立委按:这两天跟大模型压缩理论干上了,发现,这里面目前在市面上仍然充满了迷思和误解。要命的是,压缩问题是大模型革命的首要问题,反映了大模型背后的奥秘和上帝之光。感觉到了正本清源的时候。 我以为,当代生成式AI及其大模型的大爆发,其中有两个相互关联的核心问题,最值得花时间搞明白,否则就好比允许自己生活在中世纪的黑暗中。第一个是序列学习如何解锁了万能任务,让通用人工智能成为可能,AGI不再是民科或科幻。这个问题我写过多篇博客试图解说,虽然不敢肯定是不是传达准确了。第二个就是大模型智能背后的压缩理论。这个问题直到最近才算梳理明白,脉络和原理清晰起来。觉得值得分享一下心得。
在大模型无损有损的争论中,产生了很多迷思,其中一条是:智能就是无损压缩,或,无损压缩产生智能。
错!两条都错。
压缩产生智能,没错。但绝不是无损压缩产生的智能。
存在一个认知误区:很多人把训练阶段的智能性压缩(有损抽象)和一种特定应用的技术性压缩(无损编解码)混为一谈。
压缩有两个不同的含义:一个是榨干数据的油水和所有的规律性,逼近理论最优值 (K-complexity),这才是压缩的正解,智能的体现。第二个指无损压缩,要求可以无损还原始数据。无损压缩/还原不是一个真正的智能目标,它最多不过是一个应用需求(例如在存档、传输等场景)。大模型已经证实可以高效赋能无损还原数据,智能在这里起的作用是让无损压缩提高效率,即提升压缩率。
无损压缩直接服务于无损还原,无损的标准是输入信息在输出中必须达到100% 还原(bit level,包括瑕疵)。可见,离开形式标准,谈不上无损。这与极致的信息压缩不同,极致压缩的对象可以是形式,也可以是内容。前者等价于(极高压缩率的)无损压缩,但后者才是“压缩即智能”的真谛。看清这一点是破除迷思的关键。
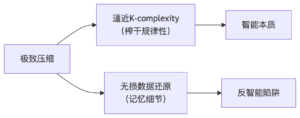
GPT作为通用智能体,其核心价值在于:生成任务中的创造性失真(多数应用场景),而无损压缩仅是技术副产品(少数应用场景,例如存贮和传输),且该能力与智能水平仅弱相关(与压缩率高低直接相关,但与无损还原宗旨无关)。
试图用无损压缩能力证明模型智能并不合适,如同用书记员的速记能力衡量立法者水平 —— 两者本质不同路径:
智能压缩追求最小因果生成规则(K-complexity路径),需主动支付抽象税;
无损压缩追求数据还原保真度,导致牺牲模型的简洁性。
GPT的革命性在于前者,后者仅是技术副产品。在生成、推理等主流场景中,创造性失真才真正是智能的闪光点,虽然其副作用幻觉在特定任务场景成为大模型与生俱来之痛。
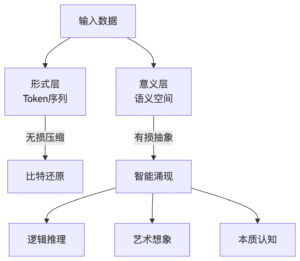
以下一词元预测(next token prediction)作为自回归训练目标的GPT,貌似是形式压缩,因为下一词元是其黄金标准。但实际上,它是不折不扣的意义压缩。微观层面,下一词元预测准不准并不是在形式层面看模型输出token与黄金标准能否匹配,而是通过token 内部表示的交叉熵(cross entropy),是在衡量输出与黄金标准在意义空间之间的吻合度。宏观层面,GPT的训练对象是大数据整体,而不是数据个体(一段话、一首曲子或一幅图)。无损压缩/还原在数据个体具有明确定义(100%还原形式),但面对大数据,这个定义实际上不可行(除非是原数据存贮)。换句话说,大数据压缩决定了它只能是意义层面的压缩,挖掘大数据背后的规律性。
就GPT赋能无损还原的应用而言,大模型的理论基础柯氏复杂度(Kolmogorov complexity,K-complexity)支持“有损训练-无损应用”框架。柯氏复杂度追求的是最小生成程序,而非数据还原能力。训练阶段,有损压缩是逼近柯氏复杂度的唯一路径;应用阶段,无损还原得益于GPT的规律性可以做到前所未有的高压缩率。
其实,著名的大模型训练的经验法则 scaling law 就是这么来的。这个经验观察及其洞见说明了有损是智能的必需:数据必须远大于模型才能有智能提升(否则模型就会“偷懒”,在庞大的参数里死记硬背过拟合,而不是不断压缩和泛化)。
换一个角度看,无损还原是算法属性,与柯氏复杂性并不直接相关。实际上,无损还原的实验表明,算法永远有办法达到无损的目标。本质上:无损还原 = 模型 + delta。这个 delta 就是模型缴纳的抽象税,是模型没记住也不必记住的细节。实践中,用强大的模型,delta 小一点;用弱小的模型,delta 就大一些。无损压缩算法不过就是在玩这个游戏。应用阶段,模型质量影响效率(压缩率),但不破坏无损性。delta 等于零,意味着模型记住了所有的细节,这要求模型趋向于无限大,或外挂巨大的硬盘。另一个极端是模型无限小,或没有模型,那就退化成彻头彻尾的硬盘了。不考虑压缩率:白噪声的 K(x)≈∣x∣,仍可用无损压缩(如ZIP)精确还原。
教科书中,柯氏复杂性定义为数据内在结构的度量,即“the length of the shortest program that outputs the string”,uncomputable,理论上不可计算。而无损压缩被视为一种工程实现手段,用于数据的精确还原。大模型的出现,经多位学者验证,的确大幅度提升了无损压缩的压缩率,但并不改变无损压缩只是一种工程工具的本性。当然,大幅度提升压缩率本身也表明,大模型对于数据分布规律性的把握达到了前所未有的高度。就复杂性理论而言,无损压缩/还原常常是个误导。但无损还原的时候压缩率高,的确是大模型高智能的一个很强的佐证,因为没有其他知识系统能胜过它。
另外,这个话题还有一个要点是时间维度。压缩的对象是历史数据,预测的应用指向未来(模型作为预言家),可还原却说的是历史数据。这意味着,即便无损压缩/还原做到了极致的压缩率,也与真正的预测能力有距离,因为这里面隔了一层时间的墙。关键是,智能的本质偏爱未来预测,而不是历史还原。未来预测必须有随机采样的空间,但还原历史却恰好扼杀了这种有益的随机性。