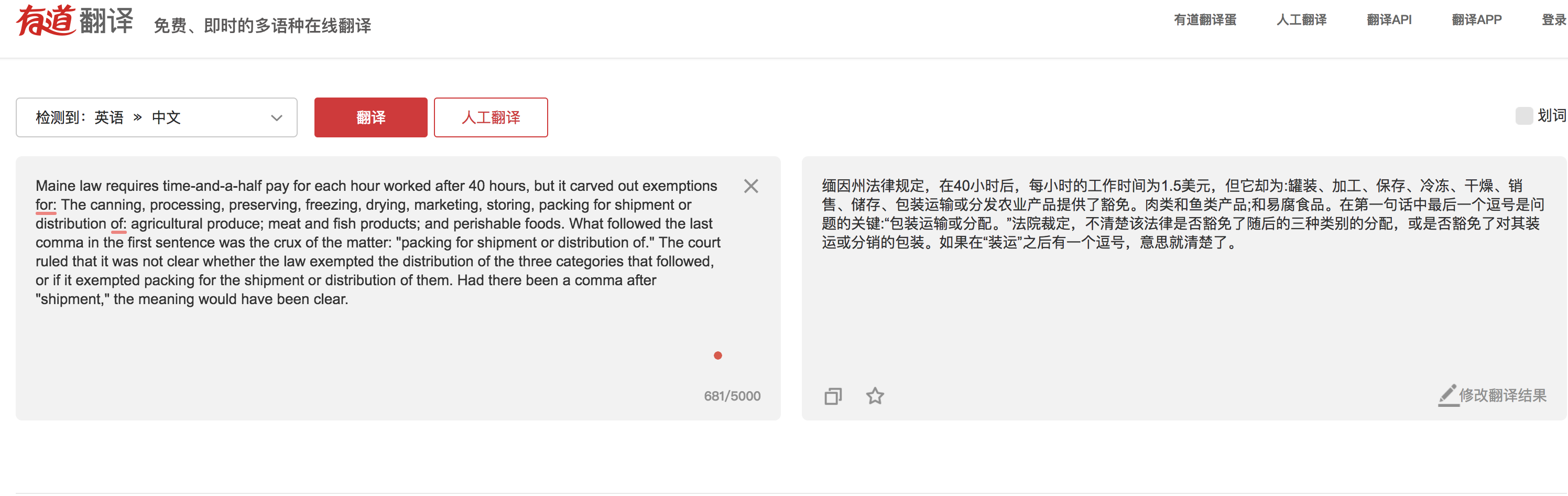
Maine law requires time-and-a-half pay for each hour worked after 40 hours, but it carved out exemptions for: The canning, processing, preserving, freezing, drying, marketing, storing, packing for shipment or distribution of: agricultural produce; meat and fish products; and perishable foods. What followed the last comma in the first sentence was the crux of the matter: "packing for shipment or distribution of." The court ruled that it was not clear whether the law exempted the distribution of the three categories that followed, or if it exempted packing for the shipment or distribution of them. Had there been a comma after "shipment," the meaning would have been clear.
原来我这些年学的都是假英文
不过法庭favor劳工,就已经甩天朝几万条街了。在那片国土,只有高端人口才可以随意耍流氓。。。
李:
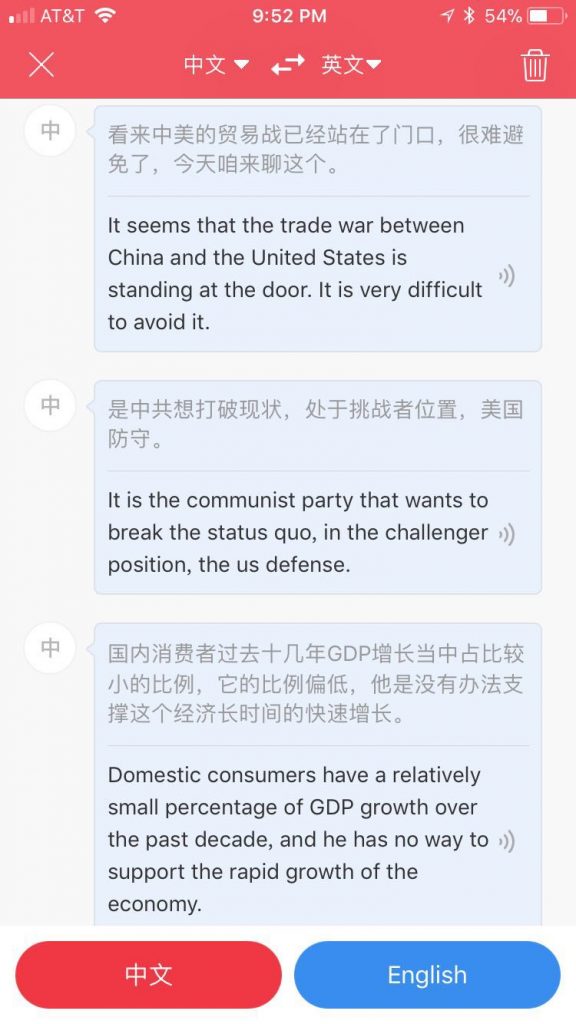
“缅因州法律规定,在40小时后,每小时的工作时间为1.5美元,但它却为:罐装、加工、保存、冷冻、干燥、销售、储存、包装运输或分发农业产品提供了豁免。肉类和鱼类产品;和易腐食品。在第一句话中最后一个逗号是问题的关键:“包装运输或分配。”法院裁定,不清楚该法律是否豁免了随后的三种类别的分配,或是否豁免了对其装运或分销的包装。如果在“装运”之后有一个逗号,意思就清楚了。”
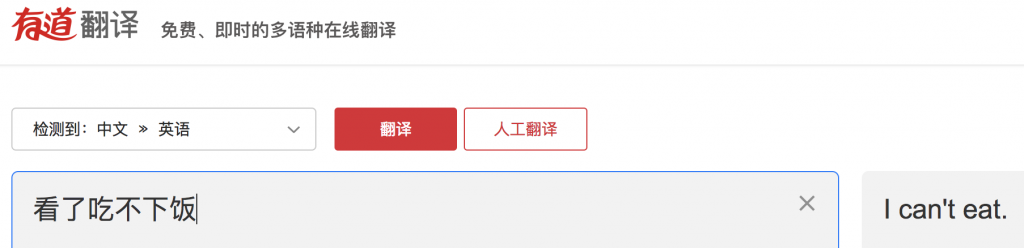
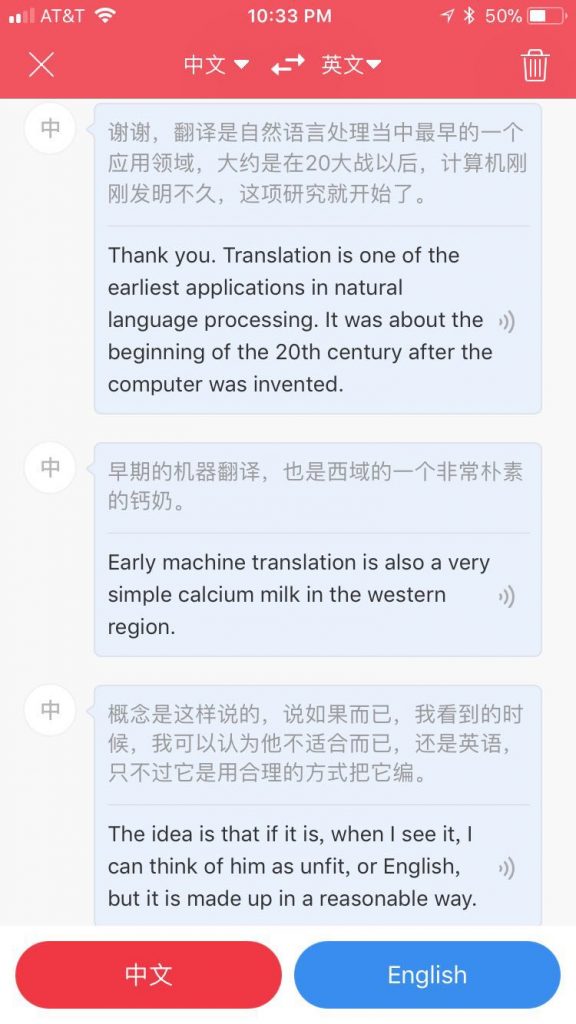
这是有道翻译,比像我这样的英语专业生在时间压力下去翻译这段,要强多了。顺便向有道同人致敬一下,他们超越了名震天下的谷歌翻译。谢谢他们提供的免费服务,我经常用它,其实是愿意付费的。MT 连同互联网,与水和空气一样,成了不值钱的必需品。
“1.5 美元” 是一个巨大的错译,应该是一倍半加班费的意思,神经机器翻译的错译问题已经是一个被反复曝光的痛点,在追求顺畅(达雅)的同时,牺牲了精准(信)。
我是这么看机器翻译走向的:
(1) 机器翻译一定会译错,所以认真使用前需要核对。
(2)核对所花时间 比一切靠人翻译 节省太多人工了。翻译员市场萎缩以后,大批译员会退出,少量留存的是那些知道善用机器的核对员,这个工作不会被取代:核对校订的需求永远存在。
(3) 机器翻译本身在进步,明天的错应该比今天的少。
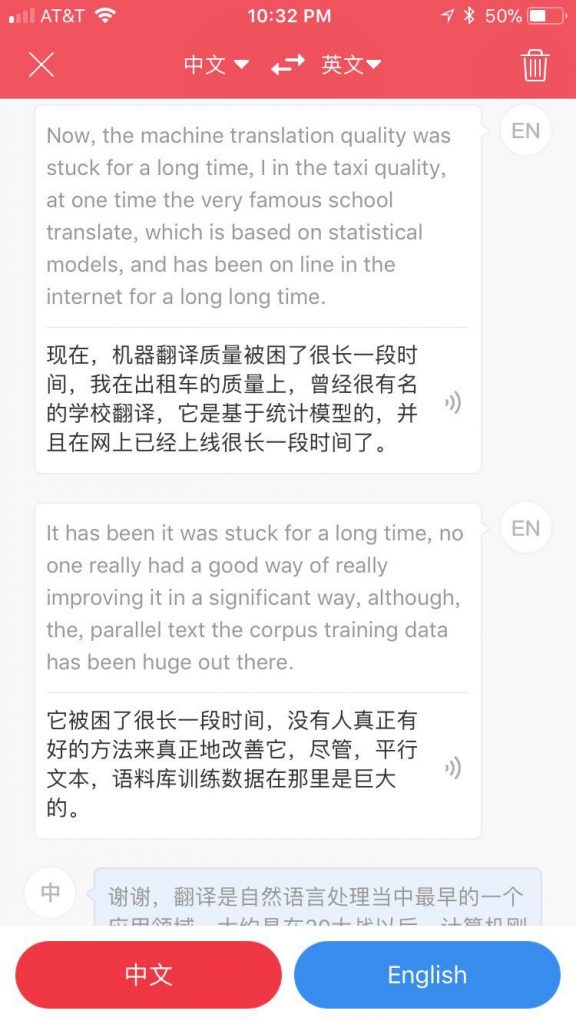
(4)论顺畅 机器越来越赶上或超越人 因为机器是在海量数据里面找 norm,而一个个体,无论学了多少年的外语,都是有限的语言接触,偏离 norm 的可能远大于机器,因此更容易生硬,尤其是在时间压力下。我本人偏好顺畅,更甚于精准,因为翻译错误我一眼可以看出来做译后编辑,但顺畅我老感觉自己还有很多力不从心的时候,需要机器帮助。自己常觉得写不顺,但评判顺不顺还是容易很多。因此,翻译工作先交给机器,然后自己校订,无论纠错,还是找出个别不顺达的细节,都容易很多,因为苦活累活机器做了。
校长:
@wei 有道翻译可以免费用么?amazing!
李:
http://fanyi.youdao.com/
try it yourself
天下真有免费午餐的。
有道的傻瓜式袖珍翻译器 大约100多美元 可以买一台 周游世界的时候用。
校长:
@wei 我靠!你没感受到同行竞争压力?
李:
感到压力的应该是讯飞。他们也出了个翻译器,好像很贵?
这个行业整体提升了,保持领先已经很难。巨头谷歌也不能。
我早跟MT说拜拜了,前几年还较劲,觉得统计MT鲁棒是鲁棒,意思也勉强可以出来,但出来的译文惨不忍睹,想着有空怼一怼统计。神经翻译出来后,基本熄灭了狂妄,顾左右不言他,反给它做宣传,吹喇叭了。(【谷歌NMT,见证奇迹的时刻】) 当然,任何技术都有短板(行话叫知识瓶颈),譬如进入一个没有人工翻译大数据可以学习的领域,神经系统就抓瞎了,譬如电商数据的机器翻译目前的可用度不到 30%(相比较:在新闻领域,机器翻译的可用度高过90%),就是说几乎完全不可用。
校长:
正确选择
典型的乱拳打死老师傅
李:
AI 这次炒热其实是有群众基础的,不完全是媒体鼓噪和精英忽悠。一个是神经机器翻译,一个是语音识别(如 讯飞的自动速记和语音输入),还有一个是人脸和图像识别,这三块儿的进步,不是忽悠,而是现实。还有一个对话,从苹果的 Siri 开始,虽然还有磕磕绊绊,虽然绝大多数普罗还是拿它当玩具,落地应用的产品多不成熟,但 Siri 还是启蒙了大众和教育了市场。这些都是普罗百姓可以亲眼见证和切身体会的科技奇迹。这些个东西激发了草根的想象力。于是,AI 热在民间还是很时髦正面的形象。
留个证据图 以防哪天系统退化(虽然是小概率事件:但马斯克昨天说 科技并不自动进步 逆水行舟 不进则退 它举的是航天技术在 SpaceX 前停滞不前反而退化的例子) MT奇迹不得重复。先防着别人怀疑假造,说不可信:
校长:
本来就是不进则退。很多科幻片里面未来都是破破烂烂破铜烂铁。就是天上一堆飞船在shithole上面飞。我认为那更接近未来的发展方向。
李:
那个是科幻,对科幻,no comment
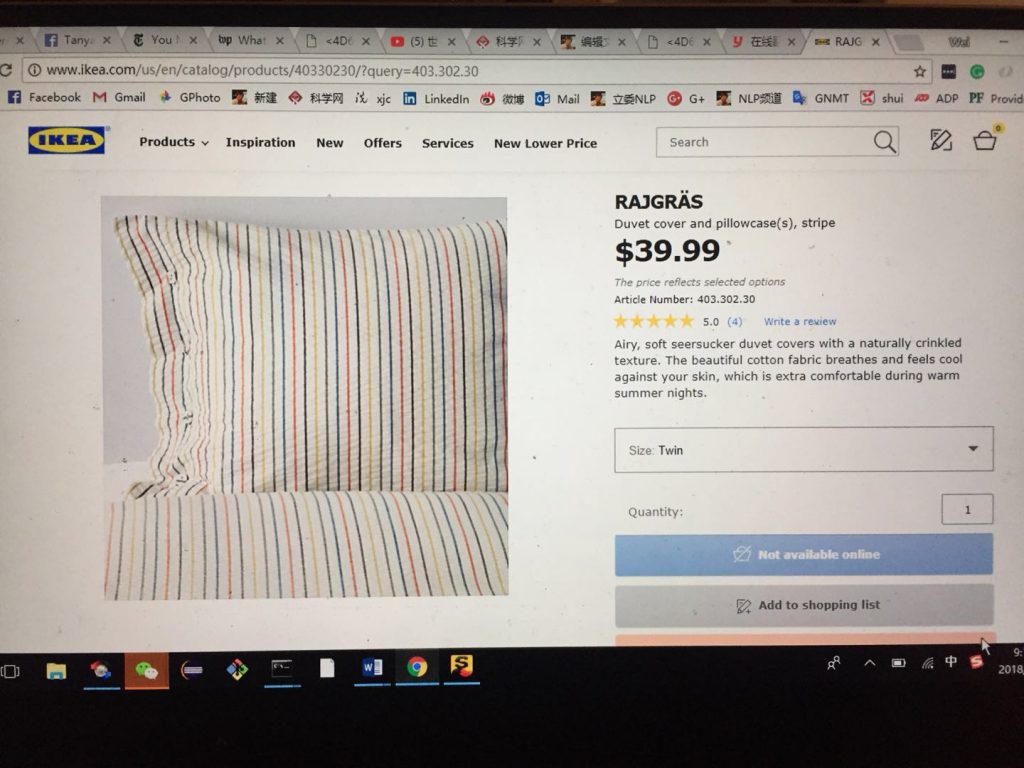
今天,领导在网上查看 IKEA 网页上的商品,问几个单词怎么讲,我说以后不用问我了,我给你的 iPhone 装了有道,比我强多了,还 handy,可她懒得查词典。我说,你不用查,拍个照就行了,打开 app 有个“拍照翻译”的按钮。wow:
挑错永远可以挑,能做到这么贴心、intuitive,乔布斯再世,也不过如此了。
Guo:
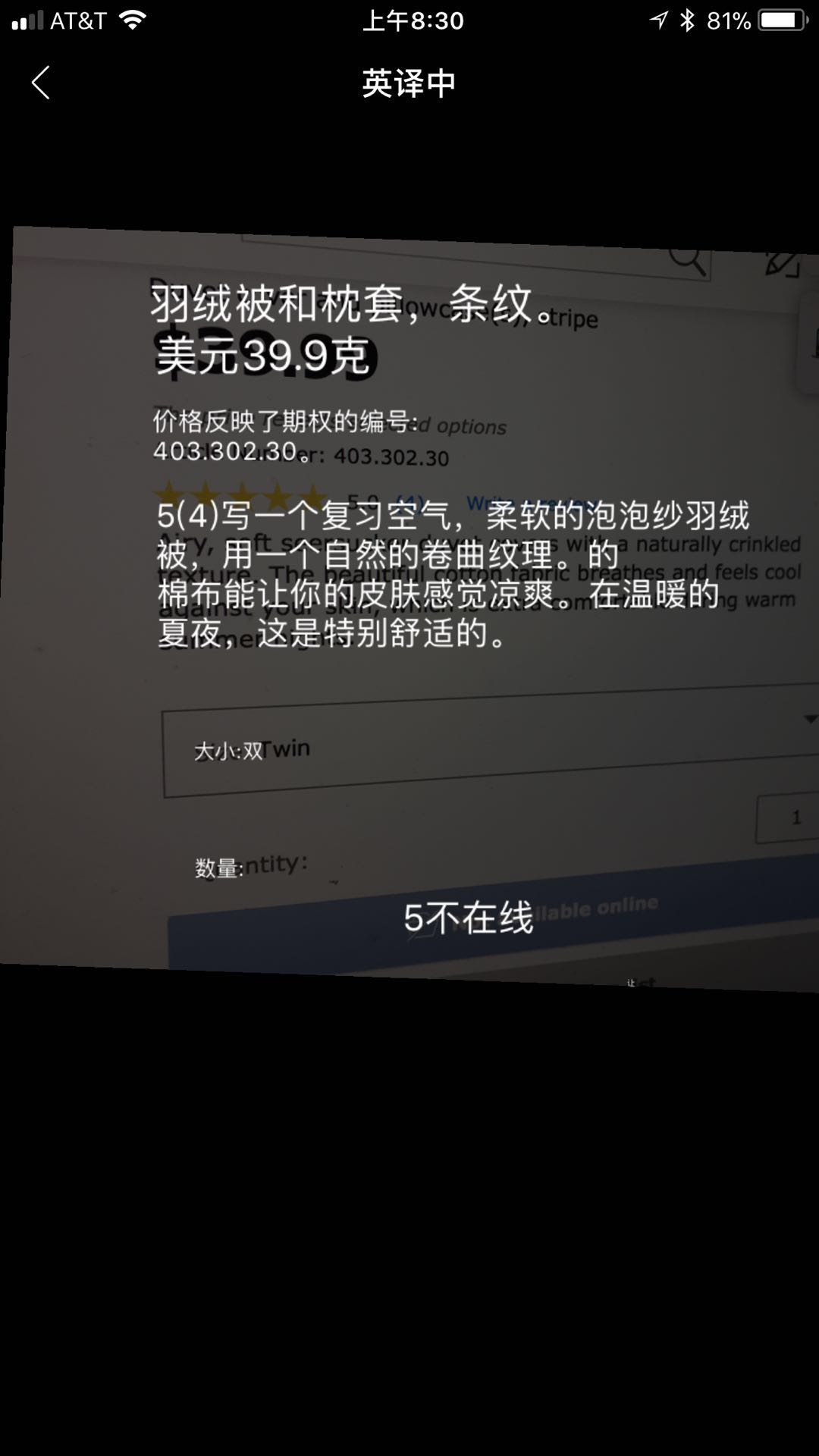
@wei 真要给你泼泼冷水了。哈,也不能太不顾事实啊。“复习空气”,完全不搭啊。这可是连“流畅”也不及格的。打住吧!
李:
还有 39.9克。
原文是:
Airy, soft seersucker duvet covers with a naturally crinkled texture. The beautiful cotton fabric breathes and feels cool against your skin, which is extra comfortable during warm summer nights.
Size: Twin
这玩意儿我不查词典也翻译不了,特别是第一句。领导以为我是英语大拿,这辈子没少拿这些东西问我,我哪里记得住这些家庭主妇关心的“领域词汇”啊?每次我被问住了,形象分就损减一分,一辈子下来,在家里我这英语专家的光环已经消磨殆尽了。呵呵。
郭:
看看微信自带的翻译:
轻盈、柔软的泡泡纱被套,具有自然的皱褶质感。美丽的棉织品呼吸和感觉凉爽的皮肤,这是特别舒适,在温暖的夏季夜晚。
大小:双胞胎
李:
不错 不错。这就是我说的,这是整个行业的技术提升,不是哪一家可以专美的了。语音、图像和MT。
$39.99 翻译成 39.9克 原来是因为 OCR 识别成 39.9g 了 哈。实在说,9 跟 g 长得的确差不离儿,加上在数字后常见,也是事出有因。 可惜了前面那个 $ sign 的痕迹。
哈,领导以前迷信我是英语大拿,这辈子没少拿这些东西问我,我哪里记得住这些家庭主妇关心的“领域词汇”啊?每次我被问住了,形象分就损减一分,一辈子下来,在自家这英语专家的光环已经差不多消磨殆尽了。呵呵。
回过来想,以前我们常常赞佩的那些大学问家过目不忘,词汇量超大,现在想来算啥,再大也比不上一个小U盘,脑子里被词汇填满,实在有点浪费。反正随身有iPhone,iPhone 里面有【有道】,有道不仅有本地词典,还可以接得上云,脑袋是无限延伸了的。可是 托福 GRE 还在考那些稀奇古怪的词,明知道好不容易记住了,考完了,还是会忘掉。跟不上时代啊。
这个也好玩 请看:
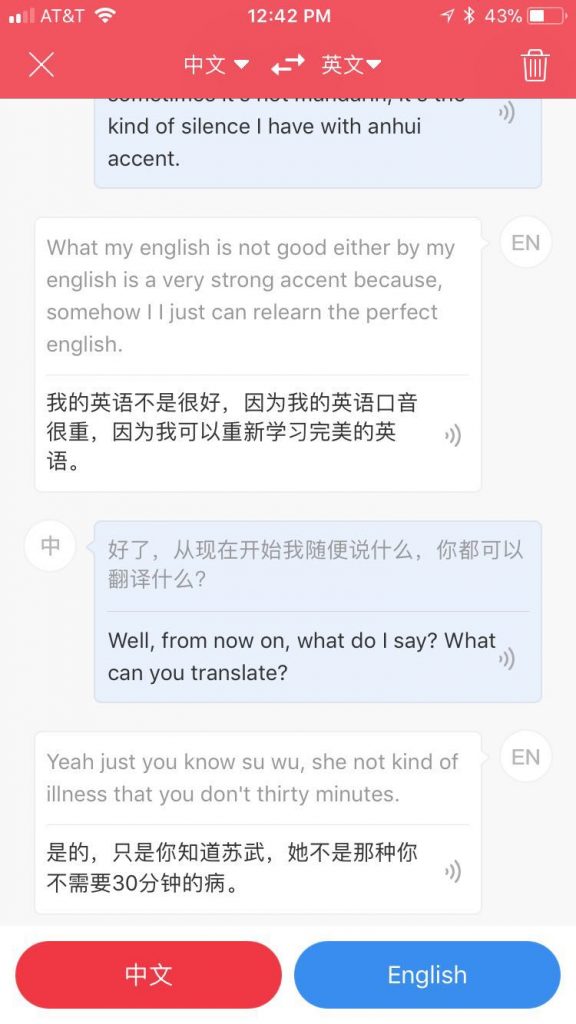
这张截屏里 头两句很顺 最下一句莫名其妙:原因是我不小心按了 英语 的话筒 说的却是汉语 哈哈。这岂止是垃圾进垃圾出啊。但它一本正经给你匹配完全错位的语音 也不设个置信下限 一样翻译出莫名其妙貌似顺畅的句子来。
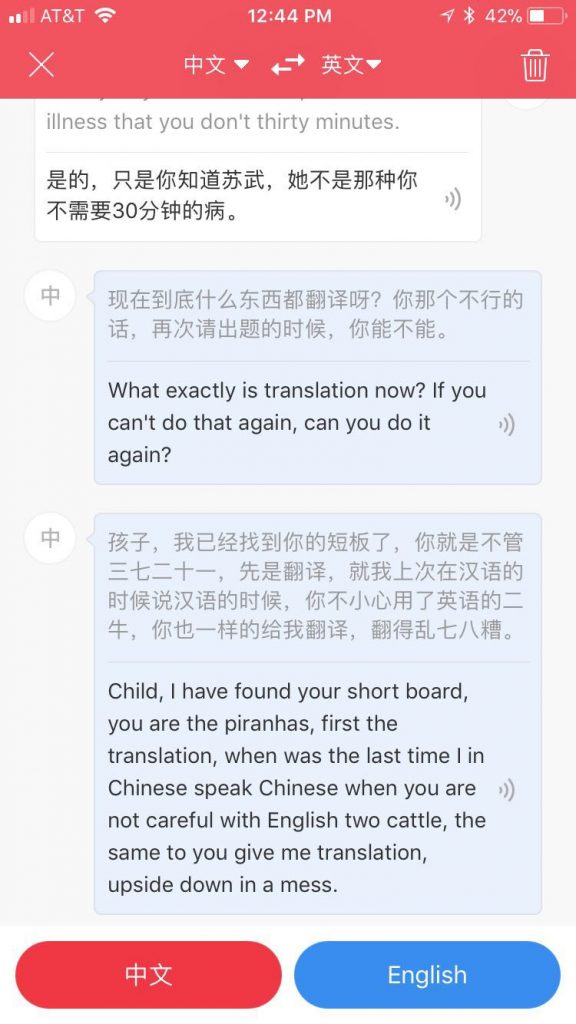
“英语按钮” 转写成 “英语的二牛”(为什么不是二妞呢),继而翻译成 English two cattle.
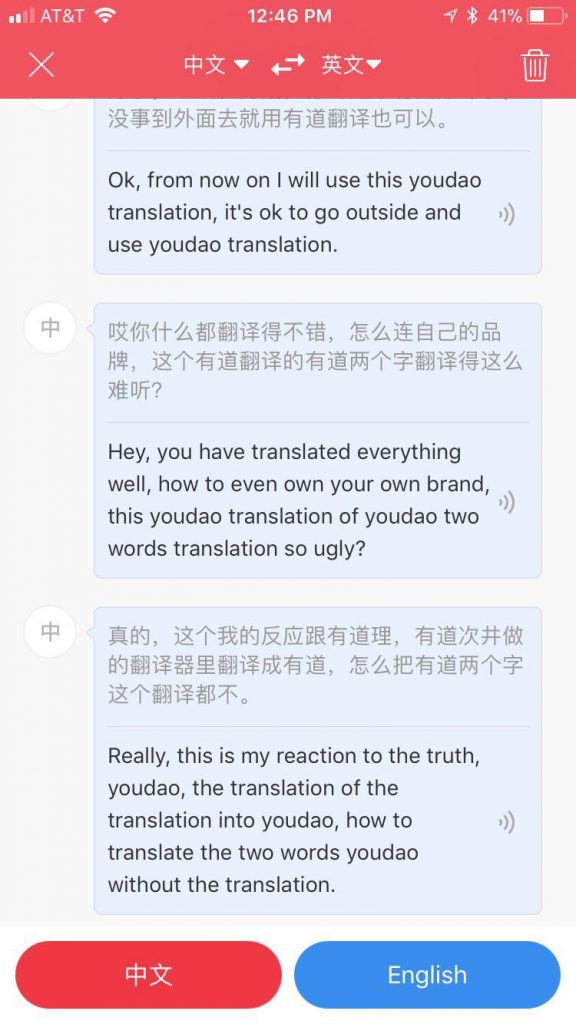
有道自己做的翻译器 却把自己的品牌名“有道”, 在英语读出来一个古怪的读音 哈。我说的是 “这个我得反映给有道”,成了“这个我的反应跟有道理”,考虑到我的口音,难为它了,倒也情有可原。
下面的实验是读一段英文新闻
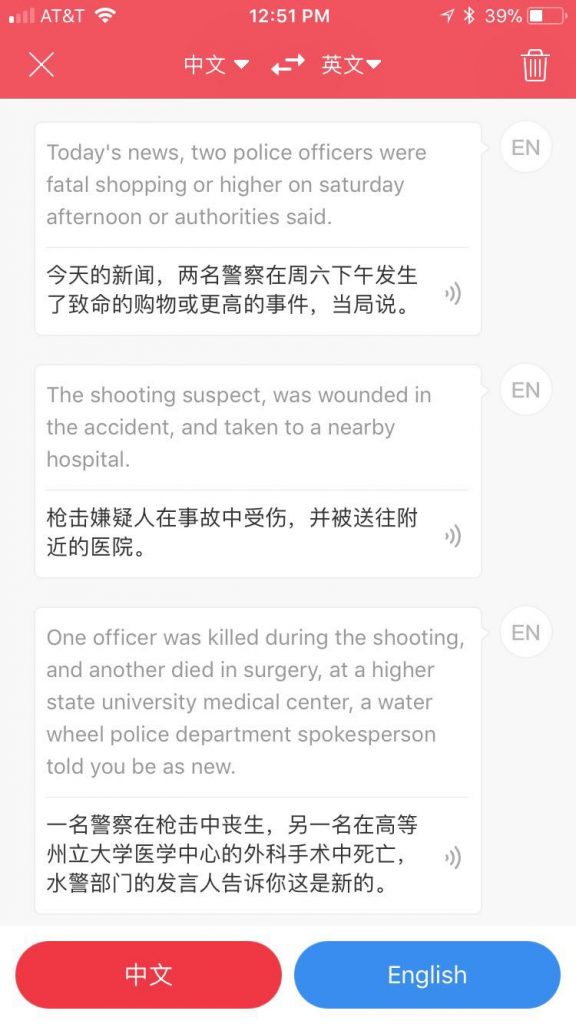
翻译基本没问题。
接着到文学城找一篇中文新闻,读给它听:
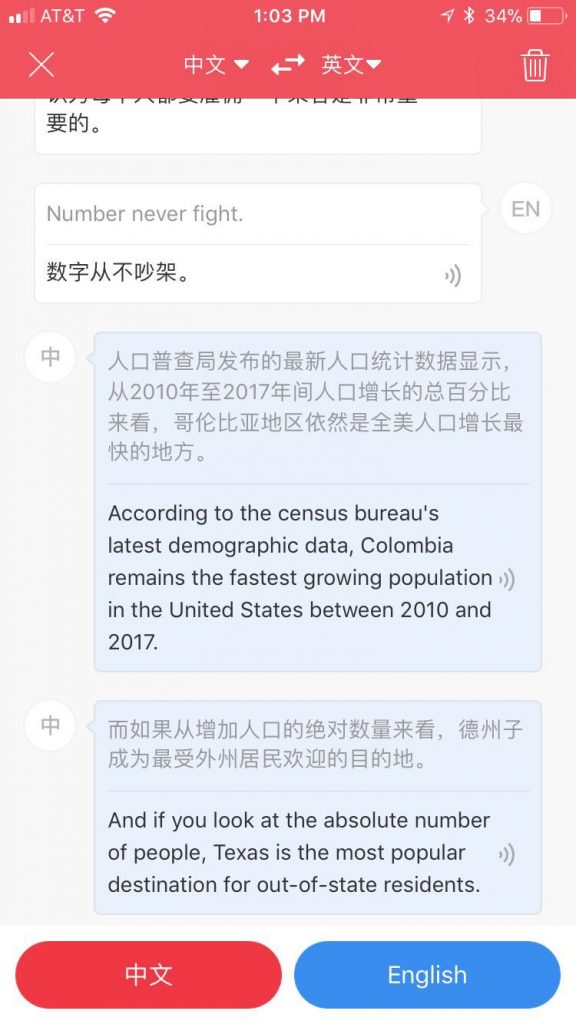
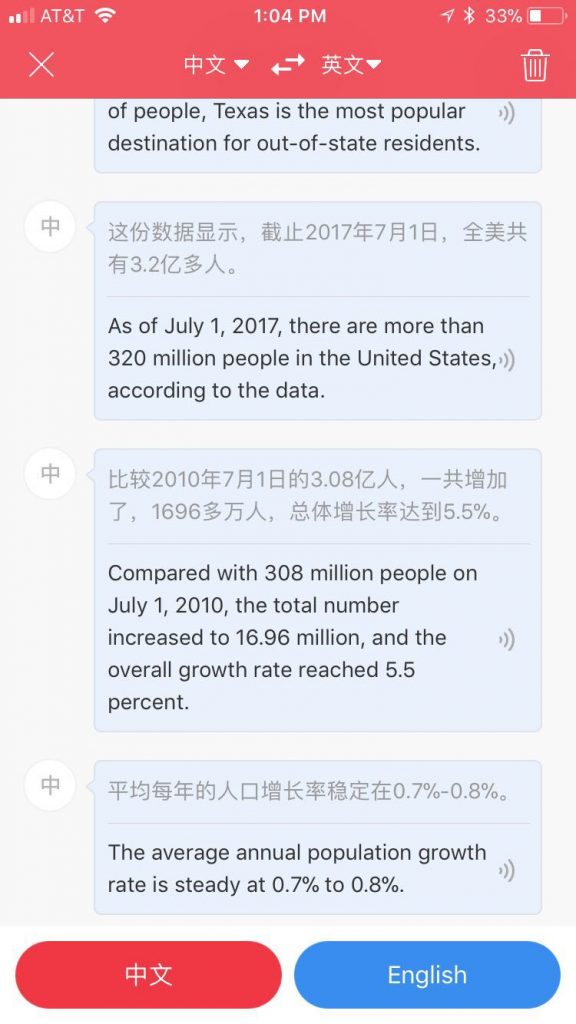

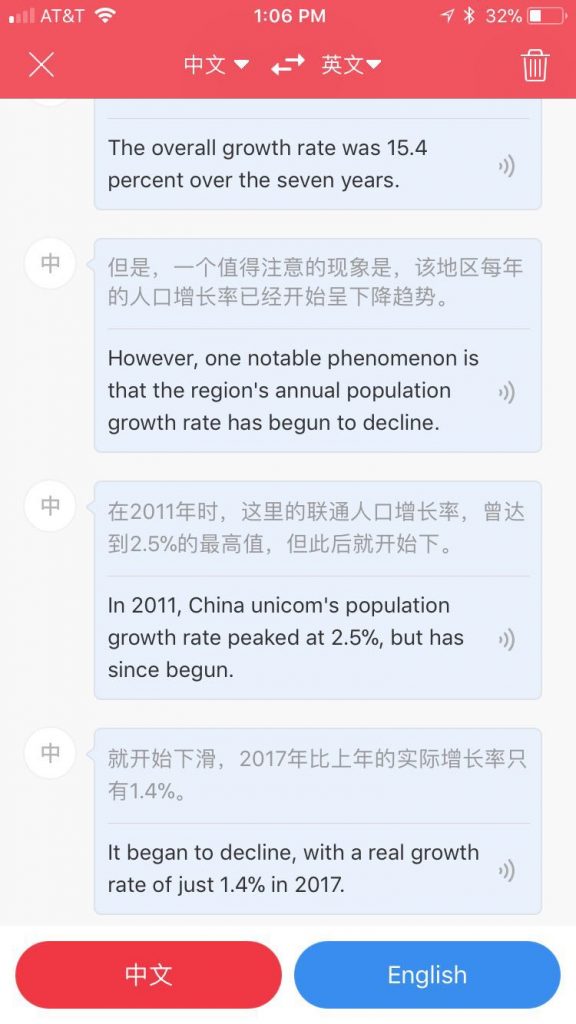
不可思议地顺畅 精准,甚至那些百分比 那些数字 也能“听懂”我的口音。
有点吓倒了。老革命心脏也不都好。
最后是我阅读的新闻的网页截屏 有兴趣可以自己对照一下。
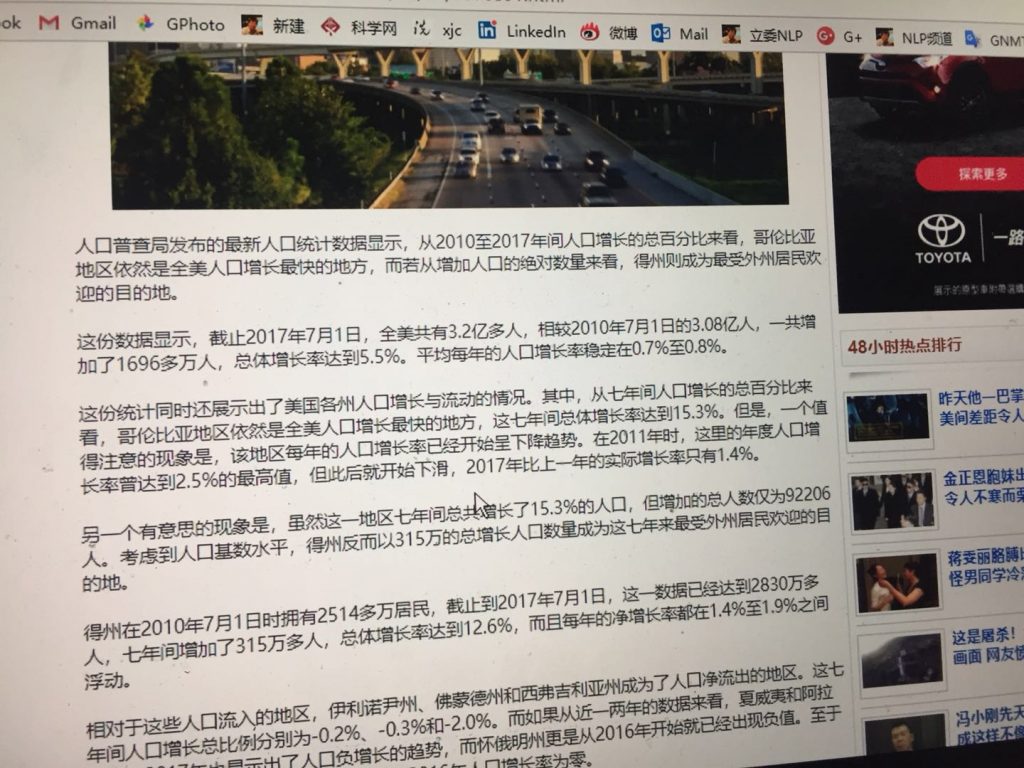
这一切 是在我这种普通话不标准 有口音干扰的信道中发生的。错误放大理论会说 这种翻译是完全不可能的,见证的不是奇迹,只能是AI魔术。
想起来谁说过的名言:“NLP 不是魔术,但是,其结果有时几乎就是魔术一般神奇。”
【相关】
【开复老师说:AI 是最好的时代,也可能是最坏的时代】
【谷歌NMT,见证奇迹的时刻】
【立委随笔:猫论,兼论AI福兮祸兮】
有道的机器翻译(http://fanyi.youdao.com/)
谷歌翻译 https://translate.google.com/
【语义计算:李白对话录系列】
《朝华午拾》总目录