【立委按】
白硕老师这篇文章值得所有自然语言学者研读和反思。击节叹服,拍案叫绝,是初读此文的真切感受。白老师对乔姆斯基形式语言理论用于自然语言所造成的误导,给出了迄今所见最有深度的犀利解析,而且写得深入浅出,形象生动,妙趣横生。这么多年,这么多学者,怎么就达不到这样的深度呢?一个乔姆斯基的递归陷阱不知道栽进去多少人,造成多少人在 “不是人话” 的现象上做无用功,绕了无数弯路。学界曾有多篇长篇大论,机械地套用乔氏层级体系,在自然语言是 context-free 还是 context-sensitive 的框框里争论不休,也有折衷的说法,诸如自然语言是 mildly sensitive,这些形而上的学究式争论,大多雾里看花,隔靴搔痒,不得要领,离语言事实甚远。白老师独创的 “毛毛虫” 论,形象地打破了这些条条框框。
白老师自己的总结是:‘如果认同“一切以真实的自然语言为出发点和最终落脚点”的理念,那就应该承认:向外有限突破,向内大举压缩,应该是一枚硬币的两面。’ 此乃金玉良言,掷地有声。
【白硕 - 穿越乔家大院寻找“毛毛虫”】
看标题,您八成以为这篇文章讲的是山西的乔家大院的事儿了吧?不是。这是一篇烧脑的技术贴。如果您既不是NLP专业人士也不是NLP爱好者,就不用往下看了。
咱说的这乔家大院,是当代语言学祖师爷乔姆斯基老爷子画下来的形式语言类型谱系划分格局。最外边一圈围墙,是0型文法,又叫短语结构文法,其对应的分析处理机制和图灵机等价,亦即图灵可计算的;第二圈围墙,是1型文法,又叫上下文相关文法,其对应的分析处理机制,时间复杂度是NP完全的;第三圈围墙,是2型文法,又叫上下文无关文法,其对应的分析处理机制,时间复杂度是多项式的,最坏情况下的最好渐进阶在输入句子长度的平方和立方之间;最里边一层围墙,是3型文法,又叫正则文法,其对应的分析处理机制和确定性有限状态自动机等价,时间复杂度是线性的。这一圈套一圈的,归纳整理下来,如下图所示:
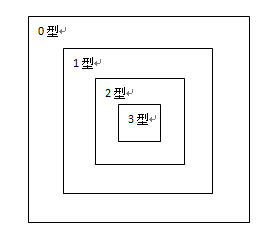
乔老爷子建的这座大院,影响了几代人。影响包括这样两个方面:
第一个方面,我们可以称之为“外向恐惧情结”。因为第二圈的判定处理机制,时间复杂度是NP完全的,于是在NP=P还没有证明出来之前,第二圈之外似乎是禁区,没等碰到已经被宣判了死刑。这样,对自然语言的描述压力,全都集中到了第三圈围墙里面,也就是上下文无关文法。大家心知肚明自然语言具有上下文相关性,想要红杏出墙,但是因为出了围墙计算上就hold不住,也只好打消此念。0院点灯……1院点灯……大红灯笼高高挂,红灯停,闲人免出。
第二个方面,我们可以称之为“内向求全情结”。2型文法大行其道,取得了局部成功,也带来了一个坏风气,就是递归的滥用。当递归层数稍微加大,人类对于某些句式的可接受性就快速衰减至几近为0。比如,“我是县长派来的”没问题,“我是县长派来的派来的”就有点别扭,“我是县长派来的派来的派来的”就不太像人话了。而影响分析判定效率的绝大多数资源投入,都花在了应对这类“不像人话”的递归滥用上了。自然语言处理要想取得实用效果,处理的“线速”是硬道理。反思一下,我们人类的语言理解过程,也肯定是在“线速”范围之内。递归的滥用,起源于“向内求全情结”,也就是一心想覆盖第三圈围墙里面最犄角旮旯的区域,哪怕那是一个由“不像人话”的实例堆积起来的垃圾堆。
可以说,在自然语言处理领域,统计方法之所以在很长时间内压倒规则方法,在一定程度上,就是向外恐惧情结与向内求全情结叠加造成的。NLP领域内也有很多的仁人志士为打破这两个情结做了各种各样的努力。
先说向外恐惧情结。早就有人指出,瑞士高地德语里面有不能用上下文无关文法描述的语言现象。其实,在涉及到“分别”的表述时,汉语也同样。比如:“张三、李四、王五的年龄分别是25岁、32岁、27岁,出生地分别是武汉、成都、苏州。”这里“张三、李四、王五”构成一个名词列表,对这类列表的一般性句法表述,肯定是不定长的,但后面的两个“分别”携带的列表,虽然也是不定长的,但却需要跟前面这个列表的长度相等。这个相等的条件,上下文无关文法不能表达,必须走出第三圈围墙。
再说向内求全情结。追求“线速”的努力,在NLP领域一直没有停止过。从允许预读机制的LR(k)文法,到有限自动机堆叠,再到基于大型树库训练出来的、最终转化为Ngram模型(N=5甚至更大)的概率上下文无关文法分析器,甚至可以算上统计阵营里孤军深入自然语言深层处理的RNN/LSTM等等,都试图从2型文法中划出一个既有足够的语言学意义、又能达到线速处理效率的子类。可以说,凡是在与统计方法的搏杀中还能活下来的分析器,无一不是在某种程度上摆脱了向内求全情结、在基本尊重语言学规律基础上尽可能追求线速的努力达到相对成功的结果。这个经过限制的子类,比起第三圈围墙来,是大大地“压扁”了的。
如果认同“一切以真实的自然语言为出发点和最终落脚点”的理念,那就应该承认:向外有限突破,向内大举压缩,应该是一枚硬币的两面。我们希望,能够有一种形式化机制同时兼顾这两面。也就是说,我们理想中的自然语言句法的形式化描述机制,应该像一条穿越乔家大院的“毛毛虫”,如下图所示:

据笔者妄加猜测,这样的“毛毛虫”,可能有人已经找到,过一段时间自然会见分晓。
from http://blog.sina.com.cn/s/blog_729574a00102wf63.html
【相关】