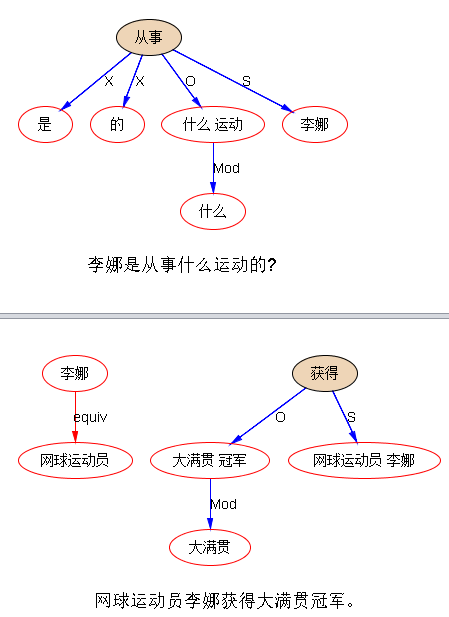
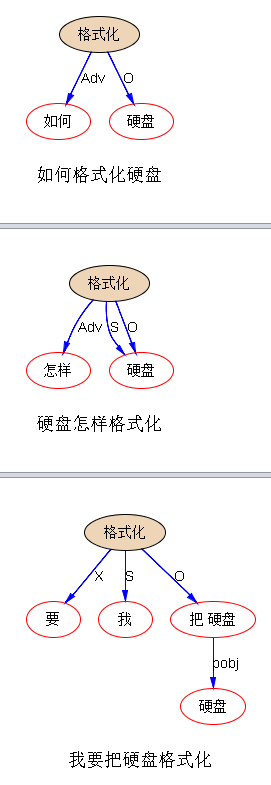
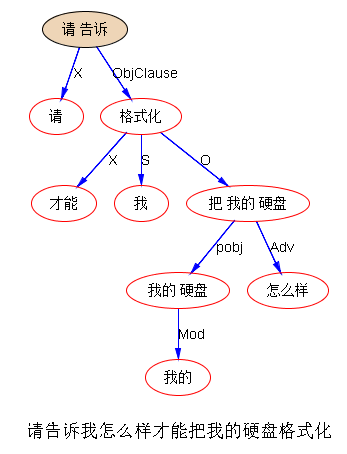
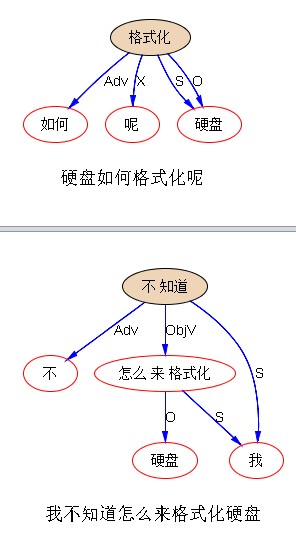
李:上次提过,先搜后parse,是可行的。
早在十几年前,AskJeeves 被华尔街追捧。这里面也有很多IT掌故我专门写过博文( 【问答系统的前生今世】,【 金点子起家的 AskJeeves 】)。 当时NLP (Natural Language Processing) 红透半边天,下一代 Google 呼之欲出的架势,尽管AskJeeves其实NLP含量很低。他们不过利用了一点NLP浅层对付问题的分析。这才有我们后来做真正基于NLP的问答系统的空间。
就在AskJeeves上市的当天,我与另一位NLP老革命 Dr. Guo,一边注视着股市,一边在网上谈先search后parse的可行性。此后不久我的团队就证实了其可行,并做出了问答系统的prototype,可以通过无线连接,做掌式demo给投资人现场测试。当年还没有 smart phone 呢,这个demo有wow的效果,可以想见投资人的想象被激发,因此我们顺顺当当拿到了第一轮一千万的华尔街风投(这个故事写在《朝华午拾:创业之路》)。
问答系统有两类。一类是针对可以预料的问题,事先做信息抽取,然后index到库里去支持问答。这类 recall 好,精度也高,但是没有 real time search 的灵活性和以不变应万变。
洪:文本信息抽取和理解,全靠nlp
李:另一类问答系统就是对通用搜索的直接延伸。利用关键词索引先过滤,把搜罗来的相关网页,在线parse,on the fly, 深度分析后找到答案。这个路子技术上是可行的。应对所谓factoid 问题:何时、何地、谁这样的问题是有效的。(但是复杂问题如 how、why,还是要走第一类的路线。)为什么可行?因为我们的深度 parsing 是 linear 的效率,在线 parsing 在现代的硬件条件下根本不是问题,瓶颈不在 parsing,无论多 deep,比起相关接口之间的延误,parsing 其实是小头。 总之,技术上可以做到立等可取。
对于常见的问题,互联网在线问答系统的 recall 较差根本就不是问题,这是因为网上的冗余信息太多。无论多不堪的 recall,也不是问题。比如,问2014年诺贝尔物理奖得主是谁。这类问题,网上有上百万个答案在。如果关键词过滤了一个子集,里面有几十万答案,少了一个量级,也没问题。假设在线 nlp 只捞到了其中的十分之一,又少了一个量级,那还有几万个instances,这足以满足统计的要求,来坐实NLP得来的答案,可以弥补精度上可能的偏差(假设精度有十个百分点的误差)。
IBM 花生机器在智力竞赛上 beat 人, 听上去很神奇, 里面会有很多细节的因应之道,但从宏观上看,一点也不神奇。因为那些个竞赛问题,大多属于 factoid 问题,人受到记忆力有限的挑战,肯定玩不过机器。
雷:@wei 为什么说事先对材料进行deep parsing的搜索不灵活?
李:事先(pre-parsing)更好。我是主张建立一个超级句法树库的,资源耗费大。但急于成事的工程师觉得也没必要。在线做的好处是,内容源可以动态决定。
雷:假设一下,我们把谷歌拥有的材料通通进行了deep parsing,那么这个搜索会是什么样的? 再辅佐以人工的高级加工
李:nlp parsing 比关键词索引还是 costs 太大。
雷:是,但是现在硬件的条件下,还是可行的吧?那就是把信息转化为了fact的知识
李:是的,哪怕只是把 Google 网页里面的百分之一parse 一遍那也有不得了的威力。那是核武器。就是 Powerset Ron 他们当年绘制的图景。可是这种大规模运用NLP不是我们可定的,成本是一个大因素,还有就是观念和眼光,那是 norvig 这样的人,或其上司才能拍板的。
雷: 暂时局限在一个领域呢?
Nick: 可以先小规模吗,如wiki等?
雷: 破坏google的力量是semantic web. 如果每个网站使用的是semantic web,who needs google, 但是现在的问题是把一个web2.0的site转化为web3.0的成本
李:Wiki已经可行,Powerset 当年就是拿它展示的。但市场切入点呢? Wiki其实是小菜,比起我们目前应对的 social media, 无论是量,还是语言的难度。
Nick:但wiki有结构
李:做wiki技术上没有任何问题。问题在产品和businesd model.
Nick:做一个wiki的语法树,再叠加wiki的结构,已经很有用了。
雷: wiki 到 dbpedia 还是只有很低的percentage吧?
李:Ron 当年游说你们和微软,不就是wiki么,其实他们的demo,纯粹从技术的角度完全可以通过 due diligence。
大家都知道知识挖掘,在大数据时代有巨大潜力,这是宏观上的认识,永远正确。微观层面,还是要有人在知识基础上做出可挣钱的产品来。微软买Powerset的时候,肯定也是基于这种宏观认识。但没有后续的产品化,买来的技术就是个负担。
RW:Google 是靠se抓流量,然后ads赚钱,Se技术本身不变现
Nick:@wei powerset我看过,not impressive at all
李:那是因为,你的角度不同。他们没有把那种结构的威力,用通俗的方式,做成投资人容易看懂的形式。我也玩过 Powerset,它的核心能力,其实是有展现的。不过要绕几道弯,才能发现和体会。方向上他们没错。
当然我不是为 Ron 唱赞歌,他再牛,再有名气,他的parser比我的还是差远了。这个世界上 yours truly 是第三 -- 如果上帝是第一,在下的下一个系统是第二的话。
当然吹这种牛是得罪人的,不妨当笑话看。
雷: 呵呵,不用上税,无妨的
Nick: 你的不好意思不得罪人
李:Jobs不是说过,只有疯狂到以为自己可以改变世界的,才能在雪地里撒尿,并留下一些味道或痕迹。我们是毛时代生人,自小有一种精英意识。天将降大任于斯人也,自己吃不饱,也要胸怀世界,解放全人类。老子天下第一的心态就是那种legacy。
洪: Chris Manning前两年就跟database/information retrieval的辩论说,别啥啥fact db和information extraction,直接deep parsing齐活。
雷:@洪 我农民,东西放哪里啊
李:Parsing real time 的应用场景,东西放内存就可以了,用完就扔,用时再来,现炒现卖。当然那个做不了真正意义上的text mining,只见树木,难见森林。但可以应对搜索引擎对付不了的简单问题。
毛: 哇哈,不得了。改不改变世界且不说,我的作息时间先被改变了。
雷: 我以为做机器学习的人在在豪气冲天,原来@wei也是!
刘: @雷 一个爱在雪地……
洪: @雷 Chris Manning的意思是,all information is in deep parsed text
雷: facts不就是来源于deep parsed text吗
洪: facts are usually triples extracted from text with consensus。
雷: under a set of ontologies, these facts form a network, that is, linguistic factors are removed。
洪: db & ir people dont really believe nlp is a must path for retrieval tasks
雷: you are right. This is why wei made such big efforts here to point out the problems of those guys.
洪: linguistic info is transparent to native human speaker , but I don't think it's transparent to computer. So, I believe in communicating with machine, or communicating with people through computer, simpler language in query or logic form should be better. Why do we want to make computer understand human language? It doesn'tmake sense at all.
李:洪爷说的是哪国话? 本来就不存在机器理解语言, 那个 NLU 只是一个比喻。其实也不存在人工智能,那也是个比喻。
洪: 现在大多数人可不把ai/nlu当比喻
李:所谓机器理解语言不过是我们模拟分解了分析理解的过程达到某种表达 representations,这种表达是达到最终任务的一个方便的桥梁,如此而已。
洪: 按你的说法,机器人过不了turing test 这一关
李:我是回应你为什么要让机器理解语言。回答是,从来就不需要它去理解。而是因为在人类从形式到内容的映射过程中,我们找到一些路径,沿着这个路径我们对人类的理解,似乎有一个说得过去的解释。
当然,那位IR仁兄说的其实是一个具体环节, 指的是搜索框,他说好好的搜索框,给几个关键词就可以查询,既快又好又简单,为什么要把搜索框变成一个自然语言接口,像以前的AskJeeves那样,让人用自然语言提问,然后逼迫机器去理解?从他的角度,这完全不make sense,这种感觉不无道理。明明不用自然语言,多数搜索任务都可以完成得很好,没有道理硬要与机器说“人话”,增加overhead, 还有机器理解过程中的误差。关键词蛮好。互联网搜索这么多年,我们用户其实也被培养出来了,也都习惯了用尽可能少的关键词,以及怎样用关键词的不同组合,容易找到较理想的结果。自然语言接口似乎没有出场的必要。
可是,这只是问题的一个方面。问题是关键词搜索也许可以解决80% 乃至 90% 的基本信息需求(只是基本,因为心中问题的答案还是需要人在搜索结果中去用人脑parse来确定,这个过程不总是容易轻松的)。但还有相当一部分问题,我们或者难以用关键词找到线索,或者找出来的所谓相关网页需要太多的人肉阅读还不能搞定。这时候,我们可能就会想,要是有个懂人话的机器,自动解答我们的信息问题多好啊。自然语言接口终究会以某种形式重回台面,增强而不是取代关键词的接口。
洪:理解就是 1.能在人与人之间当二传手;2.能根据自己存储的知识和具备的行动能力做出人所认可的反应
李:说白了,就是从线性的言语形式到语法树的映射。这是人类迄今最伟大的发现,或发明,或理论,属于最高天机。人类还没有更好的理论来解释这个理解过程。这个建树的过程,赶巧可以程序化来模拟,于是诞生了 NLU
毛:在图灵测试中,我们是把机器看成黑盒子。但是要让机器通过图灵测试,它就得理解人的语言才能作出反应。 两位大侠,能否推荐几本书看看?最好是科普类的,看着不吃力。
李:洪爷,不能因为在某些语言任务上,没有语言分析,也做到了,就来否定语言分析的核武器性质。LSA根本就没有语言分析,但它用到给中学生自动评判作文方面,效果也不错。
洪: 最近重读了几本认知方面的旧书,我倾向于认为人的内部表征是一种imaginary的多维图式表征,linguistic system只是个人际交流的接口。把多维信息压到线性。让计算机理解小说诗歌,估计永远做不到,因为计算机没有人那么强大的imaginary内部表征。@毛 wei和我一起来推荐几本nlp方面的书,就像PDP一样经典
雷:@wei 句子的语意理解后的表征方式是什么?还是tree吗?
李:逻辑语义,这是董老师的表述。外面叫 logical form,这是从乔老爷那里借来的术语。具体表现细节没必要相同。
雷: 那么我们把句子给理解后,tree与logical form并存在记忆中?
李:二者等价。细分可以有:句法树;语义树;语用树。所谓信息抽取,就是建语用树。句法树到语义树,就是乔老爷的表层结构到深层结构的逆向转换。
洪: Chomsky之所以不谈语义啥的,因为实在没啥科学证据。现在我们所讲的语义都不是native的,都是人类的数学逻辑发明,在计算机上热起来的。出口转内销
雷: 是不是与那时的行为主义为主流有关,因为语意很难有操作定义?
李:这个讨论越来越高大上,也越来越形而上。
毛:是啊,再往上一点,就到哲学、认识论的层面了。另,跟PDP一样经典的是什么书?
李:乔老爷57年小册子。
毛: 什么书名?我以前只是从编译的角度了解他在形式语言方面的理论(现在也忘了),却不知道他在自然语言方面的贡献。以前我对自然语言毫不关心,也就是这一阵听你们高论才觉得这东西挺有意思。
洪: 有关语言学和认知科学的科普书,Steven Pinker写的系列都不错
The Language Instinct (1994) ISBN 978-0-06-097651-4
How the Mind Works (1997) ISBN 978-0-393-31848-7
Words and Rules: The Ingredients of Language (1999) ISBN978-0-465-07269-9
The Blank Slate: The Modern Denial of Human Nature (2002) ISBN978-0-670-03151-1
The Stuff of Thought: Language as a Window into Human Nature(2007) ISBN978-0-670-06327-7
有关NLP:
Dan Jurafsky and James Martin's Speech and Language Processing.
有关基于统计方法的NLP:
Chris Manning and Hinrich Schütze's Foundations of Statistical NaturalLanguage Processing
好像这两本书国内都有影印本
白:总结一下:wei的中心意思,nlp技术在他手里已经很过关了,只是苦于木有好的商业模式,再加上微软谷歌等传统势力的封杀,商业上还不能成大气候。有人建议说回国发展。deep nlp,性能不是问题,可以保证线性online parse,最坏情形回退到搜索。瓶颈在别处。
雷:元芳你怎么看
李:元芳呢?
谢谢白老师的总结,实际上就是这么回事。决定成败的不是技术,而是产品方向。技术差,可以砸了产品;技术好,不能保证产品在市场的成功。技术增加的是产品的门槛。
白: 好的商业模式有两个特点,一个是技术壁垒,一个是侵略性。nlp前者不是问题,问题在后者。需要一张极富侵略性的皮。讯飞也有马失前蹄啊。
独: 多讨论,应该能够找到好的方向。讯飞很多年都做得苦逼死了,熬到这两年才爽。现在做一个新的搜索引擎公司不现实。问答类概念已经被用滥了。出门问问也是因为问答不好做,改作智能手表,反而卖的不错。智能家居的语音交互界面,本质上是一个问答系统。
李:对于关键词,语法树就是颠覆。
白: 信息服务三个阶段:门户网站,域名成为商品;搜索引擎,关键词成为商品;社交网络,粉丝成为商品。下一个成为商品的是啥?问答只是表象,关键是要回答什么成为商品。分析树也不直接是商品。
李:白老师说的极是。关键是什么是商品,可以来钱,这个确定了,作为后台的技术产品才有门槛,核武器才能发挥威力。
白: 我们还是想想,高精准度的deep nlp服务,把什么作为标的商品,才能具有侵略性。
Philip: 给@wei 的高大上技术找个商业模式
独: 我个人算是比较擅长于设计商业模式的,但是对于NLP的直接应用,还是觉得太偏后端,很难找出一个前端产品,对于用户是可感知的刚需。
白: 不在多而在狠,uber就够狠。
原载:《泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索》
【相关】