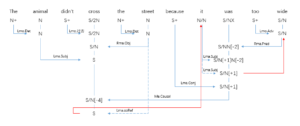
李:看到 attention 机制一个图示:

这可算是 attention 机制可视化以后,明确显示其解决了 pronoun coreference 的难题。看前后两句 it 与 animal 和 street 的关联强度就明白了:
1. The <animal> didn't cross the street because [it] was too tired.
2. The animal didn't cross the <street> because [it] was too wide.
这只是过程中其中一幅 attention 的图示化,图中没有显示其他两两 attentions 的图示(包括 it/animal/street 与 wide/tired 的两两关联度),看完就知道形容词(wide/tired)与 host noun(animal/street)之间的相谐性,是如何对 it 的 coreference attention 的影响力了。
这种两两配对的机制 简直令人发指地有效 而且有解释性,也不怕爆炸,反正所谓 multihead self-attention 机制都是可以并行计算的,大不了多上GPU,费些电而已。
白:怕不怕干扰?
李:不知道 不过就看到的这个结果,已经让人嫉妒得咬牙。好玩的插曲是,下面留言貌似还有个“理呆”傻傻地问:老师 为什么 it 与不相干的词 wide 有很强的关系?这位学生理解了 it 与名词的关系 却不能理解与形容词的关系,哈。
白:我们的观点是,it与其所指建立关系时,会把所指的本体标签复制到it这里来,然后跟tired/wide检查相谐性就是邻居之间的事情了。飞线不是白拉的,是有本体标签输入的。

特别是,飞线的建立,是在各个chunk内部的萝卜填坑都搞定的情况下才会发生。而内部填坑就意味着,it的分子萝卜已经被chunk内部的坑所同化,不相谐的百毒不侵。相谐的一路绿灯。
李:感觉是 如果句子处理满足下列条件,能穷举两两关系 而且有足够数据训练去计算这种关系,那么我们引以为傲的结构,其桥梁价值就会趋近于零,因为位置信息加语义相谐的 attentions,应该可以搞定这种 hidden correlations。这样说来,attention is all we need 即便从字面上看 也说的不错。
自然语言说复杂也复杂 但说简单也简单。简单在于,有无穷无尽的语料,预训练可以发掘很多语言知识。到下游应用的时候 单位开始变小,小到一句一词 大也不过一篇文章 对于 attention,这都不算事。(也有人现在尝试把 input 扩大到一组文件,来做跨文件自动摘要,结果也让人开眼)。
白:NN容纳了结构,正常。
李:可几年前,我们是不相信神经系统可以搞定 long distance(hidden) correlations 的,当时觉得非符号结构不能的。这个不服不行。
白:
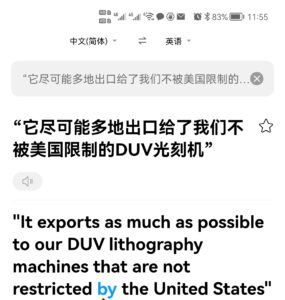
在这个模型看来,光刻机是“我们的”了。其实是“它的”。“我们”的间接宾语角色没有被揭示出来。如果没有那个“给”,这一切本来都是说得通的。
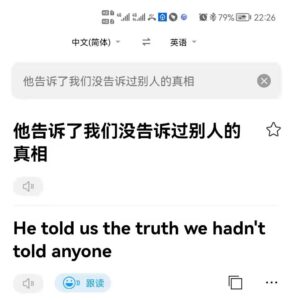
谁没告诉别人?
李:是 he,不是 we。嗯,这两例的确没搞定,也更 tricky 一些,有间接宾语干扰项。再等两年,等最新机制和方法慢慢渗透消化部署到商用神经翻译系统后再看看搞定了多少。总之,总体方向上是向好的,我觉得。越来越多的“非低枝果实”正在被神经吞噬,一个幽灵在地球徘徊......