Introduction to NLP Architecture
by Dr. Wei Li
(fully automatically translated by Google Translate)
The automatic speech generation of this science blog of mine is attached here, it is amazingly clear and understandable, if you are an NLP student, you can listen to it as a lecture note from a seasoned NLPer (definitely clearer than if I were giving this lecture myself with my strong accent):
To preserve the original translation, nothing is edited below. I will write another blog to post-edit it to make this an "official" NLP architecture introduction to the audiences perused and honored by myself, the original writer. But for time being, it is completely unedited, thanks to the newly launched Google Translate service from Chinese into English at https://translate.google.com/
[Legislature science: natural language system architecture brief]
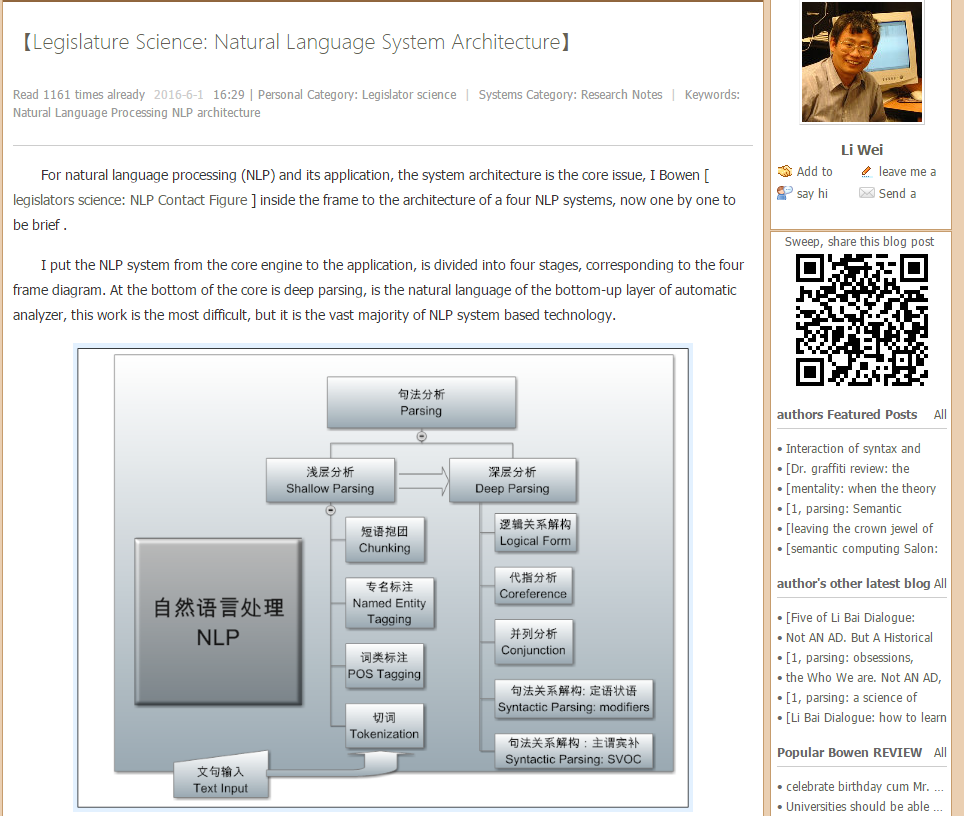
For the natural language processing (NLP) and its application, the system architecture is the core issue, I blog [the legislature of science: NLP contact diagram] which gave four NLP system architecture diagram, now one by one to be a brief .
I put the NLP system from the core engine to the application, is divided into four stages, corresponding to the four frame diagram. At the bottom of the core is deep parsing, is the natural language of the bottom-up layer of automatic analyzer, this work is the most difficult, but it is the vast majority of NLP system based technology.
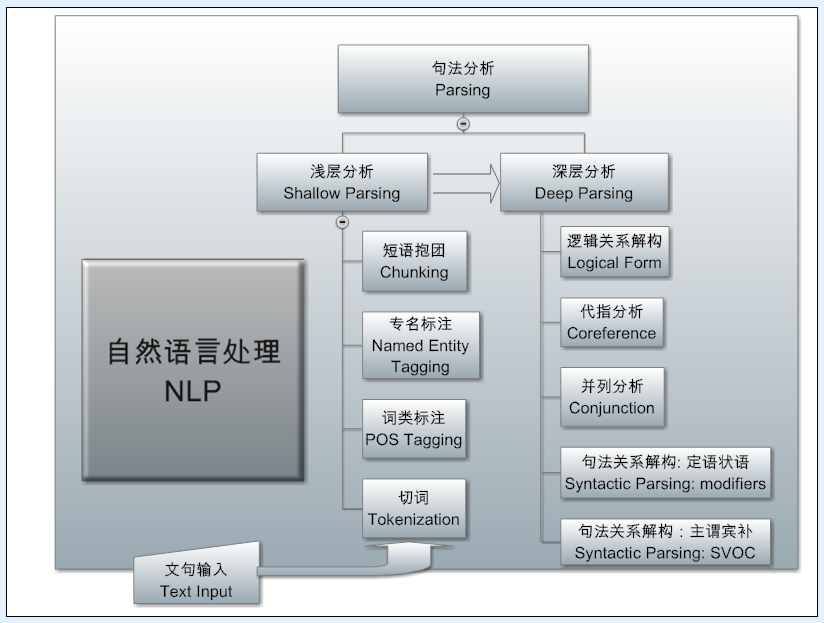
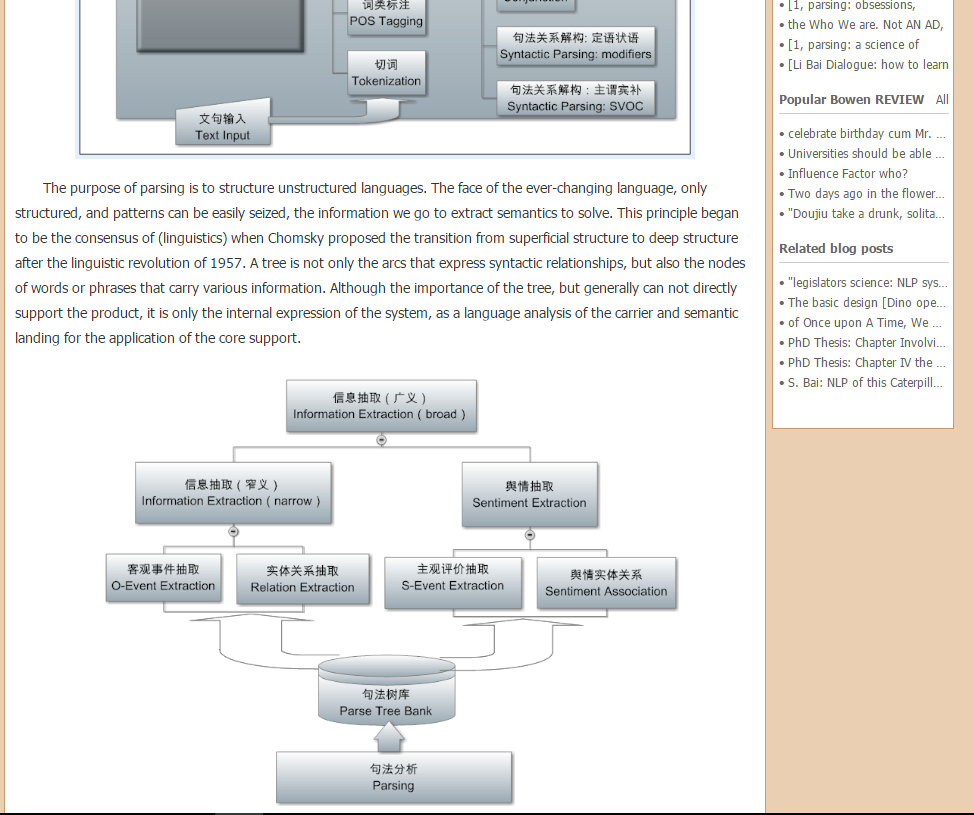
The purpose of parsing is to structure unstructured languages. The face of the ever-changing language, only structured, and patterns can be easily seized, the information we go to extract semantics to solve. This principle began to be the consensus of (linguistics) when Chomsky proposed the transition from superficial structure to deep structure after the linguistic revolution of 1957. A tree is not only the arcs that express syntactic relationships, but also the nodes of words or phrases that carry various information. Although the importance of the tree, but generally can not directly support the product, it is only the internal expression of the system, as a language analysis and understanding of the carrier and semantic landing for the application of the core support.
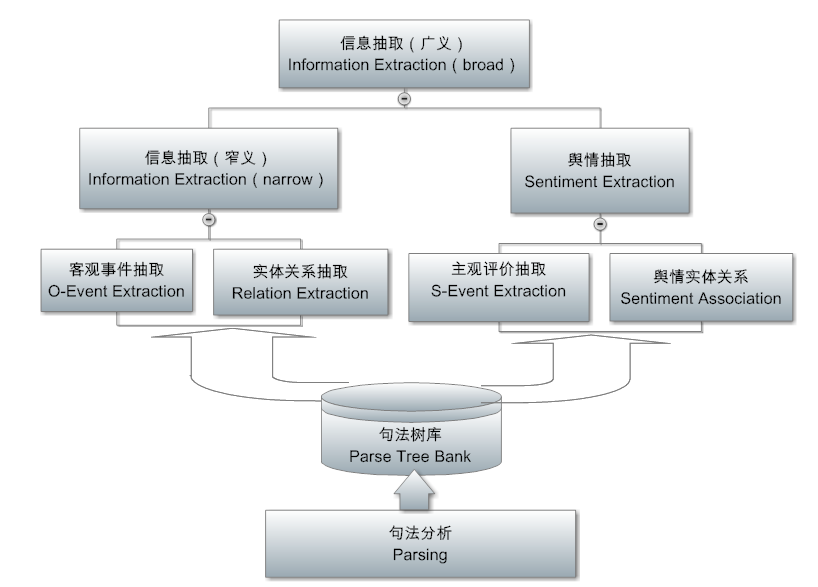
The next layer is the extraction layer (extraction), as shown above. Its input is the tree, the output is filled in the content of the templates, similar to fill in the form: is the information needed for the application, pre-defined a table out, so that the extraction system to fill in the blank, the statement related words or phrases caught out Sent to the table in the pre-defined columns (fields) to go. This layer has gone from the original domain-independent parser into the face-to-face, application-oriented and product-demanding tasks.
It is worth emphasizing that the extraction layer is domain-oriented semantic focus, while the previous analysis layer is domain-independent. Therefore, a good framework is to do a very thorough analysis of logic, in order to reduce the burden of extraction. In the depth analysis of the logical semantic structure to do the extraction, a rule is equivalent to the extraction of thousands of surface rules of language. This creates the conditions for the transfer of the domain.
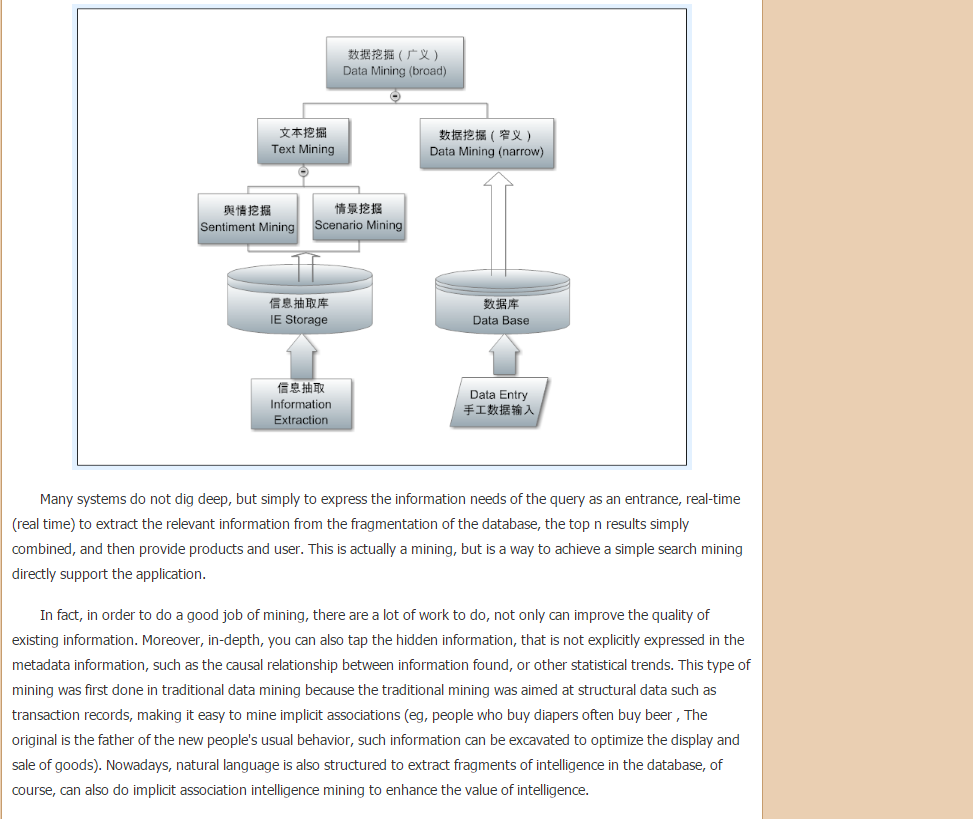
There are two types of extraction, one is the traditional information extraction (IE), the extraction of fact or objective information: the relationship between entities, entities involved in different entities, such as events, can answer who dis what when and where When and where to do what) and the like. This extraction of objective information is the core technology and foundation of the knowledge graph which can not be renewed nowadays. After completion of IE, the next layer of information fusion (IF) can be used to construct the knowledge map. Another type of extraction is about subjective information, public opinion mining is based on this kind of extraction. What I have done over the past five years is this piece of fine line of public opinion to extract (not just praise classification, but also to explore the reasons behind the public opinion to provide the basis for decision-making). This is one of the hardest tasks in NLP, much more difficult than IE in objective information. Extracted information is usually stored in a database. This provides fragmentation information for the underlying excavation layer.
Many people confuse information extraction and text mining, but in fact this is two levels of the task. Extraction is the face of a language tree, from a sentence inside to find the information you want. The mining face is a corpus, or data source as a whole, from the language of the forest inside the excavation of statistical value information. In the information age, the biggest challenge we face is information overload, we have no way to exhaust the information ocean, therefore, must use the computer to dig out the information from the ocean of critical intelligence to meet different applications. Therefore, mining rely on natural statistics, there is no statistics, the information is still out of the chaos of the debris, there is a lot of redundancy, mining can integrate them.
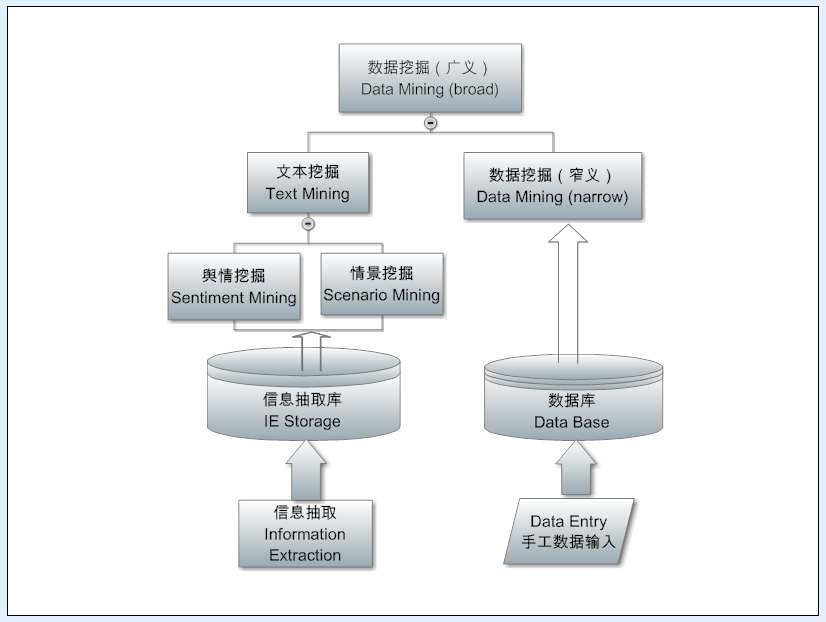
Many systems do not dig deep, but simply to express the information needs of the query as an entrance, real-time (real time) to extract the relevant information from the fragmentation of the database, the top n results simply combined, and then provide products and user. This is actually a mining, but is a way to achieve a simple search mining directly support the application.
In fact, in order to do a good job of mining, there are a lot of work to do, not only can improve the quality of existing information. Moreover, in-depth, you can also tap the hidden information, that is not explicitly expressed in the metadata information, such as the causal relationship between information found, or other statistical trends. This type of mining was first done in traditional data mining because the traditional mining was aimed at structural data such as transaction records, making it easy to mine implicit associations (eg, people who buy diapers often buy beer , The original is the father of the new people's usual behavior, such information can be excavated to optimize the display and sale of goods). Nowadays, natural language is also structured to extract fragments of intelligence in the database, of course, can also do implicit association intelligence mining to enhance the value of intelligence.
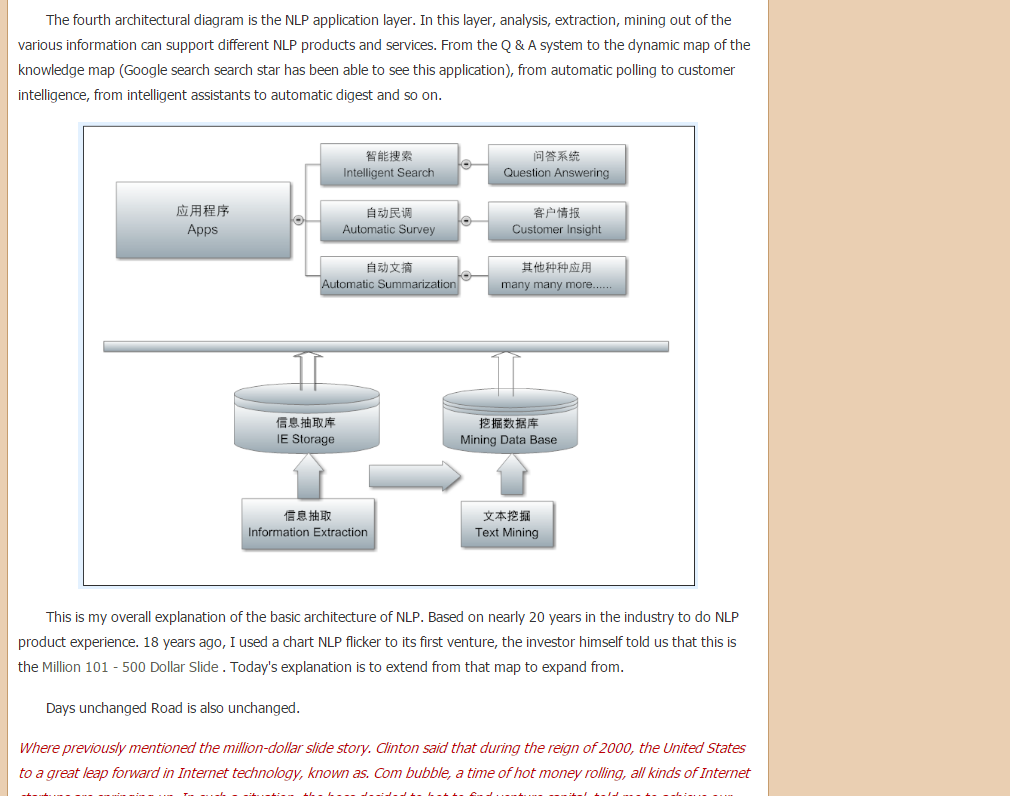
The fourth architectural diagram is the NLP application layer. In this layer, analysis, extraction, mining out of the various information can support different NLP products and services. From the Q & A system to the dynamic mapping of the knowledge map (Google search search star has been able to see this application), from automatic polling to customer intelligence, from intelligent assistants to automatic digest and so on.
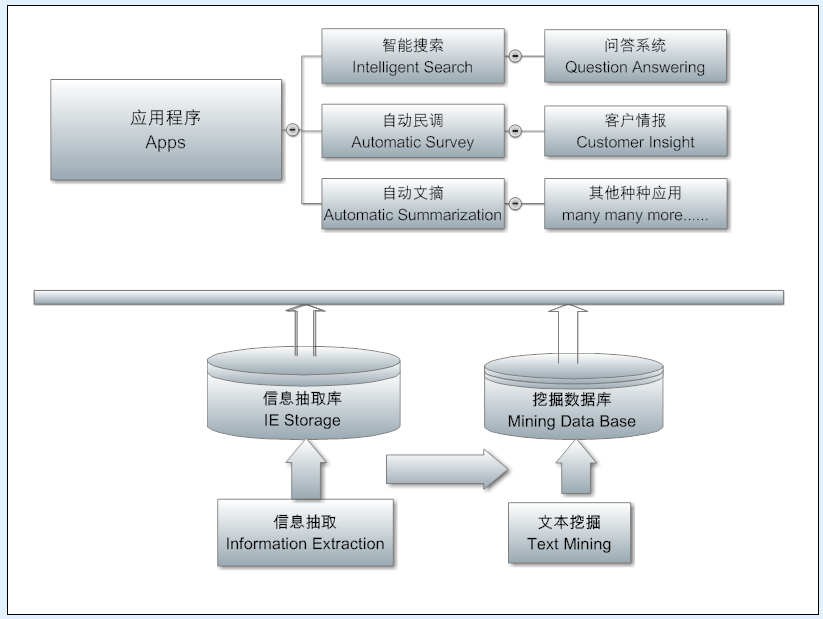
This is my overall understanding of the basic architecture of NLP. Based on nearly 20 years in the industry to do NLP product experience. 18 years ago, I was using a NLP structure diagram to the first venture to flicker, investors themselves told us that this is million dollar slide. Today's explanation is to extend from that map to expand from.
Days unchanged Road is also unchanged.
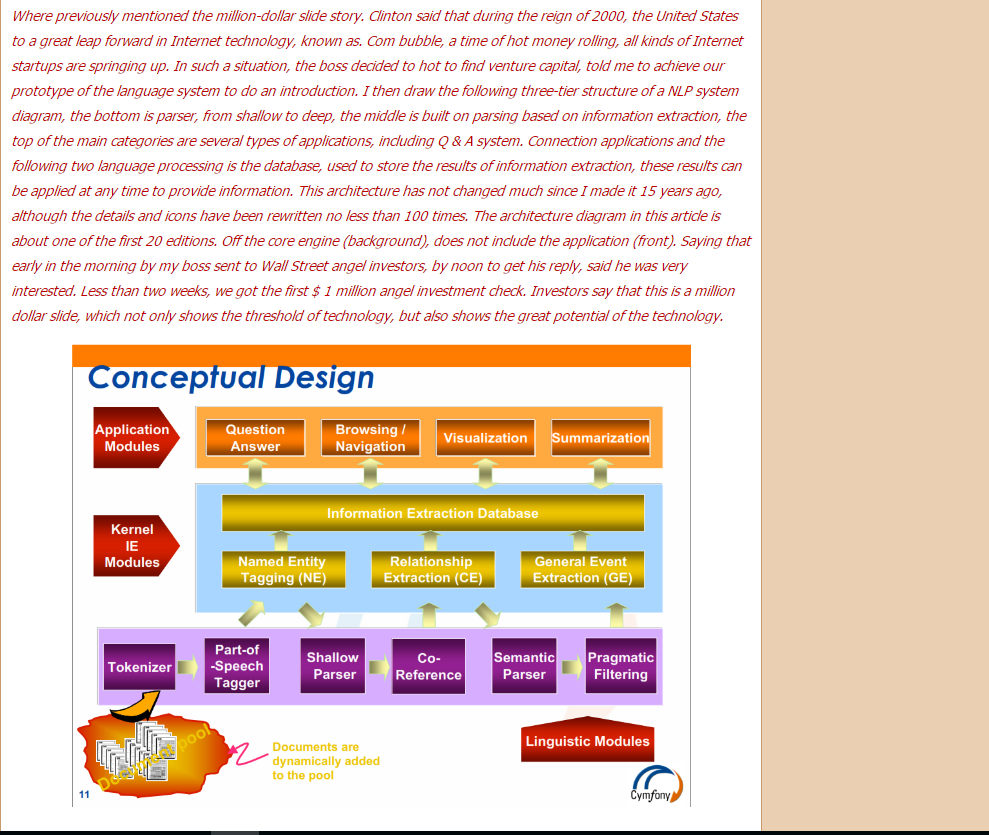
Where previously mentioned the million-dollar slide story. Clinton said that during the reign of 2000, the United States to a great leap forward in Internet technology, known as. Com bubble, a time of hot money rolling, all kinds of Internet startups are sprang up. In such a situation, the boss decided to hot to find venture capital, told me to achieve our prototype of the language system to do an introduction. I then draw the following three-tier structure of a NLP system diagram, the bottom is the parser, from shallow to deep, the middle is built on parsing based on information extraction, the top of the main categories are several types of applications, including Q & A system. Connection applications and the following two language processing is the database, used to store the results of information extraction, these results can be applied at any time to provide information. This architecture has not changed much since I made it 15 years ago, although the details and icons have been rewritten no less than 100 times. The architecture diagram in this article is about one of the first 20 editions. Off the core engine (background), does not include the application (front). Saying that early in the morning by my boss sent to Wall Street angel investors, by noon to get his reply, said he was very interested. Less than two weeks, we got the first $ 1 million angel investment check. Investors say that this is a million dollar slide, which not only shows the threshold of technology, but also shows the great potential of the technology.
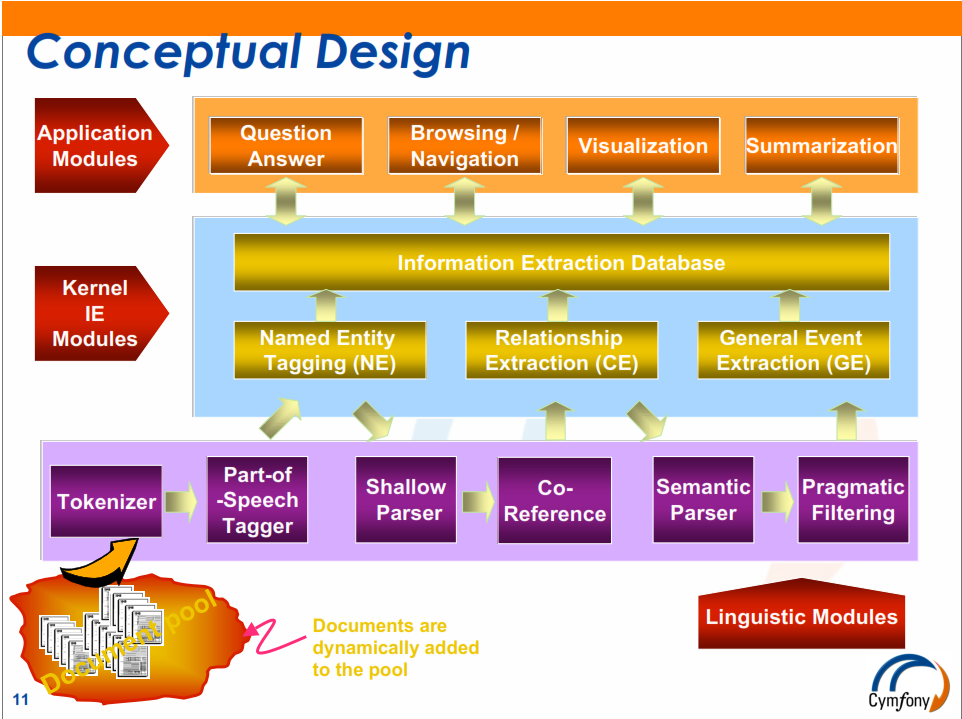
Pre - Knowledge Mapping: The Structure of Information Extraction Engine
【Related】
[Legislature science: NLP contact map (one)]
Pre - Knowledge Mapping: The Architecture of Information Extraction Engine
[Legislature science: natural language parsers is to reveal the mystery of the language LIGO-type detector]
【Essay contest: a dream come true】
"OVERVIEW OF NATURAL LANGUAGE PROCESSING"
"NLP White Paper: Overview of Our NLP Core Engine"
"Zhaohua afternoon pick up" directory
[Top: Legislative Science Network blog NLP blog at a glance (regularly updated version)]
retrieved 10/1/2016 from https://translate.google.com/
translated from http://blog.sciencenet.cn/blog-362400-981742.html