1.0. Foreword
This thesis addresses the issue of the Chinese morpho-syntactic interface. This study is motivated by the need for a solution to a series of long-standing problems at the interface. These problems pose challenges to an independent morphology system or a separate word segmenter as there is a need to bring in syntactic information in handling these problems.
The key is to develop a Chinese grammar which is capable of representing sufficient information from both morphology and syntax. On the basis of the theory of Head-Driven Phrase Structure Grammar (Pollard and Sag 1987, 1994), the thesis will present the design of a Chinese grammar, named CPSG95 (for Chinese Phrase Structure Grammar). The interface between morphology and syntax is defined system internally in CPSG95. For each problem, arguments will be presented for the linguistic analysis involved. A solution to the problem will then be formulated based on the analysis. The proposed solutions are formalized and implementable; most of the proposals have been tested in the implementation of CPSG95.
In what follows, Section 1.1 reviews some important developments in the field of Chinese NLP (Natural Language Processing). This serves as the background for this study. Section 1.2 presents a series of long-standing problems related to the Chinese morpho-syntactic interface. These problems are the focus of this thesis. Section 1.3 introduces CPSG95 and sketches its morpho-syntactic interface by illustrating an example of the proposed morpho-syntactic analysis.
1.1. Background
This section presents the background for the work on the interface between morphology and syntax in CPSG95. Major development on Chinese tokenization and parsing, the two areas which are related to this study, will be reviewed.
1.1.1. Principle of Maximum Tokenization and Critical Tokenization
This section reviews the influential Theory of Critical Tokenization (Guo 1997a) and its implications. The point to be made is that the results of Guo’s study can help us to select the tokenization scheme used in the lexical lookup phase in order to create the basis for morpho-syntactic parsing.
Guo (1997a,b,c) has conducted a comprehensive formal study on tokenization schemes in the framework of formal languages, including deterministic tokenization such as FT (Forward Maximum Tokenization) and BT (Backward Maximum Tokenization), and non-deterministic tokenization such as CT (Critical Tokenization), ST (Shortest Tokenization) and ET (Exhaustive Tokenization). In particular, Guo has focused on the study of the rich family of tokenization strategies following the general Principle of Maximum Tokenization, or “PMT”. Except for ET, all the tokenization schemes mentioned above are PMT-based.
In terms of lexical lookup, PMT can be understood as a heuristic by which a longer match overrides all shorter matches. PMT has been widely adopted (e.g. Webster and Kit 1992; Guo 1997b) and is believed to be “the most powerful and commonly used disambiguation rule” (Chen and Liu 1992:104).
Shortest Tokenization, or “ST”, first proposed by X. Wang (1989), is a non-deterministic tokenization scheme following the Principle of Maximum Tokenization. A segmented token string is shortest if it contains the minimum number of vocabulary words possible - “short” in the sense of the shortest word string length.
Exhaustive Tokenization, or “ET”, does not follow PMT. As its name suggests, the ET set is the universe of all possible segmentations consisting of all candidate vocabulary words. The mathematical definition of ET is contained in Definition 4 for “the character string tokenization operation” in Guo (1997a).
The most important concept in Guo’s theory is Critical Tokenization, or “CT”. Guo’s definition is based on the partially ordered set, or ‘poset’, theory in discrete mathematics (Kolman and Busby 1987). Guo has found that different segmentations can be linked by the cover relationship to form a poset. For example, abc|d and ab|cd both cover ab|c|d, but they do not cover each other.
Critical tokenization is defined as the set of minimal elements, i.e. tokenizations which are not covered by other tokenizations, in the tokenization poset. Guo has given proof for a number of mathematical properties involving critical tokenization. The major ones are listed below.
- Every tokenization is a subtokenization of (i.e. covered by) a critical tokenization, but no critical tokenization has a true supertokenization;
- The tokenization variations following the Principle of Maximum Tokenization proposed in the literature, such as FT, BT, FT+BT and ST, are all true sub-classes of CT.
Based on these properties, Guo concludes that CT is the precise mathematical description of the widely adopted Principle of Maximum Tokenization.
Guo (1997c) further reports his experimental studies on relative merits of these tokenization schemes in terms of three quality indicators, namely, perplexity, precision and recall. The perplexity of a tokenization scheme gives the expected number of tokenized strings generated for average ambiguous fragments. The precision score is the percentage of correctly tokenized strings among all possible tokenized strings while the recall rate is the percentage of correctly tokenized strings generated by the system among all correctly tokenized strings. The main results are:
- Both FT and BT can achieve perfect unity perplexity but have the worst precision and recall;
- ET achieves perfect recall but has the lowest precision and highest perplexity;
- ST and CT are simple with good computational properties. Between the two, ST has lower perplexity but CT has better recall.
Guo (1997c) concludes, “for applications with moderate performance requirement, ST is the choice; otherwise, CT is the solution.”
In addition to the above theoretical and experimental study, Guo (1997b) also develops a series of optimized algorithms for the implementation of these generation schemes.
The relevance and significance of Guo’s achievement to the research in this thesis lie in the following aspect. The research on Chinese morpho-syntactic interface is conducted with the goal of supporting Chinese morpho-syntactic parsing. The input to a Chinese morpho-syntactic parser comes directly from the lexical lookup of the input string based on some non-deterministic tokenization scheme (W. Li 1997, 2000; Wu and Jiang 1998). Guo’s research and algorithm development can help us to decide which tokenization schemes to use depending on the tradeoff between precision, recall and perplexity or the balance between reducing the search space and minimizing premature commitment.
1.1.2. Monotonicity Principle and Task-driven Segmentation
This section reviews the recent development on Chinese analysis systems involving the interface between morphology and syntax. The research on the Chinese morpho-syntactic interface in this thesis echoes this new development in the field of Chinese NLP.
In the last few years, projects have been proposed for implementing a Chinese analysis system which integrates word identification and parsing. Both rule-based systems and statistical models have been attempted with good results.
Wu (1998) has addressed the drawbacks of the conventional practice on the development of Chinese word segmenters, in particular, the problem of premature commitment in handling segmentation ambiguity. In his A Position Statement on Chinese Segmentation, Wu proposed a general principle:
Monotonicity Principle for segmentation:
A valid basic segmentation unit (segment or token) is a substring that no processing stage after the segmenter needs to decompose.
The rationale behind this principle is to prevent premature commitment and to avoid repetition of work between modules. In fact, traditional word segmenters are modules independent of subsequent applications (e.g. parsing). Due to the lack of means for accessing sufficient grammar knowledge, they suffer from premature commitment and repetition of work, hence violating this principle.
Wu’s proposal of the monotonicity principle is a challenge to the Principle of Maximum Tokenization. These two principles are not always compatible. Due to the existence of hidden ambiguity (see 1.2.1), the PMT-based segmenters by definition are susceptible to premature commitment leading to “too-long segments”. If the target application is designed to solve the hidden ambiguity problem in the segments, “decomposition” of some segments is unavoidable.
In line with the Monotonicity Principle, Wu (1998) proposes an alternative approach which he claims “eliminates the danger of premature commitment”, namely task-driven segmentation. Wu (1998) points out, “Task-driven segmentation is performed in tandem with the application (parsing, translating, named-entity labeling, etc.) rather than as a preprocessing stage. To optimize accuracy, modern systems make use of integrated statistically-based scores to make simultaneous decisions about segmentation and parsing/translation.” The HKUST parser, developed by Wu’s group, is such a statistical system employing the task-driven segmentation.
As for rule-based systems, similar practice of integrating word identification and parsing has also been explored. W. Li (1997, 2000) proposed that the results of an ET-based lexical lookup directly feed the parser for the hanzi-based parsing. More concretely, morphological rules are designed to build word internal structure for productive morphology and non-productive morphology is lexicalized via entry enumeration.[1] This approach is the background for conducting the research on Chinese morpho-syntactic interface for CPSG95 in this dissertation.
The Chinese parser on the platform of multilingual NLPWin developed by Microsoft Research also integrates word identification and parsing (Wu and Jiang 1998). They also use a hand-coded grammar for word identification as well as for sentential parsing. The unique part of this system is the use of a certain lexical constraint on ET in the lexical lookup phase. This effectively reduces the parsing search space as well as the number of syntactic trees produced by the parser, with minimal sacrifice in the recall of tokenization. This tokenization strategy provides a viable alternative to the PMT-based tokenization schemes like CT or ST in terms of the overall balance between precision, recall and perplexity.
The practice of simultaneous word identification and parsing in implementing a Chinese analysis system calls for the support of a grammar (or statistical model) which contains sufficient information from both morphology and syntax. The research on Chinese morpho-syntactic interface in this dissertation aims at providing this support.
1.2. Morpho-syntactic Interface Problems
This section presents a series of outstanding problems in Chinese NLP which are related to the morpho-syntactic interface. One major goal of this dissertation is to argue for the proposed analyses of the problems and to provide solutions to them based on the analyses.
Sun and Huang (1996) have reviewed numerous cases which challenge the existing word segmenters. As many of these cases call for an exchange of information between morphology and syntax, an appropriate solution can hardly be reached within the module of a separate word segmenter. Three major problems at issue are presented below.
1.2.1. Segmentation ambiguity
This section presents the long-standing problem in Chinese tokenization, i.e. the resolution of the segmentation ambiguity. Within a separate word segmenter, resolving the segmentation ambiguity is a difficult, sometimes hopeless job. However, the majority of ambiguity can be resolved when a grammar is available.
Segmentation ambiguity has been the focus of extensive study in Chinese NLP for the last decade (e.g. Chen and Liu 1992; Liang 1987; Sproat, Shih, Gale and Chang 1996; Sun and Huang 1996; Guo 1997b). There are two types of segmentation ambiguities (Liang 1987; Guo 1997b): (i) overlapping ambiguity: e.g. da-xue | sheng-huo vs. da-xue-sheng | huo as shown in (1-1) and (1-2); and (ii) hidden ambiguity: ge-ren vs. ge | ren, as shown in (1-3) and (1-4).
(1-1.) 大学生活很有趣
da-xue | sheng-huo | hen | you-qu
university | life | very | interesting
The university life is very interesting.
(1-2.) 大学生活不下去了
da-xue-sheng | huo | bu | xia-qu | le
university student | live | not | down | LEs
University students can no longer make a living.
(1-3.) 个人的力量
ge-ren | de | li-liang
individual | DE | power
the power of an individual
(1-4.) 三个人的力量
san | ge | ren | de | li-liang
three | CLA | person |DE | power
the power of three persons
These examples show that the resolution of segmentation ambiguity requires larger syntactic context and grammatical analysis. There will be further arguments and evidence in Chapter II (2.1) for the following conclusion: both types of segmentation ambiguity are structural by nature and require sentential analysis for the resolution. Without access to a grammar, no matter how sophisticated a tokenization algorithm is designed, a word segmenter is bound to face an upper bound for the precision of word identification. However, in an integrated system, word identification becomes a natural by-product of parsing (W. Li 1997, 2000; Wu and Jiang 1998). More precisely, the majority of ambiguity can be resolved automatically during morpho-syntactic parsing; the remaining ambiguity can be made explicit in the form of multiple syntactic trees.[2] But in order to make this happen, the parser requires reliable support from a grammar which contains both morphology and syntax.
1.2.2. Productive Word Formation
Non-listable words created via productive morphology pose another challenge (Sun and Huang 1996). There are two major problems involved in this issue: (i) problem in identifying lexicon-unlisted words; (ii) problem of possible segmentation ambiguity.
One important method of productive word formation is derivation. For example, the derived word 可读性 ke-du-xing (-able-read-ness: readability) is created via morphology rules, informally formulated below
(1-5.) derivation rules
ke + X (transitive verb) --> ke-X (adjective, semantics: X-able)
Y (adjective or verb) + xing --> Y-xing (abstract noun, semantics: Y-ness)
Rules like the above have to be incorporated properly in order to correctly identify such non-listable words. However, there has been little research in the literature on what formalism should be adopted for Chinese morphology and how it should be interfaced to syntax.
To make the case more complicated, ambiguity may also be involved in productive word formation. When the segmentation ambiguity is involved in word formation, there is always a danger of wrongly applying morphological rules. For example, 吃头 chi-tou (worth of eating) is a derived word (transitive verb + suffix tou); however, it can also be segmented as two separate tokens chi (eat) | tou (CLA), as shown in (1-6) and (1-7) below.
(1-6.) 这道菜没有吃头
zhe | dao | cai | mei-you | chi-tou
this | CLA | dish | not have | worth-of-eating
This dish is not worth eating.
(1-7.) 他饿得能吃头牛
ta | e | de | neng | chi | tou | niu
he | hungry | DE3 | can | eat | CLA | ox
He is so hungry that he can eat an ox.
To resolve this segmentation ambiguity, as indicated before in 1.2.1, the structural analysis of the complete sentences is required. An independent morphology system or a separate word segmenter cannot handle this problem without accessing syntactic knowledge.
1.2.3. Borderline Cases between Morphology and Syntax
It is widely acknowledged that there is a remarkable gray area between Chinese morphology and Chinese syntax (L. Li 1990; Sun and Huang 1996). Two typical cases are described below. The first is the phenomena of Chinese separable verbs. The second case involves interfacing derivation and syntax.
Chinese separable verbs are usually in the form of V+N and V+V or V+A. These idiomatic combinations are long-standing problems at the interface between compounding and syntax in Chinese grammar (L. Wang 1955; Z. Lu 1957; Lü 1989; Lin 1983; Q. Li 1983; L. Li 1990; Shi 1992; Zhao and Zhang 1996).
The separable verb 洗澡 xi zao (wash‑bath: take a bath) is a typical example. Many native speakers regard xi zao as one word (verb), but the two morphemes are separable. In fact, xi+zao shares the syntactic behavior and the pattern variations with the syntactic transitive combination V+NP: not only can aspect markers appear between xi and zao, but this structure can be passivized and topicalized as well. The following is an example of topicalization (of long distance dependency) for xi zao.
(1-8.)(a) 我认为他应该洗澡
wo ren-wei ta ying-gai xi zao.
I think he should wash-bath
I think that he should take a bath.
(b) 澡我认为他应该洗
zao wo ren-wei ta ying-gai xi.
bath I think he should wash
The bath I think that he should take.
Although xi zao behaves like a syntactic phrase, it is a vocabulary word in the lexicon due to its idiomatic nature. As a result, almost all word segmenters output xi-zao in (1-8a) as one word while treating the two signs[3] in (1-8b) as two words. Thus the relationship between the separated use of the idiom and the non-separated use is lost.
The second case represents a considerable number of borderline cases often referred to as ‘quasi-affixes’. These are morphemes like 前 qian (former, ex-) in words like 前夫 qian-fu (ex-husband), 前领导 qian-[ling-dao] (former boss) and -盲 mang (person who has little knowledge of) in words like 计算机盲 [ji-suan-ji]-mang (computer layman), 法盲 fa-mang (person who has no knowledge of laws).
It is observed that 'quasi-affixes' are structurally not different from other affixes. The major difference between 'quasi-affixes' and the few generally honored ('genuine') affixes like the nominalizer 性 -xing (-ness) lies mainly in the following aspect. The former retain some 'solid' meaning while the latter are more functionalized. Therefore, the key to this problem seems to lie in the appropriate way of coordinating the semantic contribution of the derived words using 'quasi-affixes' to the building of the semantics for the entire sentence. This is an area which has not received enough investigation in the field of Chinese NLP. While many word segmenters have included some type of derivational processing for a few typical affixes, few systems demonstrate where and how to handle these 'quasi-affixes'.
1.3. CPSG95: HPSG-style Chinese Grammar in ALE
To investigate the interaction between morphological and syntactic information, it is important to develop a Chinese grammar which incorporates morphology and syntax in the same formalism. This section gives a brief presentation on the design and background of CPSG95 (including lexicon).
1.3.1. Background and Overview of CPSG95
Shieber (1986) distinguishes two types of grammar formalism: (i) theory-oriented formalism; (ii) tool-oriented formalism. In general, a language-specific grammar turns to a theory-oriented formalism for its foundation and a tool-oriented formalism for its implementation. The work on CPSG95 is developed in the spirit of the theory-oriented formalism Head-driven Phrase Structure Grammar (HPSG, proposed by Pollard and Sag 1987). The tool-oriented formalism used to implement CPSG95 is the Attribute Logic Engine (ALE, developed by Carpenter and Penn 1994).
The unique feature of CPSG95 is its incorporation of Chinese morphology in the HPSG framework.[4] Like other HPSG grammars, CPSG95 is a heavily lexicalized unification grammar. It consists of two parts: a minimized general grammar and an information-enriched lexicon. The general grammar contains a small number of Phrase Structure (PS) rules, roughly corresponding to the HPSG schemata tuned to the Chinese language.[5] The syntactic PS rules capture the subject-predicate structure, complement structure, modifier structure, conjunctive structure and long-distance dependency. The morphological PS rules cover morphological structures for productive word formation. In one version of CPSG95 (its source code is shown in APPENDIX I), there are nine PS rules: seven syntactic rules and two morphological rules.
In CPSG95, potential morphological structures and potential syntactic structures are both lexically encoded. In syntax, a word can expect (subcat-for or mod in HPSG terms) another sign to form a phrase. Likewise, in Chinese morphology, a morpheme can expect another sign to form a word.[6]
One important modification of HPSG in designing CPSG95 is to use an atomic approach with separate features for each complement to replace the list design of obliqueness hierarchy among complements. The rationale and arguments for this modification are presented in Section 3.2.3 in Chapter III.
1.3.2. Illustration
The example shown in (1-9) demonstrates the morpho-syntactic analysis in CPSG95.
(1-9.) 这本书的可读性
zhe ben shu de ke du xing
this CLA book DE AF:-able read AF:-ness
this book’s readability
(Note: CLA for classifier; DE for particle de; AF for affix.)
Figure 1 illustrates the tree structure built by the morphological PS rules and the syntactic PS rules in CPSG95
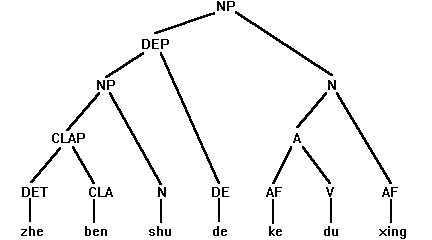
Figure 1. Sample Tree Structure for CPSG95 Analysis
As shown, the tree embodies both morphological analysis (the sub-tree for ke-du-xing) and syntactic analysis (the NP structure). The results of the morphological analysis (the category change from V to A and to N and the building of semantics, etc.) are readily accessible in building syntactic structures.
1.4. Organization of the Dissertation
The remainder of this dissertation is divided into six chapters.
Chapter II presents arguments for the need to involve syntactic analysis for a proper solution to the targeted morpho-syntactic problems. This establishes the foundation on which CPSG95 is based.
Chapter III presents the design of CPSG95. In particular, the expectation feature structures will be defined. They are used to encode the lexical expectation of both morphological and syntactic structures. This design provides the necessary means for formally defining Chinese word and the interface of morphology, syntax and semantics.
Chapter IV is on defining the Chinese word. This is generally recognized as a basic issue in discussing Chinese morpho-syntactic interface. The investigation leads to a way of the wordhood formalization and a coherent, system-internal definition of the work division between morphology and syntax.
Chapter V studies Chinese separable verbs. It discusses wordhood judgment for each type of separable verbs based on their distribution. The corresponding morphological or syntactic solutions will then be presented.
Chapter VI investigates some outstanding problems of Chinese derivation and its interface with syntax. It will be demonstrated that the general approach to Chinese derivation in CPSG95 works both for typical cases of derivation and the two special problems, namely 'quasi-affix' phenomena and zhe-affixation.
The last chapter, Chapter VII, concludes this dissertation. In addition to a concise retrospect for what has been achieved, it also gives an account of the limitations of the present research and future research directions.
Finally, the three appendices give the source code of one version of the implemented CPSG95 and some tested results.[7]
--------------------------------------------------
[1] In line with the requirements by Chinese NLP, this thesis places emphasis on the analysis of productive morphology: phenomena which are listable in the lexicon are not the major concern. This is different from many previous works on Chinese morphology (e.g. Z. Lu 1957; Dai 1993) where the bulk of discussions is on unproductive morphemes (affixes or ‘bound stems’).
[2] Ambiguity which remains after sentential parsing may be resolved by using further semantic, discourse or pragmatic knowledge, or ‘filters’.
[3] In CPSG95 and other HPSG-style grammars, a ‘sign’ usually stands for the generalized notion of grammatical units such as morpheme, word, phrase, etc.
[4] Researchers have looked at the incorporation of morphology of other natural languages in the HPSG framework (e.g. Type-based Derivation Morphology by Riehemann 1998). Arguments for the inclusion of morphological features in the definition of sign will be presented in detail in Chapter III
[5] Note that ‘phrase structure’ in terms like Phrase Structure Grammar (PSG) or Phrase Structure rules (PS rules) does not necessarily refer to structures of (syntactic) phrases. It stands for surface-based constituency structure, in contrast to, say, dependency structure in Dependency Grammar. In CPSG95, some productive morphological structures are also captured by PS rules.
[6] Note that in this dissertation, the term expect is used as a more generalized notion than the terms subcat-for (subcategorize for) and mod (modify). ‘Expect’ is intended to be applied to morphology as well as to syntax.
[7] There are differences in technical details between the proposed grammar in this dissertation and the implemented version. This is because any implemented version was tested at a given time while this thesis evolved over a long period of time. It is the author’s belief that it best benefits readers (including those who want to follow the CPSG practice) when a version was actually tested and given as was.
[Related]
PhD Thesis: Morpho-syntactic Interface in CPSG (cover page)
PhD Thesis: Chapter I Introduction
PhD Thesis: Chapter II Role of Grammar
PhD Thesis: Chapter III Design of CPSG95
PhD Thesis: Chapter IV Defining the Chinese Word
PhD Thesis: Chapter V Chinese Separable Verbs
PhD Thesis: Chapter VI Morpho-syntactic Interface Involving Derivation
PhD Thesis: Chapter VII Concluding Remarks