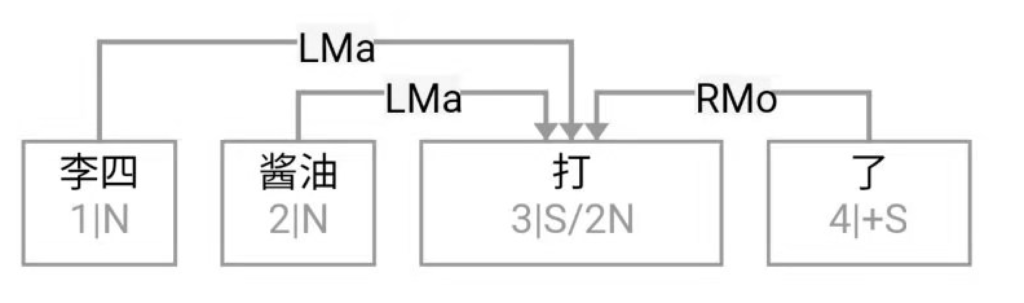
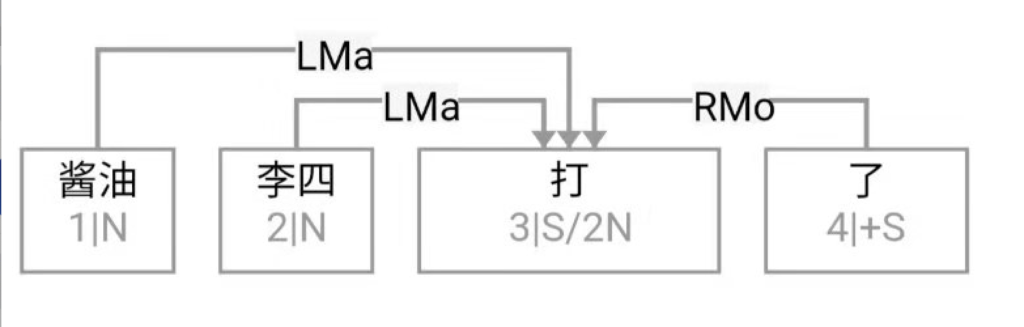
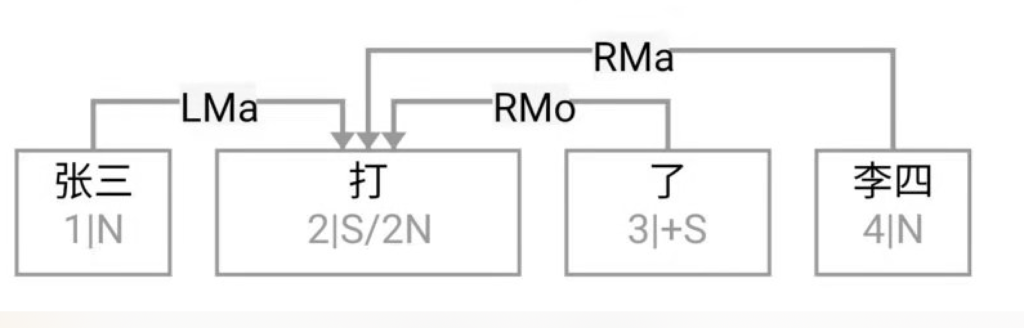
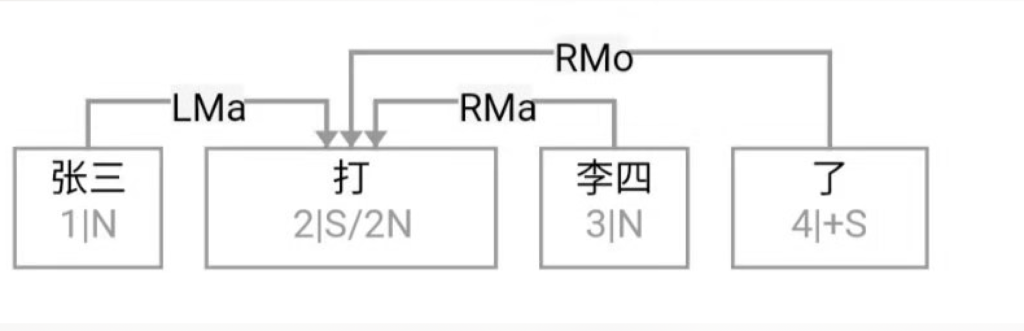
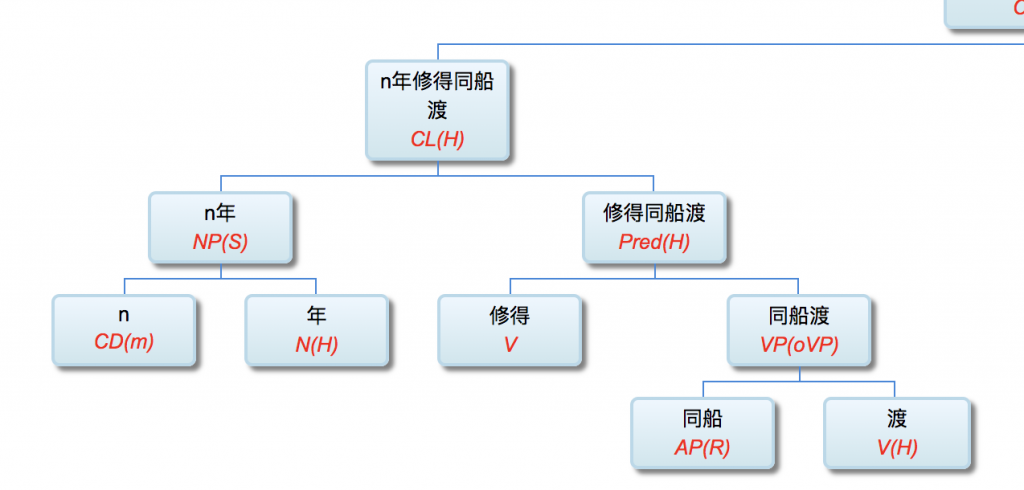
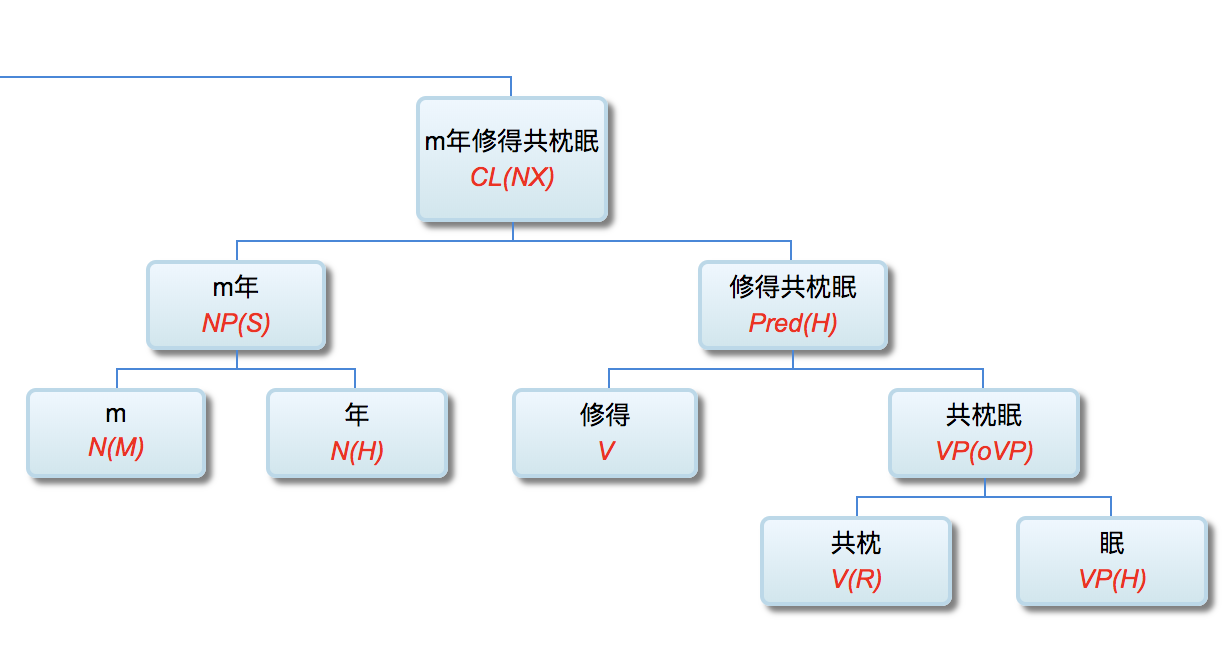
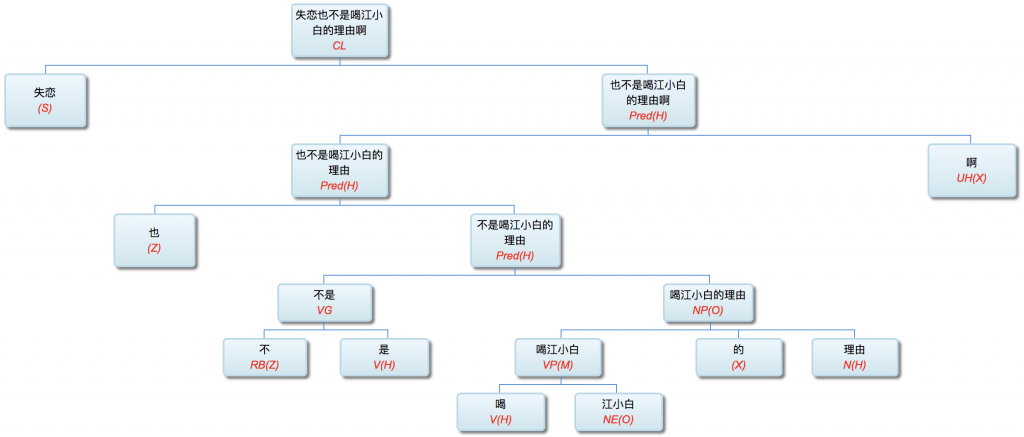
Guo: Professor Li, to ease into the discussion, let us begin with some foundational concepts. What exactly do we mean by natural language? What falls under the scope of the field, and where does it sit within the broader discipline of Artificial Intelligence (AI)?
Li: Natural language refers to the everyday languages we humans speak—English, Russian, Japanese, Chinese, and so on; in other words, human language writ large. It is distinct from computer languages. Because human conversation is rife with ellipsis and ambiguity, processing natural language on a computer poses formidable challenges.
Within AI, natural language is defined both as a problem domain and as the object we wish to manipulate. Natural Language Processing (NLP) is an essential branch of AI, and parsing is its core technology—the crucial gateway to Natural Language Understanding (NLU). Parsing will therefore recur throughout this book.
Computational linguistics is the interdisciplinary field at the intersection of computer science and linguistics. One might say that computational linguistics supplies the scientific foundations, whereas NLP represents the applied layer.
AI is often divided into perceptual intelligence and cognitive intelligence. The former includes image recognition and speech processing. Breakthroughs in big data and deep learning have allowed perceptual intelligence to reach—and in some cases surpass—human‑expert performance. Cognitive intelligence, whose core is natural language understanding, is widely regarded as the crown jewel of AI. Bridging the gap from perception to cognition is the greatest challenge—and opportunity—facing the field today.
The rationalist tradition formalises expert knowledge using symbolic logic to simulate human intellectual tasks. In NLP, the classical counterpart to machine‑learning models comprises linguist‑crafted grammar rules, collectively called a computational grammar. A system built atop such grammars is known as a rule‑based system. The grammar school decomposes linguistic phenomena with surgical precision, aiming at a deep structural analysis. Rule‑based parsing is transparent and interpretable—much like the diagramming exercises once taught in a language school.

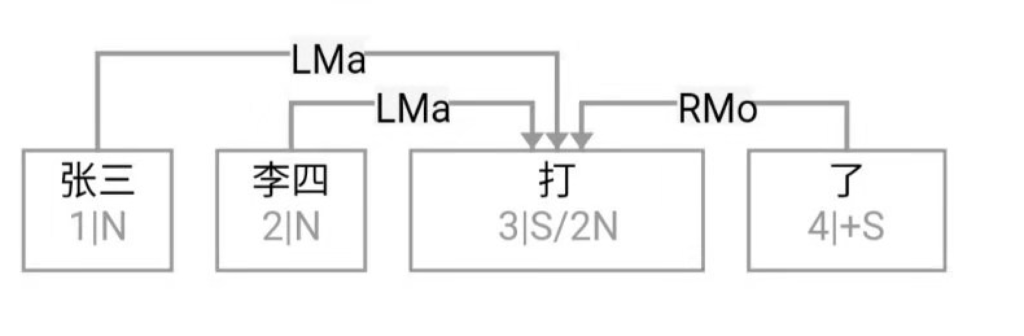
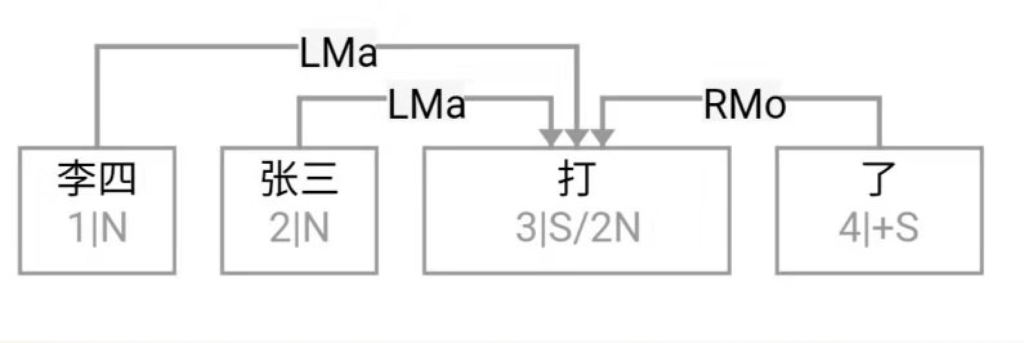
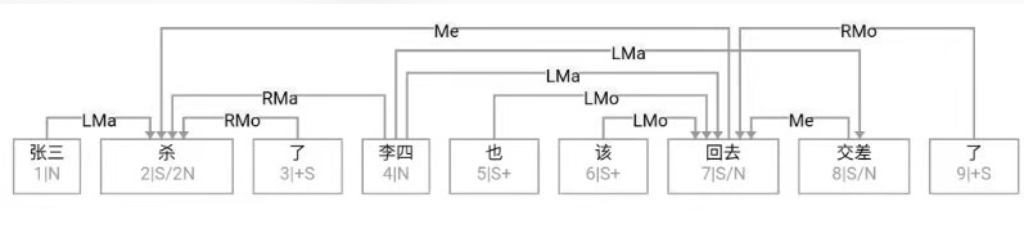
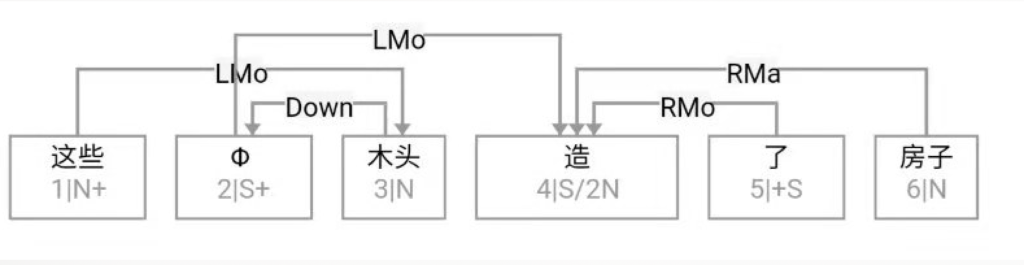
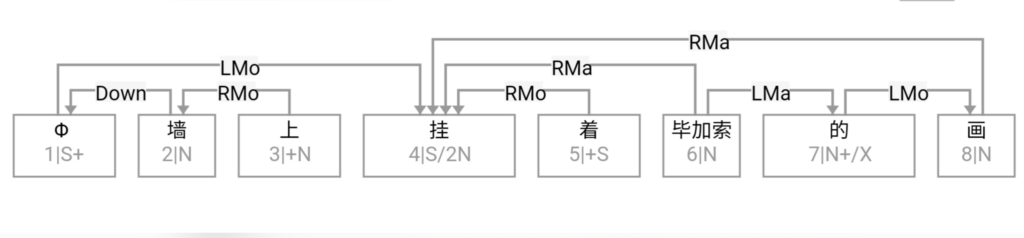
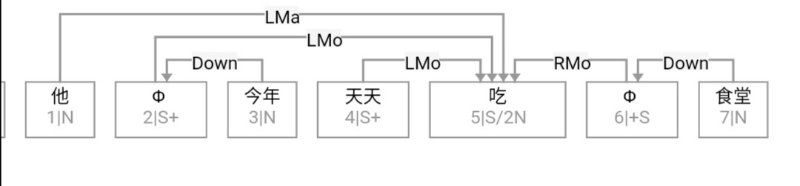
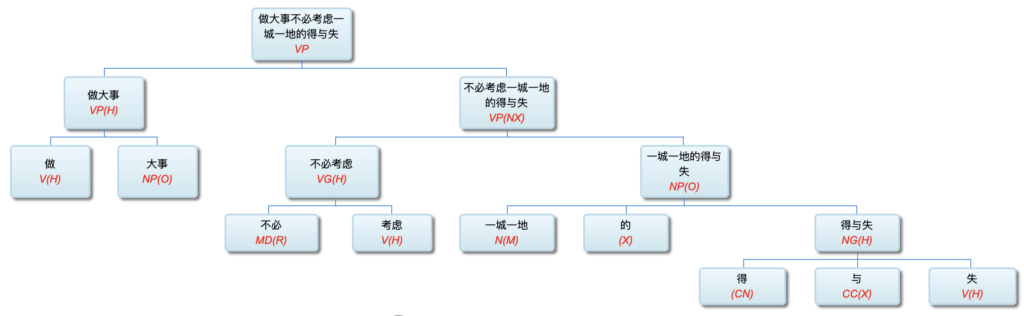
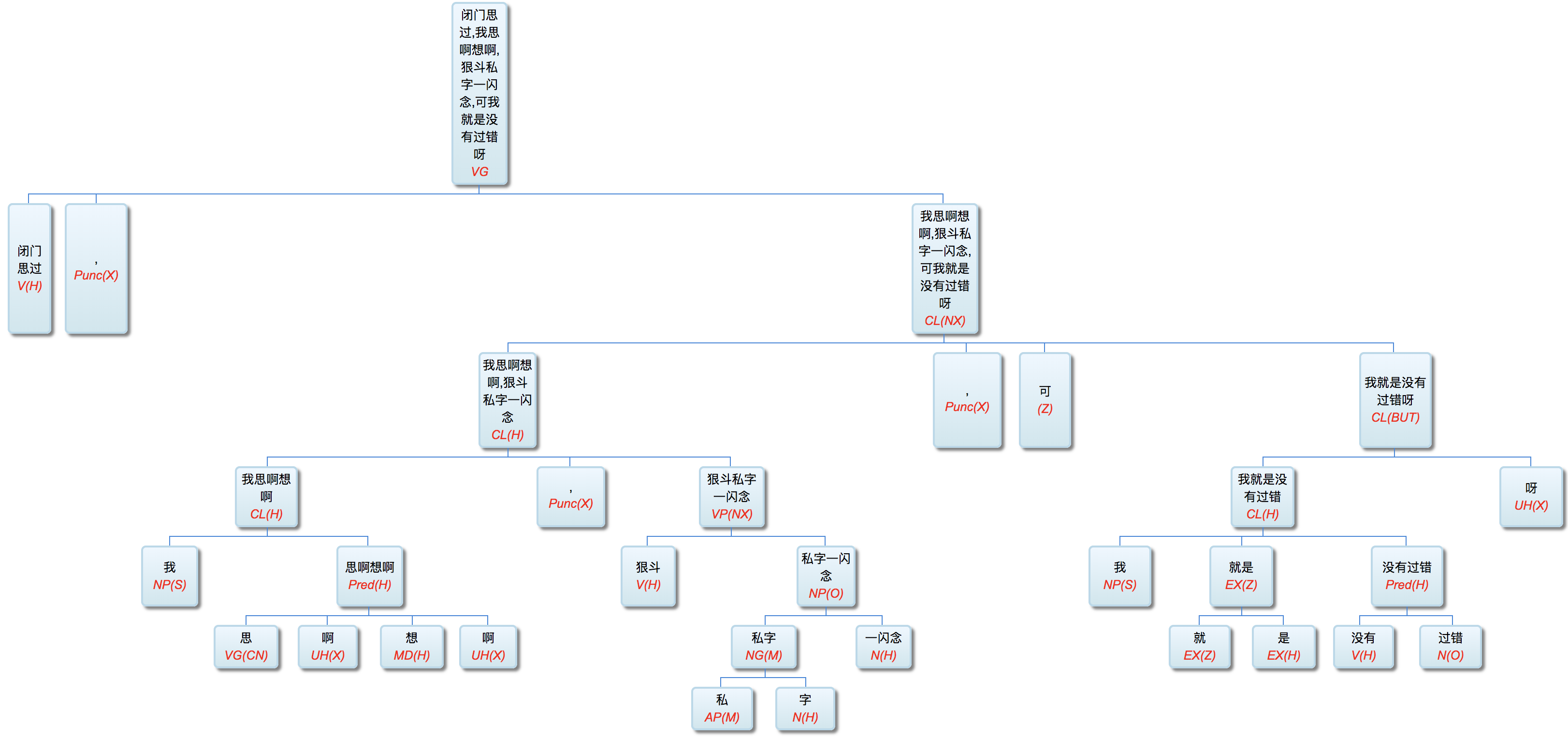
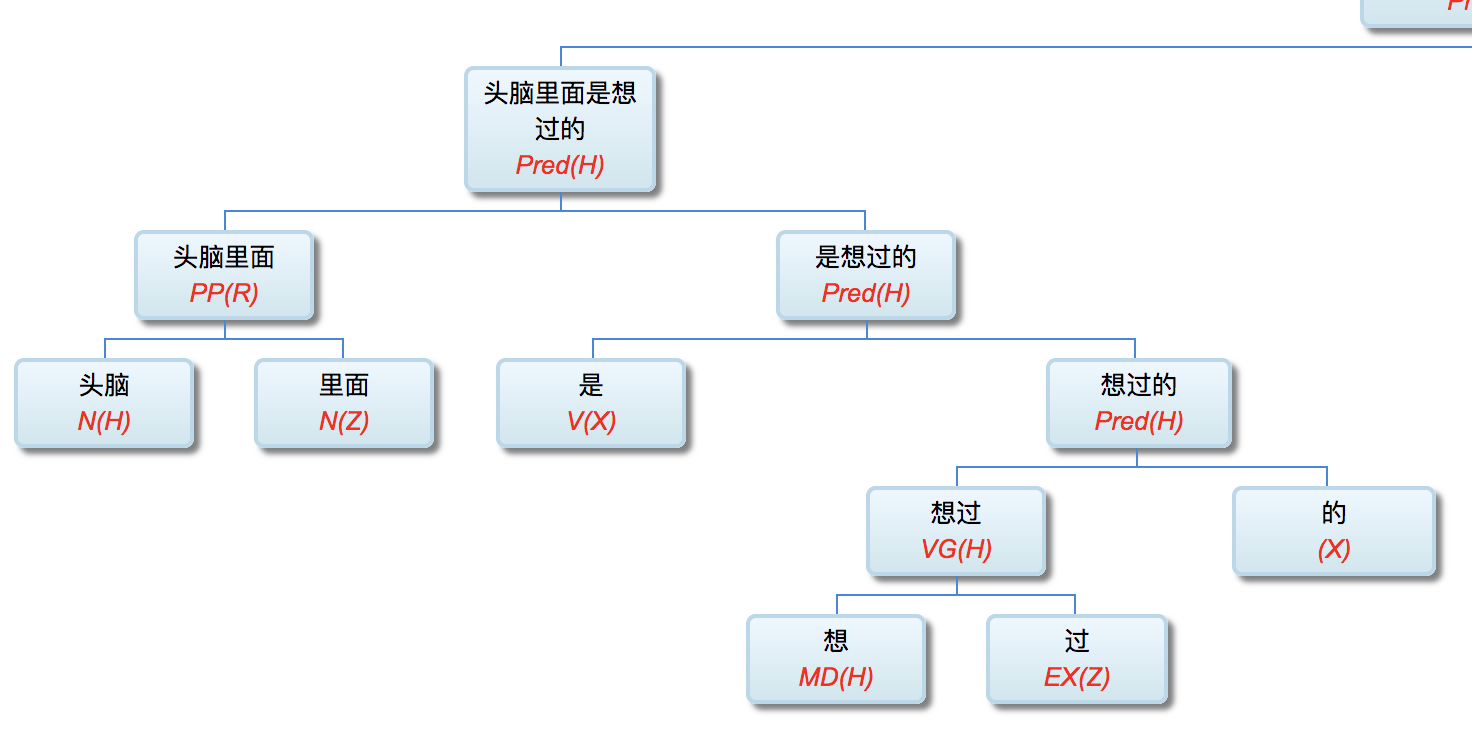
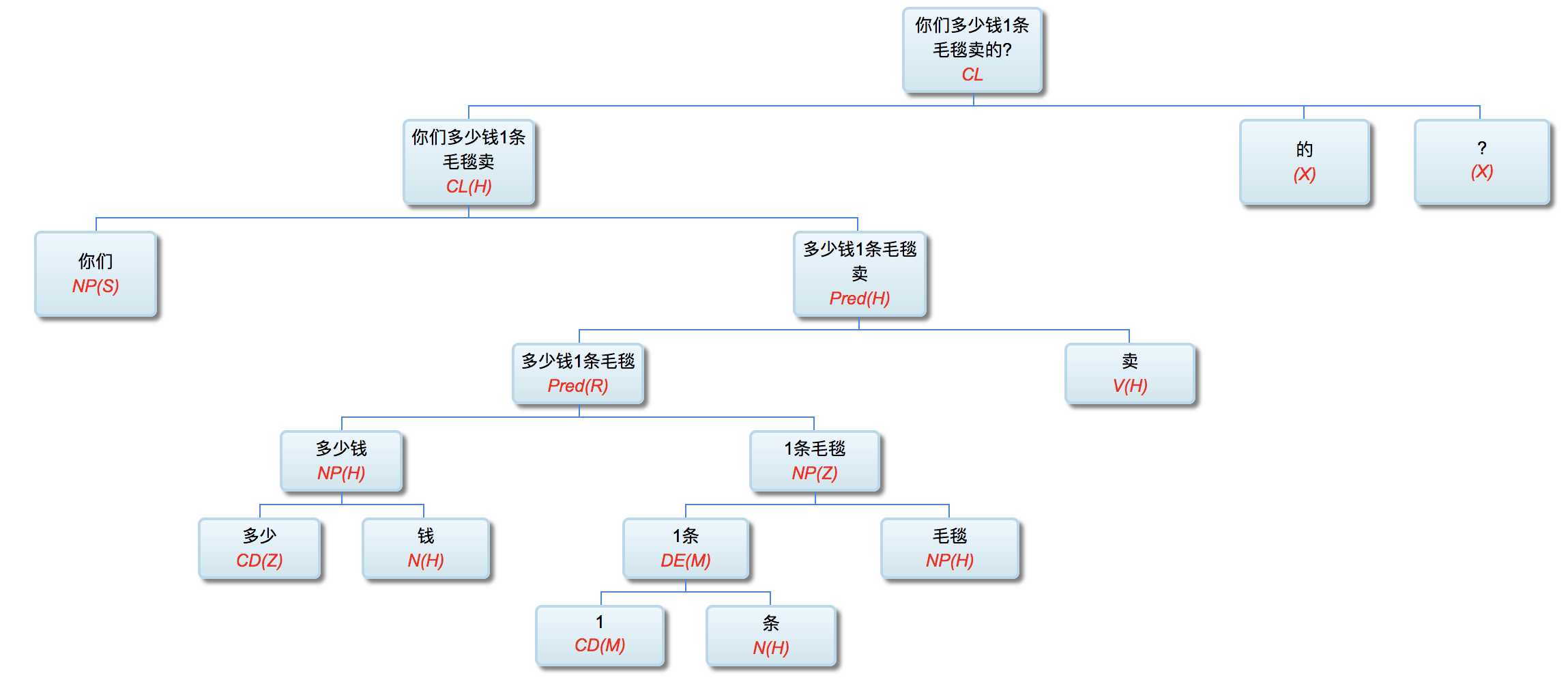
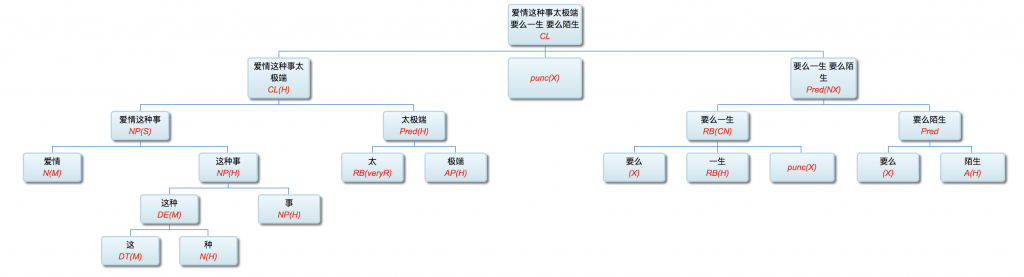
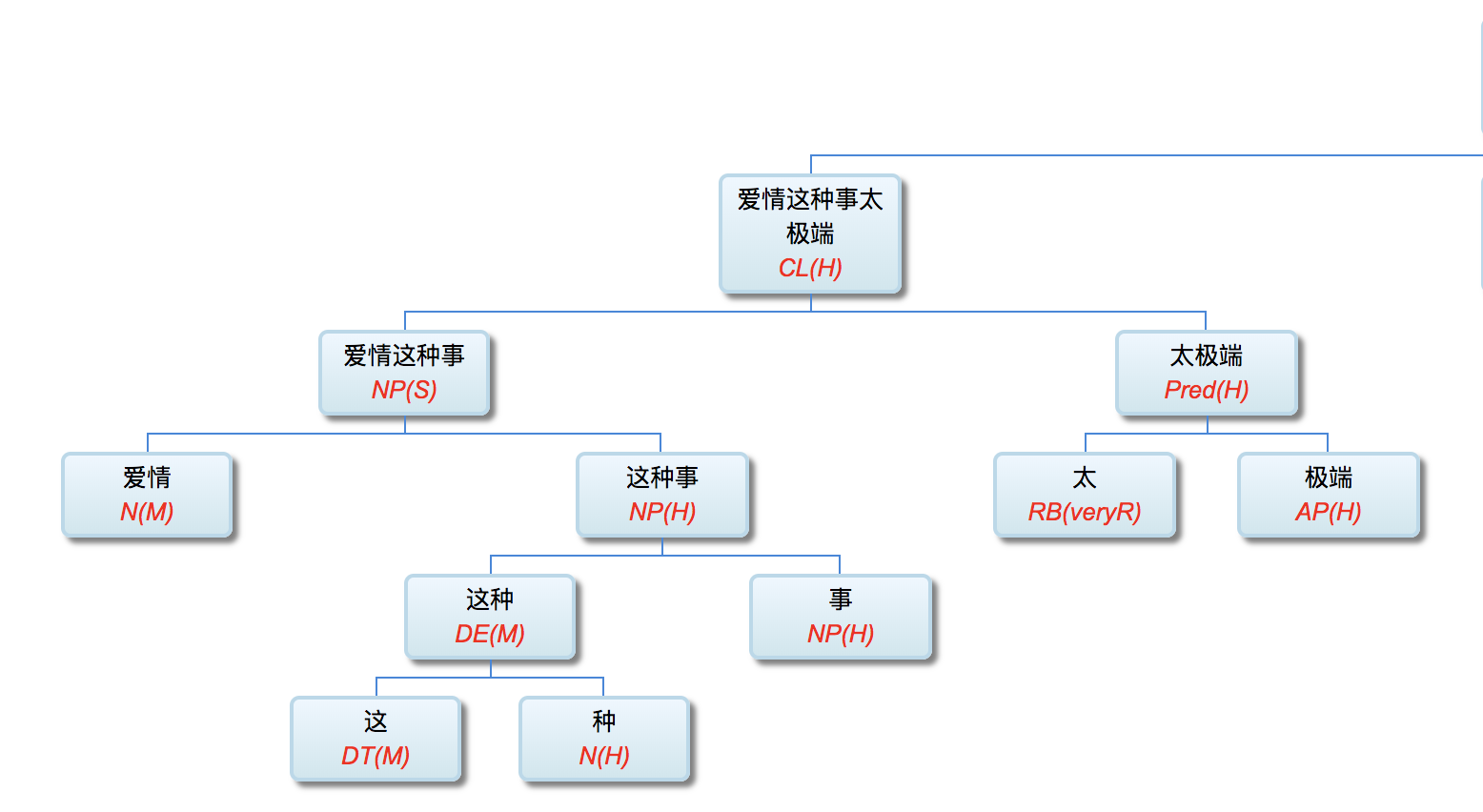
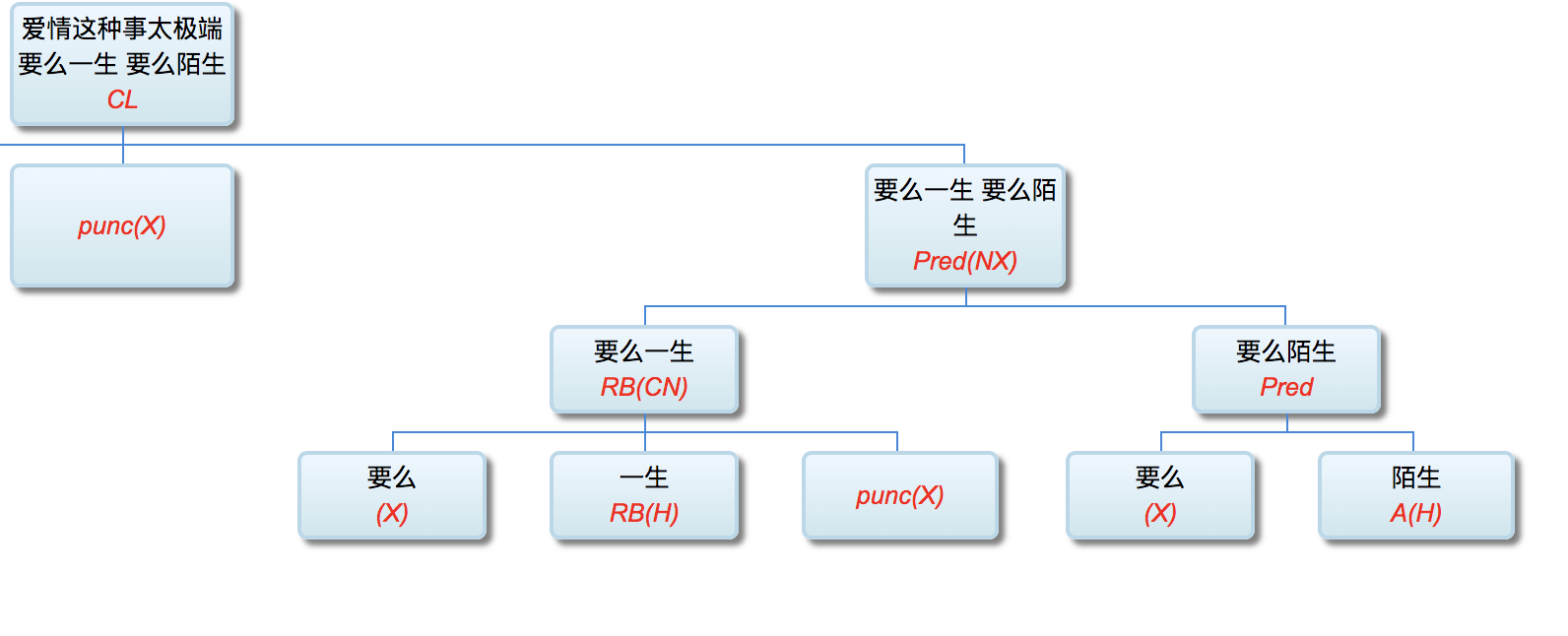
Figure 1‑1 sketches the architecture of a natural‑language parser core engine. Without dwelling on minutiae, note that every major module—from shallow parsing through deep parsing—can, in principle, be realised via interpretable symbolic logic encoded as a computational grammar. Through successive passes, the bewildering diversity of natural language is reduced first to syntactic relations and then to logical‑semantic structure. Since Chomsky’s distinction between surface structure and deep structure in late 50s, this layered view has become an orthodoxy within linguistics.
Guo: These days everyone venerates neural networks and deep learning. Does the grammar school still have room to live? Rationalism seems almost voiceless in current NLP scholarship. How should we interpret this history and the present trend?
Li: Roughly thirty years ago, the empiricist school of machine learning began its ascent, fuelled by abundant data and ever‑cheaper computation. In recent years, deep neural networks have achieved spectacular success across many AI tasks. Their triumph reflects not only algorithmic innovation but also today’s unprecedented volumes of data and compute.
By contrast, the rationalist programme of symbolic logic has waned. After a brief renaissance twenty years ago—centred on unification‑based phrase‑structure grammars (PSGs)—computational grammar gradually retreated from the mainstream. Many factors contributed; among them, Noam Chomsky’s prolonged negative impact warrants sober reflection.

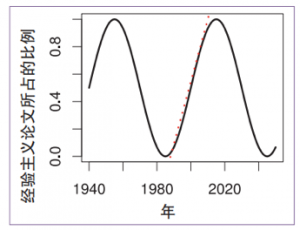
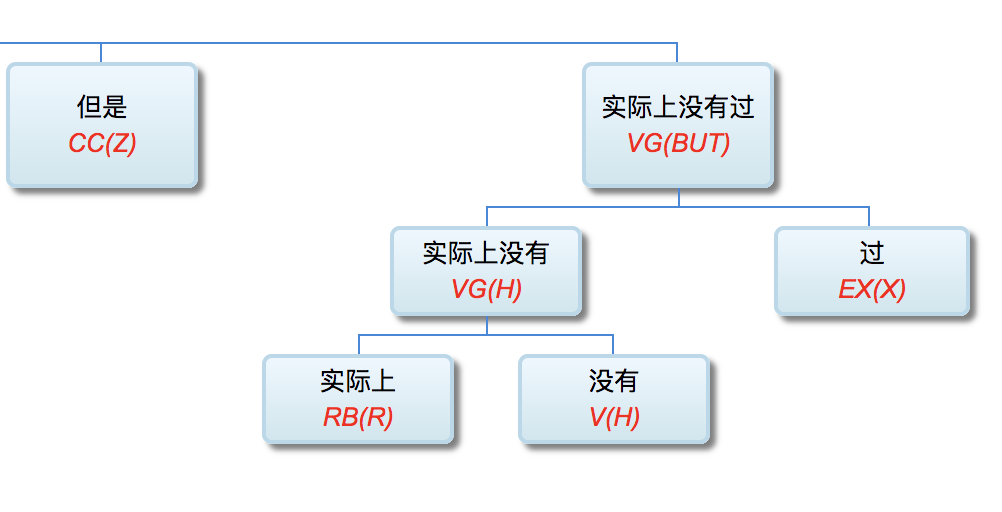
History reveals a pendulum swing between empiricism and rationalism. Kenneth Church famously illustrated the motion in his article A Pendulum Swung Too Far (Figure 1-2).
For three decades, the pendulum has tilted toward empiricism (black dots in Figure 1‑2); deep learning still commands the spotlight. Rationalism, though innovating quietly, is not yet strong enough to compete head‑to‑head. When one paradigm dominates, the other naturally fades from view.
Guo: I sense some conceptual confusion both inside and outside the field. Deep learning, originally just one empiricist technique, has become synonymous with AI and NLP for many observers. If its revolution sweeps every corner of AI, will we still see a rationalist comeback at all? As Professor Church warns, the pendulum may already have swung too far.
Li: These are two distinct philosophies with complementary strengths and weaknesses; neither can obliterate the other.
While the current empiricist monoculture has understandable causes, it is unhealthy in the long run. The two schools both compete and synergise. Veterans like Church continue to caution against over‑reliance on empiricism, and new scholars are probing deep integrations of the two methodologies to crack the hardest problems in NLU.
Make no mistake: today’s AI boom largely rests on deep‑learning breakthroughs, especially in image recognition, speech, and machine translation. Yet deep learning inherits a fundamental limitation of the statistical school—its dependence on large volumes of labelled data. In many niche domains—for instance, minority languages or e‑commerce translation—such corpora are simply unavailable. This knowledge bottleneck severely constrains empiricist approaches to cognitive NLP tasks. Without data, machine learning is a bread‑maker without flour; deep learning’s appetite as we all know is insatiable.
Guo: So deep learning is no panacea, and rationalism deserves a seat at the table. Since each paradigm has its merits and deficits, could you summarise the comparison?
Li: A concise inventory helps us borrow strengths and shore up weaknesses.
Advantages of machine learning
-
- Requires no domain experts (but does require vast labelled data).
- Excels at coarse‑grained tasks such as classification.
- High recall.
- Robust and fast to develop.
Advantages of the grammar school
-
- Requires no labelled data (but does require expert rule writing).
- Excels at fine‑grained tasks such as parsing and reasoning.
- High precision.
- Easy to localise errors; inherently interpretable.
Li: Rule‑based systems shine at granular, line‑by‑line dissection, whereas learned statistical models are naturally strong at global inference. Put bluntly, machine learning often "sees the forest but misses the trees," while computational grammars "see each tree yet risk losing the forest." Although data‑driven models boast robustness and high recall, they may hit a precision ceiling on fine‑grained tasks. Robustness is the key to surviving anomalies and edge cases. Expert‑coded grammars, by contrast, attain high precision, but boosting recall can require many rounds of iterative rule writing. Whether a rule‑based system is robust depends largely on its architectural design. Its symbolic substrate renders each inference step transparent and traceable, enabling targeted debugging—precisely the two pain‑points of machine learning, whose opaque decisions erode user trust and hamper defect localisation. Finally, a learning system scales effortlessly to vast datasets and its breakthroughs tend to ripple across an entire industry. Rule‑based quality, by contrast, hinges on the individual craftsmanship of experts—akin to Chinese cuisine, where identical ingredients may yield dishes of very different calibre depending on the chef.
Both routes confront knowledge bottlenecks. One relies on mass unskilled labour (annotators), the other on a few skilled artisans (grammar experts). For machine learning, the bottleneck is the supply of domain‑specific labelled data. The rationalist route simulates human cognition and thus avoids surface‑level mimicry of datasets, but cannot escape the low efficiency of manual coding. Annotation is tedious yet teachable to junior workers; crafting and debugging rules is a costly skill to train and hard to scale. Talent gaps exacerbate the issue—three decades of empiricist dominance have left the grammar school with a thinning pipeline.
Guo: Professor Li, a basic question: grammar rules are grounded in linguistic form. If semantics is derived from that form, then what exactly is linguistic form?
Li: This strikes at the heart of formalising natural language. All grammar rules rest on linguistic form, yet not every practitioner—even within the grammar camp—has a crisp definition at hand.
In essence, natural language as a symbolic system expresses meaning through form. Different utterances of an idea vary only in form; their underlying semantics and logic must coincide, else communication—and translation—would be impossible. The intuition is commonplace, but pinning down "form" propels us into computational linguistics.
Token & Order — The First‑Level Abstraction
At first glance a sentence is merely a string of symbols—phonemes or morphemes. True, but that answer is too coarse. Every string is segmented into units called tokens (words or morphemes). A morpheme is the smallest pairing unit of sound and meaning. Thus our first abstraction decomposes linguistic form into a sequence of tokens plus their word order. Grammar rules define patterns that match such sequences. The simplest pattern, a linear pattern, consists of token constraints plus ordering constraints.
Guo: Word order seems straightforward, but tokens and morphemes hide much complexity.
Li: Indeed. Because tokens anchor the entire enterprise, machine‑readable dictionaries become foundational resources. (Here "dictionary" means an electronic lexicon.)
If natural language were a closed set—say only ten thousand fixed sentences—formal grammar would be trivial: store them all, and each complete string would serve as an explicit pattern. But language is open, generating unbounded sentences. How can a finite rule set parse an infinite language?
The first step is tokenisation—dictionary lookup that maps character strings to lexicon words or morphemes. Unlimited sentences decompose into a finite vocabulary plus occasional out‑of‑dictionary items. Together they form a token list, the initial data structure for parsing.
We then enter classic linguistic sub‑fields. Morphology analyses the internal structure of multi‑morphemic words. Some languages exhibit rich morphology—noun declension, verb conjugation—e.g., Russian and Latin; others, such as English and Chinese, are comparatively poor. Note, however, that Chinese lacks inflection but excels at compounding. Compounds sit at the interface of morphology and syntax; many scholars treat them as part of "little syntax" rather than morphology proper.
Guo: Typologists speak of a spectrum—from isolating languages such as Classical Chinese (no morphology) to polysynthetic languages like certain Native American tongues (heavy morphology). Most languages fall between, with Modern Chinese and English leaning toward the isolating side: minimal morphology, rich syntax. Correct?
Li: Exactly. Setting aside the ratio of morphology to syntax, our first distinction is between function words/affixes versus content words. Function words (prepositions, pronouns, particles, conjunctions, original adverbs, interrogatives, interjections) and affixes (prefixes, suffixes, endings) form a small, closed set.
Content words—nouns, verbs, adjectives, etc.—form an open set forever producing neologisms; a fixed dictionary can hardly keep up.
Because function words and affixes are frequent yet limited, they can be enumerated as literals in pattern matching. Hence we have at least three grain‑sizes of linguistic form suitable for rule conditions: (i) word order; (ii) function‑word literals or affix literals; (iii) features.
Features — The Implicit Form
Explicit tokens are visible in the string, but parsers also rely on implicit features—category labels. Features encode part‑of‑speech, gender, number, case, tense, etc. They enter pattern matching as hidden conditions. Summarising: automatic parsing rests on (i) order, (ii) literals, (iii) features—two explicit, one implicit. Every language weaves these three in different proportions; grammar is but their descriptive calculus.
Guo: By this metric, can we say European languages are more rigorous than Chinese?
Li: From the standpoint of explicit form, yes. European tongues vary internally—German and French more rigorous than English—but all possess ample explicit markers that curb ambiguity. Chinese offers fewer markers, increasing parsing difficulty.
Inflectional morphology supplies visible agreement cues—gender‑number‑case for nouns, tense‑aspect‑voice for verbs. Chinese lacks these. Languages with rich morphology enjoy freer word order (e.g., Russian). Esperanto’s sentence "Mi amas vin" (I love you) can permute into six orders because the object case ‑n never changes.
Chinese, conversely, evolved along the isolating path, leveraging word order and particles. Even so, morphology provides tighter agreement than particles. Hence morphology‑rich languages are structurally stringent, reducing reliance on implicit semantics.
Guo: People call Chinese a "paratactic" language—lacking hard grammar, leaning on meaning. Does that equate to your notion of implicit form?
Li: Precisely. Parataxis corresponds to semantic cohesion—especially collocational knowledge within predicate structures. For example, the predicate "eat" expects an object in the food category. Such commonsense often lives in a lexical ontology like HowNet (founded by the late Professor Dong Zhendong).
Consider how plurality is expressed. In Chinese, "brother" is a noun whose category is lexically stored. Esperanto appends ‑o for nouns and ‑j for plural: frato vs. fratoj. Chinese may add the particle 们 (‑men), but this marker is optional and forbidden after numerals: "三个兄弟" (three brothers) not "*三个兄弟们". Here plurality is implicit, inferred from the numeral phrase.
Guo: Lacking morphology indeed complicates Chinese. Some even claim Chinese has no grammar.
Li: That is hyperbole. All languages have grammar; Chinese simply relies more on implicit forms. Overt devices—morphology, particles, word order—are fewer or more flexible.
Take omission of particles as an illustration. Chinese frequently drops prepositions and conjunctions. Compare:
-
-
- 对于这件事, 依我的看法, 我们应该听其自然。
As for this matter, in my opinion, we should let nature take its course. - 这件事我的看法应该听其自然。
* this matter my opinion should let nature take its course.
(Unacceptable as a word‑for‑word English rendering.)
- 对于这件事, 依我的看法, 我们应该听其自然。
-
Example 2 is ubiquitous in spoken Chinese but would be ungrammatical in English. Systematic omission of function words exacerbates NLP difficulty.
Guo: What about word order? Isolation theory says morphology‑poor languages have fixed order—Chinese is labelled SVO.
Li: Alas, reality defies the stereotype. Despite lacking morphology and often omitting particles, Chinese exhibits remarkable word‑order flexibility. Consider the six theoretical permutations of S, V, and O. Esperanto, with a single object case marker ‑n, allows all six without altering semantics. Compare English (no case distinction for nouns, but marking subject pronouns from obect cases) and Chinese (no case at all):
| Order | Esperanto | English | Chinese |
| SVO | Mi manĝis fiŝon | I ate fish | 我吃了鱼 |
| SOV | Mi fiŝon manĝis | * I fish ate | 我鱼吃了 |
| VOS | Manĝis fiŝon mi | * Ate fish I | ?吃了鱼我 |
| VSO | Manĝis mi fiŝon | * Ate I fish | * 吃了我鱼 |
| OVS | Fiŝon manĝis mi | * Fish ate I | ?鱼吃了我 |
| OSV | Fiŝon mi manĝis | Fish I ate | 鱼我吃了 |
Chinese sanctions three orders outright, two marginally (marked “?”), and forbids one (“*”). English allows only two. Thus Chinese word order is about twice as free as English, even though English possesses case distinction on pronouns. Hence morphology richness does not always guarantee order freedom.
Real corpora confirm that Chinese is more permissive than many assume. Greater flexibility inflates the rule count in sequence‑pattern grammars: every additional order multiplies pattern variants. Non‑sequential constraints can be encoded inside a single rule; order itself cannot.
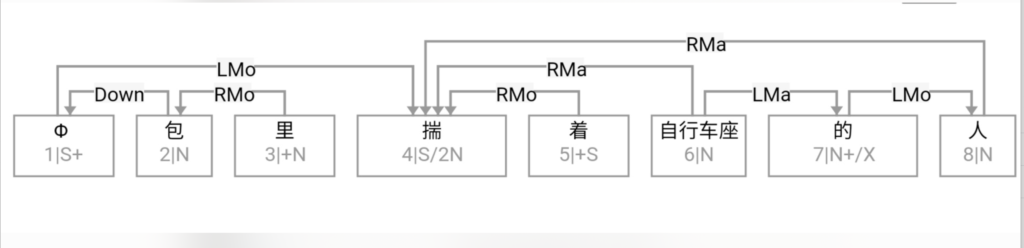
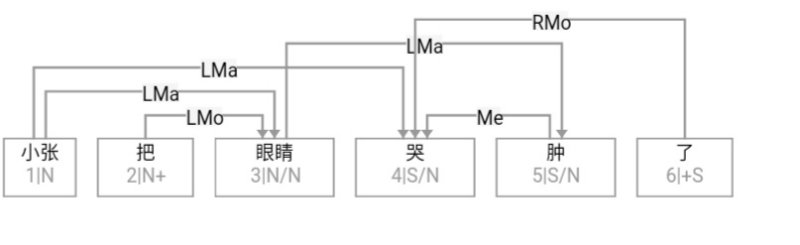
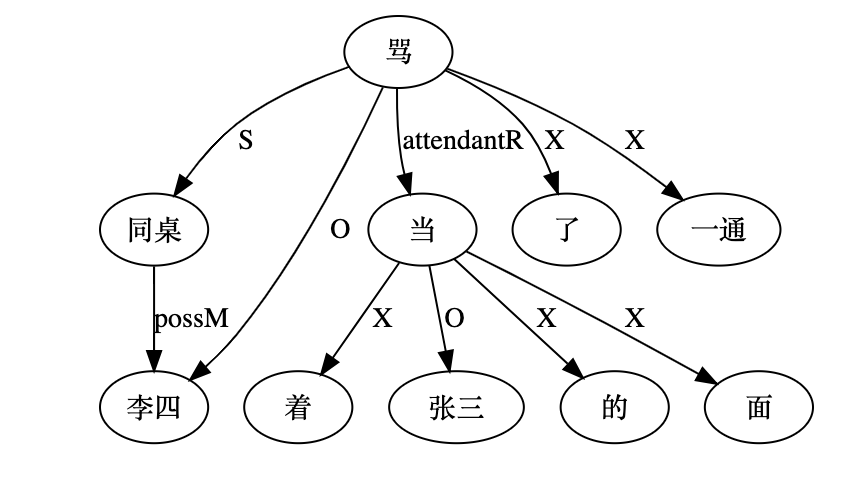
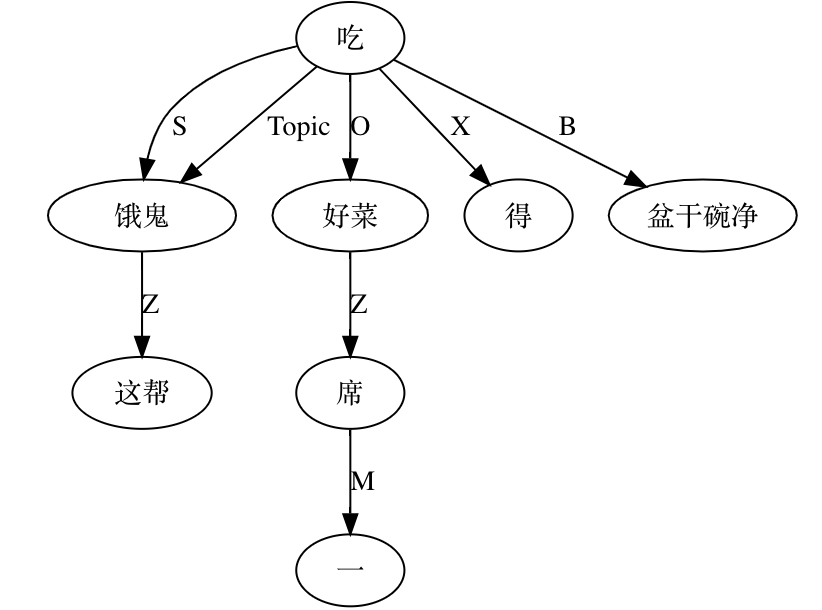
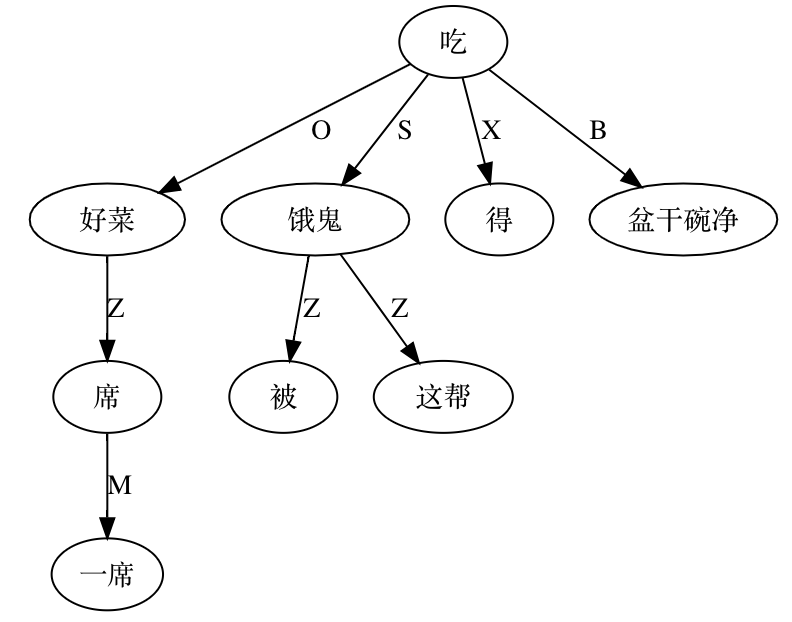
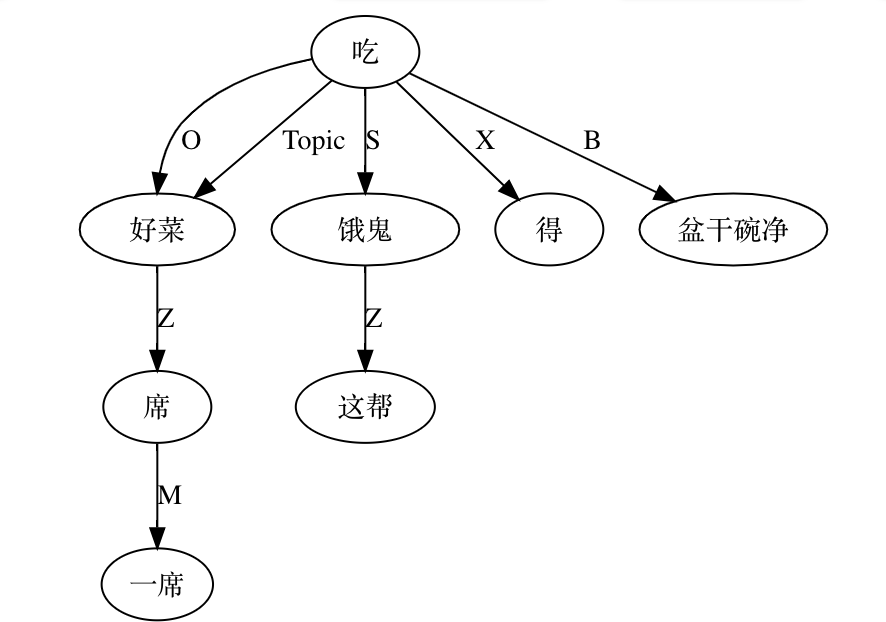
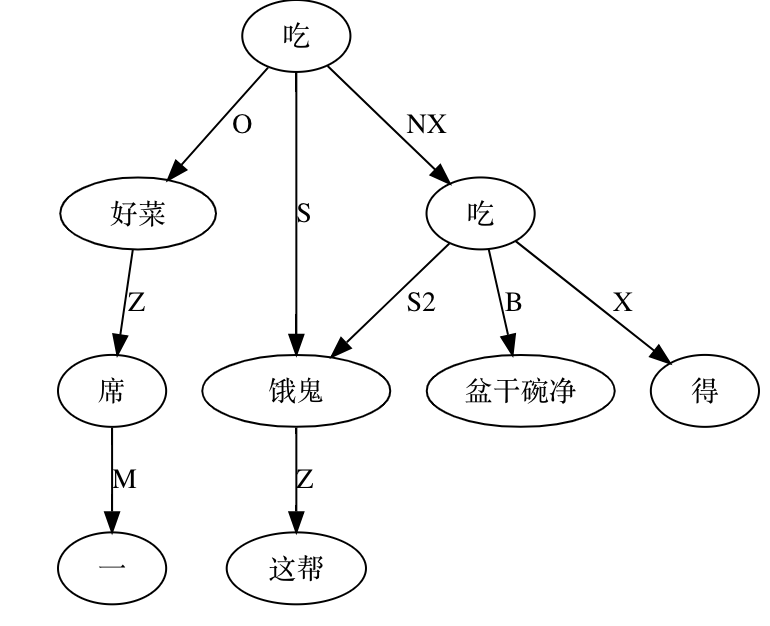
A classic example is the elastic placement of argument roles around "哭肿" (cry‑swollen):
张三眼睛哭肿了。
眼睛张三哭肿了。
哭肿张三眼睛了。
张三哭肿眼睛了。
哭得张三眼睛肿了。
张三哭得眼睛肿了。
…and so on.
Such data belie the notion of a rigid SVO Chinese. Heavy reliance on implicit form complicates automatic parsing. Were word order fixed, a few sequence patterns would suffice; flexibility forces exponential rule growth.
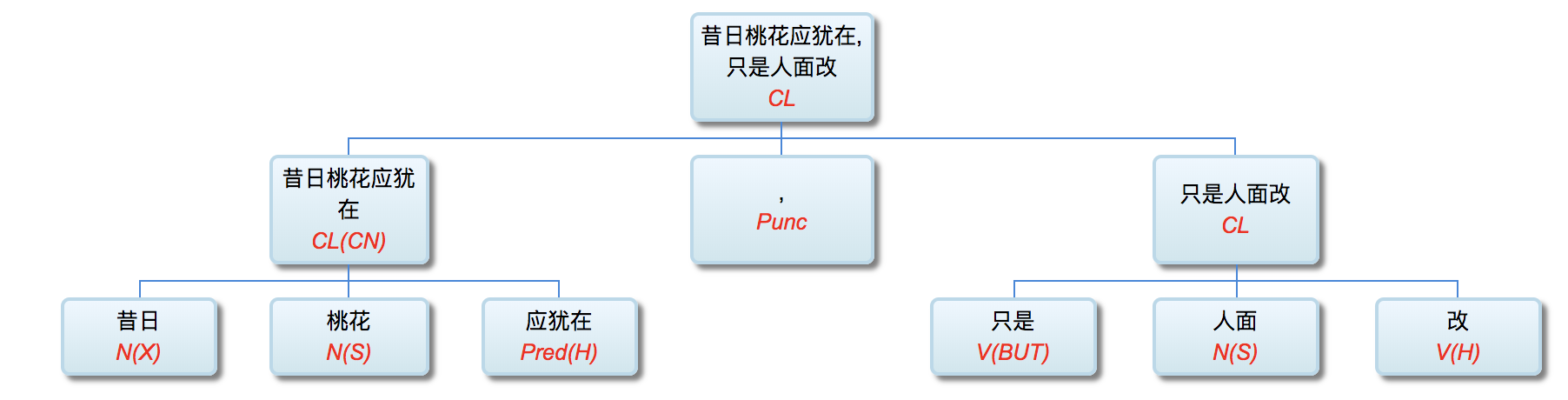
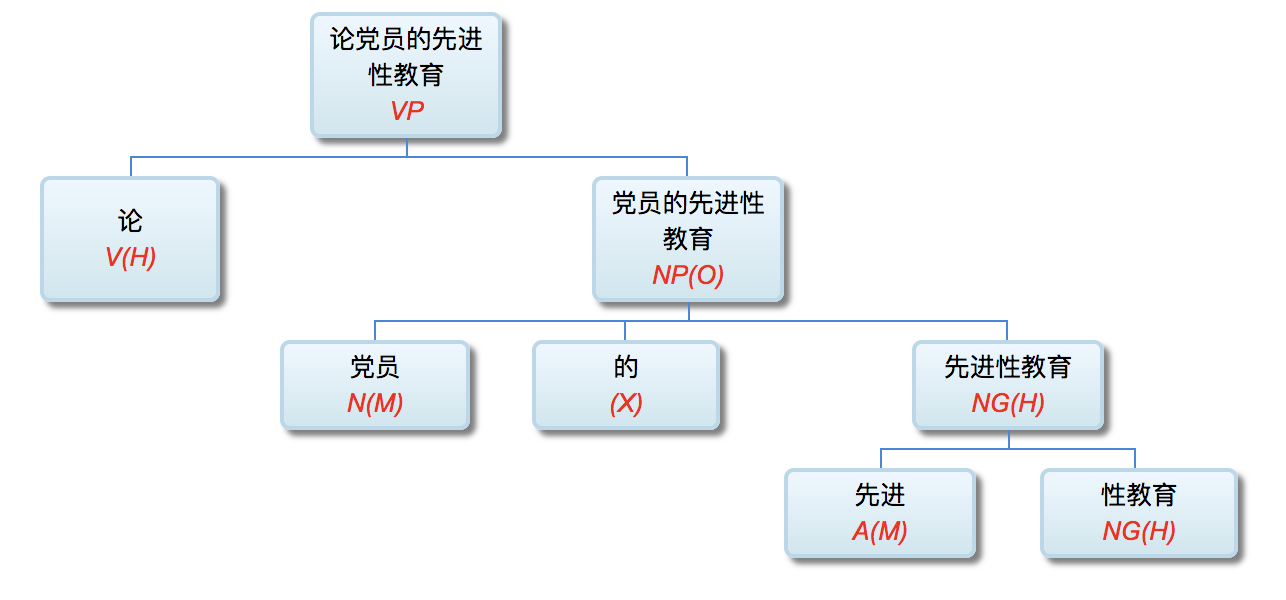
壹 自然语言与语言形式
郭: 李老师, 由浅入深, 我们还是从一些基本概念开始谈 起吧。什么是自然语言? 自然语言领域包括哪些内容? 它在人工智能里面的定位是怎样的呢?
李: 自然语言 (natural language) 指的是我们日常使用的语言, 英语、俄语、日语、汉语等, 它与人类语言是同义词。自 然语言有别于计算机语言。人脑处理的自然语言常有省略和歧义, 这给电脑 (计算机) 的处理提出了挑战。
在人工智能界, 自然语言是作为问题领域和处理对象提出来的。自然语言处理是人工智能的重要分支, 自然语言解析是其核心技术和通向自然语言理解的关键。语言解析是我 们接下来要探讨的、贯穿全书始终的话题。
计算语言学是计算机科学与语言学的交叉学科. 计算语言学和自然语言处理是同一个专业领域的两个剖面. 可以 说, 计算语言学是自然语言处理的科学基础, 自然语言处理是计算语言学的应用层面。
人工智能主要有感知智能 (perceptual intelligence) 和认 知智能 (cognitive intelligence) 两大块. 前者包括图像识别 (image recognition) 和语音处理 (speech processing)。随着 大数据和深度学习 (deep learning) 算法的突破性进展, 感知智能很多方面已经达到甚至超过人类专家的水平。认知智能的核心是自然语言理解, 被一致认为是人工智能的皇冠。从感知跃升到认知是当前人工智能所面临的最大挑战和机遇。
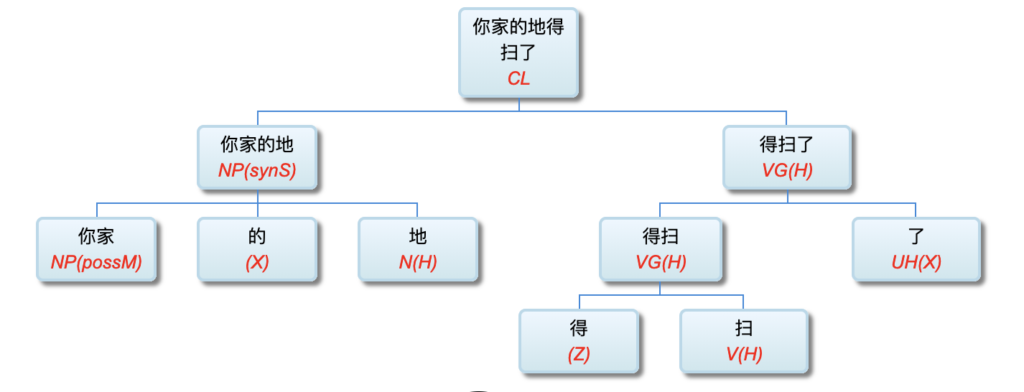
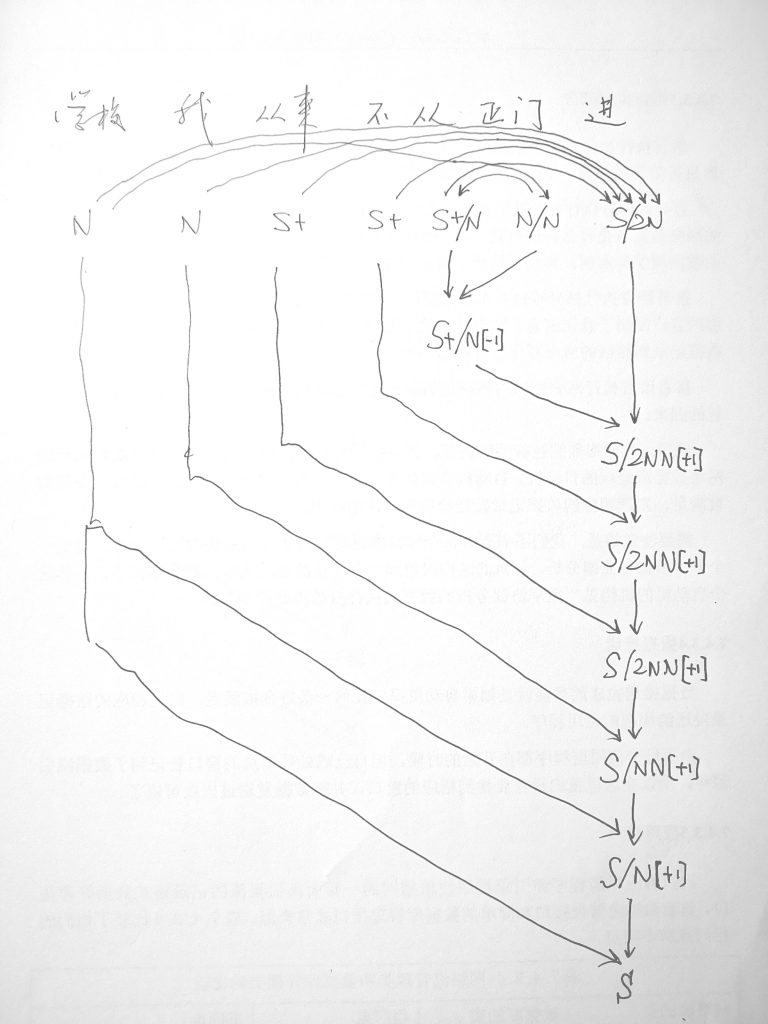
理性主义直接把领域专家的经验形式化, 利用符号逻辑来模拟人的智能任务。在自然语言处理领域, 与机器学习模型平行的传统方法是语言学家手工编码的语言规则。这些规则的 集合称为计算文法。由计算文法支撑的系统叫作规则系统 (rule system)。文法学派把语言学家总结出来的语言规则形式化, 从而对语言现象条分缕析, 达到对自然语言深层次的结构 解析. 规则系统试图模拟人的语言分析理解过程。规则系统解析自然语言是透明的、可解释 (interpretable) 的。这个过程很 像是外语文法老师在课堂上教给学生的句子分析方法。
图1—1是一张自然语言解析器 (parser) 核心引擎 (core engine) 的架构图。不必深究细节, 值得说明的是, 从浅层解析 (shallow parsing) 到深层解析 (deep parsing) 里面的各主要模块, 都可以用可解释的符号逻辑 (symbolic logic) 以计算文法的形式实现。千变万化的自然语言表达, 就这样一步一 步地从句法关系 (syntactic relation) 的解析, 进而求解其深层 的逻辑语义 (logic semantics) 关系。这个道理早在1957年乔 姆斯基 (Chomsky) 语言学革命中提出表层结构 (surface structure) 到深层结构 (deep structure) 的转换之后, 就逐渐成为语言学界的共识了。
郭: 现在大家都在推崇神经网络 (neural network) 深度学习, 文法学派还有生存空间吗? 理性主义在自然语言领域已经听不到什么声音了。怎样看待这段历史与趋向呢?
李: 大约从30年前开始到现在, 经验主义机器学习这一 派, 随着数据和计算资源的发展, 天时地利, 一直在向上走。尤其是近年来深层神经网络的实践, 深度学习在不少人工智能任务上取得了突破性的成功。经验主义的这些成功, 除了 神经网络算法的创新, 也得益于今非昔比的大数据和大计算的能力。
与此对照, 理性主义符号逻辑则日趋式微。符号逻辑在自然语言领域表现为计算文法。文法学派在经历了20年前 基于合一 (unification) 的短语结构文法 (Phrase Structure Grammar, PSG) 创新的短暂热潮以后, 逐渐退出了学界的主 流舞台。形成这一局面的原因有多个, 其中包括乔姆斯基对于文法学派长期的负面影响, 值得认真反思。
回顾人工智能和自然语言领域的历史, 经验主义和理性 主义两大学派此消彼长, 呈钟摆式跌宕起伏。肯尼斯丘吉 (Kenneth Church) 在他的「钟摆摆得太远」(A Pendulum Swung Too Far) 一文中, 给出了一个形象的钟摆式跌宕图 (图1—2).
最近30年来, 经验主义钟摆的上扬趋势依然不减 (见图 1—2的黑点表示)。目前来看, 深度学习仍在风头上。理性主义积蓄多年, 虽然有其自身的传承和创新, 但还没有到可以与经验主义正面争锋的程度。当一派成为主流时, 另一派自然淡出视野。
郭: 我感觉业内业外有些认知上的混乱。深度学习本来只是经验主义学派的一种方法, 现在似乎在很多人心目中等价于人工智能和自然语言处理了。如果深度学习的革命席卷 人工智能的方方面面, 会不会真地要终结理性主义的回摆呢? 正如丘吉教授所言, 经验主义的钟摆已经摆得太远了。
李: 我的答案是否定的。这是两个不同的哲学和方法论, 各自带有其自身的天然优势和劣势, 不存在一派彻底消灭另 一派的问题。
当前学界经验主义一面倒的局面虽然事出有因, 但并不 是一个健康的状态。其实, 两派既有竞争性, 也有很强的互补 性。丘吉这样的老一辈有识之士一直在警示经验主义一边倒的弊端, 也不断有新锐学者在探索两种方法论的深度融合, 以 便合力解决理解自然语言的难题。
毫无疑问, 这一波人工智能的热潮很大程度上是建立在深度学习的突破上, 尤其是在图像识别、语音处理和机器翻译方面取得的成就上。但是, 深度学习的方法仍然保留了统计学派的一个根本局限, 就是对海量标注数据 (labeled data) 的依赖。在很多细分领域和任务场景, 譬如, 少数族裔语言的解 析、电商数据的机器翻译, 海量标注或领域翻译数据并不存 在。这个知识瓶颈严重限制了经验主义方法在自然语言认知任务方面的表现。没有足够的标注数据, 对于机器学习就是无米之炊。深度学习更是如此, 它的胃口比传统机器学习 更大。
郭 : 看来深度学习也不是万能的, 理性主义理应有自己的一席之地。说它们各有长处和短板, 您能够给个比较吗?
李: 归纳一下两派各自的优势与短板是很有必要的, 可以取长补短。
机器学习的优势包括:
(1) 不依赖领域专家 (但需要大量标注数据);
(2) 长于粗线条的任务, 如分类 (classification);
(3) 召回 (recall) 好;
(4) 鲁棒 (robust), 开发效率高。
与此对照, 文法学派的优势包括:
(1) 不依赖标注数据 (但需要专家编码);
(2) 长于细线条的任务, 譬如解析和推理;
(3) 精度(precision)好;
(4) 易于定点排错, 可解释。
专家编码的规则系统擅长逐字逐句的条分缕析, 而学习出来的统计模型则天然长于全局结论。如果说机器学习往往是见林不见木的话, 计算文法则是见木不见林。大数据驱动的机器学习虽然带来了鲁棒和召回的长处, 但对细线条的任务较易遭遇精度的天花板。所谓鲁棒, 是robust的音译, 也 就是强壮、稳健的意思, 它是在异常和危险情况下系统生存的关键。专家编写规则虽然容易保障精度, 但召回的提升则是一个漫长的迭代过程。鲁棒性则决定于规则系统的架构设计。规则系统的基础是可解释的符号逻辑, 容易追踪到出错的现 场, 并做出有针对性的排错。而这两点正是机器学习的短板。机器学习的结果不论是对是错, 都难以解释, 因而影响用户的体验和信赖。难以定点排错更是开发现场的极大困扰, 其原因是学习模型缺乏显性符号与结构表示 (structure representation)。最后, 学习系统能较快地规模化到大数据的应用场景, 成功易于复制, 方法的突破往往可带动整个行业的提升。相对而言, 规则系统的质量很大程度上取决于专家的个体经 验。这就好比中餐, 同样的食材, 不同的厨师做出来的菜肴品质常常相差很大。
两条路线各有自身的知识瓶颈。打个比喻, 一个是依赖海量的低级劳动, 另一个是依赖少数专家的高级劳动。对于 机器学习, 海量标注是领域化落地 (grounding,即落实到应 用) 的知识瓶颈。理性主义路线模拟人的认知过程, 无需依赖海量数据在表层模仿。但难以避免手工编码的低效率。标注 工作虽然单调, 可一般学生稍加培训即可上手。而手工编制、 调试规则, 培训成本高, 难以规模化。还有, 人才的断层也算是文法学派的一个现实的局限。30年正好是一代人。在过 去的30年, 经验主义在主流舞台的一枝独秀, 客观上造成了 理性主义阵营人才青黄不接。
郭: 李老师,我有个基本问题: 文法规则依据的是语言形式 (linguistic form)。那么, 通过这个形式解析出语义 (semantics), 到底什么是语言形式呢?
李: 这是自然语言形式化的根本问题。所有的文法规则都建立在语言形式的基础之上, 可并不是每个人, 包括从事文 法工作的人, 都能对语言形式有个清晰的认识。
不错, 自然语言作为符号系统, 说到底就是以语言形式来表达语义。话语的不同只是形式的不同, 背后的语义和逻辑一定是相同的, 否则人不可能交流思想, 语言的翻译也会失去根基。这个道理老少咸知, 那什么是语言形式的定义呢? 回答这个问题就进入计算语言学了。
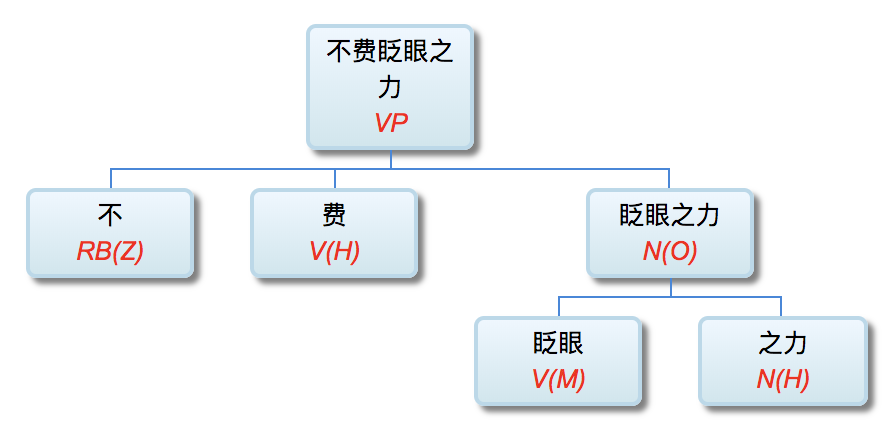
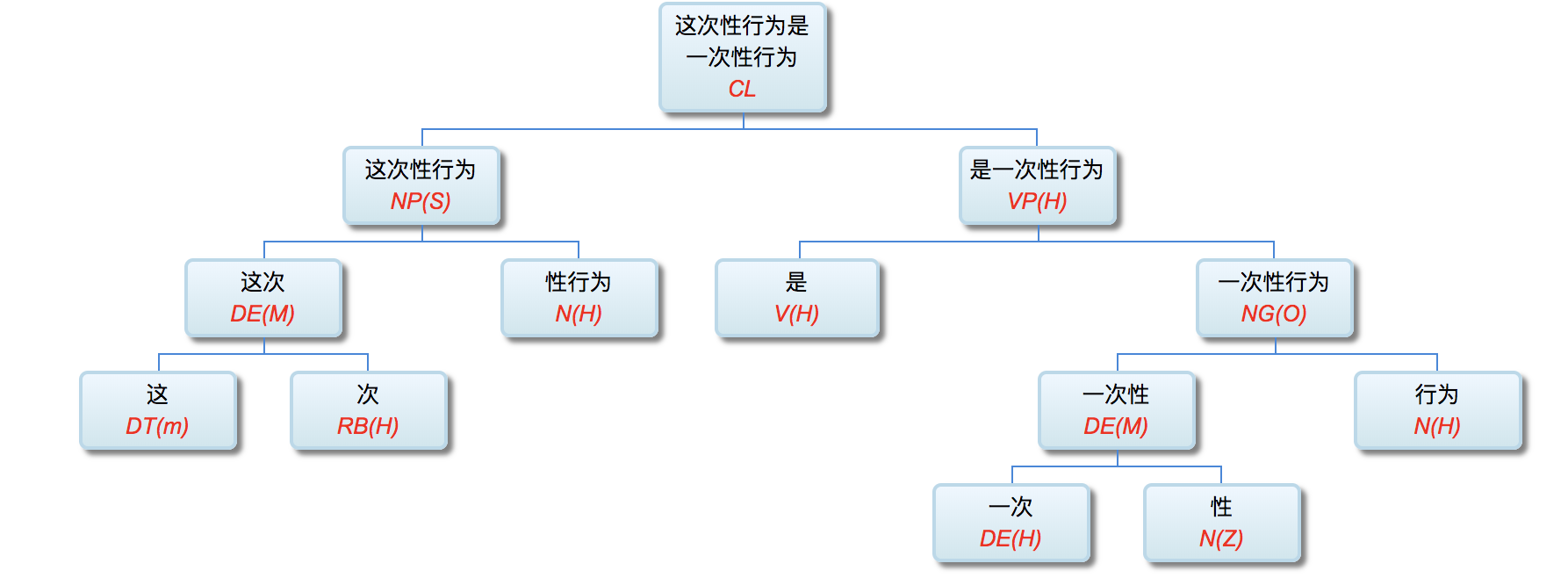
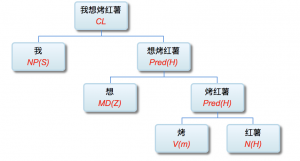
语言形式, 顾名思义, 就是语言的表达手段。乍一看语言, 不就是符号串吗? 语音流也好, 文字串也好, 都可以归结为符号串。所以, 符号串就是语言形式。这个答案不算错, 但失之笼统。这个“串”是有单位的, 其基本单位叫 token (可译 作“文本符号”), 也就是单词或语素 (morpheme)。语素, 其定义是音义结合的最小符号单位。因此, 作为第一级抽象, 我们可以把语言形式分解为文本符号及其语序 (word order)。计算文法中的规则都要定义一个条件模式 (pattern), 就是为 了与语言符号串做匹配。最基本的条件模式叫线性模式 (linear pattern), 其构成的两个要素就是符号条件和次序条件。
郭 : 好, 语言形式的基本要素是词/语素和语序。语序就是符号的先后顺序, 容易界定; 但词和语素里面感觉有很多 学问。
李: 不错, 作为语言符号, 词和语素非常重要, 它们是语言学的起点。收录词和语素的词典因此成为语言解析的基础资源。顺便提一下, 我们在这所说的“词典”是指机器词典, 它是 以传统词典为基础的形式化资源。
如果自然语言表达是一个封闭的集合, 譬如, 一共就只有一万句话, 语言形式文法就简单了。建个库把这些语句词串全部收进去, 每个词串等价于一条“词加语序”的模式规则。全词串的集合就是一个完备的文法模型。但是, 自然语言是 一个开放集, 无法枚举无穷变化的文句。形式文法是如何依据语言形式形成规则, 并以有限规则完成对无限文句的自动解析呢?
以查词典为基础的分词 (tokenization), 是文句解析的第 一步。查词典的结果是“词典词” (lexicon word), 包括语素。无限文句主要靠查词典分解为有限的单位。词典词加上少量 超出词典范围的生词, 一起构成词节点序列 (tokenlist)。词节点序列很重要, 它是文句的形式化表示 (formalized representation)。作为初始的数据结构, 词节点序列是自动解析的 对象。
接 下来就进入语言学的基本分支了, 通常叫词法 (morphology), 目的是解析多语素词 (multi-morphemic word) 的内部结构。对于有些语种, 词法很繁复, 包括名词变格 (declension)、动词变位 (conjugation) 等, 譬如俄语、拉丁语; 有些语种的词法则较贫乏, 譬如英语、汉语。值得注意的是, 词法的繁简只是相对而言。譬如汉语缺乏形态 (inflection), 单词不变形, 但是汉语的多语素复合造词的能力却很强。不过, 语 言学里的复合词 (compound word) 历来有争议, 它处于词法与句法 (syntax) 接口的地带, 其复合方式也与句法短语的方式类似。所以, 很多人不把词的复合当成词法, 而是看成句法的前期部分, 或称小句法。
郭: 以前看语言类型方面的文章, 说有一个频谱, 一个极端叫孤立语 (isolating language), 以古汉语为代表。孤立语没有词法, 只有句法。另一个极端好像叫多式综合语 (poly-synthetic language), 以某些印第安语为代表, 基本上只有词 法, 没有句法。多数语言处在两个极端之间, 现代汉语和英语更多偏向孤立语这边, 小词法大句法. 是这样吗?
李: 对, 是这样的。撇开词法句法比例的差别, 我们在研究词和语素的时候, 第一眼看到的是它的两大类别: 一类是小 词 (function word) 和形态, 是个较小的封闭集合; 一类叫实词 (notional word), 是个开放集合。实词范畴永远存在“生词”, 词典是收不住口的。
小词, 其实只是俗称, 术语应该叫功能词、封闭类词或虚词, 指的是介词、代词、助词、连词、原生副词 (original adverb)、疑问词、感叹词之类。形态包括前缀 (prefix)、后缀 (suffix)、词尾 (ending) 等材料, 也是一个小的集合。小词和形态出现频率高, 但数量有限。作为封闭类语素, 小词和形态需要匹配的时候, 原则上可以直接枚举它们, 软件界称其为匹配直接量 (literal)。至此, 我们至少得到了下面几种语言形式可以作为规则的条件: ①语序; ②小词; ③形态。不同的语言类型对这些形式的倚重和比例不同。例如, 俄语形态丰富, 对于语序和小词的依赖较少; 英语形态贫乏, 语序就相对固 定, 小词也比较丰富。
那么实词呢? 实词当然也是语言形式, 也可以尝试在规 则模式中作为直接量来枚举。但是, 因为实词是个开放集, 最好给它们分类, 利用类别而不是直接量去匹配实词, 这样做才会有概括性。人脑对于实词也主要靠分类来总结抽象的. 给词分类并在词典中标注分类结果是形式化的基础工作。
形式系统里面, 分类结果通常以特征 (feature) 来表示和标注。特征是系统内部定义的隐性语言形式。隐性形式 (implicit form) 是相对于前面提到的显性形式 (explicit form) 而 言。很显然, 无论语序还是语素, 它们都是语言符号串中可以看得见的形式。分类特征则不然, 它们是不能直接感知的。这些特征作为词典查询的结果提供给解析器, 支持模式匹配 (pattern matching) 的形式条件。
总结一下自动解析所依据的语言形式, 主要有三种: ①语序; ②直接量 (尤其是小词和形态); ③特征。前两种是显性形式, 特征是隐性形式。语言形式这么一分, 自然语言一下子就豁然开朗了。管它什么语言, 不外乎这三种形式的交错使用, 搭配的比例和倚重不同而已。所谓文法, 也不外乎用这三种形式形成规则, 对语言现象及其背后的结构做描述而已。
三种语言形式可以嫁接。显性形式的嫁接包括重叠式 (reduplication), 如: “高高兴兴”“走一走”。它是语序与直接量嫁接的模式 (AABB、V 一V), 是中文词法句法中常用的形式手段。显性形式也可以特征化。特征化可以通过词典标注实现, 也可以通过规则模块或子程序赋值得出。例如, “形态特征” (如单数、第三人称、现在时等) 就是通过词法模块得出 的特征。形态解析所依据的条件主要是作为直接量的形态词尾 (inflectional ending) 以及词干 (stem) 的类型特征, 例如, 英语词尾“-ly”与形容词词干结合成为副词 (beautiful-ly)。可见, 形态特征也是显性形式与隐性形式的嫁接结果。
郭: 从语言形式的使用看, 可以说欧洲语言比汉语更加严 谨吗?
李: 是的。从语言形式的角度来看, 欧洲语言确实比汉语严谨。欧洲语言内部也有不小的区别, 例如, 德语、法语就比英语严谨, 尽管从语言形成的历史上看, 可以说英语是从德 语、法语杂交而来的。
这里的所谓“严谨”, 是指这些语言有比较充分的显性形式来表达结构关系, 有助于减少歧义。汉语显性形式不足, 因此增加了汉语解析 (Chinese parsing) 的难度。形态是重要的显性形式, 如名词的“性数格” (gender, number and case), 动词的“时体态”(tense, aspect and voice), 这些词法范畴是以显性的形态词尾来表达的。但是这类形态汉语里没有。形态丰富的语言语序比较自由, 譬如俄语。再如世界语 (Esperanto) 的“我爱你”有三个词, 可以用六种语序任意表达, 排列组合。为什么语序自由呢? 因为有宾格 (object case) 这样的形态形式, 它跑到哪里都逃不出动宾 (verb-object) 关系, 当然就不需要依赖固定的语序了。
汉语在发展过程中, 没有走形态化的道路, 而是利用语序和小词在孤立语的道路上演化. 英语的发展大体也是这个模式。从语言学的高度看, 形态也好, 小词也好, 二者都是可以感知的显性形式。但是, 形态词尾的范畴化, 比起小词 (主要是介词), 要发达得多。动词变位、名词变格等形态手段, 使得有结构联系的语词之间产生一种显性的一致关系 (agreement)。譬如, 主谓 (subject predicate) 在人称和数上的一致关系, 定语与中心词在性数格上的一致关系等。关系有形式标记, 形态语言的结构自然严谨得多, 减少了结构歧义的可能。丰富的形态减低了解析对于隐性形式和知识的依赖。
郭 : 常听人说,中文是“意合”式语言, 缺少硬性的文法规范, 是不是指的就是缺乏形态, 主要靠语义手段来分析理解它?
李: 是的. 从语言形式化的角度看, 语义手段表现为隐性形式。所谓“意合”, 其实就是关联句词之间的语义相谐, 特别是谓词 (predicate word) 结构里面语义之间的搭配 (collocation) 常识。譬如, 谓词“吃”的对象是“食品”。这种 常识通常编码在本体知识库 (ontology) 里面。董振东先生创立的“知网 (HowNet)”∗ 就是这样一个本体常识的知识库。
∗ “知网” (HowNet) 是中国自然语言处理前辈董振东先生发明的跨语言的语义机器词典。这套词典为词义的本体概念及其常识编码, 旨在设立一套形式化语义概念网络, 以此作为自然语言处理的基础支持。
再看形态与小词的使用。譬如, “兄弟”在汉语里是名词, 这个词性是在词典标注的。但是世界语的“frato (兄弟)”就不需要词典标注, 因为有名词词尾“-o”。再如复数, 汉语的 “兄弟们”用了小词“们”来表示复数的概念; 世界语呢, 用词尾 “-j”表示, 即“fratoj (兄弟们)”。乍一看, 这不一样么? 都是 用有限的语言材料, 做显性的表达。但是, 有“数”这个词法范 畴的欧洲语言 (包括世界语), 那个形态是不能省略的。而汉语的复数表达, 有时显性有时隐性,这个“们”不是必需的, 如:
三个兄弟没水喝。
这里的兄弟复数就没有小词“们”。实际上, 汉语文法规定了不允许在数量结构后面加复数的显性形式, 譬如不能说 “三个兄弟们”。换句话说, 中文“(三个)兄弟”里的复数是隐性的,需要前面的数量结构才能确定。
郭: 看来缺乏形态的确是中文的一个挑战。中文学起来难, 自动解析也难。有人甚至说, 中文根本就没有文法。
李: 那是偏激之词了。不存在没有文法的语言。假如语 言没有“法”, 那么人在使用时如何把握, 又如何理解呢? 只不 过是, 中文的文法更多地依赖隐性形式。
汉语文法的确比较宽松, 宽松表现在较少依赖显性形式。语句的顺畅靠的是上下文语义相谐, 而不是依靠严格的显性文法规则。譬如形态、小词、语序, 显性形式的三个手段, 对于 汉语来说, 形态基本上没有, 小词常常省略, 语序也很灵活。
先看小词,譬如, 介词、连词, 虽然英语有的汉语基本都有, 但是汉语省略小词的时候远远多于英语。这是有统计根据的, 也符合我们日常使用的感觉: 中文, 尤其是口语, 能省则省,显得非常自由。对比下列例句, 可见汉语中省略小词是普遍性的:
① 对于这件事, 依我的看法, 我们应该听其自然.
As for this matter, in my opinion, we should leave it to nature.
② 这件事我的看法应该听其自然.
∗ This matter my opinion should leave it to nature.
类似句子②在汉语口语里极为常见, 感觉很自然。如果尝试词对词译成英语, 则完全不合文法。汉语和英语都用介词短语 (prepositional phrase, PP) 做状语, 可是汉语介词常可 省略。这种缺少显性形式标记的所谓“意合”式表达, 确实使得中文的自动化处理比英文处理难了很多。
郭: 汉语利用语序的情况如何? 常听人说, 形态丰富的语言语序自由。汉语缺乏形态, 因此是语序固定的语言。中文一般被认为是“主谓宾(SVO)”固定的语言。
李: 可惜啊, 并非如此。按常理来推论, 缺乏形态又常常省掉小词, 那么, 语序总该固定吧? 可实际上, 汉语并不是持孤立语语序固定论者说的那样语序死板, 其语序的自由度常超出一般人的想象。
拿最典型的主谓宾句型的变式来看, SVO 三元素, 排列的极限是六种组合。世界语的形态不算丰富, 论变格只有一 个宾格“-n”的词尾, 主格 (subject case) 是零形式。它仍然可以采用六种变式的任意一个语序, 而不改变“SVO”的逻辑语义关系 (logic semantic relation)。比较一下形态贫乏的英语 (名词没有格变, 但是代词有) 和缺乏形态的汉语 (名词代词都没有格变), 是很有意思的。世界语、英语、汉语三种语言 SVO 句型的自由度对比如下:
①SVO:
Mi manĝis fiŝon.
I ate fish.
我吃了鱼。
②SOV:
Mi fiŝon manĝis.
∗ I fish ate.
我鱼吃了。
③VOS:
Manĝis fiŝon mi.
∗ Ate fish I.
? 吃了鱼我。(口语可以)
④VSO:
Manĝis mi fiŝon.
∗ Ate I fish.
∗ 吃了我鱼。(解读不是VSO, 而是“吃了我的鱼”)
⑤OVS:
Fiŝon manĝis mi.
∗ Fish ate I.(不允许, 尽管“I”有主格标记)
? 鱼吃了我。(合法解读是SVO,与OVS正好相反)
⑥OSV:
Fiŝon mi manĝis.
fish I ate.
鱼我吃了。
总结一下, 在六个语序中, 汉语有三个是合法的, 有两个在灰色地带 (前标“? ”, 口语中似可存在), 有一个是非法的 (前标 “∗ ”),英语呢? 只有两个合法, 其余皆非法。可见, 汉语的语序自由度在最常见的SVO句式中, 比英语要大一倍。虽然英语有代词的格变(I/me), 而汉语没有, 英语的语序灵活性反而不如汉语。可见, 形态的丰富性与语序自由度并非必然呼应。
汉语其实比很多人想象得具有更大的语序自由度和弹 性。常常是, 思维里什么概念先出现, 就可以直接蹦出来。再看一组例子:
张三眼睛哭肿了。
眼睛张三哭肿了。
哭肿张三眼睛了。
张三哭肿眼睛了。
哭得张三眼睛肿了。
张三哭得眼睛肿了。
张三眼睛哭得肿了。
张三的眼睛哭肿了。
............
若不研究实际数据的话, 我们很难相信汉语语序如此任性。汉语依赖隐性形式比显性形式更多, 这对自动解析显然不利。我们当然希望语言都是语序固定的, 这该省多少力气啊! 序列模式规则就是由符号加次序构成的, 语序灵活了, 规 则数量就得成倍增长。非语序的其他形式约束可以在既定的模式里面调控, 唯有语序是规则编码绕不过去的坎儿。