【立委按】老友郭兄盛赞自动有道翻译,说强过我常用的谷歌神经翻译。于是小试一次,翻译一下我自己的英语博客,除微量技术性编辑外,基本保留原译。以飨同仁。
我们都知道,自然语言解析相当复杂,在自然语言理解(NLU)及其应用中起着重要作用。我们也知道,一个突破到90%以上,解析的准确性接近于人类的表现,这确实是一个值得骄傲的成就。然而,按照常识,我们都知道,如果没有任何附加的范围或条件,你必须有最大的勇气来宣称“最”,除非得到了吉尼斯等权威机构的认可。对于谷歌宣称的“世界上最精确的解析器”,我们只需要引用一个系统来证明它是不真实的或具有误导性的。我们碰巧建了一个。
很长一段时间以来,我们知道我们的英语解析器在数据质量方面接近人类的性能,并且在支持真实生活产品方面是健壮的、快速的和扩展到大数据的。对于我们采取的方法,即语法工程的方法,这是主流统计分析以外的另一种“学派”,这是基于架构师的设计和他几十年的语言专业知识的自然结果。事实上,我们的解析器在5年前就达到了接近人类的性能,在收益递减的时候,我们决定不再大量投资于它的进一步开发。相反,我们的关注点转移到它的应用上,支持开放领域的问题回答和对我们的产品以及多语言空间的细致深入的情感分析。
几周前谷歌发布了SyntaxNet,我受到了来自我的许多同事,包括我的老板和我们的营销主管的各种渠道的消息轰炸。所有这些都提请我对“NLU最新突破”的关注,似乎暗示我们应该更加努力地工作,努力赶上这个巨人。
在我自己看来,我也从来没有怀疑过,另一学派在深度解析上还有很长的路要走,才能赶上我们。但我们处于信息时代,这就是互联网的力量: 来自一个巨人,真实的或具有误导性的新闻,均会立即传遍全世界。所以我觉得有必要做一些研究, 不仅要揭示这个领域的真实情况, 但更重要的是, 还试图教育公众和来到这个领域的年轻学者,一直存在也将永远存在两个学派,在NLU和AI(人工智能)领域。这两个学派实际上有各自的优点和缺点,它们可以是互补的,也可以是混合的,但是一个不能完全忽视或替代另一个。另外,如果只有一个方法,一个选择,一个声音,特别是NLU的核心,比如解析 (以及信息提取和情绪分析等),那么这个世界会变得多么无聊,特别是当大众“所青睐的方法”的表现还远不如被遗忘的那个方法的时候。
因此,我指示一位不参与解析器开发的语言学家尽可能客观地对这两个系统进行基准测试,并对其各自的性能进行一个苹果到苹果的比较。幸运的是,谷歌SyntaxNet输出语法依存关系,而我们的也主要是依存解析器。尽管在细节和命名惯例上存在差异,但在语言判断的基础上,结果并不难对比和比较。为了使事情变得简单和公平,我们将一个输入语句的解析树分解成二元依存关系,并让testor语言学家判断; 一旦有疑问,他会向另一位高级语言学家请教,或者被认为是在灰色地带,而那是很罕见的。
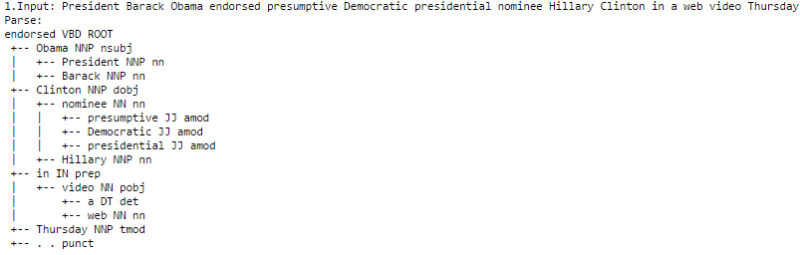
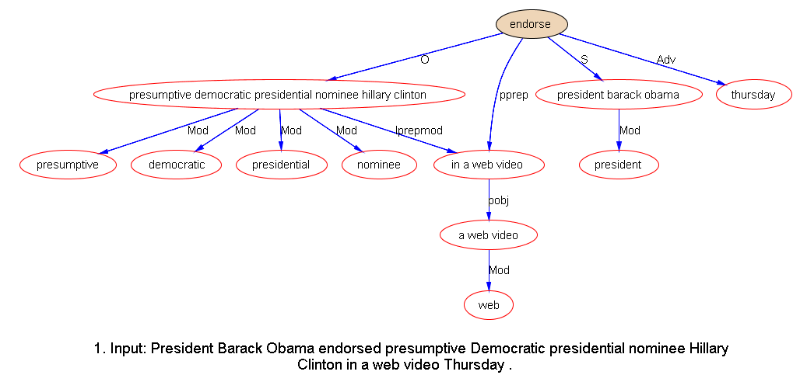
不像其他的NLP任务,例如情绪分析,在那里有相当大的灰色区域空间或标注者之间的分歧,解析结果其实很容易在语言学家之间达成共识。尽管两个系统(输出示例如下所示)所体现的格式不同,但在两个系统的句子树输出中对每个依存项进行直接比较并不困难。(对我们来说更严格的是,在我们的测试结果中使用的一种被称为“下一个链接”的修补关系在测试中并不算合法的句法关系。)
SyntaxNet输出:
Netbase 输出:
基准测试分两个阶段进行。
第1阶段,我们在新闻领域选择了英语形式的文本,这是SyntaxNet的强项,因为它被认为比其他类型的新闻有更多的训练数据。在新闻分析中公布的94%的准确率确实令人印象深刻。在我们的示例中,新闻并不是我们的开发主体的主要来源, 因为我们的目标是开发一个领域独立的解析器来支持各种类型的英语文本对于真实文本的解析,譬如从社交媒体(非正式文本)做情感分析, 以及用科技论文(正式文本)解析 来回答“如何”的问题。
我们随机选择了最近的三篇新闻文章,其中有以下链接。
(1) http://www.cnn.com/2016/06/09/politics/president-barack-obama-endorses-hillary-clinton-in-video/
(2) Part of news from: http://www.wsj.com/articles/nintendo-gives-gamers-look-at-new-zelda-1465936033
(3) Part of news from: http://www.cnn.com/2016/06/15/us/alligator-attacks-child-disney-florida/
以下是分析上述新闻类型的基准测试结果:
(1)谷歌SyntaxNet: F-score= 0.94。
(P为精度,R为召回,F为精度召回综合指标)
P = tp/(tp+fp) = 1737/(1737+104) = 1737/1841 = 0.94。
R = tp/(tp+tn) = 1737/(1737+96) = 1737/1833 = 0.95。
F = 2 *((P * R)/(P + R)]= 2 *((0.94 * 0.95)/(0.94 + 0.95)]= 2 *(0.893/1.89)= 0.94
(2)Netbase解析器: F-score = 0.95。
P = tp/(tp+fp) = 1714/(1714+66) = 1714/1780 = 0.96。
R = tp/(tp+tn) = 1714/(1714+119) = 1714/1833 = 0.94。
F = 2 *((P * R)/(P + R)]= 2 *((0.96 * 0.94)/(0.96 + 0.94)]= 2 *(0.9024/1.9)= 0.95
因此,Netbase 解析器在精度上比谷歌SyntaxNet好了约2个百分点,但在召回中低了1个百分点。总的来说,Netbase比谷歌在F-score的精确-召回综合指标中略好。由于这两个解析器都接近于进一步开发的收益递减点,其实没有太多的空间来进行进一步的竞争。
第二阶段,我们选择非正式文本,从社交媒体Twitter来测试一个解析器的鲁棒性看处理“退化文本”: 很自然,退化的文本总是导致退化的性能 (对人类和机器), 但一个健壮的解析器应该能够处理它,数据质量只有有限的退化。如果一个解析器只能在一个类型或一个领域中表现良好,并且性能在其他类型中显著下降,那么这个解析器就没有多大用处,因为大多数类型或领域没有像资源丰富的新闻类型那样有大量标记的数据。有了这种知识瓶颈,解析器就会受到严重的挑战,并限制其支持NLU应用的潜力。毕竟,解析不是目的,而是将非结构化文本转换为结构的一个手段,以支持不同领域中各种应用程序的语义支持。
我们从推特上随机选择100条推文进行测试,如下图所示。
1.Input: RT @ KealaLanae : ima leave ths here. https : //t.co/FI4QrSQeLh2.Input: @ WWE_TheShield12 I do what I want jk I ca n't kill you .10.Input: RT @ blushybieber : Follow everyone who retweets this , 4 mins
20.Input: RT @ LedoPizza : Proudly Founded in Maryland. @ Budweiser might have America on their cans but we think Maryland Pizza sounds better
30.Input: I have come to enjoy Futbol over Football
40.Input: @ GameBurst That 's not meant to be rude. Hard to clarify the joke in tweet form .
50.Input: RT @ undeniableyella : I find it interesting , people only talk to me when they need something ...
60.Input: Petshotel Pet Care Specialist Jobs in Atlanta , GA # Atlanta # GA # jobs # jobsearch https : //t.co/pOJtjn1RUI
70.Input: FOUR ! BUTTLER nailed it past the sweeper cover fence to end the over ! # ENG - 91/6 -LRB- 20 overs -RRB- . # ENGvSL https : //t.co/Pp8pYHfQI8
79..Input: RT @ LenshayB : I need to stop spending money like I 'm rich but I really have that mentality when it comes to spending money on my daughter
89.Input: RT MarketCurrents : Valuation concerns perk up again on Blue Buffalo https : //t.co/5lUvNnwsjA , https : //t.co/Q0pEHTMLie
99.Input: Unlimited Cellular Snap-On Case for Apple iPhone 4/4S -LRB- Transparent Design , Blue/ https : //t.co/7m962bYWVQ https : //t.co/N4tyjLdwYp
100.Input: RT @ Boogie2988 : And some people say , Ethan 's heart grew three sizes that day. Glad to see some of this drama finally going away. https : //t.co/4aDE63Zm85
以下是社交媒体推特的基准测试结果:
(1)谷歌SyntaxNet: F-score = 0.65。
P = tp/(tp+fp) = 842/(842+557) = 842/1399 = 0.60。
R = tp/(tp+tn) = 842/(842+364) = 842/1206 = 0.70。
F = 2 *((P * R)/(P + R)]= 2 *((0.6 * 0.7)/(0.6 + 0.7)]= 2 *(0.42/1.3)= 0.65
Netbase解析器: F-score = 0.80。
P = tp/(tp+fp) = 866/(866+112) = 866/978 = 0.89。
R = tp/(tp+tn) = 866/(866+340) = 866/1206 = 0.72。
F = 2 *((P * R)/(P + R)]= 2 *((0.89 * 0.72)/(0.89 + 0.72)]= 2 *(0.64/1.61)= 0.80
对于这些基准测试结果,我们将它留给下一个博客来进行有趣的观察和更详细的说明、分析和讨论。
总而言之,我们的作为真实产品基础的解析器在正式的新闻文本以较小的领先 (不到两个百分点,两个系统其实都已经接近专家的性能),在非正式文本中以15个百分点的巨大优势,均超过了谷歌的研究性系统SyntaxtNet。因此,可以肯定的是,谷歌的SytaxNet绝不是“世界上最精确的解析器”,事实上,在适应现实生活中的各种类型的现实世界英语文本时,它还有很长的路要走,才能接近Netbase解析器。
有道翻译 http://fanyi.youdao.com/ 自动翻译自我的领英博客:
https://www.linkedin.com/pulse/untrue-google-syntaxnet-worlds-most-accurate-parser-wei-li/
[Related]
Announcing SyntaxNet: The World’s Most Accurate Parser Goes Open
Is Google SyntaxNet Really the World’s Most Accurate Parser?
K. Church: "A Pendulum Swung Too Far", Linguistics issues in Language Technology, 2011; 6(5)
Pros and Cons of Two Approaches: Machine Learning vs Grammar Engineering
Pride and Prejudice of NLP Main Stream
On Hand-crafted Myth and Knowledge Bottleneck
Domain portability myth in natural language processing
Introduction of Netbase NLP Core Engine
Overview of Natural Language Processing
Dr. Wei Li's English Blog on NLP