一日一parsing:今天的是。。。
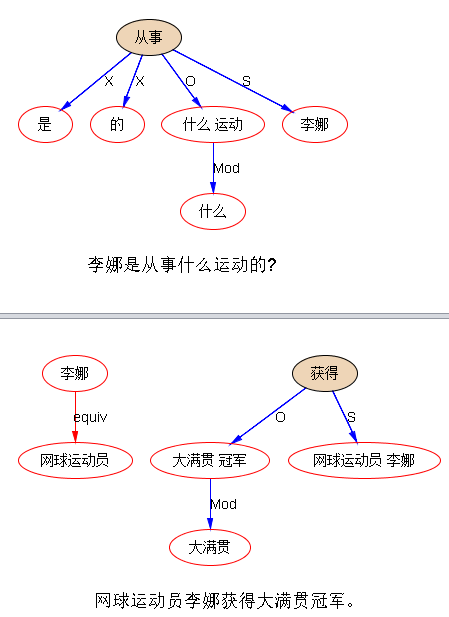
怎么知道这里的问题和答案可以相配呢?如果有 parsing 和建立其上的知识图谱,那就好办。图谱里面有 professionOf 的 relationship,有了 parsing 抽取这个关系就是小菜(这个例子很简单,就是把同位语关系映射到professionOf关系)。有了 parsing 对于 question 要问的关系,也可以解出来 asking point,子树(S:李娜-从事,O:从事-运动;Mod:什么-关系)就确定了 asking point 是寻求 professionOf(“李娜”)。然后做语义 matching,问答系统的这个环就圆了。This is IE or knowledge-graph supported QA.
具体说,为了让Q和A能match,我们可以对两边做子树规则,填空(抽取)到 professionOf 的关系去,语义一体化,然后就顺风顺水了。第一条子树规则是:
"从事"O: (“职业|运动”)
O: (“职业|运动”)
Mod (“什么|何种”)
S: ^Sombody==>
==> professionOf(^Somebody,?)
professionOf(^Somebody,?)
这是 Question parsing 和 asking point extraction. 在答案源那一边,也有一组规则做 professionOf 的抽取,其中有这样一条规则:[personNE]
[person-NE]:^Person
equiv([profession_token]:^Profession)
==> professionOf(^Person,^Profession)
QA 就这样 match 了。
如果没有专门的知识图谱,没有事先定义好的关系的抽取,怎样做 QA 来应对呢?那就用 SVO parsing 也可以应对相当多的关于事件的问答。但是关系和复杂的事件的问答,简单的 SVO matching 就不行。好在原则上说,复杂的语义大多可以预先定义成 IE (predefined), 专门去做针对性抽取。简单的语义是 open-ended 的,语言学parsing(主谓宾定状补等)就够应付了。
天不我欺也。
IE 对于 SVO,实质就是 (semantic) slot normalization,原来的 slots 是语言学的,叫 S 也好, O 也好,equiv(同位语)也好,mod 也好 。。。。现在的 slots 是 pragmatic 的语义: 譬如 professionOf, locationOf, employeeOf, acquiringCompany, acquiredCompany, priceOfAcqusition, etc.
SVO matching 的 QA 也可以举一个例子, 譬如询问如何做某事:做+某事 就是一个 V+O:
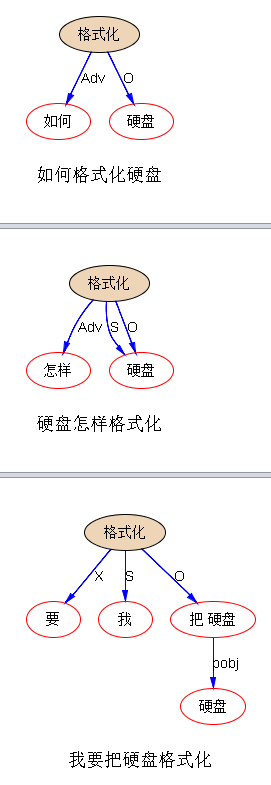
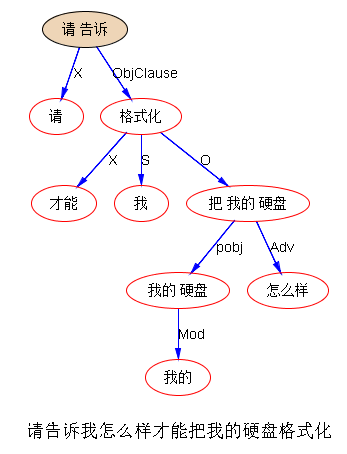
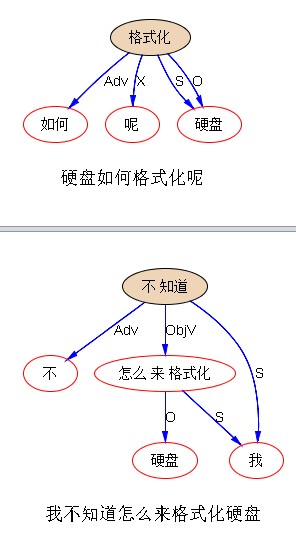
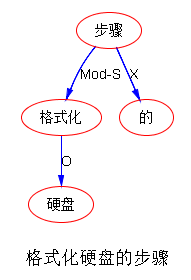
甭管怎样换说法,不变的是 VO (格式化,硬盘)。有了这个 VO matching 做底,离开QA 或人机对话就不远了。譬如,FAQ 档案里很可能就有这样的标题: 格式化硬盘的步骤;关于格式化硬盘;等。于是 Q与A基本就是 SVO 子树 matching:"格式化“ ---O---> “硬盘”。
接着这个话题再发挥一下。IE 说的是信息抽取,多数时候这个 information 是与 insights (情报,有价值的信息)等价。但其实 IE 可以是抽取有价值的情报,也可以是抽取无价值的情报(噪音)。
为啥要抽取无价值的信息呢?道理很简单,噪音捣乱啊,为了剔除噪音,首先要识别它,或者说抽取它以便扔掉它。所用的方法可以完全一样。搜索界有 stop words ,被当做噪音扔掉了,那是噪音的最简单形式,不需要上下文,纯粹是高频虚词:对于 parsing 这些 stop words 其实很关键,是必要的建立结构的桥梁,但对于关键词搜索,因为里面没有结构,这些词就变成纯粹的噪音了。用 IE 来剔除噪音,实际上是根据上下文结构来断定哪些信息是应该扔掉的,譬如上面的句子里面,在 QA 的语用场景下,就可以剔除诸如:“请告诉我”、“我不知道”等,这样才凸显关键的的VO“格式化-硬盘”。要是做相似度计算,这些个词都是噪音。把“请告诉我”当成一个 4-gram 的 stop word 行不行?可以,但是如果这种东西有很多变式,ngram 就不行了。这时候在子树基础上做 IE 抽取噪音就非常可取了。又因为噪音大多可以用 word-driven 来做,做这件事儿是很靠谱的,基本一抓一准。
小结一下,一般而言,如果 Q 和 A 说法类似,譬如“格式化”+ “硬盘”,那么只要在 SVO 基础上做 matching 就可以把 QA couple 起来。如果 说法很不相同,或者一个关系或事件的变式太多,那么就加一层 IE,matching 在 IE 语义上做。SVO 的 QA matching 是智能搜索的本质,可以对付不可预测的问题。IE 的 QA matching 是预先定义的,针对领域的,不仅精准,而且可以应对变式。两个方案相辅相成。一个善于领域的精准,一个善于open domain 的广度和召回。二者都比 keywords 好出很多,因为有结构。如果从 backoff 来看,那就是 IE 优先, SVO 其次,keywords 楼底。这样精度广度就全照顾到了。
说来归齐,对于QA,对于对话系统,parsing 是核心引擎的关键技术。QA 说到底就是在 Q 与 A 中建立映射,映射的基础是语义匹配。deep parsing 及其 IE 是语义匹配的核武。
【相关】
泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索