刘群:


鲁东东:飞哥牛b
立委:两条新闻有关联吗?
刘群:都是投资做chatgpt啊
立委:我以为 @李志飞 被王
刘群:@李志飞 自己可以找投资,愿意下场的资金肯定很多。
利人:2.3亿估计是带KPI的。
立委:那天有人评论王总说的钱不是问题,但按照现在透露的融资计划,钱仍然是个问题。他不知道 open ai 就是个烧钱的炉子吗?如果比喻烧煤,都很难想象钱是怎么每时每刻一摞一摞往里面投放燃烧的场景。百元钞票一铲子多少 需要多少铲票子工人 日夜往里面填,这个场面好刺激,
@欧小鹏 智源 AI,烧美元的熔炉,火
欧小鹏: @wei 作画: “AI,烧美元的熔炉,火”已生成完毕,希望您能喜欢~

立委: breaking: 独家丨李志飞将在大模型领域创业,做中国的 OpenAI
说真的,这次与志飞再次硅谷相聚,他对事业的那种热情执着和见识,还是很感染人。与其他随风起舞的人不一样,志飞是AI和NLP身经百战,做过软件也做过硬件产品的过来人。难得保持这一份热情。他还不断反省,说自己的执着还不够。
看好志飞的志向和投入。

Xinhua:读下来,第一是缺钱,第二是缺懂行的人。不知道李志飞投这种烧钱特别厉害的东西,会用哪家公司硬件,有哪些人会来投资,愿意烧掉10亿还不一定有结果。又回到自己造飞机和买飞机的争论。不过也许这次中美脱钩,国家会重视这种烧钱研究,愿意投钱,就像当年龙芯一样,国家持续投资烧钱。李也自己预测,这种大模型,最后胜出的不超过五个,就像操作系统,搜索引擎,造飞机,全球就那么几个公司,垄断市场是必然的
邬霄云:现在的期望也是一定会有结果了吧。
立委:眼前是硬件卡脖子的问题。前不久看到有人计算了,发现真要在 LLM 上赶上美国,目前的脱钩以及会越演越烈的这方面的封锁,会严重影响进程。这就从底座上限制了成长空间。另外,真正能进入 LLM 贵族圈中的 players 极少,现在数得过来,将来也数得过来。但这个生态下的应用可能性具有几乎无限的想象力,其中有些是非常接近现实的应用,是触手可及的。这给下游的创业者提供了很大的空间。
南山:对于任何一个新兴产业,在宏观维度上,最不缺的就是钱。尤其是这种热门赛道。对于某个人/公司,可能会出现缺钱的情况,但对于这个行业是不会缺钱的。人才是第一要素。对于国家层面,这个级别的钱并不大。
立委:宏观上看,只要砸钱,就一定会出活。
这与光刻机这种硬件工艺还不同。光刻机和中国芯这种,砸了钱也在可见的将来出不来。软件毕竟不一样。软件讲到底是拼人才,而人才的流动属性,是挡不住的。
南山:光刻机缺的要素很多,但缺口最大的依然是人才吧。一个靠谱的团队,会有很多投资人愿意砸十亿美元级别的投资。拿出一个过得去的结果,更大的投资也会接着来。核心还是人才、人才。
这是一个难得一见可以清晰看到商业回报的大事情,只要有本事做成,基本没有投资风险。所有风险都在:你搞得出来吗?
技术可行性、商业可行性都比较清晰的大事件,也算是多年难得一见的机会。但判断团队干不干得出来,就难了。
立委:从这个意义上宏观上也没风险了,因为路已经蹚出来了。
最终还是要看生态的建立,和无数下游实体的开花结果,包括领域/场景对齐,以及多模态的渗透。
志飞的粗体字:
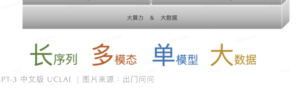
逐个论一下。
长序列,我们以前论过,其实LLM的惊艳表现与能够嵌入长序列息息相关,这是它比以前的模型应对上下文自如得多的保证。
多模态,是正在和将要发生的继续革命。LLM 从 文本辐射到其他模态(音频/语音、视频/图片)以后的大一统基础认知模型,可能会引发二次革命。
单模型,就是志飞所说的路线执着:不要过早想七想八,就是一条路线走到黑,推向极致,直到确认撞南墙或遭遇天花板为止。
最后自然还是一个“大”字:超大数据,一大遮百丑。
这个解读,我觉得@李志飞 是默契和认可的。
鲁为民:根据志飞之前在咱们群里的谈话内容,再看到他的这篇访谈,我觉得他是目前对大模型有真正理解的人,也是中国做大模型靠谱的人。值得期待。
立委:可以想见他忙,顾不上清谈了。
天将降大任于斯人也。
飞哥:感谢群里各位老师的关注,我压力山大,还请大家多给我介绍人才和多参谋参谋。
liangyan:“极客公园:就像让一个人上完大学之后,获得了基础能力,然后可以从事不同的岗位,做不同的事情。而不是在幼儿园的时候,就开始训练它拧螺丝。” 赞。
早就在关注 AGI(通用人工智能)了。
立委:一辈子没有见过这种科技飓风,昏天黑地一连刮了三个月,风势不减。打开任何媒体,满耳朵满眼睛都是ChatGPT,难以形容这种魔力。一定是碰到了人类一个共同的软肋,否则是不会如此排山倒海的。
吕正东:我在bert刚出来接受采访的时候说它是暴力美学 (我喜欢暴力),但是没有 new physics, 但是GPT是有新物理的。
立委:我不喜欢暴力,但很快意识到,这与喜欢不喜欢无关。你要 stay relevant 就必须与暴力相处。所以在 ChatGPT 诞生前,在一年前玩 GPT3 与 DALLE 的时候,就写了这个感受:AIGC 潮流扑面而来,是顺应还是(无谓)抵抗呢?
我看到的超越简单语言层面的新东西是ChatGPT后来表现出来的长对话场景的掌控(篇章链和思维链)以及初步逻辑能力的出现。预见逻辑能力还会进一步加强,但知识的层次和全面是一个难以克服的瓶颈,无论多大都似乎不行。也就是说,在可预见的将来,胡编乱造的固疾是无法医治的。只有用“擦屁股工具”来帮助减少副作用了。
展开说,你说的新物理是?
吕正东:比如说,超出常规语言模型之外的推理能力。
我是喜欢暴力的,确切的说,我想看到数据量堆到一定程度,是不是会有类似“中文房间”之类的现象出现。为此,我们在2013年搞了五百万微博数据,看看检索式对话能不能产生以假乱真的智能,又在2014年用类似的数据训练了第一个生成式对话模型,看看能不能产生智能。现在看来数据量还是太小,只是再大也搞不动了。
立委:搞不动了 哈。
昨天听伯克利一个教授讲 LLM,说自己就是个教授,有几个学生,实在搞不动 LLM。呼吁赞助 呼吁相关研究 因为军备竞赛的结果就是最后只有塔尖上的几个人能在源头上呼风唤雨。
说风势不减,我想到一件事:大家都夸耀 chat 当前的月活数在 IT 历史上前所未有,绝对第一,把老二(抖音)甩出一条街。其实它的真实影响力远大于此,因为那个月活数是受控的,不是放开手发展的,例如 不对大陆地区开放。这也难怪,如果对大陆开放了,月活数轻易翻番甚至上一个量级,它如何受得了。人家把语言搞定,顺带把中文搞定了,这就在技术上把门槛降低到可以让1数亿人进来,哪个模型受得了。这样来看其影响潜力,早已经不是月活数这种传统思维可以定量的了。
中国虽然体制落后,但信息技术上算是草根启蒙度很高的国家,只要放开闸门,会有无数人涌进来的。如果考虑到全世界很多信息技术启蒙度低的地区的潜在用户,随着时间会介入,这个影响力“让人无语”,这是我们真实感受到的,也是最近出现最频繁的说法,可以请chat总结一下这类人类的表述:
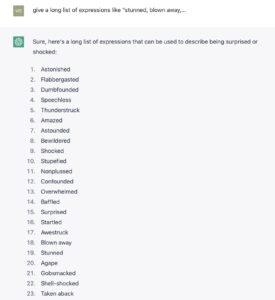
...... Taken aback Bowled over Knocked for a loop Jolted Paralyzed Discombobulated Unnerved Flummoxed Dazed Fazed Addled Bamboozled Perplexed Astounded Surprised Speechless Thunderstruck Appalled Horrified Startled Stupefied Breathless Flustered Rattled Unsettled Overcome Knocked sideways Shaken to the core ......
人类面对怪兽也不过如此吧。

震天动地 一脸懵逼 奇怪异常 出人意料 惊喜不已 爆炸了 眼前一亮 震撼人心 惊险万分 请注意,一些短语在不同的语境中可能会有不同的意义或使用方法。
这一波一波的连续信息轰炸,再好脾气的人也会审美疲劳吧。现在简直没法看,打开抖音,在谈chat;打开微信,各大群也是chat的大合唱或二人转。还有各种讲座、无数的网文和新闻。论渗透度、爆炸力和话题性,感觉是前无古例,后无来者。
NLP与语言文字工作本来是那么的清高和冷门,属于坐冷板凳的本性,没想到还有会被推到这样风口的一天,好像摇滚歌星一样耀眼。这还在一个LLM商业模式根本不清晰,领域壁垒依然耸立,认知智能刚刚划过了冰山一角、错谬随处可见的时期,似乎一切挑战和短板都不影响它的光芒。
一直在想这里面到底是什么在激发全民的想象力。想来想去,只有一个解释可以合理化这种大众的追捧:语言对于人类,比我们想象得更加重要。我们无时无刻不在使用它,无论是与人交流,还是内省,有时候似乎忘却了它的存在和价值。这时候,突然有个非人怪物居然搞定了人类语言,对于我们的冲击和震撼可想而知。
为民:现在ChatGPT 的负面新闻越来越多了。
liangyan:我特别怕,人不当使用 chatGPT ,会把这类 chatbot 污名化。搞臭它的名声。
“跟它玩,但别当真”的态度是对的。
立委:玩和用,是两码事。我是既玩也用,立竿见影。
玩总有人要“玩残”它:就没有玩不残的。老话怎么说的,不怕贼,就怕贼惦记。
liangyan:我正疑惑呢,“玩残”是,谁“玩”,谁“残”了? 比如 “ A 玩残了B。“
立委:用是每天在发生的,我一年多(GPF3)、三个月(chat)来,一直在工作中和生活中用它做实际的事情,对价值和落地可行性有切身体会。后去,会有很多下游实体都在想如何让对接实际需求做得更有章法,流程化。

认真细心,循循善诱,是个教书匠的材料。
liangyan:[Grin][ThumbsUp] 基本对,有点啰嗦。 我只想知道是 A 残废了,还是B 残废了。
立委:

这个以前论过,输出长是他们的一个设计选择,综合来看,他们的选择是非常加分的。虽然啰嗦总是容易“露怯”,更容易被玩残,言多必失,风险较大。选择少言,实际的好处可以“藏拙”,做一字千金状。但其他的 LLM 有采取输出较短的策略,其结果是体验比chat差远了。当然,敢于长篇大论,不怕露怯,需要有底气。chat 经过各种与人类偏好对齐的 强化fine tune,有了这个底气。
Yuting:同意,比起简单给出 B残了 的答案,这种啰嗦的方式让人感觉更可靠
立委:言多必失,现在开始出现越来越多的笑话是必然的,但瑕不掩瑜是他们想给公众树立的形象。
发现,只要有 human filter,chatGPT 不需要做进一步改进,目前就马上可以落地到教育 as is,if(a big IF)
chatGPT 的API服务和生态可以迅速规范化起来
AND
美国不在这方面给中国掐脖子。
目前、马上就可以落地。可行性没有问题。
因为实际上零敲碎打地实际使用下来,已经证明了可以落地产生价值,可望极大提高在线教育的生产效率。不过就是为了 play safe,需要开发一个“坐台”,让一位真人老师坐在后面,点点手指批准还是禁止或简单后编辑,回复在线学生。这个图景十分、十分清晰。考虑到它的“百科全才”的特性,在教育界落地的空间简直难以想象地广大。简直就是一个浅层金矿,只是等待下游领域对齐的 practitioners 去挖,每一铲子(无论语文、地理、历史、物理、化学、还是外语,暂时不要碰数学就好,它目前数学底子潮)都是黄金。
规模化现在就落地教育的问题是:
第一现在需要等待 微软/open AI 的最基本的生态建设和服务到位;
第二,希望美国不会在提供服务(而不是技术)层面去封锁中国,毕竟提升教育是公益,原则上中美具有共同价值观;
第三,中国不要把墙筑高,阻挡技术革命的落地,为了人民福祉应该网开一面。
如果这三点中任一点有问题,就不得不指望国内早日做出自己的 chat 来,看@李志飞 们了。按照志飞的计划,他给自己定的KPI 是六月,估计是指 2024年6月,做出中国的 chat 来。说要做到及格水平,后去会把 60 提高到 80,就应该可以建立完整的生态和促成生态革命了。60 我的理解是达到美国 chat 的 60% (最后目标80%) 水平,但是考虑到还会必然具有一些中国版的差异化优势(中文特有的数据、中国的廉价标注能力来做微调、也许多模态方面与美国处于同一个起跑点可以带来额外的惊喜能力,等等),综合水平可以达到满足生态建设和促进下游应用的程度。这个听上去是靠谱和有可行性的,如果资源和资金可以保证。
设计和管控 chat 的微调,最大限度利用国内的廉价标注潜力,open AI 用几万条去对齐,我们可以用几十万条、甚至百万条标注数据去对齐,只要管理数据质量的老总有能力管理好团队的质量。这其实是中国版 chat 能不能成功的一个关键环节,魔鬼在细节中,微调的设计和实施最能体现细节的打磨。chat 风头碾压谷歌,其实也是主要靠的这个环节的细节打磨。Open AI 与 谷歌背后的 LLMs 水平基本相当。但玉不琢不成器啊。
Google issues urgent warning to anybody using ChatGPT
强调 hallucination(梦呓、胡言乱语)的风险并无新意,但处在他的位置,发表这种是合理的,虽然都是老调。
End of day all it comes to is 在可见的将来使用它,需要有一个 human filter:或者是终端用户自己做 filter,根据他的需求和条件自行判断价值和风险,keep 这种 warning in mind;或者是下游场景/领域的服务商,提供 human/expert filter 来最大化工作效率,给用户提升价值。不仅仅教育落地的可行性清晰可见,在线门诊也一样,前提是有一个大夫坐在后面。
Li Chen:这两天用new bing的一个最大体验是同样的搜索需求下,英文的远远好于中文。看来llm落地的时候,存在语种的影响且还不小。
立委:有人提议把优质英文语料全部自动翻译成中文 来加强。
Li Chen:那要保证翻译质量,不然估计用处也有限。
立委:实际上,同样的利益和效果,应该借助于模型内部的已经部分存在但还有改善空间的跨语言表示来达到,这才符合科学原理。并不真滴需要中文的线性语料在数量上赶上来。理论上,语言的落差可以压缩到最小。
对于语言外的知识,靠增加翻译语料不是从根上解决问题。根子还是里面的语义表示的通用性。而中文语言内的问题,靠自动翻译来增强也不是正道。相信这只是个暂时性问题。中文表现弱于英文,更主要的可能是顾不上来有足够的测试。问题从来不在开发者的雷达上,自然就表现不佳。一个系统的方方面面,鬼知道那个环节的一个小错就会影响数据质量。工程上看,就是能不能把最主要的痛点以最快的方式,出现在开发者和测试团队的雷达上。只要看到,就有可能改进,否则连提升的机会都没有。所以中文的问题,不仅仅是语料不够、质量不好的简单问题。这时候,国内做的 chat 就显出差异化优势了,因为中文肯定会一直在研发和测试的雷达上。
【相关】
chatGPT 网址:https://chat.openai.com/chat(需要注册)