刘:
【在中国被二奶搞成少数几个男的开会被嫌弃的车型之一】哪个句法分析器能把这个长定语分析清楚我就服我自己都看了好半天才明白过来
董:
别说分析,这句子看着就已经服了。
梁:
我看了好半天也没明白。
白:
关键是“开会”分词错误会干扰。
董:
“知识图谱实际有国界说”的例子耶!我想在别处,没有那么多二奶的过度,就完全不理解了。所以是有国界的。就算没有了句法上的别扭,没有二奶的国度的人一定也会莫名其妙的。
白:
这句子的坑,一是分词错误的干扰,二是“开”与“车”的远距离强关联被紧密结合成词的“车型”所冲淡。
刘:
【在中国被二奶搞成少数几个男的开会被嫌弃的车型之一】几个陷阱:1.“开会”应该切开成两个词;2.“开“的受事是车,离得太远;3.”几个男的“,几个是指车型,跟男的没有关系;4."被嫌弃的车型”,被嫌弃的是男的,不是车型。
太复杂了。
白:
看见了“车型”,有多少分析器还能同时看见“车”?
还有一个干扰,就是男的被谁嫌弃。“二奶”是先行词,而且是“男的”的相对词,所以产生“男的被二奶嫌弃”的短暂错觉。其实句中的意思是,买了送二奶开简直成了标配,男的自己开反而成了异类,受到其他人的嫌弃,
各种干扰,谁攒出来的,牛啊
“在中国被丈母娘搞成少数几个男的不送房就结不成婚的大城市之一。”
刘:
微博上真实的语言例子
严:
@刘 【在中国被二奶搞成少数几个男的开会被嫌弃的车型之一】,除了你说的四个陷阱,此句在“车型”之前还达到了七块临界。1搞成2少数3几个4男的开5会6被7嫌弃8的
刘:
七块临界我理解是指理解句子的时候记忆负担的一个阈值,应该只是心理学上的经验值吧,不知道有没有理论依据?这个句子如果画依存树我怀疑可能是非投射的
严:
陆丙甫教我的,发现遵循得很好。那些难懂的法律条款常有此通病。
梁:
我体会翻译或写作时,应该尽量把长句子 breakdown 成若干短句子,尽量把头重脚轻的句子变成 balance 的,尽量把一层一层嵌套的从句简单化。 语言表达的简洁清晰,应该是一种追求。数学语言,无非是表达方式之美。文化基因,如果想让它们容易传播出去,一定是简单的和自明的。做科学传播的,也许应该注意这个。
白:
@严 “被”,和“嫌弃”,是可以结合的,被,在省略介宾的情况下直接做状语。所以数目可能没超。
Me:
数目超不超 那都是一个极端的例子 离开 “不是人话” 不远了 不值得花太大力气。
白:
一顺手就灭了也未可知
Me:
遇到此类句子 我通常采这个态度:
1 看看极端例子能有什么功能性启发
可以实现新功能或加强已有功能 但不必一定要灭了它
2 现有的parser 做一遍 结果错了 但错得 “有理” 就好。
所谓有理 是按照系统设计 所走路径 是预期之内。譬如“开会”的强搭配距离近,系统就不给远距离的“开-车(型)”以机会。这类“错误”就是预期中的正常表现,如果不这样“错”,反而要警觉了。总体来说,对这两个“人也觉得很绕”的句子,分析器表现要正常。原则上不需要为这些outliers特地去“改进”:不仅是费功问题,更主要的是要严防弄巧成拙。关键是 预期之外隐藏一种危险,无论结果好坏。其实很多乍看出乎预期的好的表现,其实还是预期内的,可预期性是符号系统的本性吧。狗屎运是玩笑话 多数狗屎运 心里明白不是狗屎 也不是运。稍微思索两分钟 其实还是在预期之内的。符号主义的实质是 系统可解析。不能解析的符号主义行为 表明系统处于失控的边缘。
姜:
请教一下李老师何谓“符号主义”?
Me:
nlp 是 ai 之一种,nlp 所谓规则系统,归类到ai的符号主义,当然 ai 里面有一个重要成分是推理,nlp 系统较少需要推理。另一个重大区别是,在貌似已经没落的 ai 逻辑符号派诸流中,多层nlp规则系统是少有的最接地气和靠谱,在不少nlp关键应用领域(譬如 named entity tagging, shallow parsing, deep parsing, information extraction, sentiment analysis and question answering)可以胜过或匹敌深度学习质量的流派,虽然已经不在学界主流的视野之中。
白:
这里面有这么一个方法论:1、站在后知后觉立场上,当这个谜底揭晓,它是一个在系统所依据的句法理论下合理的解析吗?2、如果是,那么它一定会被暴力搜索出来,没搜出来一定是系统做了剪枝,可以评估剪枝策略是否合理。3、如果不是,可以评估系统所依据的句法理论是否合理。4、如果改进句法理论,系统是否要推倒重来。
好的句法框架可以容纳这种改进,坏的句法框架容纳不下这种改进。我可以肯定地说,CFG容纳不下。
句子有“不确定性过剩”和“不确定性稀缺”两种情况。过剩时好使的剪枝策略,用在稀缺的场景,很可能会栽。为了应对稀缺,过剩时又搞不定了。所以好的剪枝策略应该是随着不确定性的程度而动态自适应的。不确定性稀缺时,并不害怕暴力搜索。
Me:
白老师说的极是。不愧为山中高人。
白:
“张三的分数和李四的分数的差是李四的分数的两倍。”
只有一个正解,其余都是伪歧义。这是不确定性过剩,大胆剪枝。但到了“人话”的边缘,如果还是人话,还是暴力搜索管用。
Me:
为难之处在于百利一弊的策略。因为百利 不能轻易动它 但是那一弊就是那啥脚后跟,一旦出现了 或者容忍它 或者补救它 终归不能动大手术。此句的关键在 “开会” 这个词条 是个伪词。一切传统的词典查询都是最大匹配,这就断了补救的路子。
在应对了离合词的系统,这个 “开-会” 倒是从词典层面被当成两个词,因为有 “开什么会”、 “开个鸟会”、 “会开得一塌糊涂” 等变式。这似乎给解决这个问题留下了可能性。但是,即便是内嵌了离合词处理的系统,也难以抵制把 “开会” 提早处理的诱惑(这就是白老师说的“剪枝”,排除了远距离“开车”的可能性)。这种诱惑是实用主义的,是的的确确的百利,但难免一弊。
白:
真凶在休眠
Me:
英雄所见。对,真要补救 机制上可以是休眠唤醒。“开-会” 作为动宾合成词,从词典得来,可保留。但词典内部可以预留被唤醒拆分的种子,这从休眠唤醒机制上可以实现。
董:
一句破小编写的破句子,让我们这么讨论,太抬举他了。
Me:
哈。而且还不像人话。
借题发挥罢。
白:
还是有启发。比如“车型”这样的复合词怎么承载词素“车”的特征,跟“开”远距离搭配,这样的机制应该不是个案。
“空客380是他这么多年来坐过的最豪华的机型。”
“坐”和“机型”。前两天说的“增长率超过了联想”,是相反方向的脑补。
Me: “开会” 的问题 是早已熟知的最大匹配原则的百利一弊 以及 hidden ambiguity 的休眠唤醒机制 的体现(如果真要解决的话)。
白:
“机型”是“飞机”的属性名,“车型”是“车”的属性名,“增长率”是“指标”的属性名,“指标”是“公司”的属性名。“联想”是“公司”的instance。空客380是“机型”的instance。如果“顺杆儿爬”或者“顺杆儿滑”能够找到相谐的搭配词,也是一种广义的相谐。早有人提过使用图而不是线性序列的方式作为分词的输出。如果输入是词图,WSD结合当前已分析结果和后续待分析词语,作出动态优选,比直接分词算法说了算,会进一步。
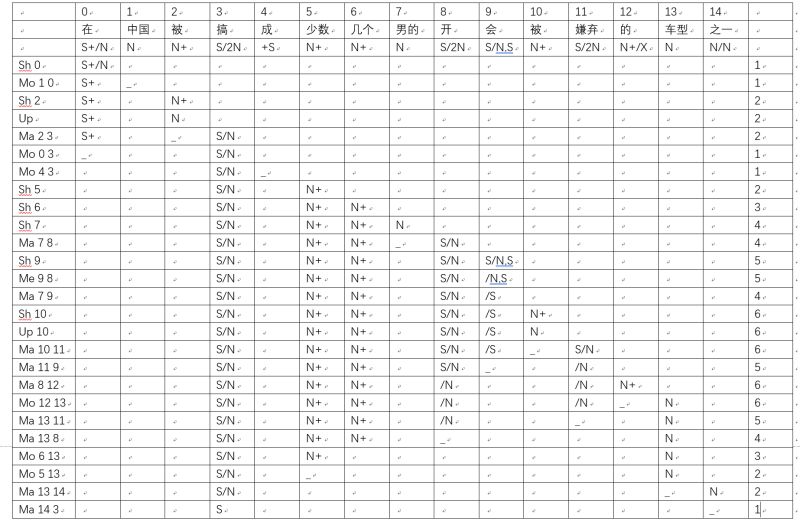
Mo是修饰关系,Ma是填坑关系,Me是合并关系,Up是升格(修饰语提升为被修饰语),Sh是shift(移进,暂不处理)。
这个分析结果还有一点不满意的地方,就是“车型”填了“嫌弃”的坑。按说“男的”填这个坑最理想。
Me:
“坐过” 与 “380” 相谐呀 无需借助“机型”,无论大数据 还是通过本体。再者 这里还有一个 等价结构:o 是 s vt 过的 n。
白:
坐-机型 vs 搭乘-机型,无关380
Me:
380 是我坐过的。
380 是我坐过的玩意儿
这澡是我洗过的最糟的
这澡是我洗过的最糟的一次体验
“坐过” 与 “玩意儿” 很难说 谐不谐 还是要落实到380。
白:
“我坐过的最豪华的机型非空客380莫属。”
Me:
一个道理。有些词 譬如 玩意儿 机型 体验,可以作为类似指代词,它要从抽象落实到具体 然后才可以验证本体关系的 appropriateness。
白:
从结构看不能绕过,而且具体不是必然具体:“这是他坐过的最豪华的机型”
Me:
这句擦边
白:
不能说“这”的相关性比“机型”还高。
Me:
严格说这句有点犯规 除非认为是 有类似 380 的实体被省略
白:
句法没毛病。这就是,不确定性稀缺,不相谐的猴子称大王 犯不上在稀缺的时候进行严格的相谐性检查。
Me:
所谓语义犯规 本来就可以是合乎句法的,不然就没有乔老爷的绿色思想了。
白:
1、句法OK。2、本体里顺杆儿爬可以爬到相谐的节点。3、相谐的节点是真正想要的。
这比绿色思想还有意义得多,“增长率超过了联想”也是同理。
Me:
逻辑上是:这个机型是他坐过的飞机中的属于最豪华的机型。
逻辑啰嗦的时候 语言就偷懒 走捷径,语言表达偷逻辑的懒 案例比比皆是。惰性是人类的基础本性。
白:
前提是稀缺,如果伪歧义密集,再偷懒,就要自讨苦吃了
“男的”和“车型”争夺“嫌弃”仅剩的一个坑的逻辑:“车型”是基于定语从句所修饰的名词的反填;“男的”是基于“会”作为情态动词对填入自己的谓词宾语“嫌弃”的穿透。通常穿透的是逻辑主语(我之前也是这么理解的),但是这个例子里,逻辑主语已经被“被”的无名介宾所捷足先登,实际是穿透到逻辑宾语,所以穿透踩空了。
看来穿透的只是一道墙,不要绑死在墙里面的特定标签上。如果墙里面两个坑,逻辑主语可以优先;如果墙里面只有一个坑,那就逮谁算谁。

这算语义?已经是言外之力的层次了。以言行事。
语言三境界:以言指事、以言行事、以言成事。
郭:
@白【在中国被二奶搞成少数几个男的开会被嫌弃的车型之一】 "我可以肯定地说,CFG容纳不下",可否展开说说? 很想知道那个G在你心目中的样子。也只有知道了那个G,才能判断是不是CFG。
你以前举过一个例子: “张三、李四、王五的年龄分别是25岁、32岁、27岁,出生地分别是武汉、成都、苏州”。
我理解你心目中的G是那有名的(a^n b^n c^n)for any n, which is well known to be outside of CFG。
同样的话,在@wei 那里,我理解就是三型文法有限状态机,因为他有个“事不过三” “超过三个就不是人话”的trick。就算三步太少,那个“七块临界”限制,也把那个G带回正则文法。总之,只要那个n有个上界,就可穷举。
白:
这里面被定语从句修饰的中心语反填回定语从句中的动词所挖之坑的机制,一个成分多个爹,首先它长的样子就不是树。既然不是树,就谈不上CFG了。反填其实造成了“环”,即:名词-动词-的-名词。七块是栈的深度限制。至于放在栈里的东西怎么用,不同的G差别很大。不是说它一被常数界定,就肯定是三型文法了。这套机制的外面,还有语义中间件,把基于subcat的和基于统计的相谐性检验封装起来。面对伪歧义,这个中间件会做出筛选。这个CFG也没有。
Me:
PCFG (probabilistic CFG)是不是就带有了中间件的意味?@白
那玩意儿一度呼声很高。从我的角度看 是大锅烩的一层parsing 还是多层 parsing才是关键。
白:
@wei 有点。
Me:
一层去做cfg 不仅爆炸 没有线性算法 而且很难做深。螺蛳壳里怎么做得出一个像样的道场来。
白:
分析结果长什么样决定了格局。在这个大框架下,数据改变不了格局。
Me:
parsing 的尴尬在 自然语言现象太复杂 千丝万缕 分而治之吧 不知道这几刀怎么切。一锅烩吧 根本就顾不过来周全。
白:
太松,伪歧义就溜进来;太紧,就不robust
Me:
分而治之是显然的上策 只是没有一点经验和功力 往往不会分。我觉得。伪歧义的问题在多层系统中几乎就不是挑战,原因就是 松紧掌控也被分而治之了。每一个可能的剪枝行为可单独去调,数据驱动 假以时间 偏差就会从一个一个局部解决 ,从而获得全局最优。
白:
话说,形容词向左做补语和向右做定语,在你那里谁优先?
比如“做好男人”:
Me:
除了 定中合成词在词典外,词典的下一层是 “一字”补语,再下一层才是定语,现在是这样切的刀。因此 假如 “好男人” 不进词典,目前的分析是 【做好 男人】,但是如果一字以上 就不了。
白:
到处可见标配-例外的逻辑。
补语与时态助词呢?“哭肿了”是“哭肿-了”还是“哭-肿了”?
Me:
无所谓。爱谁谁。
白:
同级?
Me:
我是说对这种不预先特别设计,赶上哪个算哪个。
白:
分层,了总有个落脚之处吧……
Me:
目前是 “哭肿” 在先,因为 汉语有双音趋势:
白:
又不做语音合成
Me:
两个汉字的组合 看成是词典的延伸 处于非常底层
白:
照此说来,“折腾惨了”就该是“折腾-惨了”?
Me:
没问题呀,但遇到小词的时候(譬如“惨-了”的“了”),也不绝对。然而,“哭-肿” chunk 成(open)合成词了,但“折腾”-“惨”则仅仅是补语联系,而不是合成词。
白:
有点以貌取人啊……
Me:
必须滴。这个世界有完全不以貌取人的吗?何况句法乃是关于形式的系统,以貌取人,理所当然。 只是在句法语义的理解过程中,“貌”占多大比重的问题。 句法当然不仅仅追求心灵美,心灵美理应是语义的追求。当然,句法的最终目标还是语义(理解),所以句法语义接口的时候,外表美与心灵美需要一个平衡才好顺利过渡到自然语言的理解。
白:
“东西放忘了地方”,合法吗?经常有人这么说。但是“放忘”似乎没有因二字组合而产生成词的倾向。东西-放-地方,忘-地方。忘了-地方。
Me:
成词的趋向在 只是这个 bigram 的频度还不够高,用的人多了 就成词了 。
白:
这个不是大问题,皆可。吃光、用光,俨然就是词了。动结式动词
Me:
不太一样:
放x忘y
吃x x 光
动结的逻辑宾语常常出现在主语位置 不需要用显式的被动小词 “被”,这是共性。不同的是 ............
白:
“打疼了手”
别人的手疼,“打疼”是紧组合;自己的手疼,“打疼“是松组合?如果打xx疼和打xy疼能决定这个区别的话.
Me:
“打疼了手”,默认是自己的手
打他打疼了手 不是他的手。
伤透了心 是自己的心
伤透了脑筋 也是自己的脑筋
除非“操中南海的心”。把标配给冲了。
白:
这个问题在于手、心、脑筋都是部件,有坑的
郭:
“这里面被定语从句修饰的中心语反填回定语从句中的动词所挖之坑的机制,一个成分多个爹,首先它长的样子就不是树。既然不是树,就谈不上CFG了。”“反填其实造成了“环”,即:名词-动词-的-名词。”
撇开“句法制导的语义分析”,也撇开具体的句法分析过程,就纯句法描述而言,这无非就是: X -: N V 的 N
具体的“相谐”判断,用基于挖坑填坑的一致,或基于特征的合一,或基于统计的搭配,或基于经验的标配,只有分析的颗粒度和精度的差别而已,无关语言表达力。有了 X -: N V 的 N,怎样画内部的依存结构,是个“句法制导的翻译”问题。我们大可以说“在这样这样的坑/特征/统计/搭配/标配下”“V既是N的儿子又是它的老爸”,但这都不影响这个N作为X的代表一致对外。
我想探讨的是,如果把过程性的具体剖析方法从语言表达分离开,这个“描述性的”“纯”语言长什么样子。我是在找类似上面的 (a^n b^n c^n),如果这里的n是个任意值,它就是上下文相关语言,如果n是一个有界的值,它就是一个正则语言。这是一个纯描述性的语言,无关其分析方法,也无关其语义解释。
白:
先说“分别”这件事,也有粗粒度的处理方法,就是使用“列表”。不管长度,只管收拢。收拢对收拢。还有,如果描述指的是大边界。里面的小细节都归功于语义,那我指定一个全集岂不更痛快?功夫全在细节啊。我这里用的不是句法制导的方法,而是词负载结构的方法。一条显性的句法规则都没有。还有,仅就{x^ny^nz^n}这个形式语言实例而言,它的判定可以有线速算法,跟一般二型语言的判定复杂度是完全不在一个量级的。
【相关】
【语义计算:李白对话录系列】