【大数据挖掘:转基因英文网络的自动民调和分析】
屏蔽 |||
前不久做过几个转基因在英文社交媒体的自动民调,引起广泛兴趣。不过,那几次民调都是用的最近一个月的社媒数据。很多朋友希望做一个较长时期的调查,看看西方(主要是美国)社交媒体中转基因的媒体形象及其口碑民意的演变趋势。超过一个月的数据会产生额外的数据费用,因此甚至有热心网友提出愿意筹款资助这项调查。
既然转基因是大众如此关心的热点话题,我们就拿它当小白鼠,继续做系列大数据自动调查,用海量数据粉碎少数匿名极端分子散布的大数据调查涉嫌“输入伪数据”的谣言。博主保证在话题定义和输入给系统以后,相关的原始数据搜索及其自动分析全过程没有任何人工干预。这一点是由我们的大数据产品的性质决定的。产品允许以不同的 filters 来做对比研究,博主保证对比调查中的任何 filter 都明确标示,默认为不使用。各位谨记的是,大数据是客观的存在,大数据不会说谎,但是对数据的下列解读(interpretation)不可避免有主观的成分。欢迎百家争鸣,对这些数据做出不同的解读,也欢迎对数据挖掘的条件和过程提出建议和质疑。(但不欢迎任何极端分子的胡搅蛮缠无理取闹,博主保留对任何极端或不雅留言杀无赦不解释的权利。)
转基因一年来英文社会媒体口碑的自动民调和分析如下。
(1)话题的定义和输入:GM food | GMO | genetically modified | transgenic | transgene | genetically engineered food | GMF | Franken-food
与前同(删除了歧义严重的害群之马 GMC)。
(2)自动民调结果总览
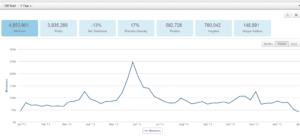
尝试解读:一年的自动调查提及转基因485万,调查了383 万多社交媒体的帖子,涉及近 15 万网民。这是真正的大数据民调,比传统手工民调最多几千份问卷,数据量和调查对象要高两到三个量级。转基因的一年大数据的平均褒贬指数为零下13度,比前几次的一个月数据的调查要好(虽然仍然是负面评价为主)。转基因的话题在西方社会媒体中,的确很有争议。

尝试解读:一年的提及转基因话题的帖子,有 28% 的帖子(134万)含有褒贬评价或情绪,其中贬(57%)略大于褒(43%)。褒贬的幅度区间在 6 度最高点(见上图最高红点旁 tooltip 小框)到 零下 32 度(上图最低谷的红点处)之间。值得注意的是 2013 年六月是转基因网络热议的最高峰,而这场热议却使得转基因褒贬指数跌入最低点零下32度。
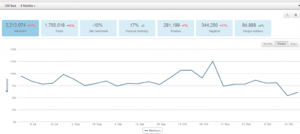
下面是最近半年的数据,褒贬度为零下10度,略好于一年的指标。
(3)共现话题:

尝试解读:多次挖掘都是如此,与转基因最密切的主题永远是 Monsanto (孟山都)。说转基因纯粹是科学问题,那是 too simple and naiive,只要背后有企业,就一定有利益因素。
(4)挺转反转的理由词云:

尝试解读:正反理由旗鼓相当的样子,这比以前一个月数据的调查大为改善。反转的最大理由不再是 gluten 相关的疾病,而是死亡(Die)和癌症(Cause cancer)。挺转声音强调的是安全(safe),也是很自然的。
(5) 挺转反转的情绪词云:

尝试解读:wow,情绪云图中挺转的分贝(那些大大字体的 love,good,great)似乎比反转的(bad,not want,concerned,fear,hate,fuck)更高(表现为更大的字体),不过后者的表达更加多样化。
(6)挺转反转的行为:

尝试解读:挺反双方不仅仅是情绪发泄,还有行动,有吃的用的买的(eat,use,buy),就有拒吃拒买甚至要求禁止的(not eat,not buy,reject,ban)。
(7) 挺转反转的比例

(8)社媒样例:还是贬大于褒嘛。

【转基因大数据挖掘系列博文】
【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】 2014-01-03
【大数据挖掘:转基因网络口碑的自动民调和分析】 2014-01-03
 只认数据不认人:IRT 的鼓噪左右美国民情了么? 2013-12-30
只认数据不认人:IRT 的鼓噪左右美国民情了么? 2013-12-30
[转载]ZT: 为啥立委的报告认为GMO造成gluten intolerance 2013-12-28
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么 2013-12-26
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24

 大数据崇拜要不得
大数据崇拜要不得