W. Li. 1997. Chart Parsing Chinese Character Strings. In
Proceedings of the Ninth North American Conference on Chinese
Linguistics (NACCL-9). Victoria, Canada.
Chart Parsing Chinese Character Strings [1]
Wei LI
Simon Fraser University
Burnaby B.C. V5A 1S6 CANADA ([email protected])
ABSTRACT
This paper examines problems in word identification for a Chinese natural language processing system and presents our solution to these problems. In conventional systems, written Chinese parsing takes two steps: (1) a segmentation preprocessor for word identification (segmenter); (2) a grammar parsing the string of identified words. Morphological analysis, when required, as in the case of productive word formation, has to be incorporated in the segmenter. This matches the conventional morphology-before-syntax architecture. We will demonstrate the theoretical defect of this architecture when applied to Chinese. This leads to the conclusion that segmentational approach, despite its being the mainstream in Chinese computational morphology, is in general not adequate for the task of Chinese word identification. To solve this problem, a full grammar should be made available. Therefore, we take an alternative one-step approach. We have implemented an integrated grammar of morphology and syntax for directly parsing a string of Chinese characters, building both morphological and syntactic structures. Compared with the conventional two-step approach, our strategy has advantages in resolving ambiguity in word identification and in handling productive word formation.
- Introduction
A written Chinese sentence is a string of characters with no blanks to mark word boundaries. In conventional systems, Chinese parsing takes two steps as shown in the following Figure 1: (1) a segmentation preprocessor (called segmenter) for word identification; (2) a word based parsing grammar, building syntactic structures (Feng 1996, Chen & Liu (1992).
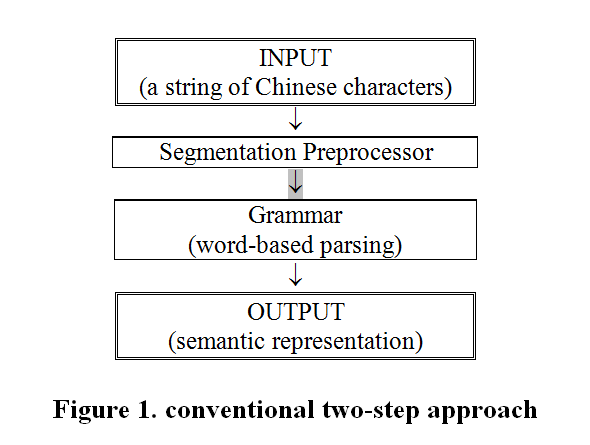
In contrast, we take an alternative one-step approach, as shown in Figure 2 below. We have implemented a grammar named W‑CPSG (for Wei's Chinese Phrase Structure Grammar). W‑CPSG integrates morphology and syntax for character based parsing, building both morphological and syntactic structures.
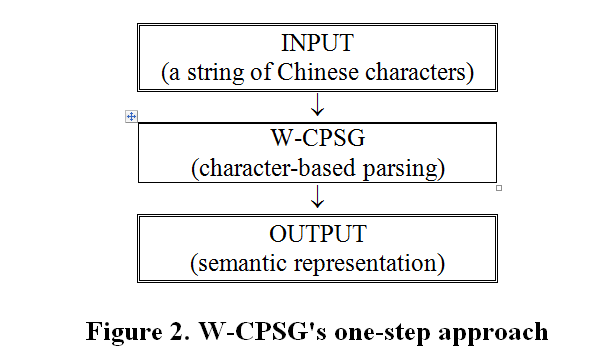
In the two-step architecture, the purpose for the segmenter is to properly identify a string of words to feed syntax. This is not an easy task due to the possible involvement of the segmentation ambiguity. For example, given a string of 4 Chinese characters 研究生命, the segmentation ambiguity is shown in (1.a) and (1.b) below.
(1.) 研究生命
(a) 研究生 | 命
graduate student | life or destiny
(b) 研究 | 生命
study | life
The resolution of the above ambiguity in the segmenter is a hopeless job because such ambiguity is syntactically conditioned. For sentences like 研究生命金贵 (life for graduate students is precious), (1.a) is the right identification. For the phrase 研究生命起源 (to study the origin of life), (1.b) is right. So far there are no segmenters which can handle this properly and guarantee right word segmentation (Feng 1996). In fact, there can never be such segmenters as long as a grammar is not brought in. This is a theoretical defect of all Chinese analysis systems in the conventional architecture. We have solved this problem in our morphology-syntax integrated W‑CPSG. Word identification in our design becomes a by-product of parsing instead of a pre-condition for parsing.
In the text below, Section 2 investigates problems with the conventional two-step approach. In Section 3, we will present W‑CPSG one-step approach and demonstrate how W‑CPSG parsing solves these problems. The following is a list for abbreviations used in this paper.
A (Adjective); AF (Affix); BM (Bound Morpheme);
CLA (Classifier); CLAP (Classifier Phrase);
DE (Chinese particle introducing a modifier of noun); DEP (DE Phrase);
DE3 (Chinese particle introducing a modifier of result or capability);
DET (Determiner); LE (Chinese perfective aspect marker);
N (Noun); NP (Noun Phrase); P (Preposition); PP (Prepositional Phrase);
S (Sentence); V (Verb); VP (Verb Phrase); Vt (Transitive Verb)
- Problems Challenging Segmenters
In general, there are two basic problems for segmenters, namely, segmentation ambiguity and productive word formation.
2.1. segmentation ambiguity
This sub-section studies the segmentation ambiguity for Chinese word identification. We indicate that this ambiguity is structural in nature. Therefore it should be captured by structural trees via parsing. We conclude that a parsing grammar is indispensable in the resolution of the segmentation ambiguity.
Behind all segmenters are procedure based segmentation algorithms. Most proposals are some modified versions of large-lexicon based matching algorithms. As an underlying hypothesis, a longer match overrides a shorter match, hence the name maximum match. Decided by the direction of the procedure, i.e. whether the segmentation proceeds from left (the beginning of a string) to right (the end of the string) or from right to left, we have two general types of maximum match: (1) FMM (Forward Maximum Match) algorithm; (2) BMM (Backward Maximum Match) algorithm (Feng 1996).
According to Liang 1987, segmenters have trouble with cases involving the segmentation ambiguity. There are two types of segmentation ambiguity: the cross ambiguity (AB|C vs. A|BC) and the embedded ambiguity (AB vs. A|B).
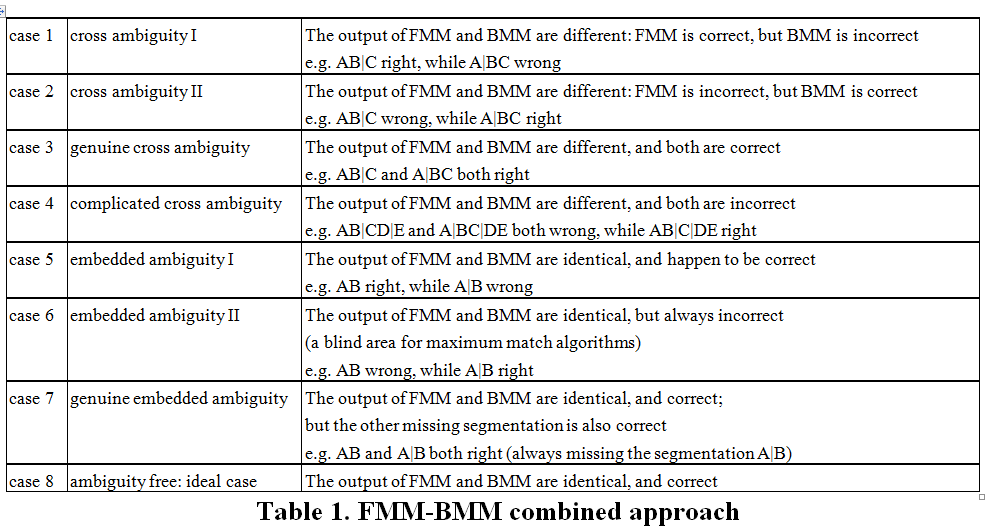
To detect possible ambiguity, many researchers use the technique of combining the FMM algorithm and the BMM algorithm. When the output of FMM and BMM are different, there must be some ambiguity involved. The following table lists the cases associated with the FMM and BMM combined approach.[2]
The following 3 examples all contain a cross ambiguity sub-string 研究生命 with 2 segmentation possibilities: 研究生|命 and 研究|生命. Example (4.) is a genuinely ambiguous case. Genuinely ambiguous sentences cannot be disambiguated within the sentence boundary, rendering multiple readings.
(2.) case 1: 研究生命金贵。
(a) 研究生 | 命 | 金贵 (FMM: correct)
graduate student | life | precious
Life for graduate students is precious.
(b) * 研究 | 生命 |起源 (BMM: incorrect)
study | life | precious
(3.) case 2: 研究生命起源。
(a) * 研究生 | 命 | 起源 (FMM: incorrect)
graduate-student | life | origin
(b) 研究 | 生命 | 起源 (BMM: correct)
study | life | origin
to study the origin of life
(4.) case 3: 研究生命不好。
(a) 研究生 | 命 | 不 | 好 (FMM: correct)
graduate student | destiny | not | good
The destiny of graduate students is not good.
(b) 研究 | 生命 | 不 | 好 (BMM: correct)
study | life | not | good
It is not good to study life.
The following example is a complicated case of cross ambiguity, involving more than 2 ways of segmentation. Both the FMM segmentation 出现|在世|界 and the BMM segmentation 出|现在|世界 are wrong. A third segmentation 出现|在|世界 is right.
(5.) case 4: 出现在世界东方。
(a) * 出现 | 在世 | 界 | 东方 (FMM: incorrect)
appear | be-alive | BM | east
(b) * 出 | 现在 | 世界 | 东方 (BMM: incorrect)
out | now | world | east
(c) 出现 | 在 | 世界 | 东方 (correct)
appear | at | world | east
to appear in the east of the world
In the following examples (6.) through (8.), ¿¾°×Êí involves embedded ambiguity. As separate words, the verb ¿¾ (bake) and the NP °×Êí (sweet potato) form a VP. As a whole, it is a compound noun ¿¾°×Êí (baked sweet potato). In cases of the embedded ambiguity, FMM and BMM always make the same segmentation, namely AB instead of A|B. It may be the only right choice, as seen in (6.). It may be wrong as shown in (7.). It may only be half right, as in the case of genuine ambiguity shown in (8.).
(6.) case 5: 他吃烤白薯。
(a) 他 | 吃 | 烤白薯 (FMM&BMM: correct)
he | eat | baked sweet potato
He eats baked sweet potatoes.
(b) * 他 | 吃 | 烤 | 白薯 (incorrect)
he | eat | bake | sweet potato
(7.) case 6: 他会烤白薯。
(a) * 他 | 会 | 烤白薯 (FMM&BMM: incorrect)
he | can | baked sweet potato
(b) 他 | 会 | 烤 | 白薯 (correct)
he | can | bake | sweet potato
He can bake sweet potatoes.
(8.) case 7: 他喜欢烤白薯。
(a) 他 | 喜欢 | 烤白薯 (FMM&BMM: correct)
he | like | baked sweet potato
He likes baked sweet potatoes.
(b) 他 | 喜欢 | 烤 | 白薯 (correct)
he | like | bake | sweet potato
He likes baking sweet potatoes.
Compare the above examples, we see that there are severe limitations for the FMM-BMM combined approach. First, it only serves the purpose of ambiguity detection (when the results of FMM and BMM do not match), and contributes nothing to its resolution. It has no way to tell which segmentation is right (compare case 1 and case 2), and, worse still, whether both are right (case 3) or wrong (case 4). Second, even when the results of FMM and BMM do match, it by no means guarantees right segmentation (case 6). Third, as far as detection is concerned, it is only limited to the problems for the cross ambiguity. The existence of the embedded ambiguity defines a blind area for this way of detection (case 6 and case 7). This is because the underlying maximum match hypothesis assumed in the FMM and BMM segmentation algorithms is directly contradictory to the phenomena of the embedded ambiguity.
In face of ambiguity, how do people judge which segmentation is right in the first place? It really depends on whether we can understand the sentence or phrase based on the segmentation. In computational linguistics, this is equivalent to whether the segmented string can be parsed by a grammar. The segmentation ambiguity is one type of structural ambiguity, not in essence different from typical structural ambiguity like, say, PP attachment ambiguity. In fact, PP attachment problem is a counterpart of the cross ambiguity in English syntax, as shown below.
(9.) Cross ambiguity in PP attachment: V NP PP
(a) [V NP] [PP]
(b) [V] [NP PP]
Therefore, like English PP attachment, Chinese word segmentation ambiguity should also be captured by a parsing grammar. A parser resolves the ambiguity if it can, or detects the ambiguity in the form of multiple parses when it cannot. As shall be demonstrated in Section 3, wrong segmentation will not lead to a parse. Right segmentation results in at least one successful parse. In any case, at least a parser (hence a grammar on which the parser is based) is required for proper word identification.
The important thing is that the ambiguity in word identification is a grammatical problem. The attempt to solve this problem without a grammar is bound to be crippled. Since traditional segmentation algorithms are non-grammatical in nature, they are theoretically not equipped for handling such ambiguity. A successive model of segmentater-before-grammar attempts to do what it is not yet able to do. This is the theoretical defect for almost all existing segmentation approaches.
(10.) Conclusion for 2.1.
The segmentation ambiguity in word identification is one type of structural ambiguity. In order to solve this problem, a parsing grammar is indispensable.
2.2. productive word formation
Unless morphological analysis is incorporated, lexicon match based segmenters will have trouble with new words produced by Chinese productive word formation, including reduplication, derivation and the formation of proper names. When the morphology component is incorporated in the segmenter, the two-step design becomes a variant of the conventional morphology-before-syntax architecture. But this architecture is not effective when the segmentation ambiguity is at issue.
In the following, we investigate reduplication, derivation and proper names one by one. In each case, we find that there is always a possible involvement of the segmentation ambiguity. This problem cannot be solved by a morphology component independent of syntax. We therefore propose a grammar incorporating both morphology and syntax.
2.2.1. reduplication
Reduplication in Chinese serves various grammatical and/or lexical functions. Not all reduplications pose challenges to segmentation algorithms. Assume that a word consists of 2 characters AB, reduplication of the type AB --> ABAB is no problem. What becomes a problem for word segmentation is the reduplication of the type AB --> AABB or its variants like AB --> AAB. For example, a two-morpheme verb with verb-object relation at the level of morphology has the following way of reduplication.
(11.) Verb Reduplication: AB --> AAB (for diminutive use)
分心 (get distracted) --> 分分心 (get distracted a bit)
让他分分心。
让 | 他 | 分分心
let | he | get distracted a bit
Let him relax a while.
It seems that reduplication is a simple process which can be handled by incorporating some procedure-based function calls in the segmentation algorithm. If a 3-character string, say 分分心, cannot be found in the lexicon, the reduplication procedure will check whether the first 2 characters are the same, and if yes, delete one of them and consult the lexicon again. But, such expansion of the segmentation algorithm is powerless when the segmentation ambiguity is involved. For example, it is wrong to regard 分分心 as of reduplication in the following sentence.
(12.) 这件事十分分心。
(a) * 这 | 件 | 事 | 十 | 分分心
this | CLA | thing | ten | get distracted a bit
(b) 这 | 件 | 事 | 十分 | 分心
this | CLA | thing | very | distracting
This thing is very distracting.
2.2.2. derivation
In Contemporary Mandarin, there have come to be a few morphemes functioning similarly to English affixes, e.g. 可 (-able) turns a transitive verb into an adjective.
(13.) 可 (-able) + Vt --> A
可 (-able) + 读 (Vt: read) --> 可读 (A:readable)
这本书非常可读。
这 | 本 | 书 | 非常 | 可读
this | CLA | book | very | readable
This book is very readable.
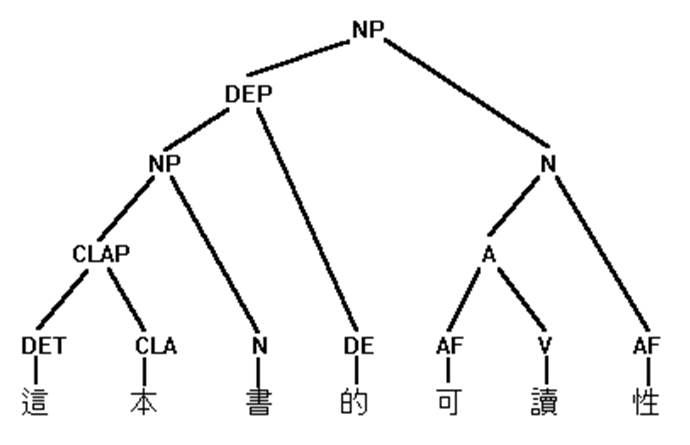
The suffix 性 works just like '-ness', changing an adjective into an abstract noun. The derived noun 可读性 (readability) in the following example, similar to its English counterpart, involves a process of double affixation.
(14.) A + 性 (-ness) --> N
可 (-able) + 读 (Vt: read) --> 可读 (A:readable)
可读 (A:readable) + 性 (-ness) --> 可读性 (N:readability)
这本书的可读性
这 | 本 | 书 | 的 | 可读性
this | CLA | book | DE | readability
this book's readability
The suffix Í· can change a transitive verb into an abstract noun adding to it the meaning "worth-of".
(15.) Vt + 头 (AF:worth of) --> N
吃 (Vt:eat) + 头 (AF:worth of) --> 吃头 (N:worth of eating)
这道菜没有吃头
这 | 道 | 菜 | 没有 | 吃头
this | CLA | dish | not-have | worth-of-eating
This dish is not worth eating.
It is not difficult to incorporate in the segmenter these derivation rules for the morphological analysis. But, as in the case of reduplication, there is always a danger of wrongly applying the rules due to possible ambiguity involved. For example, 吃头 is a sub-string of embedded ambiguity. It can be both a derived noun 'worth of eating' or two separate words as seen in the following example.
(16.) 他饿得能吃头牛。
(a) * 他 | 饿 | 得 | 能 | 吃头· | 牛
he | hungry | DE3 | can | worth-of-eating | ox
(b) 他 | 饿 | 得 | 能 | 吃 | 头 | 牛
he | hungry | DE3 | can | eat | CLA | ox
He is so hungry that he can eat an ox.
2.2.3. proper name
Proper names are of 2 major types: (1) Chinese names; (2) transliterated foreign names. In this paper, we only target the identification of Chinese names and leave the problem of transliterated foreign names for further research (Li, 1997b).
A Chinese human name usually consists of a family name followed by a given name. Chinese family names form a clear-cut closed set. A given name is usually either one character or two characters. For example, the late Chinese chairman 毛泽东 (Mao Zedong) used to have another name 李得胜 (Li Desheng). In the lexicon, 李 is a registered family name. Both 得胜 and 胜 mean 'win'. This may lead to 3 ways of word segmentation: (1) 李得胜; (2) 李|得胜; (3) 李得|胜, as seen in the following examples.
(17.) 李得胜了
(a) 李 | 得胜 | 了.
Li | win | LE
Li won.
(b) 李得 | 胜 | 了
Li De | win | LE
Li De won.
(c) * 李得胜 | 了.
Li Desheng | LE
(18.) 李得胜胜了 。
(a) * 李 | 得胜 | 胜 | 了.
Li | win | win | LE
(b) * 李得 | 胜 | 胜 | 了
Li De | win | win | LE
(c) 李得胜 | 胜 | 了
Li Desheng | win | LE
Li Desheng won.
Since the given name like µÃʤ is an arbitrary string of 1 or 2 characters, the morphological analysis of the full name should start with family name which can optionally combine with any 1 or 2 characters to form candidate proper names Àî, ÀîµÃ and ÀîµÃʤ. In other words, family name serves as the left boundary of a full name and the length is used to determine candidates. The right segmentation can only be made via sentence analysis as shown in the above examples.
Most Chinese place proper names are made of 1 to 3 characters, for example, 武汉市(Wuhu City), 南陵县 (Nanling County). The arbitrariness of these names makes any sub-strings of n characters (0<n<4) in the sentence a suspect. Fortunately, in most cases we may find boundary indicators of these names, like 省 (province), 市 (city), 县 (county), etc. Once the boundary indicator is located, the similar technique in using Chinese family name to identify the given name can be applied to select candidates of place proper names for verification through grammatical analysis.
In general, there is always a possibility of ambiguity involvement in the formation of all types of proper names.
(19.) Conclusion for 2.2.
Due to the possible involvement of ambiguity, a parsing grammar for morphological analysis as well as for sentence analysis is required for the proper identification of the words produced by Chinese productive word formation.
- W‑CPSG Grammatical Approach
This section presents W‑CPSG approach to Chinese word identification and morphological analysis. We will demonstrate how a parser based on W‑CPSG solves the problems of the word identification ambiguity and productive word formation.
3.1. rationale of W‑CPSG approach
There have been a number of word identification algorithms based on both morphological and syntactic information (see survey in Feng 1996 and Sun & Huang 1996). Most such approaches do not use a self-contained grammar to parse the complete sentence. They are confined to the conventional two-step process of the segmentation-before-grammar design. As long as the word identification procedure is independent of a parsing grammar, it is extremely difficult to make full use of grammatical information to resolve ambiguity in word identification. Careful tuning up and sophisticated design improves the precision but will not change the theoretical defect of all such approaches. Chen & Liu acknowledges the limitation of their approach due to the lack of a grammar. “However”, they say, “it is almost impossible to apply real world knowledge nor to check the grammatical validity at this stage”. (Chen & Liu 1992, p.105) Why impossible at this stage? Because these segmentation systems are based on the concept of two-step architecture and the grammar is not yet available! As we have demonstrated, the final judgment for proper word identification can hardly be made until the whole sentence is parsed, hence the requirement of a full grammar. Therefore, we are forced to make a compromise in involving how much of grammatical information depending on how much word identification precision we can afford to sacrifice. Needless to say, there is significant double-labor between such a word segmentation procedure and the following stage of parsing. As more and more grammatical information is used to achieve better precision, the overhead of this double labor becomes more serious. We consider the double labor as one strong argument against the two-step approach. If enough grammatical information is incorporated, it is essentially equivalent to a grammar. And the segmenter will be equivalent to a parser. Then why two grammars, one for word identification, and one for sentence parsing? Why not combine them? That is exactly what we are proposing in W‑CPSG - one-step approach based on an integrated grammar, eliminating the necessity of a segmentation preprocessor.
3.2. W‑CPSG character-based parsing
W‑CPSG (Li. 1997a, 1997b) is a lexicalized Chinese unification grammar. The work on W‑CPSG is taken in the spirit of the modern linguistic theory Head-driven Phrase Structure Grammar (Pollard & Sag 1994). W‑CPSG consists of two parts: a minimized general grammar and an enriched lexicon. The general grammar only contains a handful of PS (phrase structure) rules, covering complement structure, modifier structure, conjunctive structure and morphological structure. This is the nature of lexicalized grammars. PS rules in such grammars are very abstract. Essentially, all they say is one thing, that is, 2 signs can combine so long as the lexicon so indicates. The lexicon houses lexical entries with their linguistic description in feature structures. Potential morphological structures as well as potential syntactic structures are lexically encoded. In syntax, a word expects another sign to form a phrase. In morphology, a morpheme expects another sign to form a word. For example, the prefix 可 (-able) expects a transitive verb to form an adjective. The morphological PS rule will build the morphological structure when a transitive verb does appear after the prefix 可 (-able) in the input string.
We now illustrate how W‑CPSG parses a string of Chinese characters by a sample parsing chart. The prototype of W‑CPSG was written in ALE, a grammar compiler developed on top of Prolog by Carpenter & Penn (1994). ALE compiles W‑CPSG into a Chinese parser, a Prolog program ready to accept a string of characters for analysis. W‑CPSG parse tree embodies both morphological analysis and syntactic analysis, as shown below.

This is so-called bottom-up parsing. It starts with lexicon look-up. Edges 1 through 7 are lexical edges. Other edges are phrasal edges. Each edge represents a sign, i.e. a character (morpheme), a word, a phrase or a sentence. Lexical edges result from a successful match between the signs in the input string and the entries in the lexicon during lexicon look-up. For example, 可 (-able), 读 (read) and 性 (-ness) are all registered entries in the lexicon, so they get matched and shown by edge 5, edge 6 and edge 7. Words produced by productive word formation present themselves as phrasal edges, e.g. edge ((5+6)+7) for 可读性 (readability). For the sake of concise illustration, we only show two pieces of information for the signs in the chart, namely category and interpretation with a delimiting colon (lexical edges are only labeled for either category or interpretation). The parser attempts to combine the signs according to PS rules in the grammar until parses are found. A parse is an edge which ranges over the whole string. The parse ((((1+2)+3)+4)+((5+6)+7)) for (20.) represents a binary structural tree based on the W‑CPSG analysis, as shown below.
3.3. ambiguity resolution in word identification
Given the resources of a phrase structure grammar like W‑CPSG, a parser based on standard chart parsing algorithms can handle both the cross ambiguity and the embedded ambiguity provided that a match algorithm based on exhaustive lookup instead of maximum match is adopted for lexicon lookup. All candidate words in the input string are presented to the parser for judgment. Ambiguous segmentation becomes a natural part of parsing: different ways of segmentation add different edges, a successful parse always embodies right identification. In other words, word identification in our design becomes a by-product of parsing instead of a pre-condition for parsing. The following example of the complicated cross ambiguity illustrates how the W‑CPSG parser resolves ambiguity. As seen, both the FMM segmentation (represented by the edge sequence 8-9-5-10) and the BMM segmentation (represented by 1-11-12-10) are in the chart as a result of exhaustive lexicon lookup. They are proved to be wrong because they do not lead to a successful parse according to the grammar. As a by-product, the final parse (8+(3+(12+10))) automatically embodies rightly identified word sequence 8-3-12-10, i.e. 出现 (appear) |在 (at) |世界 (world) |东方 (east).

Exhaustive lookup also makes an embedded ambiguity sub-string like 烤红薯 no longer a blind area for word identification, as shown in (22.) below. All the candidate words in the sub-string including 烤 (bake), 红薯 (sweet potato), 烤红薯 (baked sweet potato) are added to the chart as lexical edges (edge 4, edge 8 and edge 10). This is a case of genuine ambiguity, resulting in 2 parses corresponding to 2 readings. The first parse (1+(7+10)) identifies the word sequence 他|喜欢|烤红薯, and the second parse (1+(9+(4+8))) a different sequence 他|喜欢|烤|红薯. Edge 7 and edge 9 represent two lexical entries for the verb 喜欢 (like), with different syntactic expectation (categorization). One expects an NP object, notated in the chart by like<NP>, and the other expects a VP complement, notated by like<VP>.
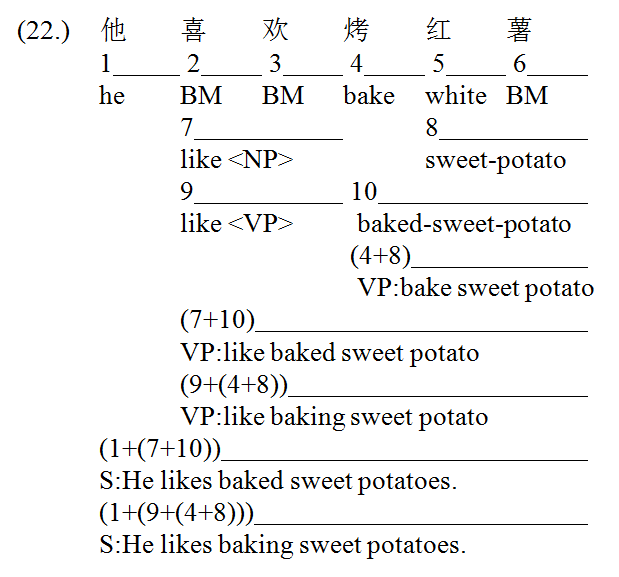
We now illustrate how Chinese proper names are identified in W‑CPSG parsing. In the W‑CPSG lexicon, Chinese family name is encoded to optionally expect the given name. Due to the arbitrariness of given names, no other constraint except for the length (either 1 character or 2 characters) is specified in the expectation. Therefore, we have three candidates for proper names in the following example, namely 李 (Li), 李得 (Li De), 李得胜 (Li Desheng), represented respectively by edge 1, edge (1+2) and the NP edge (1+5).[3] The first two candidates contribute to two valid parses while the third does not, hence the identification of the word sequences 李|得胜|了 and 李得|胜|了.
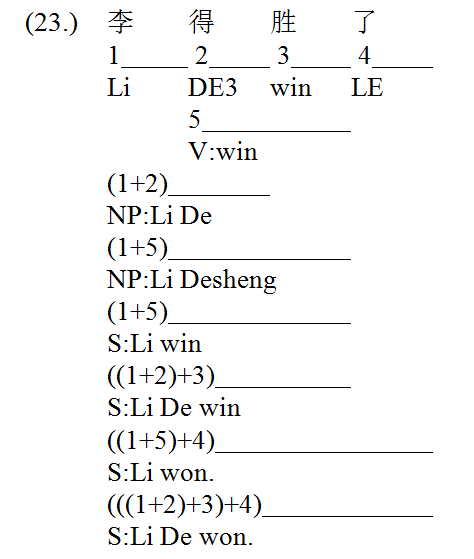
Now we add one more character 胜 (win) to form a new sentence, as shown in (24.) below.

The first two candidate proper names 李 (Li) and 李得 (Li De) no longer lead to parses. But the third candidate 李得胜 (Li Desheng) becomes part of the parse as a subject NP. The parse (((1+6)+4)+5) corresponds to the identification of the only valid word sequence 李得胜|胜|了.
Finally, we give an example to demonstrate how W‑CPSG handles reduplication in parsing and word identification. The sample sentence to be processed by the parser is 让他分分心 (Let him relax a while), involving the AB-->AAB type verb reduplication for diminutive use.
In most lexicons, 分心 (distract-heart: get distracted) is a registered 2-morpheme verb with internal morphological verb-object relation. Therefore, the reduplication is considered morphological. But in Chinese syntax, we also have a general verb reduplication rule of the type A-->AA for diminutive use, for example, 看(look) --> 看看(have a look). This morphological verb reduplication rule AB-->AAB and the syntactic verb reduplication rule A-->AA are essentially the same rule in Chinese grammar. 分心 sits in the gray area between morphology and syntax. It looks both like a word (verb) and a phrase (VP). Lexically, it corresponds to one generalized sense (concept) and the internal combination is idiomatic, i.e. 分 (distract) must combine with 心 (heart) to mean 'get distracted'. But, structurally, the combination of 分 and 心 is not fundamentally different from a VP consisting of Vt and NP, as in the phrase 看电影 (see a film). In fact, there is no clear-cut boundary between Chinese morphology and syntax. This morphology-syntax isomorphic fact serves as a further argument to support the W‑CPSG design of integrating morphology and syntax in one grammar module. Although the boundary between Chinese morphology and syntax is fuzzy, hence no universal definition of basic notions like word and phrase, the division can be easily defined system internally in an integrated grammar. In W‑CPSG, 分心 is treated as a phrase (VP) instead of a word (verb). The lexical entry 分 (distract) is coded to obligatorily expect the literal 心 (heart) as its syntactic object, shown in the following chart by the notation V<心>. This approach has the advantage of eliminating the doubling of the reduplication rule for diminutive use in both syntax and morphology, making the grammar more elegant. The verb reduplication rule is implemented as a lexical rule in W‑CPSG.[4] This lexical rule creates a reduplicated verb with added diminutive sense, shown by edge 8 (a lexical edge). The whole parsing process is illustrated below.

REFERENCES
Carpenter, B. & Penn, G. (1994): ALE, The Attribute Logic Engine, User's Guide, Carnegie Mellon University
Chen, K-J., & S-H. Liu (1992): "Word identification for mandarin Chinese sentences". Proceedings of the 15th International Conference on Computational Linguistics, Nantes, 101-107.
Feng, Z-W. (1996): "COLIPS lecture series - Chinese natural language processing", Communications of COLIPS, Vol.6, No.1 1996, Singapore
Li, W. (1997a): "Outline of an HPSG-style Chinese reversible grammar", Proceedings of The Northwest Linguistics Conference-97 (NWLC-97, forthcoming), UBC, Vancouver, Canada
Li, W. (1997b): W‑CPSG: A Lexicalized Chinese Unification Grammar And Its Application, Doctoral dissertation (on-going), Simon Fraser University, Canada
Liang, N. (1987): "Shumian Hanyu Zidong Fenci Xitong - CDWS" (Automatic word segmentation system for written Chinese - CDWS), Journal of Chinese Information Processing, No.2 1987, pp 44-52, Beijing
Pollard, C. & I. Sag (1994): Head-Driven Phrase Structure Grammar, Centre for the Study of Language and Information, Stanford University, CA
Sun, M-S. & C-N. Huang (1996): "Word segmentation and part of speech tagging for unrestricted Chinese texts" (Tutorial Notes for International Conference on Chinese Computing ICCC'96), Singapore
~~~~~~~~~~~~~~~~~~~
[1] The author benefited from the insightful discussion with Dr. Dekang Lin on the feasibility of parsing Chinese character strings instead of word strings. Thanks also go to Paul McFetridge and Fred Popowich for their supervision and encouragement.
[2] This table is adapted from the following table in Sun & Huang (1996).
| case 1 | The output of FMM and BMM are different, but both are incorrect | 0.054% |
| case 2 | The output of FMM and BMM are different, but only one is correct | 9.24% |
| case 3 | The output of FMM and BMM are identical, but incorrect | 0.41% |
| case 4 | The output of FMM and BMM are identical, and correct | 90.30% |
The 4 cases which they listed are not logically exhaustive in terms of sentence based processing (i.e. when discourse is not involved in a system). In particular, there is another case when the output of FMM and BMM are different, and both are correct. We call this a case of genuine cross ambiguity.
[3] Note that there is another S edge (1+5) in the chart. These two edges are structurally different, created via different PS rules. The NP edge (1+5) is formed through the morphological PS rule, combining the family name (edge 1) and its expected given name (edge 5). In the S edge (1+5). however, it is the subject rule (one of the complement PS rules) that decides the combination of the predicate (edge 5) and its expected subject NP (edge 1).
[4] Lexical rules are favored by many linguists to capture redundancy in the lexicon instead of the conventional approach of syntactic transformation. Lexical rules are applied at compile time to form an expanded lexicon before parsing starts.
[Related]
Interaction of syntax and semantics in parsing Chinese transitive verb patterns
Handling Chinese NP predicate in HPSG
Notes for An HPSG-style Chinese Reversible Grammar
Outline of an HPSG-style Chinese reversible grammar
PhD Thesis: Morpho-syntactic Interface in CPSG (cover page)
PhD Thesis: Chapter I Introduction
PhD Thesis: Chapter VII Concluding Remarks