学了神经翻译网课,感慨良多。回想一下觉得有些好笑:30多年前好歹也是科班机器翻译出身(社科院语言所研究生院机器翻译专业硕士,1986),大小也可以说是个学“者”。河东河西,现在乖乖成了机器翻译学“员”了。机器翻译翻天覆地的变化是有目共睹的。如果NLP其他方面的变化也达到机器翻译的程度,那才真叫不废江河万古流。
机器翻译课讲义编得真心不错。这一段讲解有点意思:
3. Trained model
During the training of the Teacher-Forced model, you provided the French sentences to the decoder as inputs. What are the decoder inputs when performing a new translation? You cannot provide the translation as an input because that's what you want the model to generate.
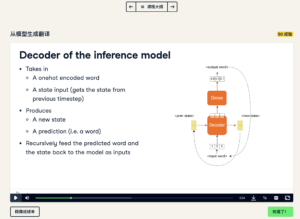
4. Decoder of the inference model
You can solve this by building a recursive decoder which generates predictions for a single time step. First, it takes in some onehot encoded input word and some previous state as the initial state. The GRU layer then produces an output and a new state. Then, this GRU output goes through a Dense layer and produces an output word. In the next time step, the output and the new GRU state from the previous step become inputs to the decoder.
就是说在训练神经翻译模型的时候,源语与目标语都在,都作为 decoder 的 inputs 来帮助模型训练。但是到了应用模型来翻译的时候,目标语作为 input 的条件不在了,那么怎么来保证目标语的影响呢?
讲义中所谓 recursive decoder 就是把目标语的语言模型带入翻译过程。这时候与训练的时候有所不同,不再是具体的目标语的句子来制约,而是用目标语预测下一词的语言模型来介入。这就是为什么神经翻译可以通顺地道的主要原因。因为有了目标语语言模型的引导。
神经翻译常常通顺有余,精准不足。这其实是一对矛盾的反映,本质上是因为 decoder 解码的时候,有两股力量在影响它,一个是源语encoder 编码的输入(上下文的 vectors),另一个是目标语语言模型(next word prediction)的输入,这两个因素一个管精准,一个管通顺,协调起来难免出现偏差或偏向。
尝试把上述讲义自动翻译(谷歌MT)后编辑说明一下:
培训模型在“教师强制”模型的培训过程中,提供给译码器的法语句子作为输入。当执行新的翻译时,解码器的输入是什么?您不能将翻译作为输入来提供,因为这是您希望模型生成的结果。推理模型可以通过构建一个递归解码器来解决这个问题,该递归解码器可以生成针对 “单个时间步长“(即:词) 的预测。首先,它接受一个热编码的输入词(这是指的源语输入文句的词)和一些以前的状态(这是指该词的上文隐藏层的内部表示)作为初始状态。接着,GRU 神经层生成一个输出(指的是下一词的向量表示)和一个新状态。然后,这个 GRU 输出通过全连接稠密层产生一个输出词(这是目标语下一词)。在下一个时间步长中,前一步骤的输出(目标语的词)和新的 GRU 状态成为解码器的输入。
目标语的语言模型是生成模型,生成模型本性就是发散的,可能步步走偏。制约它不走(太)偏的约束来自于根据源语文句编码的上下文状态。这里面还有个魔鬼细节,那就是原文句子的启动是反向的,reverse=True,就是说,原文句子的输入做了逆序操作:
sos we love cats eos --> eos cats love we sos
这样一来,当 sos(句首标志)作为解码器启动的初始单元的时候,伴随它的前文(上下文中的上文部分)不再是空(没有逆序的原句,前文是空的),而是整个句子的浓缩状态来支持它。这就说明了为什么一个 sos 的启动操作,可以依据前文生成下一个词,与 we 对应的 nous,后面就是“链式反应”了,直到生成句末标志 eos,完成一个句子的翻译。在这个递归的链式反应的每一步,每生成一个词,“前文” 就少了一个词,前文的状态因此也在步步更新作为下一步的输入,而所生成的目标语词也作为下一步的输入带入了目标语的生成模型,二者的相互作用造成了精准和通顺的妥协和平衡。目前看来,目标语的生成模型对于翻译的作用容易大于前文状态的作用,造成错译(张冠李戴、指鹿为马,人间蒸发,鬼影乍现等等问题)。但原则上,应该有办法去做平衡配置,就好比在精准和召回之间做平衡配置一样。
这一段讲义讲得蛮明白:
11. Generating translations Now you can start recursively generating French words. First you define a variable fr_sent to hold the full sentence. Then for fr_len steps in a loop you do the following. First you predict a word using the decoder. Remember that, the inputs to the decoder are, a word from the French vocabulary and the previous state of the decoder. In the fist step, the input will be "sos" and the input state will be the context vector from the encoder. This model then outputs a word, as a probability distribution and a new state. The new state will be recursively assigned to de_s_t. This means, at every time step, the previous decoder state will become an input to the model. Then in the next step you get the actual word string using probs2word() function. probs2word() is a function that accepts a probability distribution and a tokenizer and outputs the corresponding French word. After that, you convert that word to an onehot encoded sequence using the word2onehot() function. This is assigned back to de_seq which becomes an input to the model in the next step. And you keep iterating this process until the output word is "eos" or, until the end of the for loop.
这是最后的实际译文的(词循环)生成过程。利用浏览器Chrome自带的谷歌翻译(plu-g-in)如下:
给点说明:
11. 生成翻译 现在您可以开始递归生成法语译文了。首先,您定义一个变量 fr_sent 来保存完整的译文句子。然后对于循环中的 fr_len 步骤,您执行以下操作。首先,您使用解码器预测一个单词。请记住,解码器的输入是法语【即目标语】词汇表中的一个单词和解码器的先前状态【即源语的前文】。在第一步中,输入将是“sos”【句首标志】,输入的状态将是来自编码器的(源语文句的)上下文向量。然后该模型输出一个(目标语)单词【在目标语词汇表中的概率分布】和一个新状态【上下文动态更新】。新状态将递归赋值给 de_s_t。这意味着,在每个(单词生成的)时间步,之前的解码器状态都将成为模型的输入【这是译文精准的源头】。然后在下一步中,您使用 probs2word() 函数(从所预测的词的词汇概率分布)获取实际的单词字符串。probs2word() 是一个接受概率并输出相应法语单词的函数。之后,您使用 word2onehot() 函数将该单词转换为 onehot 编码序列【把生成的词重新编码以便模型下一步使用:这是引入目标语生成模型的关键输入,它是译文地道通顺的保证】。这将被分配回 de_seq,后者将在下一步中成为模型的输入。然后你不断地迭代这个过程,直到输出单词是“eos”【句末标志】,或者直到 for 循环结束。
是不是很有意思?
欣赏一下课件的图示:
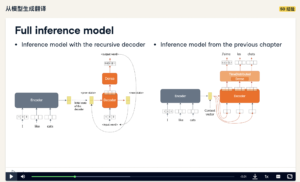
Got It! 1. Wrap-up and the final showdown You've learned a great deal about machine translation and maybe a little bit of French as well. Let's have a look back at what you've learned. 2. What you've done so far First, in chapter 1 you learned what the encoder decoder architecture looks like and how it applies to machine translation. You then played around with a sequential model known as GRU, or, gated recurrent units. In chapter 2 you looked more closely at the encoder decoder architecture and implemented an actual encoder decoder model in Keras. You also learned how to use Dense and TimeDistributed layers in Keras to implement a prediction layer that outputs translation words. 3. What you've done so far In chapter 3, you learned various data preprocessing techniques. You then trained an actual machine translation model and used it to generate translations. Finally in chapter 4 you learned about a training method known as "teacher forcing" which gives even better performance. You trained your own model using teacher forcing and then generated translations. At the end, you learned about word embeddings and how they can be incorporated to the machine translation model. 4. Machine transation models In this course, you implemented three different models for an English to French translation task. Model 1 was the most basic model. The encoder consumed the English words as onehot encoded vectors and produced a context vector. Next the decoder consumed this context vector and produced the correct translation. In model 2, the encoder remained the same. The decoder in this model predicted the next word in the translation, given the previous words. For model 3, we replaced onehot vectors with word vectors. Word vectors are much more powerful than onehot vectors and enables the model to learn semantics of words. For example, word vectors capture that a cat is more similar to a dog than a window. 5. Performance of different models Here you can see the performance of those three models. You can see that the models trained with teacher forcing give the best results. You should note that the model that uses word vectors gets to a higher accuracy much quicker than the model that is not using word vectors. 6. Latest developments and further reading Though you used the accuracy to evaluate model performance, there is a better metric known as BLEU which tries to imitate how a human would assess the translation. Another important thing to know is how out-of-vocabulary words are treated in productionized models. For example, Google cannot simply replace unknown words with a special token. To address this problem these models use a word piece model. A word piece model will identify most frequent sub-words in a corpus. For example, if the model has seen the words "low" and "newer", and has learned the sub-words "low" and "er", the model can represent the unseen word "lower". One of the most important developments in the field of NLP is the Transformer. Transformer is based on the encoder-decoder architecture. However it does not use any sequential models like GRUs. Rather, it uses something known as attention which is more light-weight than a GRU. 7. All the best! I hope this has been a fruitful journey about machine translation and I wish you all the best.
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)