白:
“张三打了李四一拳”“张三打李四的那一拳”
我的问题:1、“一拳”在两个例子里,跟“打”的“逻辑语义关系”是否是相同的?
2、如果相同,这种关系是不是萝卜和坑的关系?
3、如果是,那么这个坑是“打”自带的,还是被“一拳”的出现逼出来的?
4、非自带但可以被逼出来的坑,是一个个别现象还是一个普遍现象?是汉语特有的现象还是一个语言共性现象?
2':如果不同,第二例中的定语从句和中心语“那一拳”之间的关系是怎么建立的?
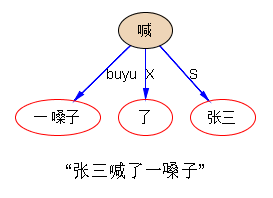
“张三喊了一嗓子”“张三喊的那一嗓子,我老远就听见了”,一个道理
另外,“回马枪”“窝心脚”等“工具扩展为招式”固定短语,是不是可以直接略掉量词,与数词结合?
我:
1. 逻辑语义上应该相同,句法上有【主谓】和【定语从句+NP】 的不同,很典型。
2 具体说,“打一拳” 就是搭配,是合成动词,与“洗澡”可比,不过后者是动宾搭配,前者是动补搭配。都是合成词的句法表现,都涉及词典与句法的动态接口。
直接量的搭配,当然属于罗卜与坑。
语言中的萝卜和坑,不外是 :(1)一个直接量(词)准备了一类词(feature)的坑;(2)一个直接量(词)准备了另一个直接量(词)的坑,通常叫强搭配;(3)一类词(feature)准备了另一类词(feature)的坑。(3) 是常规句法的表现,属于空对空,两边都不着地。其规则(feature based grammar)概括性强,但容易遭遇例外的滑铁卢。lexicalized grammar or word driven rules,越来越远离(3),或者把(3)限定在一个极少的数量上。那么就剩下(1)和(2)了。
“打...一拳” 是(1),这就到了你的第三个问题,两个直接量的搭配,谁 expects 谁?
纯技术上讲,根本就没有区分,或者说,等价。x 与 y 相互勾搭,说是 x 勾搭了 y 或者 y 勾搭了 x,都无所谓,反正他们是一家人,本来就是一个词,一个概念,不过到了语言表达,被人为分开了距离。
【3、如果是,那么这个坑是“打”自带的,还是被“一拳”的出现逼出来的?】
“打一拳”就是一个词条,概念上是混为一体的,不分你我,无所谓主次(动补的主次是词法内部的,可以无视)。但是操作上,可以有说法。(不知道汉语的搭配词典里面,“打一拳”这样的条目是放在 “打” 的下面,还是 “一拳” 的下面,还是两个地方都有?)但是,在NLP实现中,“打一拳” 与 “洗澡” 一样,是一个特定的分离词词条。不过是标签不同而已,譬如 Vo 与 Vbu,其他的事儿就交给句法了。
【4、非自带但可以被逼出来的坑,是一个个别现象还是一个普遍现象?是汉语特有的现象还是一个语言共性现象?】
对于直接量搭配,我的看法是,没有自带和被逼的问题,都是两厢情愿的相互吸引。
这个应该属于普遍现象: x--y,汉语有 “洗-澡”, 英语有 “take--bath”。词法是动补或者动词与状语这样的直接量与直接量的搭配,其他语言肯定也会有,不过一时想不到例子而已。
白:
打一苕帚疙瘩,也是搭配
任何顺手的东西,都可以抄起来就打
搭配的做法未免太ad hoc
我:
所有的词典都是 ad hoc,不然就不叫绑架了。但是 词条背后的 x--y 搭配 则是有语言共性的。
白:
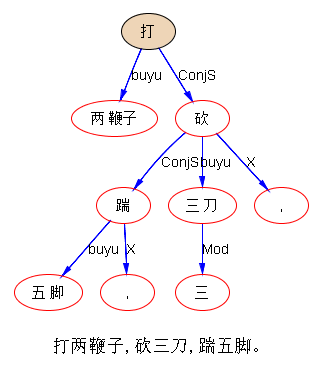
问题是不可穷尽,而且本来能产,是一个有规律性的现象,打两鞭子,砍三刀,踹五脚。
我:
不可穷尽 那就不是 x--y 强搭配。理论上 不是 x --- y,就只能是 x ---- feature,或者 feature1 ----- feature2,没有其他的框可以进去。
“砍三刀” 与 “洗三个澡” 可比吗?要是可以,那就是 x --- y,可变的不过是 numeral,两端还是固定的:“踹-脚”,“砍--刀”。
白:
加量词的不算,只算省略量词的.明显的是工具,但是原动词很难说自带了“工具”这个坑。
我:
有些中间地带的现象。
说到底是路线问题。如果是 lexicalist 的路线,中间地带的一律进入词典,不在乎 ad hoc,不在乎冗余,好处是精准。如果是“传统”的文法,那就把中间地带划归到句法去,具有完全的产生性,好处是 不错的recall,但很容易被例外搅合,损失了精准(precision)。当然也可以二者结合,先弄一条 recall 的兜底,然后见到中间地带弄错了的,再去结合词典堵它。recall 楼底的可以想象的 rule 是这样的,利用了汉语名词通常不能直接为数词修饰的句法特点:
V + CD + N --> V Buyu
这一条可以搂住很多,但是危险。修修补补也可以把这条规则的危险减小,但不能杜绝,因为这是 feature based rule 的本性(POS 是 feature )。
接着练,我们可以有个楼底的规则来满足白老师说的某种语言现象的共性:
V +(时态小词)+ CD + N ==> V <-- Buyu[CD+N]
这条规则可以 parse 上面列举的所有现象,但是还是 too “powerful”, recall 有余,precision 不足。不过 precision 这东西,工程上靠的就不断扩大测试,测试不错的话就当没有精度问题,如果测试遇到问题了,有三个路子:(1)一个是在这一条规则中打磨,把 POS 条件细化成子类或ontology,或其他限制;(2) 第二个路子是另写一条细线条规则去 override 它,使得文法成为一个 hierarchy 的模块;(3) 第三个路子就是把错的东西(例外)扔进词典, 这实际上等价于第二条路子的极限 case,把词典当成是 rule hierarchy 的极端。有了这么一个从词典规则,到细线条 feature 规则,最后到 POS 的抽象层规则的 hierarchy 的规则化设计,就可以应对语言的例外、个性一直到共性及其之间的灰色地带。
懒得大数据,甚至懒得词典绑架搭配,上面那条默认规则送进系统先凑合事儿吧,就坐等今后例外慢慢地出现,再说。
白:
为什要在细粒度基于规则
这里说的这个层面规则的缺点,用学习对付起来正是优势
我:
不要细粒度也可以啊,抓两头带中间。大不了有些 redundancy,灰色的一律当成黑色。不可穷举不过是一种修辞说法。从统计上,处于灰色地带的东西一定是可以穷举的,不过是穷举到后来成了统计性长尾,不要再举而已。
白:
我是说,这里不存在二分法,除了词典捆绑就是基于规则, 可以基于学习
我:
白老师可以 illustrate 基于学习的东西,优势在哪里?(其实这个问题,我没觉得是一个对规则系统的挑战。没觉得它的挑战超越了 “洗澡”)
白:
不能穷举、规则又零乱,正好拿可以部分例子来学。feature很值钱,长尾的实例也很值钱,裹在一起学才是正道,既有泛化,又有死记硬背。
白:
拿有规律性的东西死记硬背,是逼着好孩子耍流氓
我:
从良性角度,也可以说是教育孩子脚踏实地,一步一个脚印。
白:
在泛化和死记硬背的灰色地带,该用学习就用学习。
看着不爽,又不是没办法。
只有应试教育、临阵磨枪,才把什么活的都搞死
我:
这里面的根本是,迄今为止,一个系统要不是统计的,要不是规则的。所谓 hybrid 的系统,大多是是两个系统的叠加,而不是融合。在这样一个 context 下,就不是说,我规则的规则,词典的词典,中间混杂一些统计学习。虽然后者应该是一个研究方向,而且应该可能做得比叠加式 hybrid 更高明。如果白老师说的是纯粹的学习系统,那是另一套话语体系,no comment。从规则这边看,抓两头,把灰色当黑色做,没有问题,不过是磨时间而已。共性规则保证了 recall,而 precision 就是时间的函数。
白:
我说的是,谁可能跟谁结合用规则,在同样符合规则情况下,谁排除跟谁结合用学习,但这是无监督学习,标注来自词典。前面用规则的只涉及萝卜、坑和帽子,不涉及subcat。后面学习的则是用subcat。
我:
其实 就用 V+CD+N 这个简单的模式到海量数据去,抓回来的无监督学习也大体就齐了。这是一个很狭窄的语言现象。无监督学习的结果就是这个特定的 subcat 的 knowledge acquisition,这是一个 offline 的学习过程。然后再利用学习出来的结果,支持 parsing
白:
其实这楼已经歪了。我的本意是在探讨逼出来的非标配的坑。
如果可以那样做,离语言的本质或许更近。
“他上学的那个学校”;“他约会的那个晚上”。
不加数词也存在把在一个句式里充当状语或补语的名词在另一个相关句式中充当主谓语,而逻辑语义关系不变的情况。而那个名词的真实身份是工具、处所、时间等角色。本来对于动词来说不是标配的。来到了某种位置,就逼迫动词把这个角色变为标配。
英语的介词结尾:the man you look for,可以给它们明确身份,即使在定语从句,也是庶出(介词养的,不是动词养的)。当然可以说动介组合look for养的。
汉语里进入定语从句后分不出来谁养的,反正介词消失了,带着反而不对。带着就要把零形式用真实代词替换:“你在其中上学的学校”,“你与之结婚的女人”
加数词,只不过突出了动量含义,不改变逻辑语义关系。
砍张三的斧子……着眼工具
砍张三的两斧子……着眼动作的次数
砍张三的斧子……用来(以/之/其)砍张三的斧子
我:
补语表示次数是逻辑语义工具在语言中的"虚化"(同时“形象化”)的用法,这种虚化用法本身不是语言共性,但可以映射到到深层的逻辑语义【工具】: 【工具】是 universal 的。就“砍”而言,【工具】不是逼迫出来的标配,而是自带的标配,不信可以查董老师的 HowNet,结婚 的标配是 with [human],对于 上学, 学校 是不是自带的?大概也可以这么说,不知道知网里面 上学 有没有一个 location 的槽,标配是学校。
可以找一个完全 random 的定义或状语试试,好像不行。似乎很难找到一个具有同样逻辑语义的,并且可以参与下面两个句式的案例:补语句式(表示次数)和定语句式。换句话说,这种现象要不就是搭配,要不就是搭配的延伸,而不是 random 的修饰语(adjunct)的组合,或者从 adjunct 被逼迫成的 complement,里面的逻辑语义是概念关系的某种 argument,有其结合的必然性。这种搭配似乎可以是词对词(两条腿落地),也可能是词对小类(feature:一条腿落地)。前者是强搭配的词典绑架,后者是灰色的,不一定可以绑架得了,统计可以学习出来。
白:
正是我要说的
我:
白老师岂止是四两拨千斤 lol
词对小类的subcat的习得,譬如 某个动词要求的是某种宾语(譬如【human】),这种东西可以从大数据学习出来:这个概念已经有日子了。剑桥大学一个教授多年前就倡导这种学习,好像也做了一批实验,印象也发表了一些文章。但这些研究总体来说是零星的,研究的归研究,应用的归应用,二者似乎也没有什么结合起来让人印象深刻的成果。
白:
没有把搭配学习锚定在结构上,是没戏的
你如果又学结构又学搭配,肯定乱套
一定是选定少数几种可能的结构,让搭配来进一步甄别,各司其职
白:
“砍”的工具可以是标配,“打”不行。适合“打”的subcat很不整齐,我们心里想的是“顺手可以抄起来的物件”但是subcat列表上不会顺顺当当给你这个。于是,要诸多subcat、诸多词例都当作features,想办法从可以列举的例子(包括已经可以确认的词例-subcat子规则)学出来。
炉子太大,抄不起来。房子更大。扫把大小适中。细菌太小。所以,“张三打李四一大肠杆菌”不通。
我:
用 pattern 打+CD+N,一学一个准 只要有海量数据,根本不用怕噪音,因为这个 pattern 非常好使。
联想到10多年前谷歌有人发过一篇论文,用两个特别拣选的 ngram patterns,学出了 ISA 的 taxonomy,让人印象深刻。后来我们还重复了这个工作,虽然并没真正用上其结果,但路子是对的。照着类似学习的路子,HowNet 有一天也是可以学出来的,只要董老师定义好要学的几个语义关系的性质,找到合适的 patterns。
谷歌用的两个 patterns 是: N such as X, Y, Z ;X, Y, Z and other N
e.g.
furniture such as desks, chairs, coffee-tables
desks, chairs, coffee-tables and other furniture (will all be on sale)
taxonomy is: {X, Y, Z} -->N
学他有啥用,反正人拍着脑袋慢慢想也可以想出来呀。HowNet 语义关系丰富,所以编写了很多年,但是终究还是编写出来了,几乎完备了(董老师好像如今只是零星地补充和添加了)。既然专家可以人工编写,既完备,又精良,有什么理由指望大数据去习得这些知识呢?这是问题的一面,特别是对于相对恒定久远的概念语义关系,确实没有道理不用专家的产品。
问题的另一面是,对于具有某种流动性的概念关系,专家很难赶得上机器习得(acquisition),还有不同领域的知识,等等。这是人力不及的地带,只有指靠大数据和机器了。上面的谷歌论文中举了一些例子,特别有意思,记得是说,学出来一个 dictator 的下位概念,里面的成员极具大数据的特点,有 卡斯特罗,毛泽东,斯大林,希特勒,etc。
白:
这是主观分类了,不合适放词典里。还有“知名品牌”的实例, 马上就有商业价值了。
我:
这不是我每天做的工作吗:social media mining of public opinions and sentiments
我们公司定期出版全球知名品牌的口碑排行榜之类,印刷精良。以前出版的是奢侈品牌(名牌包、名牌轿车、高级香水)等。最近出的一期是: Social Media Industry Report 2016: Restaurant Brand
刚测试了一下白老师的例句,最奇葩的是这个:
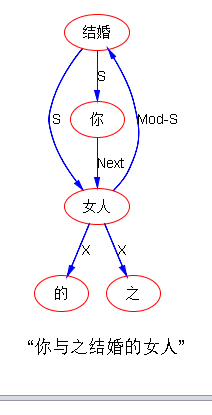
长成葫芦状的树形图,以前还真没见过。(词典里没有小词 “与之”,PP 也没合成它,于是被略去。)尽管如此,整个图是很逻辑的,撞了不知道什么运:“你”是结婚的一方(S),“女人”也是结婚的一方(S),这两方结婚的事件是一个定语从句(Mod-S),修饰到了“女人”的头上。至于小词 “的”、“之”,还有耍流氓的咸猪手 Next,这一切都是帮助建立结构的敲门砖,这些表层东西与逻辑语义无关,留在那里不是为了碍眼,而是为了在语义的语用落地的时候,万一需要表层痕迹的一些帮助呢。after all 语义计算的的目的不是为了画出好看的逻辑的图,自娱娱人,而是为了落地、做产品。
【相关】