白:“这首歌听过的都说好听”“这首歌听过的都说过瘾”
——什么好听?
——谁过瘾?
李:"过瘾" 这类词对人对物均可:我听这首歌过瘾;这首歌过瘾。
这就好比 -ed/-ing 混合了:exciting/excited。类似于 自动/他动 的零形式转变,“好听” 不同,只能对物。
白:“这首歌过瘾”可以看成,过瘾的正主儿没出现,但是使动的角色已经在那儿了。句法上鸠占鹊巢,本体上主客分明。
李:正主儿不重要,默认是 (令人)过瘾,这个“人”等于没说。
白:本体里“人”是出席的。linked data,首要任务就是不能掉链子。
李:本体是逻辑体系,不要掉链子。语言理解和表示,有所不同。本体等于是个认知背景,理解时候随时调用,也可以不调用。
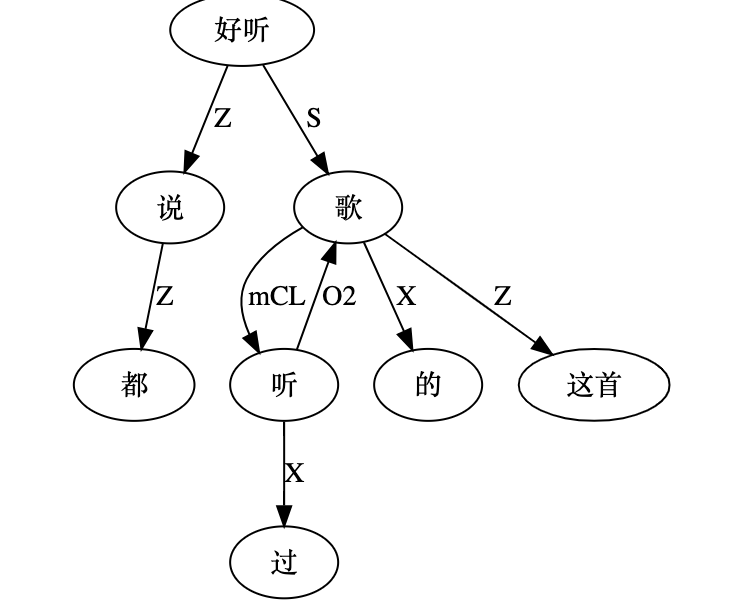
“这首歌听过的都说过瘾 / 听过的都说过瘾 / 听过这首歌的都说过瘾 / 听过的都说这首歌过瘾 / ......”
白:句法上,不相谐并不一票否决,而只是减分。没有更好的选择,减分的选择也会顶上去的。但是在回答问题的时候,低分的选择会提示某种降低自信的折扣。
在c-command位置有多个置换候选,用哪一个自然会精挑细选;如果只有一个,横竖就是他了;如果坑已经被占满,c-command位置上无论有多少候选也是干瞪眼。
李:终于弄妥了。
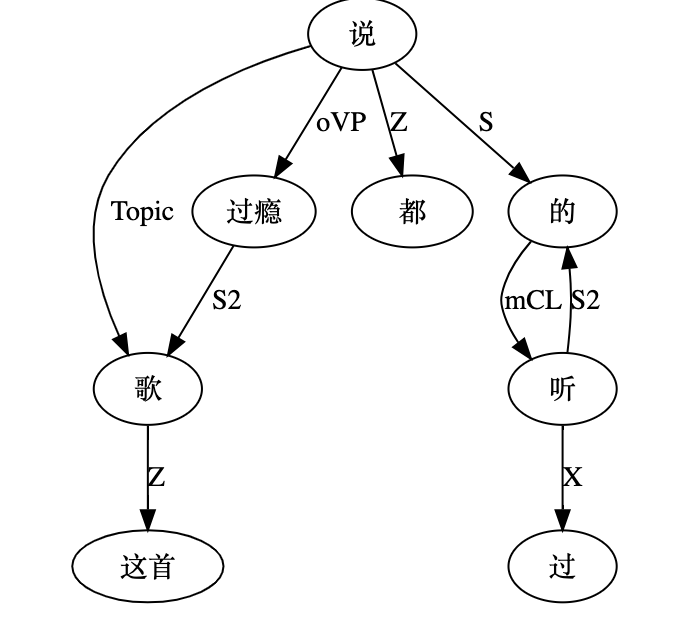
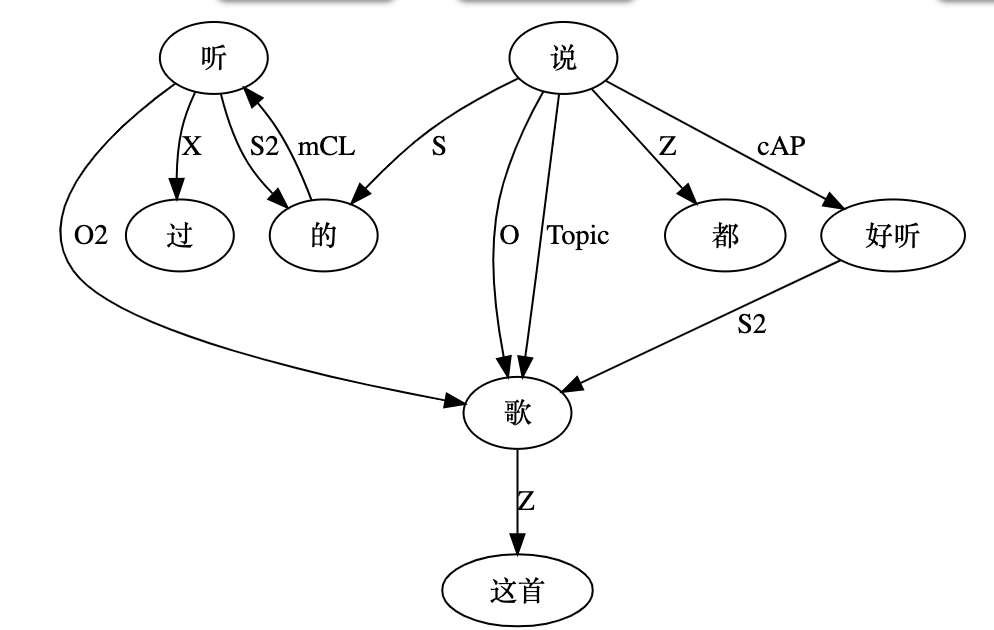
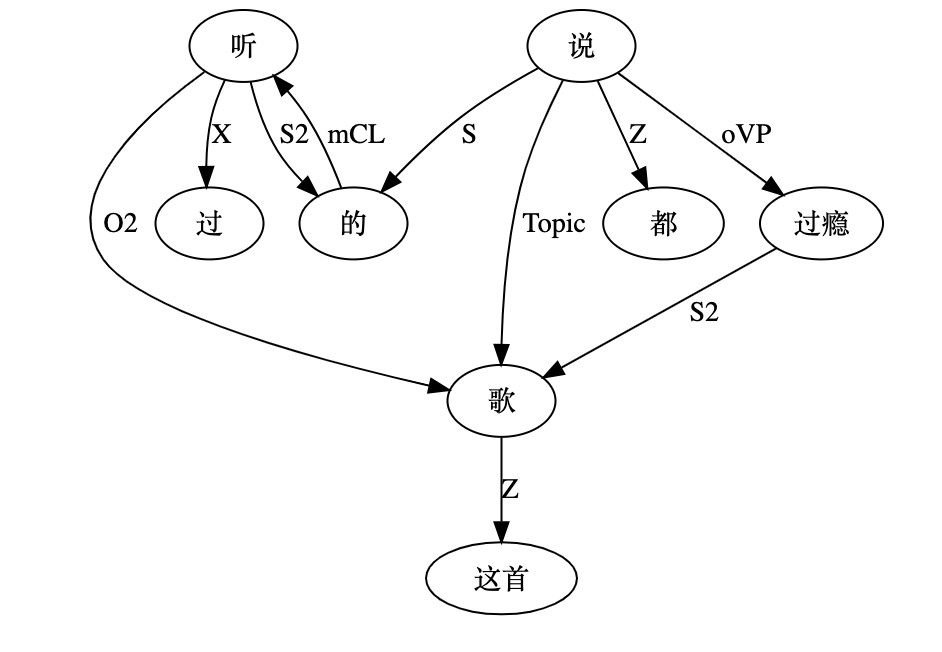
就是这图越来越不像树了,倒是更像那种叫四不像的动物。Topic 可以抹去的,不过感觉留下有益无害。真要逻辑较真的话,“的字结构” 与 “过瘾” 还可以连上 S 或 S2。痕迹都在,本体也支持,但懒得做了。连来连去,也还就是个 “的”字,连个名儿都没有。谁过瘾了?哦,听过的人过瘾了。 感觉没人这么问的。信息不具有情报价值,更像是从常识推导来的。常识常识,就是那种理应熟视无睹的不具备情报价值的知识。
白:推理,张三是听过的人,张三过瘾。
李:三段论是如此。就是不大容易想到啥场景会用上的,怀疑其解析价值。另外就是,语言表达中的确有清晰的情报与边缘的信息的区分,也的确有重要与不重要的区分。所以,单从语言角度看,也有一个什么一定要抓,什么可以放过的问题。所以,单从语言角度看,也有一个什么一定要抓,什么可以放过的问题。从情报性角度看,其实是不应该让常识过多介入的。常识之所以为常识,就是它不具备情报性。如果语言表达方面有意无意的漏洞或含糊之处都被常识“脑补”了,信息单元的情报性就被抹平了,主次容易混淆。
白:脑补的东西,一定有单独的标记。怎么可能允许一锅煮。“营业额超过了联想”也是需要脑补的。
李:人的表达和理解,都有很大的偷懒成分在。这一方面为了节能,节省带宽和脑力,另一方面也可能有个聚焦因素在。解析作为一个为表达通向理解所搭建的桥梁,也许也应该模拟逼近人的表达和理解中的聚焦和节能。所以 一直以来 句法以后做那些逻辑语义的 hidden links,总觉得是锦上添花 适可而止的工作。要做可以做得很深很全,特别是不断引入常识“脑补”,就有很多的 hidden links 可以挖掘。隐隐觉得这不是目标和应该着力的点。
白:不脑补,那张图摆在那里也是摆设。地球人都知道不可比,关键是,轻量级的脑补还是重量级的脑补。
李:这类例子很难说是需要解析的脑补。更大可能是在语用场景,是在领域落地的阶段,根据领域词汇和领域知识去补。这里有个区别:深度解析利用常识脑补,基本是不分领域和场景的,算是 boil the ocean。而到了领域场景,那是下一个阶段了,那里已经有场景聚焦和领域聚焦的考量了。
白:只做解析的立场和做场景的立场是截然不同的。下一阶段,未必是时间的先后,可能只是工序的先后。一个抓总的人需要同时考虑。
知网的设计者,除了翻译是直达场景的,其他很难说有多少场景驱动的东西触达了知网的架构和方法论层面。这也导致二次适配的工作量巨大。时代呼唤一个从方法论层面直接对接场景的新一代知网,or whatever 网
李:撇开MT,NLU 两大应用是:
- 知识挖掘 这更多是后台,离线,大数据。
- 对话,这更多是前台,在线,小数据。
当然,一个完整的交互系统,是两端都需要有的。现在看这两大应用,迄今为止,对于深度解析,需求不大,不明显,也许更多是因为还没找到可以利用的巨大潜力。
白:层次残缺。
需要解析器、本体、领域适配包协同工作,不能各行其是。
李:端到端的系统不去说它了,即便是想努力使用NLU的,在这两大应用中,凭实际经验看,对于 shallow parsing 的需求,远远大于对于深度解析的需求。shallow parsing 主要就是 NE 和一些 XP 抱团,这方面做好了,可以立竿见影。超越 shallow 的部分,用起来感觉不在痛点上。
也许是还没到那个火候。
白:现在的需求不是真正的需求,因为没有把各环节的潜力展现给最终用户。还是没做好。
李:总之,日常的开发实践和场景,不断把我们拉向 shallow 的工作。这些都是非常琐碎的,基本是资源堆积的领域性工作。也没有那么大挑战性,只要有人力 有资源,总是可以大兵团作战,以资源取胜。而具有挑战性 让我们着迷的深度解析,却发现性价比很差。做了白做的时候居多。
全世界都做对话系统,问题于是简化为 intent/slots,说白了,都是既浅层又领域的目标定义。intent 根本就没有语言学定义,不具备任何普遍语义。intent 完全就是根据目标应用所需要的 actions 来定义的语用意义上的“语义”,是典型的端到端的反映,没有可移植性。就是对于输入问题的一个针对具体应用(skill)的classification,1000个skills 有 1000 种不同的定义。这些是当前的“范式”,浅得不能再浅,但证明是可以 scale up 和有效的,前提是有资源去做。
“听过这首歌的都说好听”:
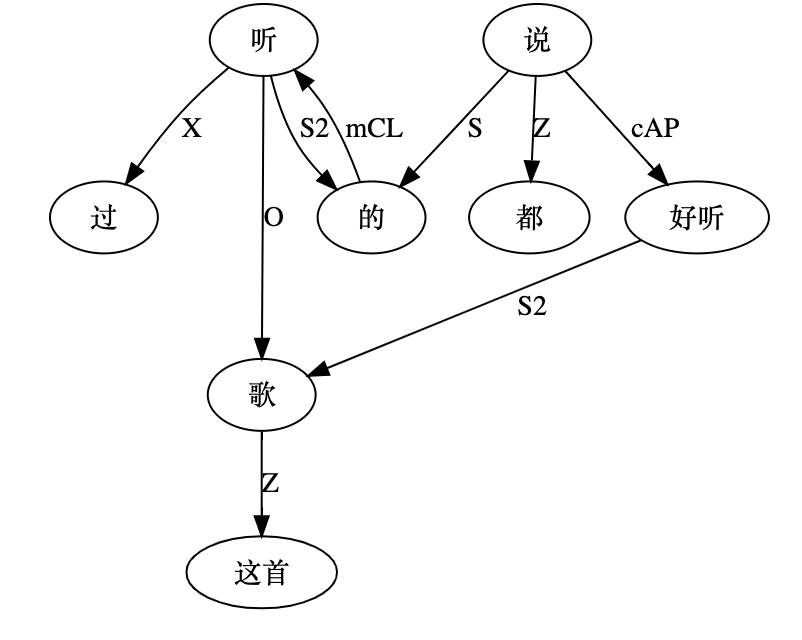
“都说听过的这首歌好听”:
【相关】