
白硕:ChatGPT的进阶思考:金融行业落地要解决哪三大问题?
立委:谢谢白老师分享。
这一期主要是提出了问题,就LLM与领域对接提出了要求,也强调了紧迫性。最大的一点就是领域积累沉淀很多年的浓缩的结构化领域知识/图谱,到底如何拥抱LLM的普适能力,从而为领域落地开辟新局面呢?
较小的领域先放下,金融是一大块、医疗是一大块、法律也是一大块,教育当然更是一大块。想来最容易被同化的大领域可能就是教育板块了,感觉上,教育这块的领域壁垒没有那么高。而且教育 by definiition 与语言以及语言受众最密切相关,应该是最先被革命的领地。现在高校面对 ChatGPT 怪物的惊恐和震撼算是一个本能的反应。
前面提到的这几大领域,其实数据量都很惊人。现在不清楚的是,如果用领域大数据做LLM,是不是就比普适的LLM,如 GPT3,甚至即将到来的 GPT4 就一定更容易落地领域,立竿见影呢?
理论上,与其给超大模型 GPT3/4 做“减法”来做领域模型,不如直接在数据端做工,只跑领域大数据,这样的大模型是不是就好用了呢。不知道,因为这些事还是进行中。
白硕:不看好。
立委:例如 《自然》有一个 article 报道了纯粹利用脱敏的美国电子诊疗记录数据做出来一个 billion 参数的 LLM(A large language model for electronic health records),在8项已有社区标准的医疗NLP任务上都达到或超过了 state of art,大约好了一个百分点左右,不知道落地是不是有感。
另外,前两天注意到微软研究也出了一个医疗 LLM 叫 BioGPT,数据比电子医疗记录要广得多,基本上把医疗卫生的公共数据一网打尽。这些工作刚出来,所用的技术都是LLM积淀下来的框架和路数,对领域落地的影响需要一些时间才能看出来。问题是,这些领域 LLM 本性上还是与领域的图谱和结构化的浓缩资源井水不犯河水。目前还看不到两个冤家如何融合和协作。
白硕:以NL2SQL为例,元数据结构是企业、行业的事情,但query中的词语带出来的二级、三级的trigger,实际上通用大模型都知道。不真大面积跑,根本不知道一刀砍下来会误伤到谁。
立委:是的。领域数据纯化了,NL 这端,尤其是口语,可能就受影响了。
白硕:等你从猿变人,人家做得好的不知道领先多远了。而且行业用户一个个牛得很,谁愿意给你做那么大量的标注和陪练?
立委:人家指的是领域这边的能人,还是指的是 AGI 那边的疯子,例如 GPT10?
行业用户再牛,也要面对这个现实:行业里管用的东西基本上处于手工业时代,与 LLM 时代岂止恍如隔世,这种对比和反差 太强烈了,简直让人不忍直视,无法忍受。
白硕:“人家”是对接派,“你”是冷启动派。
立委:嗯,明白了,人家就是隔壁瓦教授。行业用户的牛也明白了,因为它是上帝,有钱,它才不在乎谁对接,谁服务呢。他只要结果,只为结果买单。
广义的对接派包括我们所有不只是玩 LLM,还要用 NLP 来讨好客户的群体,是这个群体最终帮助搞明白落地形态。从大厂的 LLM 角度看去,所有人都是他家下游无数场景的 practitioners。
白硕:以后恐怕除了大厂和带路党,不存在第三种形态了。
立委:这一期与@白硕老师上次提到的演讲笔记是同一件事吧?这一期算是铿锵三人行。
白硕:不完全一样。上一次有学术内容,这一次基本没有。
立委:哦,所以还有个期待。这一期提供了很好的背景。现在趋同的舆论太多,白老师的洞见肯定有耳目一新的角度。
鲁为民:这个值得期待。
白硕:预训练的价值就在一个预字。如果搞成原生数据的训练,所有NLP的已知能力都得从头学起,而且行业客户提供的数据质量和数量都无法与公共域里的数据相比,私域部署的大模型最后出来的东西,肯定是东施效颦。而且还没人说你好话。
立委:东施效颦的顾虑是真的,首先水平就不在一个段位,虽然道理上科学无国界和任何其他界限,但落实和部署肯定要看资质。但数据端做拣选、清洗或其他过滤,这却是正道,也应该有效。
很多行业,例如医疗,领域数据量已经大到了形成“小社会”了。甚至口语,在医疗大数据中,也有属于医疗板块的社会媒体(例如 reddits 以及医疗问答之类)的存在,应该是并不缺乏数据的覆盖性。主要短板还是团队与团队不同,产出质量可能就不一样。
例如《自然》那个医疗LLM的工作,就做得很辛苦,是由佛罗里达大学的教授和研究生,联合硬件厂商Nvidia,做出来的。从描述看,中规中矩,没有任何科学创新,只是数据端input不同,以及输出端在NLP多项任务的微调验证。这样的产出是不是能够看好、有效,促进攻克领域壁垒,现在不好说,都需要时间和实践去消化。
宋柔:语义计算不仅要服务于应用,还应该有理论价值。以GPT及其各种后继发展的大模型,仅是生成模型,并没有通过分析而理解。这种大模型不会是NLP的终结模型,应该还有革命性的变化。
立委:分析大模型也有,BERT 就是,只不过风头现在被 GPT 碾压了而已。BERT 的微调曾经很风行,医学界也有一些经过微调的 BERT 模型在公域,可是效果不太好。
另外,我们理解的分析和生成也可能跟不上时代了,表面上看 next token 作为基石或原理的所谓自回归训练的生成模型,道理上在分析任务上应该不适应,或至少不能与分析模型争锋:语言分析任务包括问句意图理解、阅读理解还有诗词创造(诗词创作不是生成任务,而是更加依仗全局的理解和布局)等。但事实上,当一个所谓的“生成”模型在建模的时候可以记住足够长的 precontext 的时候,模型本身的分析能力,就与上下文两边都看的模型,没有实质性的差距了。
总之,实践和效果把生成模型推到了现在的高度,而且貌似成为迄今最接近 AGI 的一扇门。当然,谈“终结”还太早。
白硕:我们的专家说非人类理解人类语言的巅峰,不过分吧。
立委:不过分,跟我说的天花板一个意思。
ChatGPT 虽然不好说终结了AI或NLP,但基本终结了聊天和对话。此前甚至以后的一切人机交互,要突破这个天花板是很难了。因为从语言层面几乎到了无可挑剔的程度,虽然从个体的不同偏好来看,还有可以挑刺的地方。就自然语言交互接口而言,ChatGPT至少是没留下足够的余地,使得后来者可以给人更大的惊喜。
最大的问题是胡说。但胡说其实是语言能力强的一个指针,而不是相反,可以专论。
宋柔:无论是“巅峰”还是“天花板”,离人的语言认知峰顶还差的远呢。
立委:从一个角度看,“语言-认知”其实可以分开来看,语言已经搞定了,认知搞定了多少?我说过,认知根本没搞定,也就是 20% 的认知能力吧,但给人的印象却远远不止 20%。多数时候给人的感觉(或错觉)是,貌似它也搞定了认知,只是偶尔露怯而已。可是人类露怯也不是特别罕见的事儿呀。
宋柔:是的。人也会露怯。通过更大量的学习,人和机器都可以纠正过去的错误。但是,人能创造,人的创造能力不是靠学习数量的增大就能获得的。
立委:其实我对所谓创造性的人类独有论越来越持有怀疑。人类肯定有某种机器没有的东西,但创造性(的大部)感觉不在这个神圣的圈或点内。很多以前认为的创造性 譬如艺术创作 其实是比较容易被模仿甚至超越的了。现在看到大模型的生成物(AIGC),常常可以看到创造的火花。当然,我们总是可以 argue,所看到的AIGC 的创造性其实是我们的误读,或过度解读,是所谓 Eliza effect,读出了对象本身不具有的意义和美感来。这个 argument 自然不错,但还是无助于界定“创造”的人机边界。例如 AIGC 刚刚“创造”的这幅命题作品:水彩画 爱情。
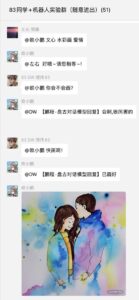
我一眼看上去就很有感。一股浪漫气息扑面而来,带着水彩画的飘逸和玫瑰梦幻色。如果是我女儿画的,我一定会称赞她有天才,可能会后悔没有送她去美术学院深造。
宋柔:艺术创造没有客观标准,与科学创造不一样。最简单的,由自然数到负数,由整数到有理数,由有理数到实数,这种跨越就不是增加学习量就能达到的。
立委:对,这个是LLM目前的短板。
回看一下人类如何学到这些知识吧:经过小学5-6年,中学5-6年,大学4年,研究生5-10年,最后是不是研究学问的料还不知道。但除了这样漫长和精心设计的教育体系,人类还想不出任何其他更加多快好省的知识传承和突破的办法来。有些学问的点滴突破,已经到了需要一个人穷尽一辈子去消化前人的认知,才能站在历史的肩膀上在某一个点上,可能做出某种突破,来延伸科学知识的前进。而做出突破的都是幸运儿,因为一将功成万骨枯,他的脚下不知道有多少无法达到彼岸的半途而废者。拿这样的知识体系作为人类最后的神圣领地也许很有道理,因为掌握它是太难了。但隐隐觉得 AI 在这个过程中,可能也有希望有所颠覆。颠覆不是 AI alone 而是 AI assist,原有的教育体系使得科学进步的 overhead 越来越大,大到了人类寿命与之不相称的程度。最终还是要诉诸 AI 来缩短这个过程。这个方向(叫 AI for science)也是值得关注的(例如,大模型在生物工程方面据说就开始扮演一个加速器的角色了)。至于这个方向的进展对于人类科学的神圣性有什么影响,目前还不好说。也许科学的神圣和严谨也不是铁板一块的。
宋柔:现在的AI只是死读书,不会联想、类比,进而归纳而抽象出新概念新方法、有时候你感觉它在联想、类比,但实际上是它学过了这个特定的联想、类比的实例。它无论如何不可能归纳、抽象出一个从未学到的概念。
AI解决不了新冠病毒变异的预测。
立委:人也解决不了吧?
即便天气预报,人貌似搞定了,但也还是不得不借助类似于 LLM 的大模型大计算才搞定的。预测模型所做的事情,与人类所做的预测有什么根本区别吗?硬要看区别,可能主要还是人不如模型,人拍脑袋做决策 与(借助)模型做决策,差距只会越来越大,因为人太容易只见树木不见林了。人类掌控全局的能力其实是一个很大的短板。
詹卫东:
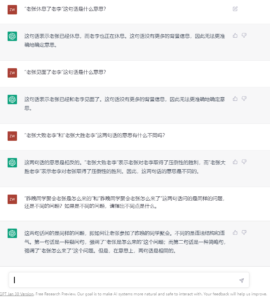
白硕:这还差得远。
立委:鸡同鸭讲啊。必需精分 bipolar 才好。
进一步说明了形式和内容可以分离,分离了也可以随机融合,融合了不 make sense ,但看上去却很雄辩。以前也见到人类胡说,如此反差密集的胡说还是让人开眼。
刘群:对ChatGPT要求太高了,lol
詹卫东:LLM为什么能“看起来像是”从符号序列中发现了知识?包括“语言(学)知识”和“世界知识”?很神奇。可惜我的数学功力不足,难以参透。
刘群:没有什么神秘的,纯粹就是基于大数据的统计所作出的预测。大家感到意外,只是对大数据统计的威力认识不足。但统计本身并不能发现更复杂的规律,这点ChatGPT并没有表现出特别之处。
詹卫东:我只是觉得(没有根据):无论给多少长的符号序列,也不可能学到真正的知识。
白硕:这个不好说。
数学上展开讨论,有一些理论上的天花板,但不是永远不会,而是会了也不可能自我认知会了。
詹卫东:其实是不是胡说倒很难判断。比如有人告诉我地心说的理论,我就很难知道地心说是不是在胡说。
立委:胡说的判定因人而异,对人的背景有要求。而语言的判定,只要 native 基本就行。
詹卫东:要验证知识的可靠性,是非常昂贵的。所以,从汪洋大海的符号序列中,学习到“知识”,难以想象。
立委:定义不清楚:什么叫知识?什么叫学到?什么叫“真正学到”?判定的标准是什么?如果标准是他的体温、脉搏和肾上腺素的分泌,是不是呼应了他的知识,那肯定是没学到。
白硕:都可以在数学意义上讨论和论证。
詹卫东:以围棋为例,可以认为机器学习到了围棋的“知识”。因为这类知识可以有函数表达形式。知识应该可以归结为不同粒度的分类能力吧,这是最基础的。
立委:这个能力已经是漫山遍野了呀。知识从概念化起步,概念化的模型表现已经是笃定的了。zero shot 的本义就在于此:你用概念 instruct 模型,模型可以从概念的“理解”,返回给你实例。
卫东:

我也是主观认为ChatGPT没有“特别之处”。比如“中秋月如钩”它也搞不定。但是,ChatGPT表现出的“语言能力”确实令人震撼。我就非常奇怪,仅仅靠预测字符,就能预测出这么流畅(前后呼应)的句子?
从“流畅的句子”(语言能力)到“真正的知识”,是不是存在鸿沟(是否可以逾越)呢?对人类而言,很多“知识”,载体就是“流畅的句子”。所以,给人一种错觉:流畅的句子 = 知识。我觉得这是ChatGPT给一般人的错觉。
有知识 → 能说流畅的句子 (这个合理)
能说流畅的句子 → 有知识 (这个存疑)
白硕:知识是嵌入好还是外挂好,我觉得这不是理论问题而是工程问题。
尼克:可能各有各的用处,有时理性需要经验,有时经验需要理性。
白硕:比如,理论上,一个实数就可以包含世界上所有的知识。但是工程上,还是要用一千多亿个参数。
尼克:变哲学问题了。
詹卫东:一个实数 > 一千多亿个参数?
白硕:数学上它们一一对应。N维空间的点可以和一条直线的点一一对应。我真的没开玩笑。
尼克:连续统。
詹卫东:这些知识,怎么能从“符号序列”中“学出来”呢?哲学问题是“知识是创造的,还是记忆的“?
立委:很多降维操作不就是要压平知识表示吗?
某种意义上,序列符号形式的语言,就是上帝赐予的压平知识的天然工具。其结果是无限的冗余、啰嗦、重复。LLM 就是在这些冗余中学到了“知识”,重新表示/复原到多维空间去。到了生成阶段,又不得不再次降维,压平成串,照顾人类的感官(眼睛读/耳朵听)。
宋柔:我想问ChatGPT一个问题,但我没有ChatGPT,也不会翻墙,不知哪位有兴趣问一下: 我国的长度计量单位过去曾用公里、公尺、公寸、公分,后来改用千米、米、分米、厘米,为什么米、分米、厘米已经通用了。但该用千米的场合往往还是用公里?如某人身高1米7,不说1公尺7;但高铁的速度每小时300公里,不说每小时300千米。
就是说,长度单位该用千米,不用公里,但为什么高铁速度说每小时300公里,不说每小时300千米?
立委:

好像也还说千米的,至少有一些小众社区是这个习惯。
詹卫东:

立委:习惯的问题(约定俗成)好像没有什么道理,感觉是偶然促成。
马少平:宋老师:发论文的时候似乎要用千米不能用公里,新闻什么的可能没有这么严格。
宋柔:正确的答复应该是:口语中,1千米和1000米读音相同,但1千米和1000米表示的精确度不同。前者精确到千米,后者精确到米。这种混淆导致“千米”这种单位不好用。
由于语料中没有这种论述,ChatGPT自然答不出来。
詹卫东:千米这个单位在小学数学题中广为使用,是把小学生绕晕的不二法器。我家娃数学能力不行,深受其害。
宋柔:为什么说“歪鼻子斜眼”,不说“斜鼻子歪眼”?
如果老外问中国人这种问题,多数中国人就说“我们就是这么说的,没有为什么。”
立委:
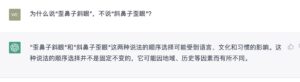
从一本正经的胡说,到一本正经的废话,到一本正经的信息量较低营养不高的话,再到一本正经的具有信息量的话,最后到一本正经的绝妙好辞。这就是一个频谱。
上面的回答,我的感觉是属于 一本正经的信息量较低营养不高的话。有信息量的部分就是提到了“习惯”。他无心,我有意,这些习惯表达法,不就是约定俗成的习惯吗。符号绑定的用法,社区约定,本源上就不需要讲什么道理。
不变的是“一本正经”:就是说,它学会了人话。
白硕:但是真有泛化。我是说儿化规则。可能就是很复杂的决策森林啊。人说不清,但说的时候拎得清。
立委:风格都能模仿,学会儿化不奇怪了。都是鸡零狗碎的东西,不是没有规则,而是规则太多,人总结不过来。
白硕:不妨试试。
立委:
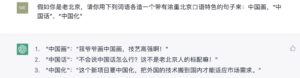
貌似还没学会。哈,没有这个知识,就好比它目前写中国诗没有学会押韵一样。但是英文诗是押韵的呀,也许就是一个阶段问题,还没进阶到那个段位:也许是等中国的大模型赶上来吧。
具体到这个儿化,是软约束,的确不好学,尤其是写到书面上,很多时候“儿”字就省掉了,让它如何抽象?如果是语音作为学习材料还差不多。
宋柔:这些例子说明,ChatGPT只会照猫画虎,不会从大量实例的类比中归纳出规律。
立委:照猫画虎 其实已经开始抽象规律了,否则就是照猫画猫。
宋柔:比如,人可以从大量实例中归纳:“矮”说的是某物的顶面到底面距离短,“低”说的是某平面在心目中标准平面的下面。说“歪”的前提是预设了正确方向,是偏离了这个正确方向,说“斜”的前提是预设了正对的方向(无所谓正确不正确),是不同的另一个方向。ChatGPT虽然学了大量语料,大部分情况下能照猫画虎差不离地说对话,但不能抽象出相关的概念,从而讲不出道理。
ChatGPT不能抽取出相关的特征,从而不能归纳出规律。
立委:感觉还是不好说。
讲道理也许不行,抽象能力不可小看它。没抽象出来,更大可能是时间和数据问题。今天没抽象出来,1年后可能就可以了。近义词的细微区分是有数据依据的。
白硕:抽象这个东西不好说清楚,但是特征是能说清楚的。也许是多少层卷积之后才能出现的特征,数据不足时特征无法分化出来。
立委:以前符号AI那边的常识推理名家 cyc 老打比方,说:去年我们是10岁孩子的常识推理能力,今年的目标是12岁。
类似的,LLM 的抽象能力它现在也许达到了大学生的能力,但还不到研究生的水平。就更谈不上达到专家 教授的高度抽象能力。但它走在万能教授的路上
【相关】
A large language model for electronic health records
chatGPT 网址:https://chat.openai.com/chat(需要注册)