The topic may sound obscure, but it goes straight to the heart of large language models.
Before We Dive In: A Quick Refresher on the Basics
What is the rank of a matrix?
You can think of a matrix as a big table made up of vectors. The rank is simply the number of truly independent information channels in that table.
For example:
The two rows are completely different, providing two independent channels → rank = 2.

The second row is just twice the first → effectively only one piece of independent information → rank = 1.
So rank = how many independent channels of information a matrix really carries.
What does “full rank” mean?
If a matrix is , at most it can have N independent channels. Full rank means it actually uses all N, with nothing wasted.
If it doesn’t, say there is a matrix but the rank is only 50, then it’s like having 1000 microphones on the table but only 50 of them are truly working.
What are singular values?
Mathematicians use Singular Value Decomposition (SVD) to break a matrix down into its “main channels.” Each channel has a strength, called a singular value. The number of non-zero singular values equals the rank.
Intuitively:
-
-
Large singular value → that direction carries useful information.
-
Near-zero singular value → that direction is effectively ignored.
-
If most singular values are close to zero, the matrix may look big, but its effective dimensionality is tiny.
Why does this matter for LLM attention?
The attention matrix in Transformers is essentially an information allocation table, deciding which tokens look at which others, and how strongly.
-
-
Theoretically, it is full rank: every token can in principle look across the entire sequence.
-
In practice, experiments show the effective rank is far lower than the sequence length L.
-
This means long contexts are poorly utilized. Even if a model claims to handle 100k tokens, in reality only a few dozen effective dimensions get used. Understanding this gap is crucial to understand the limitations of large models: context window competition, long-range forgetting, and so on.
Back to the Technical Question
“Isn’t the autoregressive attention matrix just lower-triangular? The diagonal entries are all positive, so it must be full rank, right?”
This argument sounds airtight: by definition, the rank is the number of non-zero singular values. If every token at least attends to itself, then diagonals are >0, so the matrix should be full rank.
Mathematically speaking, that’s correct — but it misses the point.
The Mathematical View: Full Rank on Paper
From a linear algebra perspective:
-
-
algebraic rank = the number of non-zero singular values.
-
As long as the diagonal entries are non-zero, the attention matrix is technically full rank.
This is like an exam script where every question has an answer written down — even if most answers are nonsense, nothing is left blank. Or like having 100 microphones, each at least making some sound, so algebraically the rank is 100.
And yes: the causal mask is a lower-triangular matrix ensuring each token only looks backward. By construction, the diagonal is positive, so the matrix is full rank.
The Engineering Reality: Effective Rank Collapse
But what really matters in intelligence engineering is the effective rank: the number of singular values that meaningfully carry information.
Think of it as “not how many microphones are plugged in, but how many actually transmit a clear signal.” If only three are loud and the rest are whispers or noise, the effective rank ≈ 3.
This explains the apparent contradiction:
-
-
Algebraically, attention can be full rank.
-
Empirically, effective rank is tiny — often orders of magnitude smaller than token string length .
-
Studies show sharp singular value decay: over 90% of the energy lies in just a few principal components. As layers deepen, the collapse compounds, leading to “rank collapse.”
The Theoretical Prediction: Rank Bottlenecks
Why does this happen? Linear algebra already gave us the warning.
-
-
The attention weights come from softmax
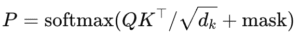
-
The product QKᵀ has rank at most dₖ, the key/query dimension.
-
So no matter how long the context is, the effective rank is bottlenecked by dₖ
-
If L≫dₖ, then even though the window allows 100k tokens, after projection to dₖ, we only have 64 independent directions left.
This is like trying to drive 10k cars through a tunnel with only 6 lanes — the rest are stuck in line.
Rank Collapse in Practice
Beneath the illusion of algebraic full rank, effective rank collapses sharply. The attention matrix geometrically spans , but the usable subspace shrinks to a narrow slit.
Why Not Just the Identity Matrix?
What if attention degenerated into an identity matrix (each token only looks at itself)? Then the rank would indeed be N.
But that’s a pathological case:
-
-
Strict rank = effective rank = N.
-
Yet information flow = 0. No interaction, no learning, no intelligence.
-
Real-world measured attention matrices look nothing like this: instead, they have only a handful of strong singular values, with the rest collapsing to near-zero.
So “rank collapse” refers not to exceptions, but to the normal spectrum of attention in trained models.
The Role of Softmax and Multi-Head Attention
Softmax: Some might think softmax rescues rank. In fact, the opposite: row-wise normalization sharpens the distribution, making singular values even more concentrated. It acts as a driver of collapse, not a cure.
Multi-head attention:
-
-
Each head has rank ≤ dₖ.
-
With h heads, the theoretical upper bound is h*dₖ.
-
This does extend effective rank, forcing heads to diversify.
-
But experiments show many heads learn redundant patterns. The actual gain is far below the upper bound — often only a few heads carry real new information.
The Mirage of Long Contexts
This is why context scaling announcements (128k tokens, 1M tokens) often ring hollow.
Yes, the model theoretically sees all tokens. But with rank collapse, most of that information is compressed into only a handful of directions.
So we see:
-
-
Models forget the beginning of long documents.
-
Fine details get blurred.
-
Only a few salient segments survive, the rest fade like mist.
-
Lessons and Implications
The debate about “full rank vs. collapse” is about two perspectives:
-
-
Mathematical full rank: Yes, attention is full rank algebraically.
-
Engineering effective rank: In practice, the usable degrees of freedom collapse.
-
Understanding this helps us see:
-
-
The illusion of long context: Simply stretching sequence length hits diminishing returns fast.
-
Why architecture innovation matters: Rank regularization, MoE, SSMs, RAG— all are essentially attempts to bypass rank collapse and make information flow more efficiently.
-
At the end of the day, “million-token context” often sells better in marketing slides than it delivers in actual usable intelligence.
Low Rank ≠ Inherently Bad
Low rank does not automatically mean something is bad.
In high-dimensional spaces, many features are already highly correlated. Forcing “full rank” often just means preserving a huge amount of redundancy. It’s like recording the same song 100 times and then claiming, “Look, I have 100 independent audio tracks!” In reality, 95 of them are duplicates or noise.
But isn’t language itself low-rank?
The answer is: yes, to some extent. Natural language is inherently redundant. Its information entropy is far below the total number of tokens, so the effective dimensionality is naturally much smaller than L. In fact, low rank is often a beneficial mechanism for compression and generalization:
-
-
It’s the same principle as Principal Component Analysis (PCA): compressing dozens of dimensions into a few principal directions can better capture the core patterns, remove noise, and improve generalization.
-
Natural language inherently has fewer effective dimensions than its token count. You can’t expect 1000 words in a sentence to provide 1000 independent pieces of information; most of them are repetitions, paraphrases, or modifiers.
-
So the problem is not low rank itself, but collapsing too fast.
-
-
Reasonable low rank: like mixing 100 microphones into 5 stereo channels — the music still sounds rich, and even clearer.
-
Excessive collapse: if only one faint channel remains, then no matter how many singers are on stage, the audience only hears a dull hum.
-
This is why rank collapse has become a real concern in engineering practice. What we need is effective compression, not over-shrinking that destroys information pathways. The real challenge is how to preserve core patterns while still making use of long-range context and more independent directions.
Conclusion and Implications
The debate between “full rank” and “collapse” is about two perspectives overlapping. Once we understand this, we can see:
-
-
The Mirage of Long Contexts: Extending sequence length alone doesn’t solve the bottleneck; performance quickly hits diminishing returns.
-
The Drive for Architectural Innovation: Regularization, Mixture-of-Experts (MoE), SSMs, and retrieval-augmented methods are essentially all ways to bypass rank collapse and let information flow more effectively.
-
Reference
Bhojanapalli, Srinadh, et al. Low-Rank Bottleneck in Multi-Head Attention Models. Proceedings of the 37th International Conference on Machine Learning (ICML), 2020. (https://arxiv.org/abs/2002.07028)
Sanyal, S., Shwartz-Ziv, R., Dimakis, A.G., Sanghavi, S. (2024). When Attention Collapses: How Degenerate Layers in LLMs Enable Smaller, Stronger Models. arXiv:2404.08634 [cs.CL].