
鲁为民:“惨痛的教训”和ChatGPT的规模优势,写了这篇短文,希望各位指正。有些想法之前在群里请教过;也借用了白老师的“对接派”和“冷启派”之说。我这个东西只是点到为止。
立委:先提一句,zero-shot/one-shot/few-shot 等,翻译成“零下、一下、几下”不大好理解,主要是 “下” 是个太常用的汉字,感觉不如 “零样例、单样例、多样例”,或“零剂量、单剂量、多剂量”,甚至“零射击、单射击、多射击” 来得贴切。
鲁为民:这个主要觉得与"shot" 同音,将错就错。
立委:
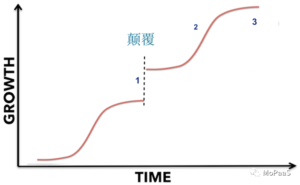
对于貌似无止境的 S阶梯形跃升,所谓“涌现”(emergence),现在大多是观察的归纳总结。为什么会这样,为什么发生超出想象、不可思议的现象和超能力, 很多人觉得是个谜。
以前很多年的AI统计模型(以及符号模型)的归纳总结都是,随着数据的增长,模型就会遭遇天花板,趋向于 diminishing returns,也就是说只有一个 S,不存在上图所示的阶梯形多个S状。
单S学习观也似乎符合我们的直觉:毕竟从统计角度看数据,数据量的成倍、甚至成量级的增长,带来的主要是海量的信息冗余,而净增的知识面只会越来越小。所以多快好省的学习模型要适可而止,以防边际效用的锐减。
可这一常规却在可以深度学习不同层次注意力patterns的巨量参数模型中突然被打破了。于是 奇迹涌现了。想来想去,个人觉得阶梯式多S型学习其所以创造奇迹、发生涌现,大概归结为下列几个条件和理由:
1. 学习对象必需有足够的可学的内容:自然语言正好满足这个条件。
以前我们做NLP的学习任务,一律是单一的,学习 parsing 也好,抽取信息也好。单一的任务角度,可学的目标是相对有限的,数据量的无限增长不可能带来无限可学的标的,因此学习过程遵循单S趋势,跟爬山似的,快到山顶的时候,再多的力气也很难带来进步。
可是自学习预训练的LLM改变了这一切。LLM没有特定的任务目标,或者说其最终是服务多任务,难以事先确定种种语言任务。这样一来,学习对象本身的知识承载力才是理论上的天花板,而这个天花板简直就是星辰大海,无边无沿:人类文明诞生以来的一切知识的承载,尽在语言中。
LLM 到了 GPT3 的规模,也不过就是划过了知识的冰山一角(以前提过,毛估估也就 20%左右),这学到的百分之二十知识,从ChatGPT的表现看,里面目前涉及几乎全部的语言知识(有词典知识、词法知识、句法知识、篇章知识、修辞知识、风格知识、对话知识、应用文知识、文学知识),外加漂在人类认知上面的基本常识、百科知识、部分逻辑推理知识等。也就是说,从AGI的视角,自然语言本身作为知识/能力的源头和对象,还有很多可以学、但还没学完的内容。仰望星空,一眼望不到天花板。
2. 学习表示必须有足够的容量:单单对象本身有各种层次可学习的内容还不行,学到了必须有足够的空间放得下才行。这个条件也在不断满足中:在一个对应与billion级token数的billion级参数的多维向量空间中,LLM们的表示空间较之深度学习革命以前的模型是大得太多了。
3. 学习过程必须有足够的深度和层次:这个条件也具备了,拜深度学习革命带来的多层网络所赐。尤其是 transformer 框架下的LLM内的注意力机制所赋能的学习和抽象能力,非以前模型可比。
阶梯式学习(超能力“涌现”、奇迹出现),上述三个条件缺一不可。
这一切要落实到实处,要靠海量的计算条件和工程能力。大厂,或由大厂做后盾的团队(例如 Open AI),具备了这样的软硬件能力。
于是,ChatGPT 诞生了。
鲁为民:还有很多东西值得进一步考虑,比如 Transformer 非常神奇。Anthropic 通过分析和实验发现,Transfornmer 的Attention Layer 可以激发 In-Context Learning 能力。而后者是 Prompt-based learning 的关键。
另外,顾老师的几何基础工作,还可能有助于进一步解释为什么高维稀疏的大模型泛化的能力局限。
立委:这里面水深了。谜底要专家们细细研究总结了。
顺便一提:大赞顾老师,虽然细节看不懂,还是一口气看完,欣赏的是横溢的才华和见识。
鲁为民:In-Context learning 需要了解清楚。这个被认为是大模型的 emergence 能力。 这个解释也有很多。除了Anthropic 的解释外,还有Stanford 的基于 Bayesian 推理的解释也说得通。
这个in-context learning 也只(碰巧)对人类够用了,它还只是 interpolation, 或者刚好在 extrapolation 的边缘。我感觉顾老师的几何理论接下去可以去解释清楚了。
立委:这是 few shots 的奥秘。
few shots 既然没有线下的微调训练,怎么就凭着几个例子,跟人类一样能举一反三,现场就学到了 open ended 的任务呢?只能说这些能力LLM都已经蕴含其中,few shots 就是把蕴含在内的能力激发出来,并现场调适对齐。这已经足够的神奇和不可思议。可是到了 instructGPT 和 ChatGPT,few shots 的模式和能力却放到一边了,进阶到了 zero shot,完全的概念化。这已经是 “beyond 神奇”了!
当然,这个 zero shot 的奥秘宏观上讲就是所谓人类对齐(RFHF)的功劳。可到底是怎么奏效的,还是雾里看花。读了 instructGPT 的论文n遍,所说的与人类偏好对齐的各种操作虽然设计精巧细致,但毕竟对齐工作的数据只是原大数据的一滴水而已,居然有点石成金之效,让人惊掉下巴。
鲁为民:这个我还是欣赏John Shulman,他真将离线 RL 用活了。
立委:本来以为他们会沿着 few shots 的路线,把革命进行到底呢。毕竟 few shots 已经把需要大数据标注的知识瓶颈给“解围”了,prompt engineering 也符合低代码的大趋势,前景足够诱人。比起传统的监督学习不知道要高明多少。谁料想他们一转弯即刻就瞄准了 zero shot 去吊打自然语言以及NLP,爽快利落搞定了人机接口,这个弯转的,简直是神来之笔。
如果坚持 few shots 虽然也还算很大的创新,但绝不会引起ChatGPT这样的核弹效应。也不会让无数人浮想联翩,让大佬如比尔盖茨对其几乎无限拔高,说堪比电脑发明和互联网问世。
鲁为民:这个是不是 Open AI 首先(在GPT-3 paper)明确提出这个?这个提法应该不trivial
立委:不知道谁发明的,但肯定是 GPT3 (playground)与 DALL-E 2 以后才广为人知的。prompt engineering 成为热词,形成小圈子的热潮也主要是 Open AI 的功劳。
给我们科普一下 学习中的 interpolation VS extrapolation 机制吧。举例说明
为民:简单说,interpolation (插值) 是预测的点在样本空间里。extrapolation 则在外。足以让人沮丧的是: LeCun 和他的博士后证明,对于高维空间预测问题(大模型属于这个),几乎都是extrapolation 问题。高维问题很难直观解释。
立委:
希望这是靠谱的,没有参杂胡说。
鲁为民:赞。但这两个词不是机器学习专有的概念吧。是不是统计或数值分析的概念
立委:隐隐觉得这个可能开始有胡说的侵染了吧?

鲁为民:好像你怎么问,它就怎么圆,lol
我觉得interpolation 和extrapolation 的概念在DL里只是 (或LeCun这里) 被借用并扩展(https://arxiv.org/abs/2110.09485):

白硕:数学上早就有。
梁焰:内插法外插法是数值分析里的方法。80年代末学《数值分析》的时候就学这个。它有点像在已有的框架结构内部外推。
宇宙学里的 “大爆炸”模型,也是外插出来的。所有数据都表明,宇宙婴儿期有一次空间的急剧膨胀。
白硕:统计也是啊,已知满足正态分布,在此前提下估计参数。
鲁为民:是的。如果要说真正的 emergence, 那就得外推(插) 。这个问题不解决,通用人工智能(AGI) 不可能。所以人类可能无望自己实现。AGI 要靠 ··· AI 自己进化实现。在这之前,人类可能会不断(前仆后继地)宣布实现 AGI 了。
白硕:向量可以肆无忌惮地内插外插,符号不行。符号泛化,遵从归纳法。这也是符号的劣势之一。要想在符号的世界任意泛化,需要有理论上的突破。
立委:我的体会那是符号泛化(generalization)操作的前提或公理。分层分级的各种generalizations 都是放宽不同条件,它是有来路、可追踪、可解释和完全可控的。
鲁为民:是的,要逃出如来佛的手掌才能外推。
梁焰:是的,泛化需要理论突破。
鲁为民:机器学习的名词千姿百态,很多都是借用其它领域。@白硕 @梁焰
机器学习的外插就是一种 Overfitting, 可能会很离谱,所以外插也不能肆无忌惮啊。
邬霄云:有一个细微的区别,符号 in interface or in implementation? 感觉@白硕 老师说的是 in implementation, 因为界面、输入、输出依然是符号,只是在计算输出的过程给向量化了 。人的处理是不是有时候也这样, deduction and induction r just 符号化过程,以方便解释给别人。
有的人是可以知道结果,但是过程解释不出来。少 ,但是见过。chain of thought is related here , 感觉。
白硕:不一样,因为泛化确实是在欧氏空间里进行的,不是在符号空间里进行的。
霄云:sure. Implementations are in vector space, but projected back to symbols.或者说,我们要逼近的函数是在符号空间里有定义的,我们的入口在符号空间里。
梁焰:如果输出在符号空间中没有定义,那我们就为它定义一个新符号,新的概念也许就这么出来了。
邬霄云:exactly. If it is useful eventually it will be accepted into common.
只是它的implementation is done by mapping to vector space and back. And the behavior of that implementation in vector space does suggest some sort of generalization in symbolic space.
白硕:这个说法存疑,既然谈逼近,就要定义邻域。在符号函数上并不能成功地定义邻域,要转到欧氏空间定义。也就是说,并不是符号空间有一个靶子,欧氏空间只是命中了那个靶子;而是,那个靶子在符号空间根本就不存在。
欧氏空间说啥就是啥。
邬霄云:同意 这个view不是很数学严谨。 我的 function 是软件开发里的概念, space 是 loosely used,to make a point about there is a mapping
But for sure the mapping is not one to one , and there are points in vector shape that don’t have direct mapping in symbolic space. So compute is in vector space thus the thing we coined as generalization is implementation in there
立委:如果符号没有足够的空间表示思想,我们如何知道。原则上总是可以一一映射,至少对于成体系的思想。
邬霄云:I actually suspect one day that compute can be symbolized , using methods like chain of thought. Language is universal, so it is conceivable that we can ask it to compute following a path that can be symbolically described.
We don’t until we do. Language is not a fixed thing. It is a result of our spending efforts doing something together. It evolves all the time. Just slow enough so it feels constant.
Brain exists before symbol.
立委:那是显然的,低等动物也有brain,但没有(用)符号。
感知跃升到认知的时侯,符号就与brain纠缠不清了。很难分清先有鸡还是先有蛋。但符号世界的离散特性决定了它总是抓大放小。
梁焰:yes, 符号有一个选择,和“去选择(de-select)”的过程,不断反复地这么做。符号思维,大概是人发明的一种高效省力的思维,但不应该僵化。
邬霄云:思维 是 什么 ? 计算? 计算 in symbolic space? Or compute that can be mapped to some symbolic space ?
梁焰:万物皆算。思维就是在计算。
邬霄云:我 记得 Hinton 说过 neural networks is the compute device
但是,结果是跟大多数什么意见没有关系 的 ,我们需要这种人。我记得我们都去做 支持向量机的时候,他可真的没有咋追风。
立委:语言符号(除了数学语言和公式)通常漏得跟筛子似的,可是它还是胜任了知识的传承 。靠的就是冗余么?车轱辘话其实每一遍都有一点新意,或不同视角或约束。凑在一起,也一样维持了知识体系的逻辑稳定性,很让人诧异的现象。
道理上,LLM 是一种费力而无法完备的路线,看上去就是死路,可是却杀出来迄今最亮眼的认知智能来。这违反我们的直觉,理论上也不好说明。当我们明明积累了浓缩的结构化知识(例如各种知识图谱和数据库),却硬要弃之如履另起炉灶,从粗糙的、重复的、充满了噪音的线性语言大数据用序列训练去学习认知。正常人应该觉得这是一种疯狂和偏执,妥妥的缘木求鱼、南辕北辙,但现在却似乎是走在正道上,有点侮辱人类智能的感觉。
邬霄云:对于大多数人来说,哪种计算管用是最真实的,然后我们去解释就好了 。我们 比较幸运的是我们有感知的领域在 发生 paradigm shifting ,so we get to watch at front seat. Feeling lucky 我们就偷着乐吧。
前几天看到那个 核聚变的 news ,compare to this one , 想想有些行当可能许久没有什么fireworks ,有感而发。这个我们可以 go in meaningful discussions or even think how we can make use of it,核聚变 就没有办法了。
立委:当然现在还没有到笑到最好的时刻。也不知道往后的AI认知路上会不会遭遇瓶颈 来阻拦多S形的学习曲线的前行 。毕竟LLM只搞定了语言,撬动了认知漂在上面的一个小部分。这样来看AI 的话,乔姆斯基理性主义对于大数据经验主义的经典批判论,似乎仍然有站得住的成分。
Minke:
Why people are fascinated about AI?
General public like it, because they think it’s magic;
Software engineers like it, because they think it’s computer science;
Computer Scientists like it because they think it’s linguistics or/and mathematics;
Linguists like it, because they think it‘s cognitive science;
Cognitive researchers like it, because they think it’s philosophy;
Philosophers don't like it, because there is no it.
Meanwhile, Mathematicians like it, because they think it’s mathematics.
立委:fun. And largely true 2.
在隔行如隔山的人类认知环境中 每一个专家都有自己的视角,就像我们难免在与机器打交道的时候,常常忍不住高估了机器,读出了AIGC 本身并不具有的意义 。我们在与其他领域专家打交道的时侯,也难免看高或看低了人家。
AGI 迷思与反思
这两天在琢磨一件事儿。从AIGC(AI Generated Content)琢磨AGI(所谓 Artificial General Intelligence)。
其实直到一两年前,对于 AGI 一直有点嗤之以鼻。主要是这所谓的通用人工智能,其实没有个像样的定义。我就觉得是扯淡,是科技界的乌托邦大饼。当然小编和媒体是从不缺席的,各种鼓吹从来不缺乏,但感觉从业人员如果心心念念 AGI,有招摇撞骗之嫌。
准确地说是自从开始玩GPT-3,逐渐反思这事儿,觉得 AGI 并不是不可以论,至少比乌托邦靠谱得多。
空洞谈实现通用人工智能,有点宣判人类智能终结的味道,感觉大逆不道;而且也永远没有尽头,因为没有验收指标。但是沿着那个思路走,再回头看自从预训练大模型(BERT/GPT等)横空出世以来的AI表现,AI 的确是在通向越来越通用的金光大道上。
回顾历史,AI 过去的成功几乎全部是专项的成功。最早的源头是特定的机器翻译和极窄的专家系统。到了统计年代,也是场景味道特别浓厚,虽然算法有共用的部分,但系统和模型都是专项的,因为数据都是场景的,领域越受限,AI效果越好。这也从AI社区的任务划分上看得出来。拿 NLP 来说,翻译、问答、聊天、摘要、阅读理解、辅助写作等等,都是各自一个门类。岂止是NLP应用的各种任务的分类, NLP 内部的很多事儿,也都各自有自己的任务和社区、竞赛等等:named entity, relation extraction, event extraction, text classification, parsing, generation, sentiment analysis, topic analysis, etc. 这种情形一直持续很久,以至于第一线做实际工作的人,一听说AGI高调,就很不屑。
现在看大模型,这些东西差不多全部统一进去了。如果说这不是通用,或在通用的路上,什么叫通用呢?
通用不仅仅表现在 NLP 天下归一,更表现在多模态AI的飞速发展,同样的基础模型+下游的机理,类似的 transformer架构,在所有的信号任务上,无论是文字、声音/音乐还是图片/美术、视屏,也都能通用了。
预训练以前的时代,AI 深度神经革命(10年前)是从图片刮到了音频再到文字,根本解决了带标大数据的监督训练通用问题。但很多很多场景,带标大数据是匮乏的,这个知识瓶颈扼杀了很多领域应用的可能性。第二波的预训练自学习创新的浪潮是从文字(LLM+NLP迁移学习)开始突破(大约五年前),回头辐射到了视频和音频。以ChatGPT为代表的这第三波通用AI旋风(几个月前),以 zero shot 为标志,以机器学会了“人话”、根本解决人机接口为突破口,也是从NLP开始。
NLP 终于成了 AI 的实实在在的明星和皇冠上的明珠。道理就在 NL 上,自然语言无论有多少不完美,它是难以替代的人类信息的表示方式,没有 NL 在人机对话上的突破,一切AI活动都是精英的玩物。现在好了,门槛无限低,是人都可以玩出大模型的花样和“神迹”出来。
说老实话,AI领域的“AGI风”,是一步一个脚印显示给人看的,完全不是空中楼阁,不服不行。大模型的表现超出了所有人的想象,甚至超出了那些设计者和DL先驱者本人的想象。Open AI 谈 AGI 谈得最多,但这一点也不奇怪,这是因为他们走在前头,他们是在看得到摸得着的表现中被激励、被震撼,谈论AGI远景的,这与投资界的 AI bubble 或小编以及科幻作家笔下的AI神话,具有不同的性质。
这就是这段时间我一直在想的 AGI 迷思破解。
几个月后老友再论涌现
斯坦福最新研究警告:别太迷信大模型涌现能力,那是度量选择的结果。
鲁为民:涌现确实是需要进一步研究。涌现可能更多的是一个定性的概念。不过实验方法有其局限,比如没有观察到的东西,不能证明不存在。1) 涌现确实与模型架构和指标(损失函数等)相关,不同的模型可能不会在类似的规模时呈现,不同模型的涌现出现也有迟早。2) 涌现与测试数据分布相关。3) 涌现不仅仅体现在性能(指标)上,更多的可能体现在其它呈现的特殊能力,包括模型适用于其它很多事先没有训练的任务。4) 涌现与模型执行的任务有关,不是一个模型对所有任务都会在类似的规模时呈现, 不同的任务涌现能力出现可能有早有晚。
梁焰:“涌现”这个词,我看到的最好的翻译是 “层展” ,一层一层(在眼前)展开。涌现,也不是 某新鲜事物自己涌现出来了,它有一个 observer. 所以有 两个 arguments: what 涌现, who is the observer. ( 套用坑理论)
立委:关于“涌现”的感觉,现在看来主要是因为以前的稀疏数据,在超大模型里面实际上不再是小数据。因此,超大模型就表现出来以前的小模型看不到或由于数据稀疏而总结不出来的很多能力。而很多NLP任务都具有稀疏数据(sparse data)的特点。所以以前很难搞定。但数据大了,模型大了,就搞定了。这个不难理解。
为什么语言能力最先搞定,并不需要超大模型,而只需要10-100亿参数模型足矣。这是因为语言本身不是 sparse data。语言能力里面,句法大规则最容易,词汇搭配随后。篇章和对话最后。
机器翻译就是一个最好的案例。前LLM时代 必须特别收集翻译对齐语料才能做,因为在随机语料中,翻译绝对是稀疏数据。但到了超大模型时代,各种翻译,起码是主要语言的翻译材料,虽然是整个语料海洋的零头,但也足够大到克服了稀疏数据的毛病。于是我们突然发现,LLM “涌现”了人类语言互译的能力,虽然它根本就不是为了翻译设计的。无奈它看到的实在太多,“无师自通” 了。自动摘要的能力也是如此。发现LLM摘要真心碾压以前的各种专门的摘要系统,它抓大放小的能力,早已超过我们人类。这一点,我反复试验过,不得不叹服。
白硕:所以这就是我说的,语言能力大家都会“到顶”,知识能力拼的是插件(外挂),跟大模型关系不大。
冯志伟:为什么会涌现?
立委:因为大。数据大,参数大。数据大,结果以前的小数据(子集)不再稀疏。参数大,它就有足够的表示能力来“涌现”不同层面的能力。
詹卫东:大应该是必要条件,但不是充分条件吧。涌现,可能找不到充分必要条件,如果找到了,智能就被解释清楚了。理解能力,可以简单的看作是“状态区别”能力。
白硕:不是全部智能,只是支撑语言能力的那部分智能。形式的接续、本体、事理关联。这个要大到长尾也不稀疏,是大致可以测算的。就是说所有长尾组合的概率都要有冲破阈值的可能。
冯志伟:人脑神经元有860亿!
Xinhua:人脑那么多神经元,大部分并不参与高级的思考活动。人的语言,思维,时空感受,都集中在几个区域。当然,这些区域可能接受大脑很多地方的投射。比如有人小中风后失去说话能力,但能写字,不影响思考和理解语言。
立委:人的脑瓜,神经元虽然天文数字,但记忆力可怜,运行效率也低 ,当然耗能也低。 耗能低,是相对于 LLM 而言。从生物自身角度,据说脑袋耗能相对来说很大,以至于很长时期成为高级动物的一个负担,不得不需要更多的进食和营养,才能维持。
【相关】
chatGPT 网址:https://chat.openai.com/chat(需要注册)