【立委按】说明一点 写这篇nlp联络图科普的时候 深度学习还没火。 ai 还没有摇身一变 ,被 dl 所窃取。当时的机器学习界 还在鄙视 取笑 并与 ai 保持距离。没想到现如今 ai 居然被看成了 dl 的同义词 突然成了香饽饽。言必称神经,连 NLP也被窃取了,也与dl划了等号。符号逻辑派的AI与规则系统的NLP,做了一辈子,到头来连“家”都没了。一切皆是学习,一切都要神经。但我相信天变了,道却不变,因此下面的联络图或可超越神经一统天下的狭隘思维。拨乱反正,谈何容易。还是一家之言,愿者上钩吧。
(NLP Word Cloud, courtesy of ourselves who built the NLP engine to parse social media to generate this graph )
【立委原按】样板戏《智取威虎山》里面,杨子荣怀揣一张秘密联络图而成为土匪头子座山雕的座上客,因为在山头林立的江湖,谁掌握了联络图,谁就可以一统天下。马克思好像说过人是社会关系的总和,专业领域又何尝不是如此。在关系中定义和把握 NLP,可以说是了解一门学问及其技术的钟南山捷径。老马识途,责无旁贷,遂精雕细刻,作联络图四幅与同仁及网友分享。此联络图系列可比林彪元帅手中的红宝书,急用先学,有立竿见影之奇效。重要的是,学问虽然日新月异,永无止境,然而天下大势,在冥冥中自有其不变之理。四图在手,了然于心,可以不变应万变,无论研究还是开发,必不致迷失革命大方向。
一个活跃的领域会不断产生新的概念,新的术语,没有一个合适的参照图,新人特别容易湮没其中。新术语起初常常不规范,同一个概念不同的人可能使用不同的术语,而同一个术语不同的人也可能有不同的解读。常常要经过一个混沌期,研究共同体才逐渐达成规范化的共识。无论是否已经达成共识,关键是要理解术语的背后含义 (包括广义、窄义、传统定义,以及可能的歧义)。加强对于术语的敏感性,不断探究以求准确定位新概念/新术语在现有体系的位置,是为专业人员的基本功。本文将
围绕这四幅自制联络图,
对 NLP 相关的术语做一次地毯式梳理和解说。本文提到的所有术语在第一次出现时,中文一律加下划线,英文斜体(Italics),大多有中英文对照,有的术语还给出超链,以便读者进一步阅读探索。
在我们进入NLP 系列联络图内部探究其奥秘之前,有必要澄清自然语言处理(NLP)的一般概念及其上位概念,以及与 NLP 平起平坐或可以相互替换的一些术语。
NLP 这个术语是根据“自然语言”这个问题领域而命名的宽泛概念。顾名思义,自然语言处理就是以自然语言为对象的计算机处理。无论为了什么目标,无论分析深浅,只要涉及电脑处理自然语言,都在 NLP 之列。所谓自然语言(Natural language)指的即是我们日常使用的语言,英语、俄语、日语、汉语等,它与人类语言(Human language)是同义词,主要为区别形式语言(Formal language),包括计算机语言(Computer language)。自然语言是人类交流最自然最常见的形式,不仅仅是口语,书面语也在海量增长,尤其是移动互联网及其社交网络普及的今天。比较形式语言,自然语言复杂得多,常有省略和歧义,具有相当的处理难度(hence 成就了 NLP 这个专业及其我们的饭碗)。顺便一提,在自然语言灰色地带的还有那些人造语(Artificial language)方案,特别是广为流传的世界语(Esperanto),它们的形式与自然语言无异,也是为人类交流而设计,不过是起源上不太“自然”而已,其分析处理当然也属 NLP。(笔者N多年前的机器翻译专业的硕士课题就是一个把世界语全自动翻译成英语和汉语的系统,也算填补了一项空白。)
与 NLP 经常等价使用的术语是计算语言学(Computational Linguistics, or, CL)。顾名思义,计算语言学 是 计算机科学(Computer Science)与语言学(Linguistics)之间的交叉学科。事实上,NLP 和 CL 是同一个行当的两面,NLP 注重的是实践,CL 则是一门学问(理论)。可以说,CL 是 NLP 的科学基础,NLP 是 CL 的应用过程。由于 CL 与数理等基础学科不同,属于面相应用的学问,所以 CL 和 NLP 二者差不多是同一回事儿。其从业人员也可以从这两个侧面描述自己,譬如,笔者在业界可称为NLP工程师(NLP engineer),在学界则是计算语言学家(Computational linguist)。当然,在大学和研究所的计算语言学家,虽然也要做 NLP 系统和实验,但学问重点是以实验来支持理论和算法的研究。在工业界的 NLP 工程师们,则注重 real life 系统的实现和相关产品的开发,奉行的多是白猫黑猫论,较少理论的束缚。
另外一个经常与
NLP 平行使用的术语是
机器学习(
Machine Learning, or,
ML)。严格说起来,机器学习与
NLP 是完全不同层次的概念,前者是方法,后者是问题领域。然而,由于机器学习的万金油性质(谁说机器学习不万能,统计学家跟你急),加之
ML 已经成为
NLP 领域(尤其在学界)的主流方法,很多人除了机器学习(如今时兴的是
深度学习,或曰
深度神经网络),忘记或者忽视了
NLP 还有语言规则的方法,因此在他们眼中,
NLP 就是机器学习。其实,机器学习并不局限于
NLP 领域,那些用于语言处理的机器学习算法也大多可以用来做很多其他
人工智能(
Artificial Intelligence, or
AI)的事儿,如
股市预测(
Stock market analysis)、
信用卡欺诈监测(
Detecting credit card fraud)、
机器视觉(
Computer vision)、
DNA测序分类(
Classifying DNA sequences),甚至
医疗诊断(
Medical diagnosis)。
在 NLP 领域,与机器学习平行的传统方法还有语言学家(linguist)或知识工程师(knowledge engineer)手工编制的语言规则(Linguistic rules, or hand-crafted rules),这些规则的集合称计算文法(Computational grammar),由计算文法支持(or 编译)的系统叫做规则系统(Rule system)。
机器学习和规则系统这两种方法各有利弊,可以取长补短。统而言之,机器学习擅长文档分类(Document classification),从宏观上粗线条(course-grained)把握语言现象,计算文法则擅长细致深入的语言学分析,从细节上捕捉语言现象。如果把语言看成森林,语句看成林中形态各异的树木,总体而言,机器学习是见林不见木,计算文法则见木不见林(本来这是很自然的互补关系,但双方都有不为少数的“原教旨主义极端派”不愿承认对方的长处,呵呵)。从效果上看,机器学习常常以覆盖面胜出,业内的术语叫高查全率(High recall),而计算文法则长于分析的精度,即高查准率(High precision)。由于自然语言任务比较 复杂,一个实用系统(Real-life system)常常需要在在粗线条和细线条(fine-grained)以及查全与查准之间取得某种平衡,因此结合两种方法的 NLP 混合式系统(Hybrid system)往往更加实惠好用。一个简单有效的结合方式是把系统建立成一个后备式模型(back-off model),对每个主要任务,先让计算文法做高精度低覆盖面的处理,再行机器学习出来的统计模型(Statistical model),以便粗线条覆盖遗留问题。
值得一提的是,传统 AI 也倚重手工编制的规则系统,称作符号逻辑派,但是它与语言学家的计算文法有一个根本的区别:AI 规则系统远远不如计算文法现实可行。AI 的规则系统不仅包括比较容易把握(tractable)和形式化(formalized)的语言(学)规则,它们还试图涵盖包罗万象的常识(至少是其中的核心部分)以及其他知识,并通过精巧设计的逻辑推理系统把这些知识整合起来。可以说,AI 旨在从本质上模拟人的智能过程,因雄心太大而受挫,以致多年来进展甚微。过去的辉煌也只表现在极端狭窄的领域的玩具系统(后来也发展了一支比较实用的专家系统),当时统计模型还是没有睡醒的雄狮。以 ML 为核心以大数据(Big data)为支撑的统计方法的兴起,让这种 AI 相形见绌。有意思的是,虽然人工智能(台湾同胞称人工智慧)听上去很响亮,可以唤起普罗大众心中的某种科学幻想奇迹(因此常常为电子产品的包装推销商所青睐),在科学共同体中却相当落寞:有不少统计学家甚至把 AI 看成一个过气的笑话。虽然这里难免有王婆卖瓜的偏见,但 传统 AI 的方法论及其好高骛远不现实也是一个因素。也许在未来会有符号逻辑派 AI 的复兴,但是在可预见的将来,把人类智能当作联接输入输出的黑匣子的机器学习方法,显然已经占了上风。
由此看来,
ML 与
AI 的关系,颇似
NLP 与
CL 的关系,外延几乎重合,
ML 重在
AI 的应用(包括
NLP),而传统
AI 理应为
ML 的理论指导。可是,由于方法学上的南辕北辙,以
知识表达(
Knowledge representation)和
逻辑推理(
Logical reasoning)为基础的传统
AI 越来越难担当实用
智能系统(
Intelligent systems)的理论指导,智能系统的地盘逐渐为以统计学和信息论为基础的机器学习所占领。国宝熊猫般珍稀的坚持传统AI的逻辑学家(如
cyc 发明人
Douglas Lenat 老先生)与擅长
ML 的统计学家(多如恐龙)虽然问题领域几乎完全重合,解决方案却形如陌路,渐行渐远。
还有一个几乎与自然语言处理等价的术语,叫自然语言理解(Natural Language Understanding, or NLU)。从字面上,这个义为“机器理解语言”的术语 NLU 带有浓厚的人工智能的烂漫主义意味,不象“机器处理语言”那样直白而现实主义,但实际上,使用 NLP 还是 NLU, 正如使用 NLP 还是 CL 一样, 往往是不同圈子人的不同习惯,所指基本相同。说基本相同,是因为 NLP 也可以专指浅层的语言处理(譬如后文会提到的浅层分析 Shallow parsing),而深度分析(Deep parsing)却是 NLU 的题中应有之义,浅尝辄止的不能登 NLU/AI 的大雅之堂。不妨这样看,带上AI的眼镜看,此物为NLU;而以 ML 而观之,则此物只能是 NLP。
此外,自然语言技术或语言技术(Natural language technology)也是 NLP 的通俗化表达。
既然
NLP 的等价物
CL 有两个parents,
计算机科学和
语言学,
NLP 的上位概念也自然可以有两位:
NLP 既可以看作是计算机科学的一个应用分支,也可以看作是语言学的一个应用分支。事实上,广义的
应用语言学(
Applied linguistics)是包含计算语言学和
NLP 的,不过由于计算语言学作为一个独立学科已经站住脚跟半个多世纪了(其主要学刊是《
Computational Linguistics》,学会是 ACL,顶级国际会议包括 ACL 年会和 COLING 等),(窄义的)应用语言学现在更多用来表示语言教学和翻译这样的实用领域,不再下辖计算语言学这个分支。
从功能上看,NLP 与 ML 一样,同属于人工智能的范畴,特别是自然语言理解以及NLP的种种应用,如机器翻译。所以,广义的人工智能既是机器学习的上位概念,也是自然语言处理的上位概念。然而,如上所说,窄义或传统的人工智能强调知识处理包括常识推理(common-sense reasoning),与现行的 ML 和 NLP 的数据制导(data-driven)现状颇有距离,因此有 NLP 学者刻意保持与传统AI的距离以示不屑为伍。
千头万绪,纲举目张,下文分四个层次、用四幅联络图来讲解 NLP per se。四个层次分别是:
1. 语言层(linguistic level);
2.
抽取层(extraction level);
这四个层次的关系,基本就是自底而上的支持关系:1 ==》2 ==》 3 ==》4。显然,
NLP 的核心句法分析器(
Parser)处于第一层, 而《
自动民调》、《
问答系统》、《
机器翻译》这样的系统则是第四层应用的例子。
需要说明的是,NLP 的对象自然语言有两种形式,
语音(
Speech)和
文本(
Text),因此NLP自然涵盖语音方面的两个重要方向:1. 教授电脑听懂人话的
语音识别(
Speech recognition);2. 教授电脑说人话的
语音合成(
Speech synthesis)。由于笔者对
语音处理(
Speech processing)比较外行,本系列专谈针对文本的
NLP,视语音识别和语音合成为文本处理(
Text processing)的 前奏和后续。事实上,在实际的语言系统中,语音处理和文本处理的分工正是如此,譬如
NLP 在手机上最新应用如
苹果的 Siri 就是先行语音识别,输出文本结果,再行文本分析,然后根据分析理解的结果采取行动(根据主人指令去查天气预报、股票、播放某支音乐等等)。
净手焚香阅好图
我把 NLP 系统从核心引擎直到应用,分为四个阶段,对应四张框架图。
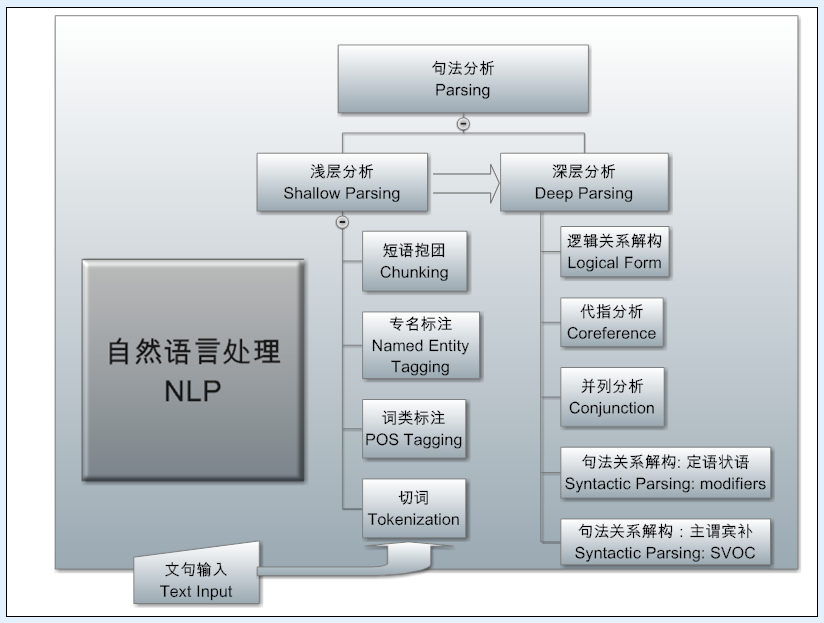
最底层最核心的是 deep parsing,就是对自然语言的自底而上层层推进的自动分析器,这个工作最繁难,但是它是绝大多数NLP系统的我称之为带有核武器性质的基础技术,因为自然语言作为非结构数据因此而被结构化了。面对千变万化的语言表达,只有结构化了,patterns 才容易抓住,信息才好抽取,语义才好求解。这个道理早在乔姆斯基1957年语言学革命后提出表层结构到深层结构转换的时候,就开始成为(计算)语言学的共识了。结构树不仅是表达句法关系的枝干(arcs),还包括负载了各种信息的单词或短语的叶子(nodes)。结构树虽然重要,但一般不能直接支持产品,它只是系统的内部表达,作为语言分析理解的载体和语义落地为应用的核心支持。
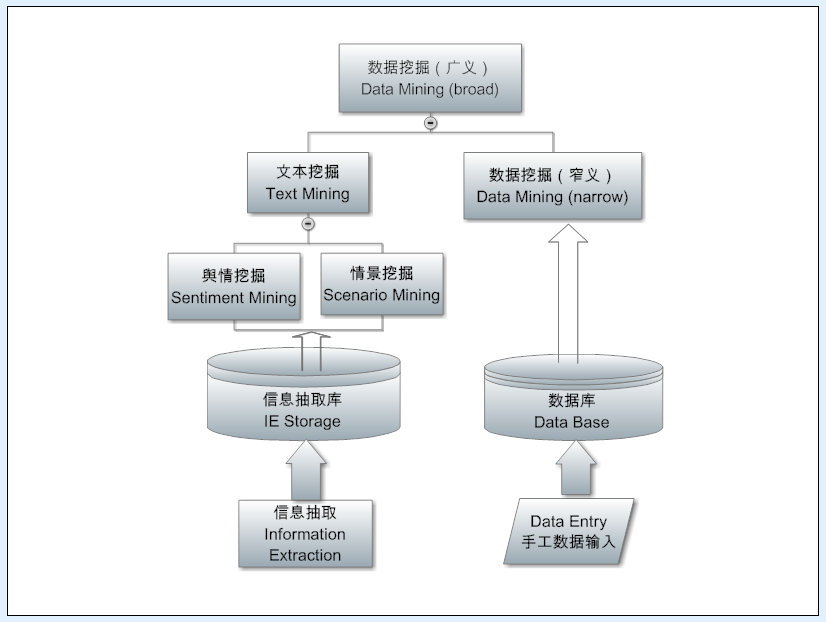
接下来的一层是抽取层 (extraction),如上图所示。它的输入是结构树,输出是填写了内容的 templates,类似于填表:就是对于应用所需要的情报,预先定义一个表格出来,让抽取系统去填空,把语句中相关的词或短语抓出来送进表中事先定义好的栏目(fields)去。这一层已经从原先的领域独立的 parser 进入面对领域、针对应用和产品需求的任务了。
值得强调的是,抽取层是面向领域的语义聚焦的,而前面的分析层则是领域独立的。因此,一个好的架构是把分析做得很深入很逻辑,以便减轻抽取的负担。在深度分析的逻辑语义结构上做抽取,一条抽取规则等价于语言表层的千百条规则。这就为领域转移创造了条件。
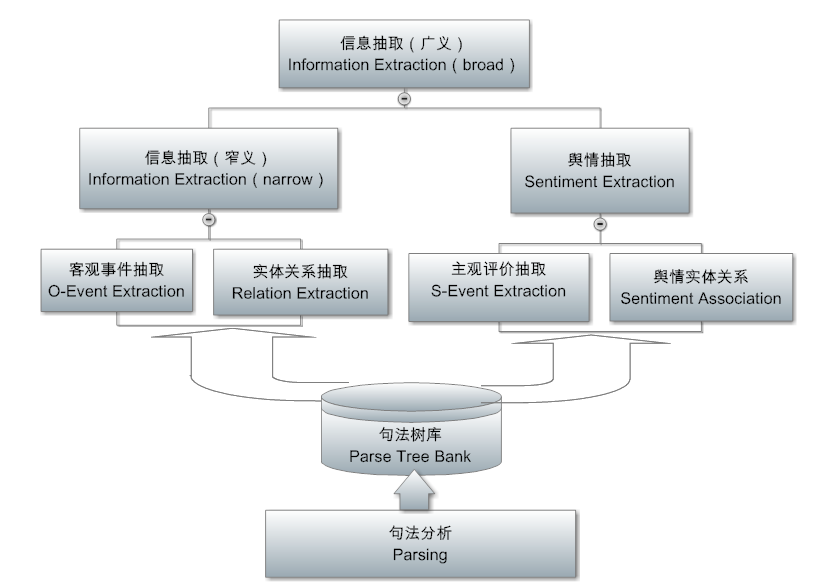
有两大类抽取,一类是传统的信息抽取(IE),抽取的是事实或客观情报:实体、实体之间的关系、涉及不同实体的事件等,可以回答 who did what when and where (谁在何时何地做了什么)之类的问题。这个客观情报的抽取就是如今火得不能再火的知识图谱(knowledge graph)的核心技术和基础,IE 完了以后再加上下一层挖掘里面的整合(IF:information fusion),就可以构建知识图谱。另一类抽取是关于主观情报,舆情挖掘就是基于这一种抽取。我过去五年着重做的也是这块,细线条的舆情抽取(不仅仅是褒贬分类,还要挖掘舆情背后的理由来为决策提供依据)。这是 NLP 中最难的任务之一,比客观情报的 IE 要难得多。抽取出来的信息通常是存到某种数据库去。这就为下面的挖掘层提供了碎片情报。
很多人混淆了抽取(information extraction) 和下一步的挖掘(text mining),但实际上这是两个层面的任务。抽取面对的是一颗颗语言的树,从一个个句子里面去找所要的情报。而挖掘面对的是一个 corpus,或数据源的整体,是从语言森林里面挖掘有统计价值的情报。在信息时代,我们面对的最大挑战就是信息过载,我们没有办法穷尽信息海洋,因此,必须借助电脑来从信息海洋中挖掘出关键的情报来满足不同的应用。因此挖掘天然地依赖统计,没有统计,抽取出来的信息仍然是杂乱无章的碎片,有很大的冗余,挖掘可以整合它们。
很多系统没有深入做挖掘,只是简单地把表达信息需求的 query 作为入口,实时(real time)去从抽取出来的相关的碎片化信息的数据库里,把 top n 结果简单合并,然后提供给产品和用户。这实际上也是挖掘,不过是用检索的方式实现了简单的挖掘就直接支持应用了。
实际上,要想做好挖掘,这里有很多的工作可做,不仅可以整合提高已有情报的质量。而且,做得深入的话,还可以挖掘出隐藏的情报,即不是原数据里显式表达出来的情报,譬如发现情报之间的因果关系,或其他的统计性趋势。这种挖掘最早在传统的数据挖掘(data mining)里做,因为传统的挖掘针对的是交易记录这样的结构数据,容易挖掘出那些隐含的关联(如,买尿片的人常常也买啤酒,原来是新为人父的人的惯常行为,这类情报挖掘出来可以帮助优化商品摆放和销售)。如今,自然语言也结构化为抽取的碎片情报在数据库了,当然也就可以做隐含关联的情报挖掘来提升情报的价值。
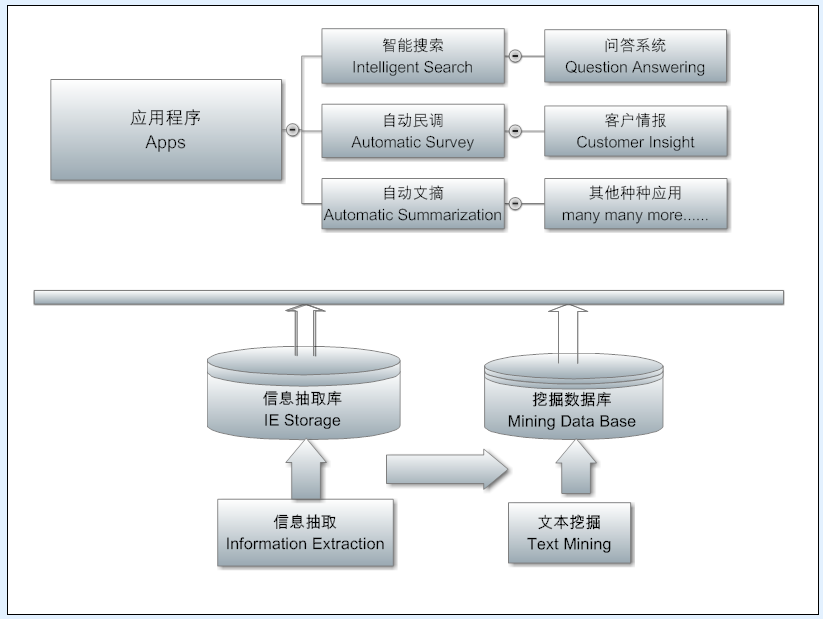
第四张架构图是NLP应用(apps)层。在这一层,分析、抽取、挖掘出来的种种情报可以支持不同NLP产品和服务。从问答系统到知识图谱的动态浏览(谷歌搜索中搜索明星已经可以看到这个应用),从自动民调到客户情报,从智能助理到自动文摘等等。
这算是我对NLP基本架构的一个总体解说。根据的是20多年在工业界做NLP产品的经验。18年前,我就是用一张NLP架构图忽悠来的第一笔风投,投资人自己跟我们说,这是一张 million dollar slide。如今的解说就是从那张图延伸拓展而来。
天变还是不变,道是不变的。