【立委按】这阵子研读NLP当前最核心的 transformer 框架及其注意力机制入迷。注意力机制是主流AI最给力的 transforner 框架的核心,神一般的存在。这个框架是当前最火的预训练超大模型的基石,被认为是开启了NLP新纪元。网络时代的好处是,只要你对一个专题真感兴趣,就会有源源不断的信息奔涌而来,更不用说这么火爆的专题了。音频、视屏、文字可谓汗牛充栋。各种讲解、演示,深浅不一,相互交叉印证,非常过瘾。光入不出,非君子所为也。一己之得,演义如下,与同好分享之。
世界的未来在AI。AI 的皇冠是 NLP。NLP 的核弹是大模型。大模型的威力靠transformer。Transformer 重在编码器(encoder)。编码器的精髓是自注意力(self-attention)。
今儿我们就来说道说道这个自注意力机制。
注意力机制是那种乍一看特别让人懵圈的东西,但原理却很直白。说到底就是聚焦机制,用一层又一层过滤网,虚化周边杂讯,突出一条条隐藏的关联信息。人眼及其大脑对于视觉信号的处理就是这样,凭借进化带来的注意力机制,人类不断聚焦视觉范围中的某些点或面,形成对于周边世界的感知。视觉信号绝不是不分主次一起同时进入我们的感知。
回到NLP的自注意力机制应用。一段文字,或一句话,理解起来,说到底就是要找到词与词之间的关系。从 parsing 的角度,我们主要是看句法语义的关系。现在已经很清楚了,所有这些关系基本都被注意力机制根据相关性捕捉到了。
说注意力机制让人懵圈,主要是说它的技术实现初看上去不好理解,绕了好多弯,很容易让人堕入云雾。就拿 encoder (编码器)中的 自注意力(self-attention)机制 来说,从我们熟悉的数据流来看,也就是一组词向量输入,经过自注意力层以后,输出的是另一组向量。除了它的输入输出长度是可变的以外(因为句子有长有短),形式上看,自学习层与神经网络的最原始的全链接层也没啥两样,都是每个词对每个词都可能发生某种影响,都有通路在。
这也是为什么说,有了自注意力,远距离依存关系就不会被忘却,敢情人家是每一条飞线都不放过的,远距离的飞线与近距离的飞线都在这个机制的视野之内,而且所有的两两关系都是直接相连,不经过其他中间节点。(远近的差别是后来加入到这个机制的词序编码 position embedding 来体现的,这个词序编码里面名堂也不少,也是做了多种探索才找到合适的表示的,这个可以暂时放在一边,只要知道词序作为语言形式的重要手段,并没有被抛弃即可。)
输入的是词向量 X,输出的是与X等长的词向量 Y,那么这个 Y 怎么就与 X 不同了呢,自注意力到底赋予了 Y 什么东西?
这与我们符号这边的 parser 有一比:输入的是线性词串 X及其符号特征,输出的是依存结构关系图 Y。实质上并无二致。
输入端的词向量 X 就好比线性词串符号特征,它是没有任何上下文信息的一个个独立的词所对应的特征向量表示,通常用 word embedding 实现。假如 X 里面有个多义词 bank,那么 embedding 以后的词向量里面其实是包容了这个歧义的,因为这时候上下文的制约因素还没有考虑进来。
而 Y 则不同,Y 是通过自注意力的变换把上下文带入以后的表示。例如,Y 中的 bank 向量已经由于上下文的制约,转变为消歧了的 bank 了(如果上下文中有 river,就是“河岸”的内部表示,如果上下文有 money、account 等的关系,则是“银行”的内部表示了)。这种能力其实比符号依存图的输出更厉害,因为依存图只是把词与词的依存结构解析出来,为词义的消歧创造了条件,但还没有自然消歧。
搞清楚输入输出 (X --> Y) 是理解自注意力的目的的关键,语言就是通过自注意力机制把语言形式编码为特定语境中的语义。说到底,自注意力就是一种“向量空间的 parser(这样的 encoder 可称作 vector-parser)”。
从8000米高空鸟瞰这种神奇的机制,是极度简化了它。真正实现这种 vector-parser 功能的不是一层自注意力,而是n层自注意力。每一层自注意力的叠加合力,造成了 X 渐次达到 Y。这也符合多层网络的本义,与多层自动机叠加的符号parser模型也是同样的原理。
再往里面看究竟,更多的花样就会逐渐呈现。每一层自注意力并不是只是在节点之间拉上飞线就训练出各自的权重(影响力),那样的话,就回到最原始的神经网络了,无法对付语言这样的 monster。
这就引来了注意力机制的魔术般的设计。我们假设X是输入向量序列(x是其中的词向量, x1, x2, ...xn),Y是输出向量序列(y是其中的词向量, y1, y2, ...,yn)。简单说,就是让x先1体生3头,然后再一体变多体,最后才变回为与x对应的y输出。如此叠加累积这才完成 X--> Y 的语义理解。
先看1变3,就是把每个词向量复制三份,人称三头怪兽。发明者给这三个头起了名字: Query,Key,Value,说是受到了数据库查询的启发。这种比喻性的启发既带来了方便,也造成了混乱,因为向量变换与数据库查询最多是一半相似。比喻都是跛脚的,可这次却是坑苦了几多学员。
先从相似的一面谈背后的原理和设计动机。第一个问题是:为什么要一词生出三头呢?
这是因为 vector parser 的目的是寻找词与词之间两两依存关系。而任何两词的依存关系都涉及两个词 x(i), x(j)。为了捕捉这种二元关系,第一个要确定的是谁具有这些关系,这个主体谁就是 Query。这就好比相亲,谁是相亲的发起者,谁追的谁?被追的那个就叫 Key。
因为一句话(或一个段落)中,每个词(x)都是自我中心的,每个词都要通过与上下文中其他词之间的两两关系来重新定位自己为 y,因此每个词都在不同的时间里充当求偶者,也在不同的时间里充当了被(追)求者。这就是为什么每个词节点都要设计 Query 和 Key 的原因。
那三位一体中的 Value 是怎么回事?这就是比喻害人的地方了。本来按照数据库查询的类比,当词 x(i) 作为自我中心的 Query 的时候,它去追求(查询)其他的某个词 x(j) 的 Key,两人相亲就是匹配一下,是不是看对眼了。数据库中的 query 与 key 匹配上以后,就会从数据库中返回 key 所对应的 value,是不是说,把 x(j) 的第三头 Value 返回来,就大功告成呢?
完全不是这回事。
实际的相亲以及建立关系的过程要“绕”得多。乍看简直诡异,慢慢消化了才会拍案叫绝。这种东西本来应该是上帝的不传之码,不知道怎么就流入人间,成为打开任何符号(不仅仅是语言文字符号,一样适用于各种音频、视屏符号)编码的钥匙。福兮祸兮,就好比是伊甸园的禁果,人类掌握了AI密码以后是加速自“作”而亡的节奏,还是提升了人类的福祉,就不好说了。但对于人的求知欲和征服欲,这无疑是核弹一级的刺激。
此处就会涉及一系列数学公式。非理工出身的人立马就堕入迷宫,但其实是纸老虎,它倒腾来倒腾去也就那么几个公式:一个是相亲前换套衣服好让Query与Key可以做匹配交融,一个是向量之间的“相乘” (MatMul,又叫 dot product),就是相亲交融本身,合二为一的内部其实是在计算二者的文本相似度(cosine距离),然后是 scale 和 soft-max,就是把相互关系的强度量化成概率百分数,等于是相亲后把各种满意不满意的感觉汇总打个权重总分,最后就是对所有的对象做加权求和(权重就是softmax刚打的分),然后与本人的 Value(第三个头)相乘。原来,Value 是本体 x 变形为 y 的基础,与其相乘的向量就好比一张过滤杂讯的网,使得变形了的 y 是突出了上下文关系的本体表示。总之,这一通折腾,才计算出真正的输出结果 y。“我”(自我中心的那个 x)已经不再是单纯的、青涩的我,而是成为关系中的我(y)。每个词都这样脱胎换骨一次,于是,奇迹发生了,符号被编码成了结构和意义,上下文的信息被恰到好处的捕捉进来(如果训练数据足够海量)。
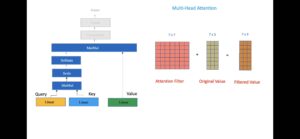
上面说的是三位一体的本体 x 如何与环境交互变成了 y,但实际上为了便于注意力聚焦在不同的关系上,编码器都是设计成多头(就是很多个三位一体的组)注意力的叠加。这就给了每一组注意力以足够的空间去专注到某一种关系的抽象,而不是分散到多种关系去。这样的多头设计,在几乎无穷无尽的超大语言数据的无数次的迭代训练(back prop训练算法利用参数的梯度下降拟合实现)来逼近语言本身,所用的技巧就是无穷无尽的语言填空:例如在语言数据中随机抹去 25% 的词,然后训练模型根据语言的上下文信息去尽可能正确填空,从而把所谓自学习转变成经典的监督学习,因为黄金标准就在被遮蔽的语言符号里面。
上面略去了可以训练得到的参数设计的细节,其实也很简单,就是给每一个 Query,Key,Value 旁边配上一个相乘的权重参数矩阵 Query*W1,Key*W2,Value*W3,来记录符合训练数据的权重参数值,这样的训练结果就是所谓语言大模型。
AI/NLP 是实验科学。就是说,上面这通神操作虽然也需要有设计哲学的启发和规划,也需要有各种灵感的激发,但归根到底还是很多人在无数次的试错中通过输入输出的最终验证找出来的道路。而且多数神奇结果都是发明者最初没有预料到的。信息表示在神经网络内部的数据流(tensors)中千转百回层层变形,这样出来的语言模型居然具有赋能各种NLP下游任务的威力,这其实超出了所有人的想象。对于越来越深的多层系统,我们一直固有一种错误放大(error prop)的顾虑,所谓差之毫厘失之千里,怎么保证最终的模型是靠谱的呢?
这种保证源于训练数据的规模。超大数据就好比牵住风筝的那根线,任凭风大云高,风筝翻飞,只要那根线足够强壮,它就不会离谱。监督学习的奥秘就在目标驱动,注意力为基础的所谓自学习被大数据监督学习罩着,超出人类任何个体能力的大模型就不奇怪了。
有研究表明,这种模型内部捕捉到的种种关系可以图示化,显示各种句法关系、指代关系(例如 it 在上下文中与谁绑定,见图示)、远距离逻辑语义关系、常见的事实关系等都在它的表示网络中。

这张大网到底能推动多少NLP落地应用,开花结果,目前处于进行时。好戏刚刚开场,精彩值得期待。
谈到落地应用,就不能不提 transformer 的另一半 decoder(解码器)了。如果说编码器的宗旨是消化理解自然语言这头怪兽,得到一种内部的语义表示,解码器的作用就是把语义落地到下游NLP的各种应用上,包括机器翻译、自动文摘、信息抽取、文本分类、文本生成、知识问答、阅读理解、智能助理、聊天机器人、文字转音(TTS)、文字转图、文字转代码等等。值得强调的是解码器同样要用到注意力机制,事实上注意力机制的发明使用是先从机器翻译的解码器开始的,然后才平移到编码器,改名为“自注意力机制”。编码解码的注意力机制实质相同,区别在于解码器为了语义落地,Query 来自目标应用端的词向量,匹配的却是编码器中的 Key,以此作为语义的连接,从而实现目标应用的软着陆,赋能NLP应用的开花结果。这里的细节可以另文讲述,但原理上与 parser 以结构语义赋能NLP应用相同。
现在回头看自然语言及其NLP的历史,无论有意无意,上帝显然是犯了两个泄露天机的错误。第一个错误是让符号语言学家寻找到了语言结构的奥秘。第二个错误就是把意义的真谛赋予了数据科学家的向量表示。从此不可收拾。
有文为证。我在《科普小品:文法里的父子原则》中写道:
“话说这语言学里面有一门学问叫文法。学文法简单来说就是学画树。各种各样形态各异的树,表达了语言的多姿多彩,却万变不离其宗。奇妙啊。当年上帝怕人类同语同心去造通天之塔,乱了天地纲常,遂下旨搅乱了人类语言。印欧汉藏,枝枝蔓蔓,从此语言的奥秘就深藏不露。于是催生了一批文法学家,试图见人所不能见,用树形图来解剖语言的结构。忘了第一个画树的人是谁,感觉上这不是人力可为。天机不可泄漏,泄漏者非神即仙。历史上有两位功力非凡的文法神仙专门与上帝作对,各自为语言画树,一位叫 Tesnière,另一位就是大名鼎鼎的乔姆斯基。”
我的另一篇科普博文中也有过预警:
“语言是何等神器,它是交流的工具,知识的载体和合作的基础。人类一旦掌握了共同语言,齐心造反就容易了,绝不会安于伊甸园里面吃吃果子。真神于是有些怕了,决定搅乱自然语言,使得人类不能顺畅交流,内讧不断。这才有人类世代努力建造通天塔企望大同而不成。直到如今,世界仍不太平,语言依旧混乱,战争和恐怖时有发生。尽管如此,人类还是迎来了电脑革命的新时代。”
人成为上帝,还要上帝吗?
【后记】 这个话题足够重要,所以花了很多功夫调研消化然后介绍出来。本来太多人写这个题目,不少我一个科普介绍。但既然学也学了,就吐出来,力求与其他人写的东西,角度或风格有所不同,也算是一个老司机对科普的贡献。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)