LLM的"大就是好"还能走多远?
——关于Scaling Law的一些思考
老友张俊林《从Deepseek R1看Scaling Law的未来》一文,引起老友热议。
白老师的推荐抽提是:
核心观点: ——无限堆叠不会无限增长(物理世界规律也不支持),只有S型增长,一个S曲线一定会出现边际效益递减。 初期语言能力的涌现,与语料数据中包含的语言知识密度有关。 接下来的增长实际上是第二根S型曲线,更多语料贡献的是常识性知识,常识知识密度不及语言知识密度,所以要更大算力才能涌现。 再接下来是逻辑知识(思维链)的学习。自然语料中逻辑知识密度更低,用算力野蛮淘金,吃力不讨好。所以,用逻辑知识密度更高的合成数据做强化学习,才能让第三个S曲线爬坡。这就顺理成章了。
鲁总评论说:Scaling Law 这个词现在有点滥用。S 曲线(Sigmoid函数刻画的非线性曲线)倒是可以描述技术的生命周期,但它往往是一个接下一个(一个技术遇到瓶颈,往往才有另一个技术的开始)。。。这个在ChatGPT刚出来时我们回顾过。大模型的这几个 "Scaling Laws" 也印证这一点 (Test-Time 和 Post-Training “Scaling Laws" 有点重叠部分):
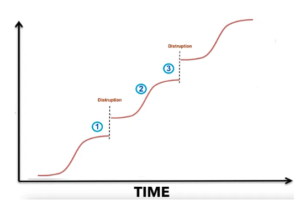
创新就是从一个S曲线到另一个S曲线,well known results。这也是斯坦福大学那位鼓吹新能源、自动驾驶以及再生食品革命等科技乐观主义的教授(叫?)每次演讲必谈的技术革命的adoption曲线。他自称根据这个曲线,他在过去30年对于技术影响社会的许多预见都证明是对的,虽然每一次预见社会都会取笑他。
回到LLM领域的 scaling law 话题。Scaling law本质上是一种经验法则,而经验告诉我们,大多数经验法则都符合S形曲线(或增量的正态分布)。具体到LLM,"大就是好"正是这种法则在遇到平台期或天花板之前的体现。这里的"大"指的是数据规模大、模型参数量大,缺一不可。模型规模不够大,数据再多也无法有效消化——这早已是业界共识。不过OpenAI早期的设计中过分强调模型规模的做法现在看来是一种误导,直到Chinchilla Scaling Law的提出,业界才形成了更合理的共识:数据规模和模型参数量需要保持适当的比例关系。
LLM Scaling的底层逻辑是什么?
首先要明确:LLM不是数据库,其目标不是记忆长尾数据的细节。大模型训练本质上是对大数据内容的压缩,换句话说,压缩的是数据背后的知识体系(包括常识、百科知识等),重点在于揭示大大小小的各种规律性(也就是所谓的泛化能力,generalizations)。
一般直觉会认为,数据规模越大,冗余也越多。无论如何过滤清洗和去重,冗余度随规模增长,似乎意味着可榨取的"油水"会越来越少。那么为什么到了千亿tokens这种以前难以想象的数据规模,大模型依然显得"吃不饱"?为什么从千亿扩展到万亿tokens,scaling law依然有效?
这个现象的关键在于LLM是序列学习(编码)和序列推理(解码)的系统。序列本身是一维的,但序列中蕴含的patterns和规律性却是高维的。举个例子:即使是简单的"猫追老鼠"这样的序列,背后可能涉及物种关系、捕食行为、空间运动等多个维度的知识。这种多维知识表现在序列层面,就会发生天然的组合爆炸。对大数据的"大胃口"正是应对这种组合爆炸的有效策略。只要不是完全的信息冗余,增加的不同序列对模型抽象数据patterns通常都是有帮助的。
然而,人类自然产生的高质量数据是有限的。预训练已经几乎吃尽了现有的高质量自然数据。于是,业界开始探索另外的AI智能增长曲线。
从预训练到推理:两个还是三个S曲线?
张俊林指出:
OpenAI o1推出后,另外两个阶段不再孤单,也各自拥有了姓名,产生了各自的Scaling Law,对应后训练阶段的强化学习Scaling Law(RL Scaling Law)和在线推理阶段的Inference Scaling Law(也叫Test Time Scaling Law)。
这里值得探讨的问题是:到底是三个S曲线,还是两个?推理模型的S曲线与此前的预训练S曲线有多大可比性?
理论上确实可以分为三个阶段: 1. 预训练 2. 后训练(尤其是推理强化学习) 3. 推理阶段
这三个阶段理论上都可能找到资源投入与性能提升之间的正相关S曲线,即scaling laws的某种表现函数。但实际上,在当前部署的应用中,后训练和推理这两个阶段应该共享同一个S曲线,原则上不存在两条独立的增长曲线。
当然,如果用户利用提示词技巧来影响模型的test time,让它更深入的思考,这可能间接影响 CoT (ChainOfThought)的长度或深度。但那是 query 的改变,是 input context 的变化,感觉也不应该算作 test time compute 的独立的 s曲线。
另外,说推理模型这一波潮流是范式转变,开启了新的 RL/Test-time scaling law,总觉得有一点太言之凿凿了。直觉上,推理模型的增长曲线与此前的预训练 scaling law 的增长曲线,大概率没有直接的可比性。
Scaling law 说的 law,实际上我们都知道是所谓经验“法则”。经验需要足够的实践数据积累,才能总结出来。强化学习赋能的推理模型才刚开始,没有足够的经验数据刻画这是怎样的一种增长关系,能持续多久,是不是昙花一现,还是可以持续相当长的时候,等等。
持续时间不够长的 scaling,其实没有多少经验法则的意义。Anthropic CEO Dario 提到 deepseek 的时候说(大意), deepseek 显得这么亮眼其实是赶上了好时机,言下之意是运气的成分大于技术硬核实力和创新(滑稽的是,Anthropic 迄今没有能力推出任何推理模型,虽然R1以来,谷歌和国内都有推理模型的上线)。他说,推理刚刚开始,所以任何人走通了这条路,在这个初期阶段都会有一个大增长。譬如PhD段位的考试题,在没有推理模型的LLM中,可能分数很低,但一旦有了推理模型,有了所谓 test time compute 的 CoT,成绩就会直线上升,给人创造了奇迹的感觉。
现在是推理模型的早期,后去会如何呢?靠增加 test time compute,或不断延长 CoT,还会有多少增长空间?这个问题是现在进行时,貌似没有明确答案。但隐隐觉得,这个持续增长的时间或曲线,远不如预训练那样稳定和持续,进而其作为 scaling law 的说法不一定站得住。
这第二条反映 RL scaling law 的后训练智能增长曲线,不大好与 pretrain scaling law 相提并论,很可能并不是可持续的,也可能很快就遭遇制约因素的强烈反弹(见后“Test Time Compute 的制约”)。
DeepSeek R1的启示:慢思考的真相
以DeepSeek R1为例,用户可以选择"deepthink"模式来启动慢思考的chain-of-thought(CoT)推理,但实际上用户难以通过增加计算时间来提升推理质量。这是为什么呢?
让我们看一个具体例子。假设我们让R1解决一个复杂的数学问题:
- 传统模型可能直接给出答案:"结果是42" - R1会展示详细的推理过程:"让我们一步步思考:1) 首先考虑...... 2) 然后我们可以...... 3) 最后得出结果42"
表面上看,R1的回答展现了"慢思考"(CoT)的特征,但实际上这个推理过程是模型在训练阶段就已经固化的生成模式,而不是在回答问题时动态探索多个可能的推理路径。换句话说,CoT+answer 看似是"慢思考"后的回答,但其实并不改变自回归 ntp(next token prediction)的单向序列生成定式。说白了就是,R1 的 cot+answer 给人慢思考的样子,但生成的本性还是GPT“快思考”范式。在 test time,思考的深度和规模不是动态探索,虽然可以用 beam search 进行内部的隐式多路径选优。
Test Time Compute 的制约
目前业界热议的"test time compute",指的是含有CoT机制的推理模型相比传统的非推理模型需要更多的在线计算资源。以V3/R1为例,处理同样的问题,启用CoT 的R1可能需要V3 n多倍的计算时间。但这种计算量的增加是模型训练后固化的行为模式导致的,而不是可以动态调节的算力投入。test time compute 没有可控的伸缩可能性,也就谈不上 test time scaling law。
预训练与后训练的CoT强化学习的一个很大的不同是:预训练 scaling law 可以长期稳定乃是因为一旦训练完成,不大影响在线响应的时间,生成模式就是简单 query+answer。因此预训练阶段离线训练几个月都是可以忍受的,只要训练出来的大模型能力有大的提升。但推理模型后训练阶段的CoT强化学习不同,它在培养模型在线回应慢思考的习惯,生成模式是 query+cot+answer。推理模型的 cot 拉长,不仅仅是训练的资源和时间的耗费问题,更主要的是它反映在部署推理阶段的 test time compute 的延长,严重拖延了系统的响应时间。而用户在线使用系统的时候,一般来说对于慢思考的计算量和耗费时间是有能够忍耐的上限的。
这就带来了一个关键问题:即使研究表明indefinitely 增加CoT的长度(相应增加在线计算时间)能带来持续的性能提升,符合某种 scaling law 的经验法则,这种增长也会受到推理阶段现实因素的制约。一般用户可能愿意等待5-10秒获得更好的答案,但如果需要等待几分钟乃至几小时,使用体验就会大打折扣,乃至不可接受。
Scaling Law的可持续性之辩
Open AI CEO Sam Altman 和 Anthropic CEO Dario 这些大佬可能会争辩说,对于极其复杂的问题(如证明黎曼猜想、设计下一代航天战机等),即使模型需要一周的计算时间,相比人类团队需要数十年的工作量仍是极大的进步。但这种论述有两个问题:
1. 这类超复杂问题的LLM可行性远未得到验证 2. 极端场景不具有普适性,难以作为可持续的scaling law 的数据点
当然,这并不是否认S曲线作为描述scaling law的有效模型,也不是否定S曲线叠加的合理性。预训练和后训练两个阶段的增长曲线(s1和s2)叠加确实可能反映了资源投入与性能提升的整体关系。但我们需要谨慎看待CoT推理是否开启了一个真正可持续的scaling曲线。
结语:通向AGI的道路还有多远?
如果推理模型的scaling law缺乏可持续性,这就带来了一个更深层的问题:仅依靠这两个scaling laws,我们能否达到通用人工智能(AGI)的理想彼岸?更进一步,让AI平替人类劳动、极大提升生产力的超级人工智能(ASI)的技术理想是否真的可行?
目前的证据表明,预训练scaling law确实展现了相当的持续性,但推理模型的scaling law可能会较快遇到现实约束。这提醒我们,通往AGI/ASI的道路可能需要更多的创新突破,而不仅仅是现有方法的简单外推。在人工智能发展的下一个阶段,我们或许需要寻找全新的增长曲线。
【相关】