《AI 随笔:从对张医生的综述抄袭指控谈起》
网友爆张文宏医生博士毕业论文涉嫌抄袭,有图有证据。这是最近闹得沸沸扬扬的大事件。主要是张医生在疫情期间由于言论大胆独特而成为争议人物。爱的爱死,恨的恨死。张黑要掘地三尺,粉丝要誓死捍卫,背后有许多社会学的因素在。但这不是我考察此热点事件的角度。
我的角度是AI,得出的结论是,综述抄袭的指控跟不上时代了。随着AI语言模型的进展,不仅是对张医生,对任何人的综述抄袭的指控很快就会无效。 改写别人写好的综述,经过机器变换算自己的,实践中是无法从技术上做抄袭指控的。
目前学术界的要求是综述的文字必须是自己的文字,可如何定义“自己的文字”呢?说到底就是不要被目前“查重软件”揪出来就算自己的了,那简直不算事儿。除非把“自己的文字”定义为必须符合这个个体一辈子文风的平均值,这一点虽然技术上是可以想象的,但没有意义。最终,人还是要拼内容,而不是拼形式。而现代的技术可以某种程度上做到把内容与形式分开。
举报说:
张文宏论文第79页至82页,从被抄袭文章的第一节开始全文照抄,只是去掉了小节编号。
这是据举报的张医生综述抄袭的第一页:

把它自动转成 text 如下:
kat6 基因是 MTB 染色体中的一功能区段,虽然 MTB 全基因序列目前尚在研究中,但 katG 基因的结构已很清楚。它的上游相隔 44个碱基与 furA 基因相连51,下游相隔 2794 个碱基与 embC 基因相连,应用 kpnI 限制性内切地MTB INH 教感标准株 8 Rv 进行消化后,得到一个大约 4810bp 的 DNA 片段,它作为开放可读框架存在被分析时,具有高度编码概率价值.KatG 基因就位于该片段的第 1979 - 4201位,全长 2223bp,其中 A428bp,C696bp,C740bp,T359bp,C+C 占64. 6%。将此片段转玉到一个能在 500hg/ml INH 中生长的耻垢分支杆菌 ML, smegmatis) 中,结果使后者获得了对 INH 的敏感性 (MIC为 8- 32hg/ml ),而对其他药物的 MIC 不变,证实了此 DNA 序列确是katG基因,它与 MTB 对 INH 的耐药性至直接相关0加。Cooderill以及lin 等对MTB 的 ATCC25618 株的 katG 基因含圾 2223 个核巷酸,除了第 700 位一个碱基由乌嗓叭取代了胞喀喧【它们的产物均为甘氨酸] 之外,与 RY 株的核苷酸种类和顺序都是一样的,但当他们对MTB 的 HRv-MC 株和 ATCC27294 株进行 kat6 基因分析时,则发现它们与 HRv 株的 katG 基因序列至少存有 16 个破基的差异,因此,在进行 katG 基因的研究,选择 MTB 标准对照柏时,应充分考虑不同菌株间基因差异的可能性, 尽量选用通用的标准析 HRv 株。 在对 katG基因进行分子学检测,尤其名聚合醇馆反应 (PCR ) 或 DNA 杂交检测时,其引物和探针的设计应尽可能地各开 kat6 的变异区域。
kat6 基因的同源性和功能
许多微生物都含有 xatG 基因,它们与 MTB 基因有较高的同源性-Heymiy直等用一个找带着来自 MTBkatG 基因的探针进行杂交分析,,结果 MTB H Rv 株和麻风分支持菌等 6 株分支杆菌均可见有亮度不同的杂交带,应用氨基酸序列分析显示,MTBkatG 基因编码的过氧化氢- 过氧化物酶,与胞内分支杆菌、大肠杆菌和沙门氏菌、和芽孢杆菌属的嗜热脂肪杆菌编码的过氧化所 - 过氧化物酶,其氨基酸残基符合率为 60% 、53. 3% 、45.7% ,与来自啤酒酵母菌的细胞色素 5也有部分同源性,表明 kat6 基因的分布是非常广泛的。Kat0 基因编码产生 hene-conting 酶,也称为过氧化气 - 过氧化物酶,醇分子量为 8000,在细菌的氧化代谢过程中发挥重要作用。虽然 katG 基因广泛存在于其他微生物中,但众所周知,INH 通常只对 MTB 野生株有效,MIC 多在 0. 02hg/ml1; 对绝大多数的其他分支杆菌的效果就......
我们用seq2seq语言模型自动改写试试:
kat6基因是MTB染色体中的一个功能片段。虽然MTB的整个基因序列仍在研究中,但katG基因的结构已经变得清晰。其上游相隔44个碱基与furA基因51相连,其下游相隔2794个碱基与embC基因相连,用kpnI限制性内切酶MTB INH教义标准菌株8 Rv进行消化后,得到约4810bp的DNA片段,当以开放可读框分析时,编码概率值较高的KatG基因位于该片段的1979-4201位,全长2223bp,其中A428bp,c6996%.将该片段转化为能够在500hg/ml INH生长的耻垢分枝杆菌ML,导致后者获得对INH的敏感性(MIC 8- 32hg/ml),而对其他药物的MIC没有变化,证实该DNA序列确实是katG基因,其与MTB对INH的抗性直接相关。Cooderill和lin等人的MTB ATCC 25618株的katG基因含有2223个核酸,除了700位的核苷酸被Wusangpa取代(他们的产物是甘氨酸)外,核苷酸类型和序列与RY株相同。然而,当他们分析MTB HRv-MC株和ATCC27294株的kat6基因时,发现它们与HRv株的katG基因序列至少有16个片段差异。因此,在研究katG基因和选择MTB标准参比柏树时,应充分考虑不同品系间基因差异的可能性,尽量选择通用标准HRv品系。在katG基因的分子检测中,特别是著名的聚合酶链反应(PCR)或DNA杂交检测中,引物和探针的设计应尽可能分离kat6的变异区。
kat6基因的同源性和功能
许多微生物含有xatG基因,与MTB基因具有高度同源性-heymie等人使用携带MTBkatG基因的探针进行杂交分析。结果显示,6种分枝杆菌,分别为MTB H Rv株和麻风分枝杆菌等。,具有不同亮度的杂交条带,氨基酸序列分析的应用表明,MTBkatG基因编码的过氧化氢-过氧化物酶与芽孢杆菌属的胞内分枝杆菌、大肠杆菌和沙门氏菌以及嗜热乳酸杆菌编码的过氧化物酶的氨基酸残基符合率分别为60%、53%。分别为3%和45.7%。与酿酒酵母细胞色素5的部分同源性也表明kat6基因的分布非常广泛。Kat0基因编码产生hene-conting酶,也称为过氧化物酶,其醇分子量为8000,在细菌的氧化代谢中起重要作用。尽管katG基因广泛分布于其他微生物中,但众所周知,INH通常仅对MIC大于0的MTB野生菌株有效。02hg/ml1。对大多数其他分枝杆菌的影响是......
以上是全自动改写版本,免不了有瑕疵,但是意思应该接近。对于专业人士,在机器辅助生成的基础上做一些必要的后编辑是自然而容易的事情,基本上就是通读一遍,顺它一顺就行了。
不知道“查重软件”能不能发现改写版本是抄袭的文字?不知道如果经过软件自动改写以后的综述,还会不会陷入“综述抄袭”的指控?
指控的抄袭对象的原文也附上作为比对:

搞不清楚在张医生毕业的年代,科研规范的平均水平如何,关于科研规范的教育和风气如何。
在我们入行的80年代,我知道是没有什么严格规范的,论文中只有极少数留洋归来的人才遵循国际规范,每个该有出处的地方都会注明。大部分论文,包括我的导师辈的权威们的论文,大多不严格注明出处。只在论文最后,有个【参考文献】列表,但这个列表与论文没有 coreference,根本搞不清哪个部分是哪个参考文献来的,哪个部分是原创思想。当时我们觉得这就是论文该有的样子。所以,如果以现在的规范回去检查80年代的论文,可能会打倒一大批名人,甚至泰斗。我说的80年代某些领域不规范,是指的引用出处不规范,不是说抄袭。导师辈论文其实很多干货,但是还是有很多引用不规范的问题。当时的圈子没人意识到这是不规范。那还是中国学术圈与国际学术圈没有接轨的年代。很多事情都有个时代局限性的。
当然,张医生的年代应该大有改进,与国际学术规范开始接轨了。但现在与20年前到底改变多少,不得而知。就事论事,我相信按照现在的注定短命的学术规范看,张医生的确是抄袭了。这种综述抄袭在当时(上个世纪末)估计是个有一定普遍性的问题?
什么是现在的学术规范?对于综述(或科普),对抄袭的理解是,文字相同就算。如果idea一样,文字不同,不算抄袭,因为综述和科普都是介绍别人的工作,而不是自己的原创思想。
这个标准貌似有理,但我想指出的是,这个标准落后于时代,已经难以为继了。
因为 AI 领域有一种东西叫“生成语言模型”,最著名的要算是 openAI 推出的 GPT-3 与国内华为等多家研究团队协作推出的“盘古”,二者都是超大规模的语言模型。
GPT-3 参数高达1750亿,据传光训练更新一次模型,就需要两千多万美元的投入,这是AI领域的核武竞赛似的算力和算法的大竞赛。盘古模型有千亿参数,训练数据量也是天文数字,高达40TB,是全球最大的中文语言(NLP)预训练模型。在生成文本时,这类模型非常强大。生成的文本与人类生成的文本从形式上看是难以分辨的。除了辅助写作(包括改写 paraphrase)外,这类模型最大的特点是真正解决了 open-domain 的问答难题,它们所涵盖的知识实在太大了,远远超过曾经名噪一时的打败人类的IBM沃森问答系统。
关于综述抄袭的问题,过去是不规范的问题;将来也不是问题,因为可以利用NLP模型来改写。过去与将来之间才是问题。综述内容相似,说法必须不同的要求,要用自己的字句组织来表达类似的内容,有了AI语言模型的助力,不会成为问题了。特别值得强调的是,生成模型的本质具有随机性,因此同样的内容trigger出来的生成品从字面上看每次都不相同,根本无法查证最终结果来自机器还是人,还是二者的协作。将来对于综述的规范标准势必要改,不能是查字句的相似度。除非是说综述也要求内容完全不同:这怎么可能呢?既不能查内容,也不能查字句,到底综述还能不能确立标注都成了难题。虽然理论上讲,综述是需要功力的,能反映一个人对学科的宏观理解和最新进展的把握,但是制定可以执行的规范标准,可能是一个巨大的挑战。
道理上可以从综述的段落组织、逻辑线条等角度去要求不同,但总是越来越难于量度,无法 enforce,也难以服人。也许未来最终的结果是,综述文章不算发表,至少比原创要打个折扣。将来让机器做综述,让专家做一点后编辑,可以批量而及时地生成种种综述,也不是不可想象的。
有老友说:综述是指对一个领域一个时期的工作的综合评述,并指出当前热点,存在的关键问题,今后的发展方向。在好的刊物,通常是邀请行内权威来撰写的。学生改文字不改结构,还是算抄袭。即使结构改了,不加引用地叙述某个已发表的观点,而且逻辑相似,还是算抄袭。
道理是如此,可是怎么落地执行呢?怎样定义综述的结构是抄袭的呢?而且如果避免了文字雷同后,谁有精力去查对、指控 并且可以证实这种指控而且服众呢?没有可行性。
现在 GPT-3 故意神秘兮兮的,说不敢公开发布,怕模型被滥用、误用或恶意使用,譬如用来制造机器水军。但是武器已经造出来了,怎么挡得住人们的使用呢?如果只有部分人有使用特权,其他人排除在外,这不是在滥用之上又增加了一层不公平么?
而且的而且,一个有 access 的人使用模型生成了结果,结果本身是没有追踪痕迹的(除非带上区块链 LOL)。这是生成模型的随机性质决定的。
小结一下:现在看重的所谓综述抄袭的学界标准很快就会跟不上时代了。因为世界上没有什么“自己的文字”才算原创,内容重复不算抄袭这码事儿。现在的同学不会那么傻和懒,他们其实不费吹灰之力就可以利用电脑生成,来规避这个综述文字抄袭的指控。这项指控不久将来估计就会成为历史。
重要的是他的论文本身的含金量,到底如何,外行无从知道。而当前的综述抄袭是软件和傻子都可以挖掘的。同时,用语言模型以毒攻毒,如果学界规矩不做改变,综述抄袭将来连权威都难以做实指控了,更不用说naive的“查重软件”了。也可以换个角度来看这件事:在没有电脑和打印机的年代,我们中小学交的作业都是手写的,那么字写得好看可以加分,不好看减分,也就是理所当然的明规则或者潜规则了,虽然字好看不好看纯粹是形式,与内容没有一毛钱关系。现在还有老师批改作文的时候考虑字的好看与否吗?你想这样做也没条件了,大家都是电脑交作业,好看程度拉平了。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2021)
《李白梁严127:神经的要害在数据瓶颈与定点纠错盲区》
李:我觉得,神经的要害在数据瓶颈与定点纠错盲区,而不是非符号化或可解释性。
这几天在琢磨可解释性的问题。可解释性与性能是两码事,道理上,产品讲的是性能,可解释性最多算是客户友好,让人感觉舒服一点而已。(可解释性的基础是与用户共享的符号系统。不共享的符号也不具有可解释性。这就好比我买了个吸尘器,你给了我一份我不认识的外语说明书。或者接待我的客服以为我是日本人,叽里呱啦跟我说了一通,没带机器翻译的话,虽然也是符号系统,对我是完全不具有可解释性。)
好,回到NLP。
我们追求NLP系统的可解释性,好像是说,程序做什么、怎么做的,算法背后的那条逻辑线索,你需要让我明白,否则我不舒服。这实际上有点强“机”所难。说老实话,就是设计者本人,如果系统变得复杂了,也很难总是搞明白算法的每一个逻辑线条,更遑论对用户解释了。如果容易搞明白,也就没有 debug 的繁难了。
严:可解释性,是指从输入到输出的推理路径可显示,而不是算法自身。
李:输出是输入的函数。可以脱离算法来解释吗?路径不是算法的产物或表现?
感觉粗线条的可解释性 目的是为用户友好。细线条的可解释性不可行 也没意义 很像一个伪问题。
特斯拉为了这种用户友好 不得不花力气在屏幕上显示机器 “看” 到了什么物件。用户见到机器看见了障碍物,障碍物渲染的图片越逼真,心里就觉得越心安。如果机器没看见,屏幕上没有那个障碍物,就不放心。但是从看到环境中用户聚焦的物件到驾驶决策,路径很长也非确定性,可是人的这种心理需求不能不照顾。
我的主要意思是说,应该把开发重点放在“用户友好”范畴下的可解释性上,而不是一味追求过程的透明性。
接着“神经网络短板”的话题讲,迄今为止,神经网络基本上不能落地领域,在NLP领域场景无所作为,这是基本事实。原因也很清晰,就是绝大多数领域场景应用,只有 raw corpus,缺乏或根本就没有大规模带标数据。神经网络无法做无米之炊。于是给符号路线的冷启动应对留下了空间。
白:不能落地是因为没有带路党,而带路党很可能切走很大一块蛋糕。
李:冷启动就是一种带路党。
白:带路党不需要懂符号,只需要懂客户。带路党可以把数据补完全。
李:神经网络主流认知把带路党简单定义为标注,然后就撒手不管了,大不了就是砸银子 找成百上千的标注大军去标注。我可以对任何领域一窍不通 也一样做领域的应用。这个策略对于可以简单明确定义任务又有资源标注的场景,的确是普适的。
梁:数据只是说“有”,没有说“无”,that's the problem
李:这也是那位挑战神经网络的老教授的口头禅。来自数据的知识不全,完成不了认知理解过程。
白:没有的数据你怎么标注?
李:说的是NLP,没有数据就没有NL对象了,哪里有 P 的问题。
白:带路党可以让数据从无到有,所以,挑战毫无意义。带路党牛就牛在他们是活的数据,我觉得老教授在用一种外行的方式挑战内行。
李:老教授对机器学习很了解,不是外行。传统机器学习肯定做过很多,大概没亲手做神经网络研究,但总是拿别人的神经系统“玩耍”。他不是看不懂神经奥秘,而是认知定位决定了他的批判角度。想起来毛说的知识越多越反动。老教授涉猎太广,知识太多,反而牵累了他。
白:王朔书里的小混混在街上喊“谁敢惹我?”一个人高马大的主儿过来说:“我敢惹你。”混混马上搂着人高马大的主儿说:“那TM谁敢惹咱俩?” 我觉得,老教授应该向小混混学习,混成“咱俩”之一。否则啥也不是。
李:有时候做一个事儿,少一点知识也许更加有利,无“知”一身轻。现如今做NLP的后学,连语言学基本教程也不看的,为多数。今天的气候,这显然不影响成为NLP专家。今天是NLP专家,一转身就是图像专家,再转身就是华尔街金融模型专家。神经网络横扫专家的架势。
白:这是落地之前,落地时不是酱紫滴。落地时有太多不适应,当然跟缺数据有关,跟缺知识不直接有关。知识不能直接变成缺失的数据,知识处理的工具也无法拿来处理大模型已经消化了的数据。
李:话说回来,缺乏专业知识也不是长久之计。前面提过的那个NLP后学 傻傻地问 it 为什么跟形容词 wide 那么强相关,就是因为缺少语言学的常识。词与词相谐是普遍的,绕一个弯就糊涂了,不是语感差,而是基本专业知识不够。
白:长久之计就是语言学知识和带路党深度结合,不着痕迹地把语言学知识灌注在带路党的工作环境之中。
梁:其实,我们能够交流,我们共现于同一个时代,那就是我们已经共享很多知识了。
李:这也是老教授立论的基础,共享的知识是理解和认知的外在前提,不是数据里面的东西,因此光靠数据是不行的。
还有个有意思的发现,密集听了一批最新神经网络的讲座,发现用的最多的几个词是 meaning / information,这就是共同语言了。句子来了,embedding 转成 vectors,vectors 在里面做种种变换计算,就成为 meaning (的载体)了。从 information 的流向和处理角度来看,vectors 对于 information 的各种处理空间大,灵活度高,里面可以有足够的余地尝试各种信息叠加、抵消、门槛等等操作来验证效果。
相比下来,符号基本上是 1-hot coding 的表示,处理 info 就远远不如 vector 的高效和灵活。Not even close,实际是天壤之别。符号主要的好处就是用户友好,看着似乎容易懂,“感觉”比较容易掌控。另外一个好处就是,符号可以外加一个 hierarchy或图谱,进行透明的“过家家”一般的逻辑推理。
白:符号带优先级不就行了?
李:优先级如果是离散的少数参数的调控,也不好敌大数据落地训练出来的种种 weights。
白:符号外挂啊,瓤还是神经。
information一万个人有十万个定义,躲着走为妙。
李:还好啊,反正有个信息论的精确定义做底,信息也是现代物理的基本对象。虽然讲的时候不一定按照数学定义来,但多数人觉得自己的定义离开它不远。
白:用到语义的时候,怎么着都不对味儿。
李:在讯飞的时候,与同事大牛讨论过,我说你的神经网络是个黑盒子,同事说,我觉得一点也不黑。现在比较理解他了。你可以说具体的参数和权重 难以从细节上一一说明白含义,但是总体上的逻辑线条对于设计者是相当透明的。很多时候 学到的巨大的向量表示看上去难以理解 只要结果对了 就不去究竟了。但是真要做一些用户友好的符号化翻译或可视化努力,可解释性是可以不同程度显示出来的。这些都是聪明绝顶的人,模型绝不是瞎撞出来的黑盒子。所以 可解释性作为一个批判要点,更多是从用户友好层面来说 说他们做得不够 还有些道理,而作为对神经系统的总体批判 有失公允。
与其批判机器学习“欠缺可解释性”,不如批判“难以定点纠错”,后者对于大型工程的确是个痛点。
白:外挂可以解决定点纠错问题。批判它干啥,你带路党悄悄把外挂做了,啥都有了。
李:例如,我用自动驾驶每次在相同的几个地点 总是犯错 莫名其妙刹车,我没有办法让特斯拉去做定点纠错,你就是把这个问题录频了 n 次反复提交上去,然后每两周一次软件更新,你盼啊盼,多数时候你的 bug 是泥牛入海,永无改期。这也不能怪特斯拉,它只能收集规律性问题,然后扩大训练,希望下一个 release 整体好一些。客户个体的痛点他不仅是没时间照应,而且也没有有效的办法去定点改正。
【相关】
《李白126:神经 attention 机制搞定代词指代的案例》
李:看到 attention 机制一个图示:

这可算是 attention 机制可视化以后,明确显示其解决了 pronoun coreference 的难题。看前后两句 it 与 animal 和 street 的关联强度就明白了:
1. The <animal> didn't cross the street because [it] was too tired.
2. The animal didn't cross the <street> because [it] was too wide.
这只是过程中其中一幅 attention 的图示化,图中没有显示其他两两 attentions 的图示(包括 it/animal/street 与 wide/tired 的两两关联度),看完就知道形容词(wide/tired)与 host noun(animal/street)之间的相谐性,是如何对 it 的 coreference attention 的影响力了。
这种两两配对的机制 简直令人发指地有效 而且有解释性,也不怕爆炸,反正所谓 multihead self-attention 机制都是可以并行计算的,大不了多上GPU,费些电而已。
白:怕不怕干扰?
李:不知道 不过就看到的这个结果,已经让人嫉妒得咬牙。好玩的插曲是,下面留言貌似还有个“理呆”傻傻地问:老师 为什么 it 与不相干的词 wide 有很强的关系?这位学生理解了 it 与名词的关系 却不能理解与形容词的关系,哈。
白:我们的观点是,it与其所指建立关系时,会把所指的本体标签复制到it这里来,然后跟tired/wide检查相谐性就是邻居之间的事情了。飞线不是白拉的,是有本体标签输入的。
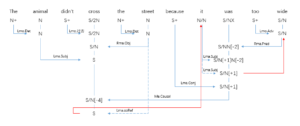

特别是,飞线的建立,是在各个chunk内部的萝卜填坑都搞定的情况下才会发生。而内部填坑就意味着,it的分子萝卜已经被chunk内部的坑所同化,不相谐的百毒不侵。相谐的一路绿灯。
李:感觉是 如果句子处理满足下列条件,能穷举两两关系 而且有足够数据训练去计算这种关系,那么我们引以为傲的结构,其桥梁价值就会趋近于零,因为位置信息加语义相谐的 attentions,应该可以搞定这种 hidden correlations。这样说来,attention is all we need 即便从字面上看 也说的不错。
自然语言说复杂也复杂 但说简单也简单。简单在于,有无穷无尽的语料,预训练可以发掘很多语言知识。到下游应用的时候 单位开始变小,小到一句一词 大也不过一篇文章 对于 attention,这都不算事。(也有人现在尝试把 input 扩大到一组文件,来做跨文件自动摘要,结果也让人开眼)。
白:NN容纳了结构,正常。
李:可几年前,我们是不相信神经系统可以搞定 long distance(hidden) correlations 的,当时觉得非符号结构不能的。这个不服不行。
白:
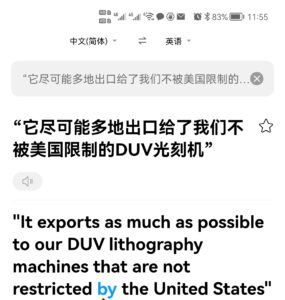
在这个模型看来,光刻机是“我们的”了。其实是“它的”。“我们”的间接宾语角色没有被揭示出来。如果没有那个“给”,这一切本来都是说得通的。
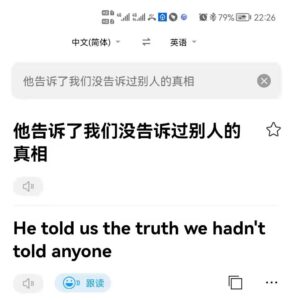
谁没告诉别人?
李:是 he,不是 we。嗯,这两例的确没搞定,也更 tricky 一些,有间接宾语干扰项。再等两年,等最新机制和方法慢慢渗透消化部署到商用神经翻译系统后再看看搞定了多少。总之,总体方向上是向好的,我觉得。越来越多的“非低枝果实”正在被神经吞噬,一个幽灵在地球徘徊......
【相关】
《AI 随笔:观老教授Walid的神经网络批判有感》
昨天在 YouTube听了一个数小时的批判深度学习的小圆桌会,有点意思:
NLP is not NLU and GPT-3 - Walid Saba (可惜国内需要翻墙才能看youTube,我截屏如下)
是三个名校中青年学者对一位学富五车的老年教授,大家抱着尊重老专家的尊敬之心,与这位批判者深入交谈究竟神经网络的短板在哪里。
Walid 教授对于领域一边倒极为不满,凭着他对于电脑科学(早年好像是伯克利电脑博士)、传统机器学习和现代神经网络、符号AI、心理学、语言学等多学科的了解,讲述自己对于所谓 Bertology(就是 Bert 这类神经方法论)的批判,他的博客也有系列点评和批判。他是真有学问,所以批判中不时有闪光金句和洞见,但总体而言,说老实话,他的批判显得无力。
说来说去 他批判的焦点就是 embedding 词向量这样的数据结构虽然是伟大的发明 因为语言单位可以做各种信息计算了 但是说到底会遭遇无结构的天花板。他所谓的结构 不是指的文法结构 而是说 向量本身算来算去 无论求和 求product 还是 concatenate 这些信息操作的结果 他认为还是平面的 没有结构的。最终无论模型多大,也只是对于语言数据中可以观察到的词与词之间的某种角度的 similarity 计算而已,尽管可以捕捉语言中的 long distance dependency。
但是 语言理解有两个部分,他说,一个是说出来的 可以观察到的部分 一个是没说出来的脑补的 “我知道你知道(I know you know)”的部分。二者缺一不可,但是纯粹通过大数据训练的模型没办法得到后者,因此是跛脚的。
这个论点有其闪光之处,但是他说的太绝对了。
所谓数据里面学不到的后者 听了半天就是指的某种 ontology(本体知识),他有点遮遮掩掩,说自己几十年探索的最新创新还不想马上公布于众,又忍不住说其实就是一个 type ontology,并不复杂,规模也不大,2000 个基本概念,是四岁儿童都具备的先验知识。这其实就是 HowNet 的头部 features,也是 Longman 词典中用来定义所有词汇的大约 2000 基本词汇的某种映射物,他也许会有些不同的组织方式,不会相差太远。
总之,这些基本概念或 types 所构成的常识(他称 type checking,和 type unification)在语言理解中一直在下意识中起到脑补作用,否则人类的交流难以进行。既然人类是这样利用二者理解和交流的,电脑单单凭借大数据怎么可能模拟人类的语言能力呢?
我来批判一下他的批判(其实三位后学中的一位也不断礼貌地在反驳他的系列批判)。
蕴含常识的基本ontology确实有脑补作用,这个我们在白硕老师的语义计算群讨论过的无数案例中都有体现,但是铁口说这些东西是不可能从大数据学出来的,感觉偏差很大。他举例说 want 需要的 agent 是 human,这是四岁小孩子都知道的常识。其实大数据里面这种主语谓语的 type correlation 太普遍了,不可能不在大数据(预)训练中反映出来。
他还举了两个图片的例子,一个是女老师辅导学生的照片,一个一家三口的全家福,他说这两张图片的数据本身是没有区别的,都是成年人与孩子在一起的合照。他挑战说,因为数据本身没有区别,所以系统学不出来前者是辅导员与学生 后者是父母与孩子的关系。这个笑话闹大了 因为后学马上把两幅照片输入谷歌图片理解系统。结果是:第一张图 tutoring 的概率最高,第二张图 family 概率最高。
他实际上是犯了同样的错误 他以为数据中不存在的某种知识 其实在大数据的雷达上是有反映的。如果是小数据 可能的确找不到区别性特征或规律 数据大了就不同了。老教授这时候不得不说 你不能拿我举的个别案例说事,总之是有一种数据里面不存在的知识在起作用。这么说自然也有一些道理 但是感觉他批判的力度太弱,而且留给自己的批判空间也越来越小了。
说他有一点道理 是说大数据即便学出来常识 这些常识也是支离破碎的 没有内部的组织性和严格的结构 hierarchy,学出来的 onology 和人头脑里的 ontology (以及语义学家精雕细琢的ontology模型)总是有区别的。这一点需要承认,但很难说在语言应用现场前者的效果比后者差,本体知识与其他知识一样最终还是要落地的,要以落地赋能效益作为最终衡量。
他还举了一个有意思的例子,他说大学校园(campus)与大型商场群(mall),从物理角度观察几乎没有区别。但是人类的认知很容易区别二者。既然没有物理区别,机器怎么能够区别它们?这实际上是 tutoring 与 family 的放大版,实际上也经不起质询。二者的区别即便在物理层面也还是有蛛丝马迹。
总之,老教授的道理越来越难验证,他费了很大力气找出来的批判反例,其实大多不能构成神经网络的真正挑战。
他还举了一个 product 的例子,他说人类的ontology中有 product 的概念,可是千差万别的几乎任何东西都可以是 product,数据中怎么能区分这样的概念呢?人怎么认知的呢?人是把 product 与 manufature(制造) 结合起来的,“制造”的结果/宾语 就是 product,不管结果如何不同。同理,teacher 这样的概念离不开 teaching,先有 teaching 才会有其 agent 来做 teacher,形成这个概念的 type。这样的先验知识 他认为纯粹数据是学不出来的。因为学不出来 所以需要用到这种知识的认知理解过程 神经网络就是无能为力的。
总之,不能说他的批判完全没有道理,但是力度很不够,不足以批判神经系统的潜力。有些知识目前的神经系统也许没有捕捉,因此表现不出来,但很难说以后就没有。关键是,坚持 ontology 只能先验,不能反映在大数据中,这个论点是有问题的。常识在个例中通常是不说的,人吃饱了撑的,不会总是说出来人人都知道的常识:人要吃饭;枪可以杀人,等等。但是既然是常识,大数据的趋向中就会有反映,而捕捉这种趋向,是多维度的向量空间的拿手戏。常常是系统其实捕捉了,但因为向量表示如果不做可视化的用户友好努力,不变成人可以理解的符号或图示,我们不知道模型已经捕捉了。
他的有道理之处可能是在常识的深度推理、长链条的推理方面,目前的神经架构纯粹靠大数据可能局限于框架而学不出来,也用不起来。但大数据深度学习是一个进展变化迅速的上升领域,今天的无能就是明天的突破口,很难说推理这条路它一定跨不过去。这就好比几年前我们都觉得 coreference 和其他篇章的关联,神经网络应该是无能的,直到今天我们亲眼看到了神经系统在篇章方面的成就,这才改变成见。
这才十年左右的功夫,从CNN,到 RNN,到双向RNN,到LSTM,到 transformer,到各种 attention机制,深度学习的进步让人眼花缭乱,而每次进步都是真实可测的。以前看不上所谓的 transfer learning,觉得有点不实在,但超大规模预训练落地以后,产生了GPT3和盘古这样的庞然大物,NLP方面的 transfer learning 一下子变得触手可及了。今后几年这方面可以预见有越来越多的应用实践出现。
老教授还反复质问:心理学家、语言学家、逻辑学家这么多学者这么多代人艰苦探索语言和思维的奥秘,做了那么多的工作,难道这些人都是做无用功吗?你凭着大数据,一招打天下,只靠神经网络就搞定了人类认知?come on,give me a break
这种质询诉诸感情大于讨论问题,没多大意义。不同的路线和方法论虽然理论上不可能完全覆盖和超越另外的路线和方法论以及先贤,以此说一边倒对科学发展是不健康的,盲目迷信神经网络是不智的,两条路线可以取长补短,这些道理都没问题,但是以此来挑战新方法 还是需要拿出更加实在的立论和案例。老教授给人的感觉“虚”了些,有些倚老卖老,又有点像堂吉柯德战风车。精神可嘉。毕竟这种声音已经很少听见了,即便发声了,也很快淹没。乔姆斯基也多次批判过经验主义路线和机器学习,谁把他老人家当回事呢?都是我干我的,供着他或无视他,敬而远之。
时代大概就是这么前进的。连坚信“上帝不掷骰子”的爱因斯坦反对量子不确定性固执了一辈子,物理界还是达成共识认定老爱错了,普遍接受了现代量子理论。人不会因为曾经伟大,就可以改变潮流方向。
老教授的批判,其实还不如我们的批判深刻。我看到的神经网络的短板很简单:迄今为止,神经网络基本上不能落地领域,在NLP领域场景无所作为。
这是基本事实。原因也很清晰:就是绝大多数领域场景应用,虽然有数据,但是多是 raw corpus,缺乏或根本就没有大规模带标数据。皮之不存毛将焉附?神经网络除了预训练的语言模型以外(其实也是监督学习,只不过不需要人工标注而已,无数的语料本身就是自然标注的语言模型训练集),全部的拿得出手的应用成功都源于标注数据的监督学习。不管怎么神经,无米之炊是做不到的。于是符号路线就有了用武之地,就是这么简单。
我们可以做领域NLP的无米之炊。符号NLP在建立了平台和parser以后,就可以用“冷启动”快速结构开发来弥补领域应用的空档。无米(labeled corpus)可以,有稻(raw caorpus)就成,parser 就是碾米成稻的机器,结构就是一种通用标注,在此基础上的领域落地不过就是配置调适到最终目标,这条路经过多领域的实践证明是快速有效的。(但是,预训练也许是个竞争性威胁,在此基础上的 transfer learning 可能是个领域落地的替代品。我们当翘首以望。)
往深里说,除了带标数据的知识瓶颈外,老教授提到的外在知识,譬如领域知识图谱,等也是一个因素:不能说大数据完全学不了,但学得不系统不完整链条没有深度和结构的确是目前的神经局限。
关于领域场景冷启动,可以从我们最近的电力场景知识图谱的实践得到一些启发。这个落地尝试我体会特别深。那真是冷启动,比冷还要冷,是冻启动。平常的冷启动,产品经理至少还能给一个 完整的 specs,里面给出领域知识抽取的样例,定义的每一种类至少给一个 input-output 对照的例子,作为种子去启动冷知识的开发过程。
回顾一下背景,电力NLP落地一直想做,但觉得很棘手,主要是行业太深,看不明白。而客户自己也说不清楚需求的细节,只是感觉有必要首先把这个场景的知识学习出来才好。这次是我们自己与电力客户做沟通了解,我们的一位 leader 临时充当产品经理的角色,给了一个电力图谱的初步 schema 设计图,有原始文档作为参照,完全没有时间去做例示化 specs 定义。我们要自己消化去启动知识工程。等于是把产品经理的任务转移到我们开发人员了。几天后做出的结果与做知识融合的后处理模块开发人员接口。知识融合需要做一些 dirty work,不仅仅是应对NLP抽取的碎片化知识结果,同样要应对半结构化表格抽取出来的碎片化结果,这个过程所化的时间远多于NLP冷启动抽取(现在看来语言parsing和抽取不是真正的瓶颈,后面的融合目前是瓶颈,这方面我们需要一些时间抽象和总结,来提高平台化的融合能力)。不久,做出来的图谱原型看上去有模有样,符合 schema 的设计要求。
电力领域的数据很各别。这与我们以前尝试过的金融文书、法律文本完全不同,因为金融法律虽然是领域风格的文字,但读起来与新闻类还是有不少类似的地方,起码外行也能大体读得懂,因此消化理解图谱里面的关系,心里感觉有谱。可是到了电力,虽然其实行文很规范(没有风格,完全的机械性文字表述,力求精确),但是没有领域基本知识,很难看懂,无从下手。
刚拿到薄薄的一页 schema 设计图,也是一头雾水,一组抽象的概念连接起来,到底想表示什么领域知识呢,不确定。但是几个小时对着原始文档的对照讲解和讨论,很快就冰释了这个领域知识的壁垒,有点豁然开朗的感觉。
说这是一次奇妙的NLP领域落地的产研经历,是很真实的感受。今后遇到其他暂新的领域,也不要被表面的“黑话”形式所吓倒。只要冷启动的方法论过硬,感觉困难的领域知识理解问题,也许实际落地操作层面就是一层没有捅破的窗户纸。
我们主打的RPA(Robotic Process Automation,机器人过程自动化)是普适的,可以触达各种各样的不同领域场景。由此带来的更加“高深”的领域知识抽取任务就会五花八门。这拓展了我们对于不同领域数据的视野。方法论和NLP平台的威力和意义就在于,任你千变万化,万变不离其宗。这个宗不仅仅是指背后的语言结构(这个高深一点,培训难度也大一些),也包括从原始数据自动做领域词汇习得(关键的一环)、上下文约束机制(线性的、结构的,线性的约束比较简单,能很快培训一线人员做低代码开发)、多层松绑机制、冷启动质量保障控制流程(没有大量标注数据也可以对精度和召回做系统性控制)等一系列配套工具,这些就是可以普适的NLP的平台工具。
这样的零标注数据的领域场景,神经纵然三头六臂,奈其何也?
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2021)
《成长花絮:小鬼子成为共产主义者》(留存)
《成长花絮:小鬼子成为共产主义者》
屏蔽 |||
陪女儿研究马克思主义
早上起床,甜甜告诉我:Dad, I had a weird dream. The last sentence I remember saying to somebody is:
"If there is anything that I know, communism is for you."
看来,这个学期学世界历史,甜甜是对共产主义学说着迷了。
前几天,女儿回来告诉我,说她的世界历史课程要求介绍一位历史名人,其他同学有选卢梭、拿破仑、教皇保罗二世等,她选的是卡尔马克思,要求我帮助她了解马克思主义。我说那没问题,我从小就学习马克思,谈马克思主义如数家珍。女儿说,首先要了解马克思的生平事迹,然后主要是介绍马克思对下面两个问题的论点:马克思怎么看人性?马克思怎么看政府?
马克思的人性论,我这个当年的学马列小组积极分子也不大了解。人性在我们的少年时代是塔布(taboo),学习马克思也要绕开它:当年我们强调的是阶级性,而不是人性。改革开放以后,在老邓发动反自由化之前的思想解放年代,曾经有过对青年马克思异化理论的大讨论,印象深刻。顺藤摸瓜,上了维基百科 wiki,发现还真有专题论及青年马克思的人性论及其异化论。马克思的生平、其他论述,包括政府,wiki 上都有很好的概述。互联网上的百科wiki是人类新技术时代的一个创举,女儿已经养成习惯了,凡事查 wiki,我也鼓励她做这类研究项目尽可能参照 wiki.
生吞活剥看了维基百科的马克思条款,甜甜对马克思佩服得五体投地,整理了不少笔记。笔记上交给老师前,必须用自己的话综述改写,这样就对有些问题需要深入理解。譬如人性,维基的讲解围绕马克思对于人的自然性、创造性以及天赋才能的肯定,反衬生产关系对于劳动者创造本性的异化,显得太过抽象。女儿问:马克思到底是说人性是好,还是坏啊?我根据自己的理解,回答说:马克思是持肯定态度的,他要说的是,其所以产生阶级斗争等残酷的事件,那是人的社会环境和地位决定的。资本家作为人,并不是生来就要压榨无产阶级的坏蛋,但是他的阶级地位决定了他必须剥削无产阶级,以追求最大利润。资本家作为人格化资本的本质,是他的资本家身份决定的,不是他的本性问题。一个无产者,无论多么善良,一旦成了暴发户,变成资产阶级以后,他一样要被异化,成为资本的代表。
女儿最感兴趣的是共产主义,说我们从小被洗脑了,以为共产主义导致独裁和邪恶,其实共产主义是多么地美好。
"we were brain-washed to believe that communism is associated with dictatorship and leads to evil. But according to Marx, communism is a beautiful society, no class. no class struggle, work is fun and not a burden, one can satisfy his most potential with his gifted talents. But why the countries experimenting with communism all failed?
"They failed for a good reason. The reason is clearly stated in Marx's works but the followers did not take it seriously. That is, an ideal society like communist needs to be supported by the maximum productivity."
女儿说:马克思了不起,资本主义太臭了(sucks),你看这两年的金融风暴,目前席卷欧洲资本主义国家的政府倒债危机,处处说明资本主义必然灭亡,共产主义必然胜利。
女儿说,我觉得我现在已经是共产主义者了,资本主义太烂,一定要被共产主义所取代(Dad, by now, I think I am already a communist. Capitalism sucks, got to be replaced by communism.)
我乐了,这话怎么与四十年前我们的信仰如出一辙呢。
http://blog.sciencenet.cn/blog-362400-496571.html
上一篇:《成长花絮: I love me too》
下一篇:《每日一歌: Savage Garden - I knew I loved you》
《成长花絮:Hi, I’m Karl Marx》(屏蔽留存)
《成长花絮:Hi, I’m Karl Marx》
屏蔽 |||
几周前,甜甜世界历史课的项目《与思想家见面:卡尔 马克思》终于完工了,接着是要在课堂上给老师同学讲演。首先,要着装成学者马克思的样子。马克思的形象甜甜很熟悉,还在她很小的时候,她就从我小时候的临摹素描中看到了马恩列斯毛,还有华盛顿(见《成长花絮第一期:学画》)。服装好办,她就穿我的长衫西裤凑合,主要是马克思的大胡子。我陪着孩子转了好几家店铺,她都不满意。幸好由于万圣节将临,湾区临时增加很多化妆店,里面充满了稀奇古怪的服饰、骷髅,当然也有面具和大胡子。最后找到的胡子倒是很像马克思,就是颜色太黑了点儿,印象中马克思是花白胡须的。我安慰甜甜说,这是青年马克思的大胡子,完全没有问题。何况你讲演中的人性主题确实是青年马克思的思想,老年马克思更加激进和革命,远离了人性的主题。

就这样,甜甜上场了,讲得激情昂扬,特别是结句“全世界无产者,联合起来!” 甜甜先是用的德语,然后用英语重复,掷地有声。受到老师的赞许。下面是讲演稿的纲要:
Meeting of the Minds: Karl Marx
Hi, I’m Karl Marx, a middle class, 18th century German scholar, who was born at the beginning of the Industrial Revolution, when Capitalism was just starting and not yet mature. There were no social welfare programs (such as healthcare or pension) or worker unions, and everything was a class struggle between the rich, Bourgeoisie, and the working class, Proletarians. My theory, Marxism, is about the ultimate government, Communism, in which the property of a society is owned by all members, and peoples’ talents are utilized to their full potential, so that people enjoy their work while working toward the common good. Capitalism is a corrupted system in which the Bourgeoisie have all the power and exploit the Proletarians, while the Proletarians are unfairly treated, wage-earning robots. Even in democracy, when people vote, they are affected by mass media, controlled by the Bourgeoisie. All humans are naturally creative and talented. So I say to you all, everyone is equal. We should overthrow the dictatorship of the Bourgeoisie, "Proletarier aller Länder vereinigt Euch!" Proletarians of the world, unite!
http://blog.sciencenet.cn/blog-362400-496578.html
上一篇:《成长花絮: I love me too》
下一篇:《每日一歌: Savage Garden - I knew I loved you》
小鬼子的马克思研究笔记(屏蔽留存)
小鬼子的马克思研究笔记
屏蔽 |||
Notes on Karl Marx and Communism
1. Bio
Karl Marx was a German philosopher, sociologist, and communist in the 18th century. He developed a famous theory, called Marxism, that fundamentally influenced the human history. In fact, Karl Marx is among the most quoted scholars in history and is one of the most influential figures of all time. His two most famous works are: The Communist Manifesto published in 1848, mainly a political statement for the communist movement, and Das Capital, a book he devoted his life to on the nature of the capitalist system. In the last century, following his revolutionary theory, there were communist movement and revolutions in many countries to form a communist group of states, led by Soviet Union in 1922 and led to the founding of Red China in 1949. However, since the collapse of Soviet Union towards the end of last century, the communist movement suffered a big retreat and even the post-Mao China turned to market economy, a system closer to the capitalist economy than the communist economy. Marx's predictions that the global revolutions will end the capitalist system in the world are not proven right.
2. Marx's view on government
Marx has a theory of social development involving 5 major social types, from lower stages to upper stages, i.e.
Primitive Communism --> Slavery system --> Feudalism --> Capitalism --> Socialism --> Communism.
He regards the capitalist government as an inhuman government which only protects the capitalists (bourgeoisie) while oppressing the working class (proletarians). He believes that despite the name of democracy, a capitalist society is in essence based on Dictatorship of Bourgeoisie. He concludes that capitalist government should be overthrown by the working class and replaced by the socialist government based on Dictatorship of the Proletariat. Eventually socialism transitions to communism when the productivity gets to the highest level. Communism is the ideal society in Marxist theory in which every one enjoys his work, which brings job satisfaction and fulfillment of his creativity, at the same time producing the products to meet the needs of all the society. In communism, there is no distinction of class, no class struggle and everything is in harmony.
3. Marx's theory of human nature:
Contrary to the popular view that human is selfish by nature, Marx thought that human is a naturally creative animal. Accordingly, an ideal society creates a condition for the whole development of human nature. But capitalism is an evil society which turns humans into wage slaves.
Marx's theory of human nature plays an important role in his criticism of capitalism and his ideal of communism. A closely related and even more influential theory of Marx is about alienation from human nature caused by the capitalist system.
4. Marx's theory of alienation
By alienation, Marx refers to the social separation of people from their "human nature" which is supposed to be decent and creative. Marx believed that alienation is a systematic result of capitalism. He believed that it is the alienation that deformed human nature, making people behave differently depending on one's social status. The nature of capitalists becomes exploiting and oppressing the working class purely for the seeking of profits. The working class becomes wage-slaves like robots working in inhuman conditions.
Only in the communism can all men gain freedom and be liberated from wage-slavery, enjoying the full nature of their creativity.
5. why he thinks that way
Marxism was formed in an age when the capitalism was not mature and there were waves and waves of class struggle and society conflicts : there were no social programs, no unions and other forms of laws as seen in the modern society. For example, there were no minimum wage law, child labor law, income tax regulations and social welfare to protect the lower working class and to balance the interests between the capitalists and the proletarians. Out of deep compassions for the lower working class who has been struggling for very basic living, and out of the anger towards the early capitalists who were after profits by forcing the working class to work long hours with very low pay and very poor working conditions, Marx concluded that the capitalist government is inhuman and will be overthrown by the proletarians and replaced by the socialist and then communist government.
Works Cited
“Karl Marx.” Wikipedia: The Free Encyclopedia. 19 Sep. 2011. Wikimedia Foundation. 21 Sep.
2011 http://en.wikipedia.org/wiki/Karl_Marx
“Marx’s Theory of Alienation.” Wikipedia: The Free Encyclopedia. 26 Aug. 2011. Wikimedia
Foundation. 21 Sep. 2011 http://en.wikipedia.org/wiki/Marx's_theory_of_alienation
“Marx’s Theory of Human Nature.” Wikipedia: The Free Encyclopedia. 22 Jun. 2011.
Wikimedia Foundation. 21 Sep. 2011 http://en.wikipedia.org/wiki/Marx%27s_theory_of_human_nature
http://blog.sciencenet.cn/blog-362400-496591.html
上一篇:《成长花絮: I love me too》
下一篇:《每日一歌: Savage Garden - I knew I loved you》
叛逆期的小鬼头(屏蔽留存)
叛逆期的小鬼头
屏蔽 |||
女儿到了叛逆期,脑后有反骨,凡事逆向思维,不仅总是与父母对着干,对很多传统认知、社会共识也很 不屑。
在学校,她在初中和高中最喜欢的个别几个老师也都是对时政冷嘲热讽的,或者特立独行的那种。其中一位大谈地球变暖是政客和媒体危言耸听,虚拟出来糊弄百姓的乌龙,女儿极为信服。
后来学历史,他选择写毛泽东。在西方的教科书和大众话语中,毛和希特勒斯大林是一类独裁者,反面人物。可女儿觉得自己被洗脑了,她要挣脱出来,一定要找出毛泽东和毛泽东时代正面的东西来写自己的作业。于是跟我谈,开宗明义,阴暗的、反面的、残暴的一面,我看到的很多,你不必谈。你专门给我列一个清单,具体谈谈毛和毛时代的亮点。我说,对于这么复杂的历史人物和历史阶段,自然是正反两面都有。你要正面的材料和论据,我就给列出一个清单来,清单的最前一条就是毛的医疗制度的革命,使得最贫困的农民得以享受几乎是免费的最基本的医疗服务(见 【老爸:毛时代的送医下乡制度】 ;【老爸:毛时代的王一千美谈】 )。
另一位教语文的老师极度自大,宣称自己永远不会错,他擅长语言结构分析,教孩子画句法图,做主谓宾分析,有语言天赋的女儿在语法分析方面是他最好的学生。后来女儿看到我让机器自动分析,再复杂的句子,也被分析出很漂亮的句法树出来,终于承认她的老师是天下第二,山外有山,还有语言学博士的老爸在他老师之上(女儿知道这位老师正业余攻读语言学硕士)。看来,逆反如女儿,也还是信服权威,我的博士头衔显然比她老师候选硕士的头衔让她相信我的语言学要高出她老师一头。女儿表明她最大的愿望之一就是,跟老爸学一手,哪天去当面找老师的茬子,证明他语法分析错了,他并不是如他自己标榜的那样伟大光荣正确。我说,这很容易,你把他的分析拿给我看,我总可以找出错误或者不合适的分析出来,但是不要指望他承认错误。文科的东西,测不准原理在作祟,并非黑白分明的。
http://blog.sciencenet.cn/blog-362400-539237.html
上一篇:看铁匠打铁
下一篇:【老爸:毛时代的送医下乡制度】
社会媒体是言论自由的天然突破口 (屏蔽留存)
社会媒体是言论自由的天然突破口
屏蔽已有 2239 次阅读 2012-5-11 23:18 |个人分类:成长花絮|系统分类:科研笔记| 人权, 突破口, 言论自由, 古巴, Yoani
[立委按]
女儿历史课要求写一篇 research paper,选取一个对社会发展有影响的当代人物或机构,论述其成就和意义。社会发展的领域包括政治、经济、教育、卫生、慈善和人权。虽然技术领域不在列表上,女儿还是选了她心目中的 传奇偶像人物 Steve Jobs,因为他 made a ding in the universe, 可以从教育或其他领域谈他的技术革命带来的影响。可是选题提交上去,没被老师批准,说 Steve 前不久刚去世,铺天盖地都是关于他生平事迹的资料,使这个选题具有不对称的优势。于是女儿转选即将上市的社会媒体巨头 Facebook 的创始人 Mark Zuckerberg,还是技术改变世界的传奇人物,结果以同样理由不得通过。
女儿有点扫兴,这两位是她读得最多,最有兴趣研究的人物,其余的人物和机构大多提不起兴趣来,少数有意思的名人如诺贝尔奖获得者南非的曼德拉和美国前副总统戈尔都已经被其他同学抢占了。想了半天说,那我就写盘尼西林的发明者弗莱明吧,说明医药的革命性突破在偶然里面包含了必然,伟大发现是预备给有准备的心灵的(prepared mind)。可是弗莱明不算当代人物,也不行。
最后老师把一个古巴人权斗士 assigned 给她了,算是命题作文。于是上网查资料,做笔记,折腾半个多月,终于写出了这篇研究文字,其主旨就是“社会媒体是言论自由的天然突破口”。特转载于后,与各位分享。虽然只是一个美国中学生的粗浅笔记,可能对转型期的当代中国也许也有些意义。
论述这篇的主题并不难,高技术支撑的社会媒体成为言论自由的平台和突破口是自然而然的事儿。除非当政者退回到前数字时代,废除互联网,任何长城都不可能完全阻挡信息的自由流通。古巴的人权英雄 Yoani Sánchez 女士抓住了时代的机遇,以其勇敢智慧和不屈不挠成为世界人权史上第一批利用技术对抗独裁的先驱之一,因此成就一世英名(以她的国际名声和影响,有望获得明后年的诺贝尔和平奖)。美国这边的论文训练,除了 thesis (中心思想)要鲜明突出外,还要求承转起合(transition)到位,段落要有 topical sentence,人物和事件要有背景介绍,材料来源必须详细标注来源,最后的总结概括阐述其意义和价值后,还需要几句话谈 so what,即从长远的角度预示其历史意义。女儿问:她很了不起,已经为人权做出了很大贡献,so what?我给她提示了两点:一是星星之火,榜样的力量是无穷的,等群众都觉悟了,追随她的结果就会演变成改变世界的力量。第二点就是和平演变,追求自由是人类的天然权利和本性,钳制言论自由和基本人权的反动力量和独裁政权,终将为保护自由的民主社会所替代。但这个过程不一定要伴随流血和革命,和平演变对国家和人民最为有利。女儿有些懵懂,但还是把这两点融合进去了。
不知她的老师买不买账?
11 May 2012
Blogging Through Silence

Living with a fear of speaking is not easy, while the free world takes for granted the freedom of speech, the citizens of Cuba are still deprived of this basic human right. Yoani Sánchez, who uses the power of Wordpress blogging to air her views freely, is one of Cuba's best-known human rights activists to fight for free expression. Sánchez manages to use her blog as a forum to exercise free speech in the totalitarian reign of Castro in Cuba. Her use of Internet and technology to blog through silence pioneers a new direction for the movement of human rights in the world.
The end of The Cold War twenty years ago did not end entirely the communist dictatorships. Today, there are still a few extremist regimes such as Cuba and North Korea. The communist Cuba, founded by Fidel Castro half a century ago, still continues the system of Stalin in which free speech is a political taboo: "Stalinism with conga drums," says Ms. Sánchez as she compares it to the former totalitarian Soviet Union (“Cuban Revolution”). The press in Cuba is under strict government censorship. The traditional media such as newspapers and television act as a propaganda device for the government to control the people who also cannot elect their own leaders. The current leader, Raúl Castro, was not elected but was appointed by the former leader, his brother, Fidel Castro.
Born in 1975, Yoani Sánchez spent her childhood worry-free at a time when Cuba was fully supported by the former Soviet Union. However, her generation had to go through the time of hardships when the Soviet Union collapsed and the soviet aid was discontinued. Soon there was severe food shortage along with difficulty for all necessities. Disappointed and disillusioned with her home country, she moved to Switzerland in 2002 where she got used to the life of style in the free world. Her husband ended up not being able to find a professional job in Switzerland and the couple decided to return to Cuba in 2004. After studying computer science, Ms. Sánchez later started her career as a freelance writer and was determined to be a free person. Starting from 2008, she began signing her blog with her real name, a brave move in Cuba. (“Generation Y: My Profile”)
Yoani Sánchez’s blogging enters a taboo area in Cuba. Time magazine comments about Sánchez saying, "under the nose of a regime that has never tolerated dissent, Sánchez has practiced what paper-bound journalists in her country cannot: freedom of speech" (“The 2008 Time 100: Yoani Sanchez”). Traditionally, journalists who dare to break the silence are punished -- even sent to jails! This has happened to a number of dissidents and journalists, including Yoani’s husband who used to be a journalist and was sent to prison (“Desde Aqui: The Year of Yoani”). The regime controls the people through fear and terror and using the police to enact these efforts to brainwash the citizens. Saying what you think in Cuba can be dangerous. In 2002, Cuba imprisoned dozens of journalists, who declared themselves dissidents and published criticisms of the regime. Many are still in prison (“Desde Aqui: The Year of Yoani”). Most Cubans are so afraid of being labeled a critic that they are reluctant to utter the words "Fidel Castro" in public. Sánchez believes that the fear of Cuba's own secret police is the main reason why the vast majority of people choose to keep silent. “Fear leads Cubans to restrict what they say and do,” Sanchez states (Sánchez xii). Worse still, people who live in a totalitarian country for too long tend to generate an "internal policeman," for subconscious self-censorship (“Cuban Revolution”).
To break the silence as well as the internal fear, Sánchez started exercising free speech by blogging in the cyberspace. The use of blogs and twitter allow her to publish her opinions and report events in Cuba any time she gets access to the Internet. The digital revolution, also referred to as the information age, helped to provide a platform for Yoani to change the society, in her own way, as part of the worldwide human rights movement. In April 2007, Sánchez launched her blog, Generación Y (Generation Y: My Profile). Within a short time, "her name passed from anonymity to popularity" in 2008 (“Desde Aqui: The Year of Yoani”). Thanks to her honesty in describing the true life of Cubans under the communist regime, and her excellent writing ability, her blog was an instant hit and has become internationally influential. Generación Y has about 14 million hits a month and is now translated into seventeen languages by volunteers (“In Cuba, the Voice of a Blog Generation”). In fact, her blog becomes a must-read for any serious researcher who needs to study contemporary Cuban society (“Cuban Revolution”). Her numerous awards, recognizing her pioneering work, include Time magazine's “One of the 100 Most Influential People in the World” in the "Heroes and Pioneers" category, “Spain's Ortega y Gasset Prize” for “Digital Journalism”, and the prize for “Best Weblog” in “The BOBs” contest (“The 2008 Time 100: Yoani Sanchez”).
Sánchez’s work shows that freedom can only be earned by people who strive for it. Freedom is not a gift one can expect or beg for from a dictator. The Internet provides a new platform for all people to take freedom into their own hands. With her knowledge of computers and the web, Sánchez is grasping this historical opportunity. Her voice is instantly carried over the country and around the world. The Internet is a new space, a gray area where the Cuban regime does not yet have explicit regulations, nor can it enforce practical means to stop people from expressing and publishing. While many people still choose to blog only anonymously, Yoani broke the silence in signing her blog and commenting on any subjects to which she turns her attention, including taboo subjects like corruption, political systems, and democracy. Her description of Cubans' daily lives provides a true picture of their society, which is not depicted in the official journals of the country. "You have to believe that you are free and try to act like it," she says. "Little by little, acting as though you are free can be contagious" (“Cuban Revolution”).
Yoani Sánchez is wise to move one step at a time, trying not to break explicit laws, only pushing the limits in the gray area. She chooses not to associate herself with existing dissident groups. Under the pressure from the international community, Cuba has to be cautious in handling her. It has blocked her blog within Cuba, trying to stop her words from spreading and impacting the Cuban people; but it cannot block many of her mirror sites hosted outside the country. From time to time, her blogs are also made into CDs and smuggled back to Cuba (“Cuban Revolution”). This is the power of The Internet: unless the government abandons The Internet and goes back to the pre-digital age, the government cannot block the free information flow. When Sánchez cannot directly reach her blog site, she asks her foreign friends to help publish the posts she has emailed them. (“Desde Aqui: The Year of Yoani”) Over time, other Cuban writers have begun to follow her example and the Desde Cuba website, famous for hosting her blog, has since seen an increase of Cuban bloggers, including her husband Reinaldo's and several other popular writers’ blogs. In 2009, President Obama wrote a letter to compliment her great efforts in using technology for free speech. "Your blog provides the world a unique window into the realities of daily life in Cuba. It is telling that the Internet has provided you and other courageous Cuban bloggers with an outlet to express yourself so freely, and I applaud your collective efforts to empower fellow Cubans to express themselves through the use of technology" (“Generation Y: My Profile”).
With her pioneering work, Sánchez’s free speech is now a fact of life in Cuba albeit only in a limited space. Sánchez’s effort has made a lasting difference in the human rights campaign. Her persistence and sense of responsibility have earned her a great reputation in the world. She is a symbol in the digital age for fighting for freedom of speech under a dictatorship. Gradually, governments in totalitarian countries may have to face the fact of free expression as more and more people follow her example in publishing in social media and exercising their freedom of speech. When a variety of voices are heard in cyberspace, the same process will eventually occur in the traditional media, sooner or later. As freedom of speech is exercised long enough, it will become a natural style of living, and there will be no way back. It is imaginable that a democracy, which protects people's human rights, will eventually replace the existing totalitarian governments. As an old saying goes, a single spark can start a prairie fire. Sánchez is just that spark. Everything she has done is only a beginning in Cuba, but a remarkable breakthrough in human history.
Works Cited
"Cuban Revolution." Wall Street Journal. Wall Street Journal. Web. 11 May 2012. <http://online.wsj.com/public/article/SB119829464027946687-2qWBoM9EpwF1S0_7hn6prJNeJqo_20080121.html?mod=tff_main_tff_top&apl=y&r=139874>.
Escobar, Reinaldo. "The Year of Yoani." Desde Aqui / From Here. Wordpress, 31 Dec. 2008. Web. 11 May 2012. <http://desdeaquifromhere.wordpress.com/2008/12/31/the-year-of-yoani/>.
Hijuelos, Oscar. ""The 2008 Time 100: Yoani Sánchez"" Time Specials. Time Inc., 30 Apr. 2009. Web. 11 May 2012. <http://www.time.com/time/specials/2007/article/0,28804,1733748_1733756_1735878,00.html>.
Rohter, Larry. "In Cuba, The Voice Of a Blog Generation." The New York Times. The New York Times, 06 July 2011. Web. 11 May 2012. <http://www.nytimes.com/2011/07/06/books/yoani-sanchez-cubas-voice-of-a-blogging-generation.html?_r=1>.
Sánchez, Yoani. "Generation Y » My Profile." Generation Y: My Profile. Wordpress. Web. 11 May 2012. <http://www.desdecuba.com/generationy/?page_id=108>.
Sánchez, Yoani. Havana Real: One Woman Fights to Tell the Truth about Cuba Today. Brooklyn: Melville House, 2011. Amazon.com: Havana Real: One Woman Fights to Tell the Truth about Cuba Today (9781935554257): Yoani Sanchez, M. J. Porter: Books. Amazon.com, Mar. 2011. Web. 11 May 2012. <http://www.amazon.com/Havana-Real-Woman-Fights-Truth/dp/1935554255>.
转载本文请联系原作者获取授权,同时请注明本文来自李维科学网博客。
链接地址:http://blog.sciencenet.cn/blog-362400-569854.html
上一篇:互联网有史以来最大的IPO:Facebook 眼看就要上市了,怎么玩?
下一篇:自来水和地沟油的话题
当前推荐数:4 推荐人: 王亚娟 曹聪 李银生 李宇斌
推荐到博客首页
发表评论评论 (1 个评论)
删除 |赞[1]mirrorliwei 2012-5-12 11:11说到当代、现代和近代的区分,镜某的孩子说:自己出生后的事情是当代,父辈的事情是现代,爷爷辈以前的是近代。或者干脆说,自己出生前的事情都是“历史事件”。这也是个分类方法。
选人物,看上去好写,实际上难写。而选择某些(国际)组织、机构,看上去不好写,但是写起来会比想象要容易。比如说联合国及其下属的组织,科教文组织、粮食机构、难民问题、国际标准等等的。甚至各类的体育运动的组织,比如国际奥委会、足球等也都可以写。
Tian (Age 15): Karl Marx in Tanya's eyes
Tian (Age 15): Karl Marx in Tanya's eyes
屏蔽 |||

This is Tanya's history course project, researching an influntial thinker and then making a presentation in the form of addressing the world with his ideas. Tanya chose the communist god-father Karl Marx, who she thinks is an intriguing figure with a great dream but failed in the practice.
(1) Meeting of the Minds: Karl Marx
Karl Marx addressing the world
(Tanya was dressed like an old scholar wearing a grey wig and white thick beard just like Marx and made the following speech passionately, with the ending sentence first in German and then repeated in English, word by word, very powerful. The teacher was impressed and gave her an A.)
Hi, I’m Karl Marx, a middle class, 18th century German scholar, who was born at the beginning of the Industrial Revolution, when Capitalism was just starting and not yet mature. There were no social welfare programs (such as healthcare or pension) or worker unions, and everything was a class struggle between the rich, Bourgeoisie, and the working class, Proletarians. My theory, Marxism, is about the ultimate government, Communism, in which the property of a society is owned by all members, and peoples’ talents are utilized to their full potential, so that people enjoy their work while working toward the common good. Capitalism is a corrupted system in which the Bourgeoisie have all the power and exploit the Proletarians, while the Proletarians are unfairly treated, wage-earning robots. Even in democracy, when people vote, they are affected by mass media, controlled by the Bourgeoisie. All humans are naturally creative and talented. So I say to you all, everyone is equal. We should overthrow the dictatorship of the Bourgeoisie, "Proletarier aller Länder vereinigt Euch!" Proletarians of the world, unite!
(2) The U.S. is a land of free speech. Despite the bad association with communism in the media, Tanya shows keen interest in Karl Marx and his theory of communism. The other day when she got up, Tanya told me, "Dad, I had a weird dream. The last sentence I remember saying to somebody is: If there is anything that I know, communism is for you."
Looks like she really got intrigued by communism during the study of World History. This was quite a surprise to me, as we have seen and experienced too much of "communism". Tanya told me that kids in America had been brain-washed to believe communism is evil, leading to dictatorship, but after research, she now realizes that communism is a very nice dream of mankind, perhaps too nice to be practical.
"we were brain-washed to believe that communism is associated with dictatorship and leads to evil. But according to Marx, communism is a beautiful society, no class. no class struggle, work is fun and not a burden, one can satisfy his most potential with his gifted talents. But why the countries experimenting with communism all failed?
"They failed for a good reason. The reason is clearly stated in Marx's works but the followers did not take it seriously. That is, an ideal society like communist needs to be supported by the maximum productivity."
Tanya continued, "Marx is a great man, and capitalism sucks. Look at the financial storms in recent years that spread from US now to Europe, all the signs show that capitalism is doomed and communism will most likely conquor the world, if made practical. "
She smiled, "Dad, by now, I think I am already a communist. Capitalism sucks, got to be replaced by communism."
I was really shocked, at the fact that her speech was almost identical to my thinking when I was her age. It took us years to get out of it. Nevertheless, I still like the fact that free thinking and speech enable Tanya to research and understand the world in her own way and pace. Like all teanagers, the existing reality is always the worst, the ideas from the other world look so much better and beautiful.
(3) Research Karl Marx
Notes on Karl Marx and Communism
1. Bio
Karl Marx was a German philosopher, sociologist, and communist in the 18th century. He developed a famous theory, called Marxism, that fundamentally influenced the human history. In fact, Karl Marx is among the most quoted scholars in history and is one of the most influential figures of all time. His two most famous works are: The Communist Manifesto published in 1848, mainly a political statement for the communist movement, and Das Capital, a book he devoted his life to on the nature of the capitalist system. In the last century, following his revolutionary theory, there were communist movement and revolutions in many countries to form a communist group of states, led by Soviet Union in 1922 and led to the founding of Red China in 1949. However, since the collapse of Soviet Union towards the end of last century, the communist movement suffered a big retreat and even the post-Mao China turned to market economy, a system closer to the capitalist economy than the communist economy. Marx's predictions that the global revolutions will end the capitalist system in the world are not proven right.
2. Marx's view on government
Marx has a theory of social development involving 5 major social types, from lower stages to upper stages, i.e.
Primitive Communism --> Slavery system --> Feudalism --> Capitalism --> Socialism --> Communism.
He regards the capitalist government as an inhuman government which only protects the capitalists (bourgeoisie) while oppressing the working class (proletarians). He believes that despite the name of democracy, a capitalist society is in essence based on Dictatorship of Bourgeoisie. He concludes that capitalist government should be overthrown by the working class and replaced by the socialist government based on Dictatorship of the Proletariat. Eventually socialism transitions to communism when the productivity gets to the highest level. Communism is the ideal society in Marxist theory in which every one enjoys his work, which brings job satisfaction and fulfillment of his creativity, at the same time producing the products to meet the needs of all the society. In communism, there is no distinction of class, no class struggle and everything is in harmony.
3. Marx's theory of human nature:
Contrary to the popular view that human is selfish by nature, Marx thought that human is a naturally creative animal. Accordingly, an ideal society creates a condition for the whole development of human nature. But capitalism is an evil society which turns humans into wage slaves.
Marx's theory of human nature plays an important role in his criticism of capitalism and his ideal of communism. A closely related and even more influential theory of Marx is about alienation from human nature caused by the capitalist system.
4. Marx's theory of alienation
By alienation, Marx refers to the social separation of people from their "human nature" which is supposed to be decent and creative. Marx believed that alienation is a systematic result of capitalism. He believed that it is the alienation that deformed human nature, making people behave differently depending on one's social status. The nature of capitalists becomes exploiting and oppressing the working class purely for the seeking of profits. The working class becomes wage-slaves like robots working in inhuman conditions.
Only in the communism can all men gain freedom and be liberated from wage-slavery, enjoying the full nature of their creativity.
5. why he thinks that way
Marxism was formed in an age when the capitalism was not mature and there were waves and waves of class struggle and society conflicts : there were no social programs, no unions and other forms of laws as seen in the modern society. For example, there were no minimum wage law, child labor law, income tax regulations and social welfare to protect the lower working class and to balance the interests between the capitalists and the proletarians. Out of deep compassions for the lower working class who has been struggling for very basic living, and out of the anger towards the early capitalists who were after profits by forcing the working class to work long hours with very low pay and very poor working conditions, Marx concluded that the capitalist government is inhuman and will be overthrown by the proletarians and replaced by the socialist and then communist government.
Works Cited
“Karl Marx.” Wikipedia: The Free Encyclopedia. 19 Sep. 2011. Wikimedia Foundation. 21 Sep.
2011 http://en.wikipedia.org/wiki/Karl_Marx
“Marx’s Theory of Alienation.” Wikipedia: The Free Encyclopedia. 26 Aug. 2011. Wikimedia
Foundation. 21 Sep. 2011 http://en.wikipedia.org/wiki/Marx's_theory_of_alienation
“Marx’s Theory of Human Nature.” Wikipedia: The Free Encyclopedia. 22 Jun. 2011.
Wikimedia Foundation. 21 Sep. 2011 http://en.wikipedia.org/wiki/Marx%27s_theory_of_human_nature
http://blog.sciencenet.cn/blog-362400-684386.html
上一篇:Tian Tian (Age 10): Tanya's Amazing Life (4/4)
下一篇:Age 9, Age 10 and Age 16: Father's Day Gifts
从人类认知谈AI融合之不易
听了一些深度学习的大神们的各路演讲,有些感触。
他们的科普类演讲大多有个共性,就是哲学味道很浓,有上帝视野,或干脆自己做上帝状。这是可以理解的情绪和姿态,也是一种自然的表现。在AI寒冬走过来的这些人,面壁N多年,终于迎来了扬眉吐气的深度网络横扫AI的各种奇迹和荣誉,不俯视天下反而是不可能的。
面对新闻记者的采访,有时候会给人一种自己被自己的成就吓倒了的极端自豪感,很有趣也很人性的一种表现,这种时候最容易天马行空。记者问,你认为什么时候神经网络可以自主意识呢?回答是,我认为已经自主意识了啊。
不过他们的长篇演讲还是有很多让人启发的思考,他们都在寻找下一个突破口,并不满足于小修小补。小修小补,模型越做越大的渐变式成功,他们认为是年轻人的事儿,水到渠成。他们希望自己能带领AI迎来下一个范式转变或者根本性突破。这种心理非常强烈,也是很自然的。人的本性都是,无论多大的成就,盛筵过后总是要追求下一个更大的辉煌。
其中思考最多的问题之一是,人用小数据就可以高效训练自己的技能,可是深度神经却需要大了好几个数量级的数据才能训练好。图像识别是最典型的例子,儿童开始识别猫啊、狗啊,见过的实例非常有限,但识别率则很高,什么机制?为什么机器只能蛮力去学,不能像人类一样?
在与人的认知机制的比较中,他们出现了两极的表述,很有意思。上面是强调人和机器的不同,思考如何弥合这种不同,或者如何更加逼近人的认知过程来提高机器学习效率。另一个方面说法却是强调深度神经就是人的神经。敢于这么说我觉得主要是因为生物领域的大脑机制研究很多年陷入泥潭。有人说这不怪生物学家,因为人的认知和意识是世界上最难解开的谜,目前人类对它的认知只是冰山一角。既然脑神经系统是怎么工作的留下太多的空白,AI 神经系统的大神们就理直气壮认为深度神经网络就是人脑机理的最完美模型就可以理解了,毕竟这套模型在很多认知任务(语音、图像、翻译等)的表现中已经接近或超过人脑的水平。
AI神经与生物认知这两个领域以前大多处于老死不相往来的状态。有意思的是,由于AI的高亮度,现在越来越多的生物界人士开始关注神经网络系统的进展。听过一些生物学家的看法,认同AI的不少,大概是看到了AI的表现,有点信服的意思。
谈点自己的观感。人脑的认知和决策比较复杂,大概其中有些部分的机制的确很像是各个节点互相连接以不同权重互相影响的神经网路,特别是那些我们称为“本能式反应”的下意识过程(例如遇到紧急路况的驾驶反应,在水中学会的游泳技能等),这些反应人也说不清,有些甚至已经固化到我们的条件反射里面,但这些反应是有效的生存策略。
但是,人的确有非常有逻辑条理和清晰的认知过程存在,包括我们所熟知的语言理解过程,虽然说 native speaker 似乎都可以“本能”学会说话和理解,但是其中绝大多数理解过程细细琢磨是可以找到背后的逻辑脉络的。这种认知通常是符号化(概念化)的,往往非常抽象而高效,不依赖大数据,只需要有限量数据做微调。这方面的理性认知与目前流行的神经网络很不相同。
能够清晰梳理出来的语言理解案例,在白硕老师的语义计算群里有过无数案例、讨论或解说,【语义计算:李白对话录系列】对此有所记录。其特点是:1. 符号化的;2. 多层面的较量;3. 就事论事都可以讲清楚哪个层面哪个因素主导了最终的理解,如果出现歧义,歧义背后的脉络也是清晰可见的。这些层面其实并不多,列举下来:第一是词汇概念及其背后的本体知识(常识),也包括情感分析的因素;第二是形式制约(句法、形态等);第三是篇章上下文;第四是领域性行业知识;第五是说者和听者的社会关系影响。大概就这几项了。原则都是有限的符号体系可以勾画、模拟和演算的。
符号AI在这方面的尝试已经很多,创新在悄悄发生,虽然听不到太大动静。这一路更像是真实逼近或模拟的高级认知功能。感觉到的痛点不是高度抽象的符号化概念化本身的问题,而是以上各种力量对比在语言理解过程中如何较量的问题。这正是符号化规则的短板,压下葫芦浮起瓢。也正是在这点上,神经系统或统计模型应该可以助力,主要是要找到合适的接口来做对接。这方面白老师也说过多次。我的理解是,符号系统画出骨架,血肉可以让大数据神经/统计模型来填写。
可是这种对接和融合的构想,不是神经系统 leaders 所要的。这也可以理解,每个人有不同角度。他们的角度总是,确立神经的骨架,在神经网络的延长线上,希望其他知识系统用某种方式融入。但迄今为止也大多想不出来如何融入“异质” 的知识资源,毕竟这看上去是不兼容的怪物。不少人不是不想深度融合,但困于不兼容的感觉是普遍的。
宏观上看是两条路线的不兼容,根本就没有起码的共同语言与词汇,只不过恰好面对的问题领域重合了而已。一边是离散的符号,一边是各种向量/参数,怎么交融?这就好比物理学家、化学家和生物学家很多时候不兼容一样,物理面对的是基本粒子,化学玩的是分子,生物研究细胞,不同层次的体系,如何交融。
~~~~~~~
有生物医学老友评论说:
“人用小数据就可以高效训练自己的技能”, 不知道这有啥证据。
人从生下来就在学习。把猫狗图像识别用于刚出生 的婴儿试一试,估计还不如机器快。
人的认知过程本质是环境输入信号和大脑已有模型的拟合过程,而人脑的已有模型是通过学习建立的。这个模型的建立过程归记忆的机制在研究。很显然目前还不能在分子和细胞水平进行解释。
AI识别和人脑识别最大的不同是AI没有情绪成份。人脑情绪成份的加入会严重影响记忆建模过程,并因此影响模型和环境信号的拟合过程,也就是影响对环境信号的识别。情绪成份是生物上亿年进化出来的东西,和个体生存和种系繁衍有关。情绪的逻辑和AI的数理逻辑差异巨大。
说不准算不算小数据认知。只是感觉认识物体与学习语言类似,并不需要海量样本。
我们教孩子认识一个物体,也就是给有限的几个样本,他们就认识了。后去这些物体的各种变形,基本上一样可以认出来。
类似的过程在学习语言这种复杂的系统中最为明显。所以乔姆斯基认为,人生下来就有一个普遍语法机制在头脑,这个机制有一些参数需要数据去训练,但人在学语言的时候,其实面对的并不是海量数据,也不是完整无误的数据。就是这些片段的有限数据,让最傻的孩子也可以自如学会母语。
可是机器学习不同,最新的深度学习的语言模型的预训练规模是:
GPT-3 is a very large language model (the largest till date) with about 175 billion parameters. It is trained on about 45TB of text data from different datasets
当然,现在的语言模型的语言生成能力包括流畅度和合法性,已经超越普通人的水平。
乔姆斯基批评这种学习是蛮力,没有科学意义,因为不能揭示人类的认知过程。
的确,关于生物演化而来的喜怒哀乐情绪,在人机对比中更具有区别意义。
本来情绪这种东西,看上去是非理性的 比较低级的心理过程,因为一些高级动物也会有某些情绪的表现。而理性思维和智能被认为是人类独有的高级认知功能。
但是,现在看来,机器在不断压缩或逼近人类的智能空间,原先以为人类独有的很多智能活动,逐渐被机器学习超越了。反而是情绪这种东西,成为人机的真正鸿沟。
教会机器“谈”恋爱并不难,但是让机器堕入爱河是不可能的。让机器呼天喊地哭鼻子叫苦叫疼也可以做到,但证明他是因为痛苦而哭现在看来是天方夜谭。自主意识和自主感情是科学幻想所热衷的话题,但是至少迄今没有任何可信的迹象表明,生物科技(基因工程)与电脑科技会真正深度融合人机,以至于可以创造出具有情绪的超级机器人。担心自主的机器起来造反或谋杀人类,是相当可笑的。AI如果有灾难,是人自己把自己玩死了,是某种 bugs 没消除就部署造成的意外灾难,这是可能的,但绝不是机器人犯上作乱。
图灵测试不是人机不可逾越的界限,情绪证明才是。
【相关】
《李白125:语言学的爱因斯坦之梦》
白:

“写作业”被整体强制为N/N。
终于搞清楚了,只有“最大投射”才有权利参加Swap,即从已饱和的坑中置换出免费萝卜的操作。一个成分所包含的所有最大投射,按“加入革命”(即配属于当前中心词)的早晚排列,last-mentioned不是指自然顺序,而是指参加革命顺序。越晚参加的,免费额度越不牢靠,越有可能被替换成临时工。
李:为什么要强制转N?
另一个可能的做法也许是:
(1) “当成”: S/2N X
(2)“把”:X+
然后就齐了,介词可以带着S的介宾,S的三个坑可以匹配一个 X。
白:想过这个方案,某种意义上是等价的。
李:一个旁证:“当写作业为负担”,“当” 的两个坑,一个是 X 做宾语,一个是 PP(为) 做补足语。“当成”实际上是 “当+成/为” 而来的合成词,结果合成动词整体就有了三个坑。
白:感觉X+容易惹火烧身,X好控制一些,所以用了后者。把的这个,因为是直接成分,所以用了N+。用了X+,弄不好就把整个谓语给吞了。
一般的介词是S+/N或者S+/X,后置的也有+S/N或者+S/X。单目运算,即升降格、泛化特化这种,虽然中心词没有改变,但中心词的句法属性有了重大改变的,也属于“最大投射”。比如“吃食堂”,“食堂”从N变更为+S前后,是两个不同的最大投射。
李:这样的话 如何区分:“在中国服务” vs “为中国服务”,这种介词搭配如何体现?
白:S+/N N S/2N,这是一样的。但是,惠格是必选论元,可以置换一个免费额度给萝卜“中国”重用。间宾是正式工作,发工资的,介宾是客串临时工,不发工资的。在中国,不是惠格,没有这个待遇。介宾就是正式工作了。中间代表“中国”的那个N,重用与否,有免费额度与否,区别主要在这儿。这是“服务”的论元结构决定的。
李:嗯,“在” 标注为 S+/N,“为”的格怎么表示?或者说 “服务” 怎么表示需要这个 “为”-格?从词典角度,这种介词搭配信息应该是在 “服务” 的词条上吧。
白:我们在S+的modee里表示 +beneficial 这个控制标签。服务的对象,在服务第二个坑里,有一个 -beneficial 的控制标签。二者匹配,就可以。
李:嗯 那行。
白:之前还讨论过“张三向李四出示身份证”“张三为李四出示身份证”的问题,也是类似。惠格会截胡。把李四当成身份证的宿主,对格(向)不会截胡,所以宿主是张三。这个介宾转正,实行的是白名单制。
把和被,直接用N+转正了,与动词无关。
李:对 这两个介词就是格标志。
白:而其他与动词有关的就采用白名单制。即使“在”格,遇到合适的动词也可转正的。比如“放在桌子上”。
S/3N +S/N N +N
桌子上,可以转正。但是,在桌子上打滚,就不是标配论元,只能老老实实地做介宾。打滚是S/N,不特别强调处所。在天上飞,类似。
李:放:locative+,这样的标注缺少方向,如何区分:
“在家 放 在抽屉里”
“在外 放 在口袋里”
为什么 “在家/在外” 斗不过 “在抽屉里/在口袋里”?“放 在家”、“放 在外” 也都是通的。
locative 的候选PP,在谓词前是静态状语,谓词后才是 动态/目的地/结果 意义的所谓补语;前者一般认为是随机的,后者才是(萝卜/坑)配对。
白:已填坑的萝卜,只有本体、控制标签都相谐的最大投射,才可以考虑重用与否。控制标签,类似自动机的状态,但一般从命名上即可看出句法意义,所以比较方便语言学家维护。
“假如不是家人在绑匪手里,谁会忍得下这口气啊?”通过条件连接词组成复句,主句的已填坑萝卜“谁”,在从句中“家人”处的残坑被复用。兼语句式更是典型的萝卜复用。
右填坑、右修饰,先验优先级都高于对应的左填坑、左修饰。但像惠格,放在前面也好使。
“为他把邮票贴在信封上。” 既有locative,又有beneficial。
“为他把胡子刮了”,刮的是“他”的胡子;“为了他把胡子刮了”,刮的是自己的胡子。如果一定要“为她把胡子刮了”,可以因为不相谐而强制指向自己。“为”效果等同于“为了”。
类似的吞音段子有:“今天我要讲两个小时,【停顿】你们肯定烦透了。”——其中的“要”一开始被理解为“想要”,停顿后自动被脑补为“要是”。
“为他把扣子扣在扣眼里”,扣子是衣服的部件,衣服是人的部件(缺省场景)。那扣子是介宾的,而不是逻辑主语的。因为惠格介宾可以截胡残坑。
“他的基本信息已经被公安部门编码在身份证里。”——谁的身份证?好像很显然,但是想要让计算机做到,就要让位于逻辑主语的定语位置的“他”有机会出来走两步,才能碰上那个放出了“残坑”的“身份证”。我们的做法是:给一个免费额度,看动态(后验)优先级造化。
李:宏观上看,回答谁的身份证这个问题(填逻辑所有格的坑),是一个与本句其他谓词填坑的问题处于不同层次的问题。【N1 “编码” N2 PP(N3)】 已经完满了,只不过恰好 N3 本身是个部件,那么部件就有个逻辑宿主的问题出现。换句话说,这貌似另一层次的问题,感觉上较少受到句法条件的约束。既然不是同一层的问题,超越这个层次找宿主的自由度就大很多。策略可以是左右扫描,找距离最近的本体相和谐的宿主为最优。不必顾忌结构的约束,只要看线性距离即可,前提是相谐。上句中,唯一的 candidate 是“他”,无论 “他” 处于结构树的什么节点上。
白:转正问题和这个不一样,这是对的。前者是白名单制,后者是黑名单制。在自身辖域里,唯一相谐的已填坑萝卜,要复用也只有它了。可万一不那么相谐呢?比如“她意识到妻子的责任。” ——这时,宁可空着,也不乱填。
“作为这个网站的访客,我居然不知道(其)域名。” 这个顺序,“访客”是最新参加革命的,但与“域名”的宿主在语义上不相谐,于是需要进一步顺藤摸瓜,找出下一个大瓜——“网站”。不加“其”,机器翻译给自动加its的很少;加了“其”,做对的就多了。
如果坑的总数超过萝卜的总数,那么有合适的萝卜优先复用,这个精神是一致的,只不过,有的用白名单制,有的用黑名单制而已。
李:白名单是要求相谐,黑名单是要求只要不相悖(对象没在黑名单上)即可,是吗?
白:不是,白名单是不在里面就不考虑萝卜复用,在里面也还要过相谐这一关。黑名单是不在里面就可以考虑萝卜复用,在里面同样要过相谐这一关。
李:里面?辖域?同一个句子之内?
白:两方结合,一方有未饱和坑,且在自身辖域之内寻萝卜未果;向另一方的已填坑萝卜寻求复用。所以范围是另一方的辖域。两方正式结合,辖域合并的不算。萝卜复用都是辖域内部的事情,不涉及辖域合并。
人家都搞C-Command,我这萝卜复用的位置更宽泛,只要是最大投射就ok。不如就叫M-Command。
李:C-command 之类对于反身代词 self 似乎的确有可以感触的结构约束效用。但是对于其他寻求宿主的行为,感觉结构不起作用。Binding theory 其实是从反面证明了这一点,其中第二条约束说的不是“谁可以回指谁”,而是“谁不可以回指谁”,后者实际上是几乎放弃了结构约束。
白:不一定是宿主,谓词合并时过继而来的那些残坑怎么寻找相应的可复用萝卜,都需要研究分析树的拓扑。残坑和代词释放出来的空范畴可以一并处理。
李:所有格宿主问题感觉不是结构问题。至于其他的合并共享,应该是有结构约束的。
白:我这里已经统一了。是一个完整的大一统理论。
李:哈哈。联想到这段时间老看到物理大牛的大一统理论,theory of everything,每个人都想实现的爱因斯坦之梦。
白:中心词萝卜对正常坑,只需要CFG;中心词萝卜对残坑,需要C-Command;非中心词萝卜对正常坑和残坑,都必须突破C-Command,但后者是纯粹的交叉,画出来都是飞线。用程序实现也不难,这个部位的核心代码也就200行。四种情况一个理论模型就可以搞定。
李:嗯 听上去蛮 comprehensive and reasonable。
飞线的实质就是本体决定论,绕过结构,再深也压不住。句法(结构)语义(本体)的“统一场”中涵盖句法约束和语义约束的不同比例分配,包括两个极端:1. 结构决定论;2. 本体决定论,plus anything in between, white- or black-lists。
白:只有第三种情况:非中心词萝卜对正常坑,才需要白名单控制,其他不需要。
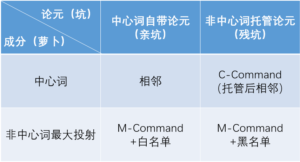
把四种情况分别列一下,除了第一种,都有“交叉”。第二种,是非中心词分母把自己的未饱和坑(残坑)托管给中心词分母,让这些残坑有跟亲坑一样与外界结合的机会。第三种,是给非中心词最大投射一个进入主流成为其论元的机会,前提是,最大投射携带的控制标签在对方设定的标签白名单之内。第四种,是让合适的非中心词最大投射和对方携带的残坑之间有一个“拉飞线”的机会,前提是,最大投射携带的控制标签不在对方设定的标签黑名单之内。
M-Command关系,萝卜一方处于某一个非中心词所在子树的继承链顶端,坑一方处于中心词所在子树的任何位置。C-Command关系,萝卜一方处于所在子树的中心词位置,坑一方处于中心词所在子树的任何位置。
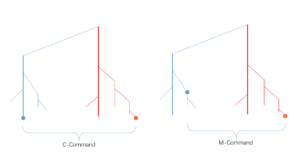
垂直方向是局部中心词继承方向,斜向转角处是最大投射成分。
寻找萝卜复用的算法,涉及到把所有最大投射按类型链在一起,随着分析的进行,这个链会动态调整,但是一旦正常邻接成分处理完毕仍有未饱和坑,就会启动这条链的搜索。这个算法也就是把各类飞线一网打尽的算法,号称“大一统”。
李:这个 c-command 和 m-command 图示,看不大懂。通常说的 c-command 就是姐妹及其下位。蓝点和红点没看出姐妹关系。两个点是姐妹,需要共同的 parent ,不知道在哪里。
白:对啊,姐妹,这里还要考虑中心词继承关系。蓝点顺着中心词继承路线可以走到转角点,也就是左子树的根。它就可以统辖整个右子树。M-Command,就是蓝点不一定走到根,可以走到任意最大投射。只要你相谐。但是对面的坑,亲疏有别。
李:所谓 m-command 说到底我的理解就是放松 traverse 的条件限制。其实可以从反面来想这个问题。条件放松到极致,就是遍历每一个节点。那么问题就变成 m-command 比起遍历,到底多了什么限制?或者问 到底哪些是 m-command 的例外区间?
白:中心词继承路上,不用多关注,盯住最后结果就行了。一开始并不一定给你很具体的本体标签。越继承,越具体。修饰语的每一次汇入,都会带来modee的标签。比如,“不男不女的东西”,“不男不女”给“东西”带来了更加specific的本体标签吧。
实用角度,对于M-Command,我们可以只考虑N和S的继承链。需要遍历的数据组织非常清晰。
【相关】
社媒挖掘:关于狗肉的争议
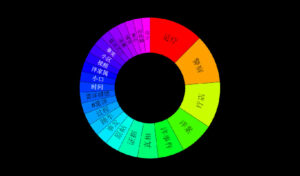
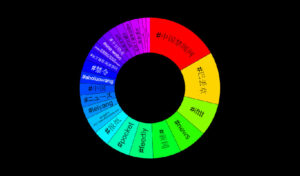
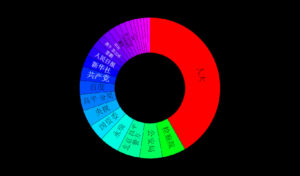
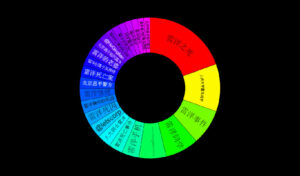
社媒挖掘:关于狗肉的争议
蒋老师看了关于柴静的社会媒体舆论挖掘后留言,问可不可以帮助挖掘一下狗肉的话题。这也是一个极其有争议的热点话题。凸显动物保护主义与传统文化的冲突。
蒋老师何等人物,岂敢怠慢。n 年前,是蒋老师最先介绍我到科学网来的。恭敬不如从命,还是赶紧交家庭作业吧,这是对过去27个月的中文社会媒体样本的初步挖掘结果,还没有做细致的分析解读。
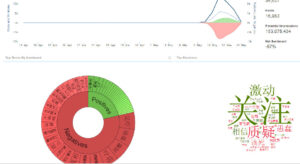
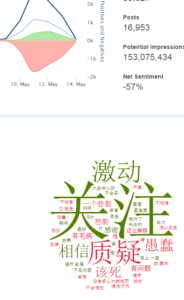
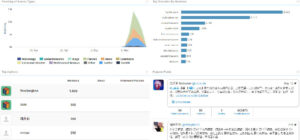
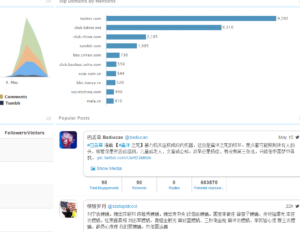
一 总览和回顾

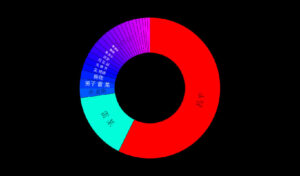
上面是过去27个月的“狗肉”话题在社交媒体的热议度,能看到两个高峰,那应该是在玉林狗肉节期间引起的广泛争议。
下图叫 Brand Passion Index Trend,内涵舆情挖掘的简约但丰富的信息,反映的是对于狗肉好恶的消长趋势,图中截取了过去一年半中社会舆论喜爱或痛恨(吃)狗肉的争议变化,三个泡泡反映了每半年的好恶(BPI)指标:泡泡的深浅度反映了数据的新旧,具体说就是,左下颜色最深的泡泡是最近半年统计挖掘出的好恶指标,中间那个泡泡是一年前的统计,颜色最浅的右下泡泡反映的是一年半前的指标。泡泡的大小表明了热议度,譬如一年前比半年前热议更多。泡泡所处的坐标位置反映了两项舆情,一是好恶(越往左越喜欢),二是情绪烈度(越往上越情绪化)。可见,一年前那个统计情绪烈度最大,而对(吃)狗肉的厌恶则随着时间推移越来越大(越来越靠左)。这说明什么呢?应该可以看到近年来,动物保护主义的影响在逐渐增大,反对吃狗肉的呼声正在变高。

Download
二 相关热点话题

Download

Download

Download

Download

三 褒贬比例


四 情绪及其好恶的理由



五 社会舆论的地理分布

六 数据样本的来源

8 蔣勁松 吕喆 戴德昌 余池明 张珑 赵美娣 uneyecat bridgeneer
发表评论评论 (12 个评论)
- 删除 回复 |
 赞[7]bridgeneer
赞[7]bridgeneer - 谢谢博主给的链接,图很清晰

- 删除 回复 |赞[6]bridgeneer
- 饼图看不清

|
|
【社煤挖掘:雷同学之死】(屏蔽留存)
【社煤挖掘:雷同学之死】
屏蔽 |||
这是最近的热点新闻,舆情鼎沸,有蔓延之势。值得挖掘和跟踪。




社煤选样:
|
雷洋遗体外伤严重 |
|
质疑雷洋案件十大疑点 |
|
雷洋妻报案:有充分证据警察涉故意伤害致死罪(图) |
|
雷洋事件解决不好,非正常死亡可能成为常态【时局深度】- |
|
蔡慎坤:血与泪的控诉还原雷洋遇害真相 |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
转发雷洋案刑事报案书:描述死亡过程(真相即将到来)-衡阳 |
|
雷洋案件之疑点-第11页- |
|
血与泪的控诉还原雷洋遇害真相- |
|
网传'大学生屁股被警察叔叔打开花',警方:属实!图_中华论坛_中华网社区- |
|
雷洋死亡当晚到底发生了什么?央视专访当事警察 |
|
雷洋家属向北京市检报案要求侦查涉事民警- |
|
'他沒有嫖娼時間' 家屬報案指雷洋被無辜毆死 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
血与泪的控诉还原雷洋遇害真相 |
|
雷洋死有余辜! |
|
雷某的家人实在太不要脸了! |
|
“刑事报案书”描述雷洋之死【李鸣生】-常德 |
|
雷洋妻子报案,事件最新爆料!嫖娼是栽赃,雷洋被打死-休闲侃吧- |
|
[原创]雷洋遗孀之报案书等于官媒的死刑判决书 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋最新情报:“刑事报案书”描述雷洋之死经历 |
|
关于要求北京市检察院立案侦查雷洋被害案的刑事报案书(转载) |
|
我们为什么要关注雷洋之死? |
|
雷洋案刑事报案书,警方涉嫌故意伤害(致人死亡)罪、滥用职权罪、帮助伪造证据罪- |
|
转帖:雷洋妻子向北京市检察院报案:嫖娼是栽赃,雷洋被打死 |
|
1) 雷洋家属告控告警方 2) 雷被殴打致死当日是雷结婚纪念日 3)尸检结果延迟到60天出结果 |
|
一个昌平“嫖娼者”为何引燃了全国公众的怒火?(转) |
|
陈有西律师曝雷洋案发现最新一个重要疑问 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
雷洋家属向北京市检报案,要求侦查涉事民警 |
|
【时评】雷洋之死,疑云重重 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
作为正在人大读书的研究僧,分析雷案可能的结果吧- |
|
七律读微信圈雷洋数帖激愤有咏一气呵成重字不改也 |
|
何新:悼雷洋 |
|
哀悼环保烈士雷洋 |
|
血的事实告诉我,雷洋事件很快就平静下来! |
|
警察滥用国家暴力必须予以遏制 |
|
雷洋事件解决不好,非正常死亡可能成为常态【时局深度】- |
|
雷洋之死纯属咎由自取_中华论坛_中华网社区- |
|
人大硕士雷洋真的嫖娼了吗?十三省 |
|
朝吉:足疗送命记 |
|
雷洋之死击碎了中产阶级的优越感! |
|
昌平的一个“嫖娼者”为什么会引发公众的怒火 |
|
雷洋案:尽管真相还在路上,三种共识可以先到 |
|
北京公安回應雷洋案:決不護短 |
|
北京市检察院:已将雷某家属报案材料移送昌平检方 |
|
北京市公安局公开回应雷洋案:高度重视绝不护短 |
|
横河:雷洋案为什么应该怀疑警方 |
|
关于雷阳事件的随想 |
|
警察蜀黍为何喜欢抓嫖?- |
|
“雷洋事件”终于开了个好头 |
|
雷洋用牺牲捍卫一个公务员的尊严 _网上谈兵_中华网社区- |
|
从目击者证言和记者调查的报道看被忽略的雷洋事件关键点 |
|
雷洋被强押致死案,槽点多多,警方说辞漏洞百出 |
|
雷洋事件:中国人民大学88级部分校友向公安部门下战书 |
|
雷洋家属联系第三方鉴定机构将第二次与检方沟通- |
|
雷洋事件,显示了老百姓的焦虑,不安全和无助感_网罗天下_天涯论坛 |
|
雷洋的家属成了大输家!!! |
|
雷洋案真相不难搞清,但很多人打死也不愿相信 |
|
解密雷洋之死的根本原因!-常德 |
|
有见过抓嫖不在店里抓现行而在马路上盘查的吗 |
|
【视点】比雷某嫖娼事件真相更可怕的,是“相信”尽失! |
|
【时评】雷洋事件,送环球时报两字无耻 |
|
中国人民大学88级部分校友就雷洋同学意外身亡的声明 |
|
[原创]雷洋之死:给你真相又何妨? |
|
雷洋遗体外伤严重尸检后家属控告警方涉嫌犯罪 - 中国禁闻网 |
|
呼格案律师谈雷洋之死:涉事警察是嫌犯警方无权再接触证人-常德 |
|
民众为什么关注雷洋的案子? |
|
转载:雷洋妻子正式报案:嫖娼是栽赃,雷洋致命处睾丸异常肿大系被打死 |
|
妻子坚决捍卫老公嫖娼有理正义吗。打飞机不算嫖娼吗_中华论坛_中华网社区- |
|
雷洋之死的九大谜团,谁能告诉我们真相? |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
雷洋案真相不难搞清,可怕的是有人就是打死也不愿相信 |
|
网友热议:雷洋的事,恐怖在哪儿?(图) - 看中国 secretchina.com |
|
雷洋尸检报告未出,但问题已显现:(第3页)_天涯杂谈_天涯论坛 |
|
[原创]嫖娼案拒谈嫖娼,雷洋老婆居心叵测,图谋不轨 |
|
雷洋死亡案铁证如山,雷洋没有白死 |
|
雷洋案新证据浮现:警察有问题 |
|
快讯!雷洋家属正式控告警方涉嫌犯罪 |
|
雷某嫖娼案最终结果的终极预测-第2页- |
|
雷洋怎么死的,我来分析下。 |
|
[原创]雷洋死因的逻辑分析 |
|
[原创]雷洋怎么死的?【猫眼看人】- |
|
雷洋嫖娼,谁又在嫖中国法律_天涯杂谈_天涯论坛 |
|
警方回应雷洋案热点问题昌平检方介入调查 |
|
【转帖】中国人民大学88级部分校友就雷洋同学意外身亡的声明- |
|
橫河:雷洋案為什麼應該懷疑警方 |
|
最新消息:从警方提供及其他方面提供的证据看,雷洋涉嫌“嫖娼”的疑问太多!【铁证】 - 有啥说啥 |
|
我们为什么要关注雷洋之死?(第4页)_关天茶舍_天涯论坛 |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
我服了雷洋家人了,到底要闹哪样?没见过这么无赖的(第5页)_天涯杂谈_天涯论坛 |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
人大部分88级校友就同学雷洋身亡声明:对恶我们不会忍太久全文 - 中国禁闻网 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
大陸雷洋離奇死亡聯合國貼文關注 |
|
雷洋尸检超过12个小时北京昌平警方回避不 |
|
热帖:为什么我们应该感谢雷洋的妻子(图) |
|
雷洋死有余辜! |
|
[原创]由雷洋事件看恶警李乐斌杀人未受惩罚的危害性 |
|
[原创]支持雷洋遗孀依法起诉诬陷其亡夫的媒体 |
|
雷洋之死的真相究竟是什么? |
|
[原创]雷洋,愿你的名字叫做公正与法治【猫眼看人】- |
|
雷洋事件,显示了老百姓的焦虑,不安全和无助感_网罗天下_天涯论坛 |
|
'嫖娼者'雷洋的安全感要不要保护 |
|
亦忱:简评陈有西代理雷洋案的前景 |
|
雷洋案新证据浮现:警察有问题 |
|
雷洋之死的两个最重要真相! - 云中茶社 |
|
[原创]由雷洋事件看恶警李乐斌杀人未受惩罚的危害性 |
|
雷洋家属发表声明:警方的做法是在混淆视听 |
|
昌平警方的行为完全合法! |
|
周小平:酷吏以法杀人,奸生以文灭口-真相为何败给愤怒?-第6页- |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
[原创]三点详析雷洋事件严重亏空损耗了XX公信力! |
|
雷洋有没有嫖娼,有一个绝招,立刻就能见分晓! |
|
风云洞评劣等民族情商高?(图) |
|
周小平:酷吏以法杀人,奸生以文灭口-真相为何败给愤怒?-第6页- |
|
周小平:酷吏以法杀人,奸生以文灭口-真相为何败给愤怒?-第6页- |
|
雷洋有没有嫖娼,有一个绝招,立刻就能见分晓! |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
涉案警方擅自检验死者DNA是否涉嫌违法犯罪? |
|
贾冀豫__北京出租车司机说雷洋是打死的 |
|
【风青杨专栏】对不起,我并不想知道雷洋如何嫖娼(第8页)_天涯杂谈_天涯论坛 |
|
雷洋之死让普通人感到无比恐惧 |
|
雷洋之死或可推动社会三大进步 |
|
雷洋之死让普通人感到无比恐惧 |
|
这不是两个人死亡的问题_社会热点_中华网社区- |
|
解密雷洋之死的根本原因!-常德 |
|
性价比。。。。_上海汽车论坛_XCAR |
|
有见过抓嫖不在店里抓现行而在马路上盘查的吗 |
|
雷洋嫖娼离奇死亡案。 |
|
重大消息!国资委官员嫖娼被抓猝死(组图) |
|
这不是两个人死亡的问题 |
|
张鸣:雷洋之死 |
|
雷洋案,网友如何“推波助澜”?全民一起破案,真相越来越近了吗?- |
|
人大硕士求救帖,几乎每一段都充斥着谎言! |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
2016年05月13日 |
|
人大的校友别再发声了,77,78,84,88级的 |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
《雷洋案》引起北京公安局领导高度重视 |
|
雷洋是不是嫖娼不重要?扯淡!笔者用十点给某些人普法 |
|
快讯!雷洋家属正式控告警方涉嫌犯罪 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
雷洋事件也许将有助中国执法部门的公正、警醒? |
|
那些声嘶力竭认为雷洋嫖娼该死的人,他们是些啥人? |
|
雷洋事件也许将有助中国执法部门的公正、警醒? |
|
关注小人物的命运!就是关注自个命运!小人物之死网友理应关注 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
“欺负死人不能说话”乃世间首恶 |
|
“欺负死人不能说话”乃世间首恶 |
|
拿雷洋殒命事件大肆鼓噪的那些人,可把死者一家人害惨了 |
|
“欺负死人不能说话”乃世间首恶 |
|
[原创]“欺负死人不能说话”乃世间首恶 |
|
力瑾:還有多少國人在意雷洋案的真相? |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
警方续昌平涉嫖男子在查处过程中突发死亡通报有无问题 - 第2页 - 警务探讨 |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
雷洋案:为何警方信息发布总显得很被动? |
|
【视点】比雷某嫖娼事件真相更可怕的,是“相信”尽失! |
|
【时评】雷洋事件,送环球时报两字无耻 |
|
中国人民大学88级部分校友就雷洋同学意外身亡的声明 |
|
'嫖娼者'雷洋的安全感要不要保护 |
|
打飞机为何没有改变雷洋案的舆情走向? |
|
一个昌平“嫖娼者”为何引燃了全国公众的怒火?(转) |
|
十族沦为下一个魏则西比雷洋尤恐怖 - 有图有真相 - 中豫爆料 |
|
十日谈;我想说几句了,关于何新的两篇文章_中华论坛_中华网社区- |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
【今言野语】副省长私访被警察殴打的社会问题?_新闻众评_天涯论坛 |
|
[原创]雷洋死亡案铁证如山,雷洋没有白死 |
|
雷洋死亡案铁证如山,雷洋没有白死 |
|
说雷阳打飞机我的看法不成立!_中华论坛_中华网社区- |
|
陈中华;警察威严不容丧尽,法律遵严不容侵犯_中华论坛_中华网社区- |
|
为违法警察洗地,无耻!_中华论坛_中华网社区- |
|
雷洋事件,某些人已经玩过火了! |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋事件:雷洋律师团调集近20位律师参案 |
|
雷洋事件:雷洋律师团调集近20位律师参案 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
转载:一个昌平“嫖娼者”为何引燃了全国公众的怒火?|洛阳城事 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷洋之死第二季 |
|
规范警务活动:从雷洋案开始 |
|
雷洋之死击碎了中产阶级的优越感! |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
李悔之:比雷洋之死更可怕的是龙兴伟 |
|
从雷洋案看科学研究思维在生活中的应用 |
|
从雷洋案看科学研究思维在生活中的应用 |
|
人大部分88级校友就同学雷洋身亡声明:对恶我们不会忍太久全文 - 中国禁闻网 |
|
民主到底能不能当饭吃? |
|
对警察说两句,你们不感到愧疚吗 |
|
涉嫌嫖娼男突发死亡,你怎么看?- |
|
雷洋事件,让我想起那些年采访过的奇葩嫖娼案_三秦网 |
|
雷洋被嫖被死案,急呼性合法化_京味悠长_天涯论坛 |
|
贪官雷洋嫖娼被抓,畏罪拘捕逃跑未遂身亡 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
[原创]我又不嫖娼,我为什么会成为下一个雷洋 |
|
我们追问雷洋是怎么死的,他们却要证明他是怎么嫖的! |
|
雷洋怎么死的,我来分析下。 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷洋妻儿父母岳父母的今后生活北京警方必须承担- |
|
雷洋案件之疑点-第5页- |
|
投票赢取《狄仁杰之神都龙王》.. |
|
《意外的恋爱时光》都市剩男&.. |
|
为您梦想中的“土豪人生”投票.. |
|
雷洋事件需要真相而非真像 |
|
雷洋案件之疑点-第3页- |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
拍案尖笑(集锦) |
|
雷阳事件现场群众偷拍视频 |
|
雷洋疑案:史上效率最高最变态最廉价的嫖娼 |
|
雷洋事件解决不好,非正常死亡可能成为常态【时局深度】- |
|
雷洋事件解决不好,非正常死亡可能成为常态 |
|
老徐:雷洋事件需要真相而非真像 |
|
雷洋事件,让我想起那些年采访过的嫖娼案 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
警察能让处女嫖娼,何况男士乎? |
|
雷洋事件解决不好,非正常死亡可能成为常态_中华论坛_中华网社区- |
|
雷洋事件解决不好,非正常死亡可能成为常态_中华论坛_中华网社区- |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
雷洋之死击碎了中产阶级的优越感! |
|
雷洋之死击碎了中产阶级的优越感! |
|
贾冀豫__北京出租车司机说雷洋是打死的 |
|
”这份“公平正义”,雷洋听不到了,但我们必须感受到!(第2页)_重庆_天涯论坛 |
|
警察能让处女嫖娼,何况男士乎? |
|
让子弹飞一会:人大硕士涉嫖身亡(集中讨论)(第2页)_国际观察_天涯论坛 |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
这些事发生在啥国度?! |
|
德媒:雷洋之死公信力缺失之下人人自危(图) |
|
德媒:雷洋之死公信力缺失之下人人自危(图) - 中国禁闻网 |
|
德媒:雷洋之死公信力缺失之下人人自危(图) |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
对不起,我并不想知道雷洋如何嫖娼-邵阳 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
罗竖一:检方应尽快就雷洋一案启动侦查程序 |
|
雷洋死亡案,我持消极看法 |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
张鸣:雷洋之死 |
|
说服公众 |
|
【话题】常识变为异端的社会 |
|
下一个“雷洋”不会太远,或是你我,或在身边- |
|
下一个“雷洋”不会太远,或是你我,或在身边- |
|
被雷洋案击中的那根弦 |
|
雷洋案与毒地案有关?网传因特殊身份致死(组图) |
|
警方:已證實雷洋有嫖娼行為 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
雷洋嫖娼案的所有证据都是事后补上? |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
雷洋嫖娼案的所有证据都是事后补上?(图) - 中国禁闻网 |
|
重要质疑:就雷洋案请教昌平警方几个问题-常德 |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
关注雷洋,也关注人民警察 |
|
[原创]就雷洋案请教昌平警方几个问题 |
|
没有嫖娼动机的说法很可笑 |
|
[原创]雷洋死亡原因的最简单分析 |
|
雷洋案新证据浮现:警察有问题 |
|
三个字道破宇宙真理,破解《道德经》三千年谜团。 |
|
雷洋家属状告公安局全体民警,称雷洋没嫖娼,一切都是警方伪造,故意杀人后伪造事实 |
|
[原创]凯迪何公然支持传谣?!有关“雷阳视频”的真相 |
|
[原创]十年一觉京华梦赢得娼平嫖客名 |
|
雷洋“嫖资收据”铁证如山_胜利社区_东营论坛_油城茶座 |
|
985各校新闻量排行 |
|
张鸣:雷洋之死.............. |
|
尸检结论获一致认可前雷洋遗体不会被火化 |
|
[原创]洗脚女,昌平警察提供了雷洋没有进入洗脚店的证据 |
|
民主到底能不能当饭吃? |
|
识不足则多虑,不要因个别负面事件过于恐慌 - 我说深圳事 |
|
谁在妖魔化中国人 |
|
中国人开始追求免于恐惧的自由 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
致人“屁股开花”的警察有兽性无人性 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
雷洋事件,某些人已经玩过火了! |
|
中国人开始追求免于恐惧的自由(转载)_邯郸_天涯论坛 |
|
[原创]雷洋案:“我上车,我必死” |
|
公知们,不要搬起石头砸了自己的脚(转载)_时尚资讯_天涯论坛 |
|
质疑雷洋案件十大疑点 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋妻报案:有充分证据警察涉故意伤害致死罪(图) |
|
[原创]雷洋案:“我上车,我必死” |
|
欲追究警方刑責雷洋家屬向北京市檢報案 | 暴力執法 | 大紀元 |
|
欲追究警方刑责雷洋家属向北京市检报案 |
|
[原创]雷洋家属及代理律师已提出刑事起诉 |
|
雷洋事件,某些人已经玩过火了! |
|
欲追究警方刑事责任雷洋家属向北京市检报案 - 中国禁闻网 |
|
四川省纪委与厅纪委过去有结论吗?王书记上任后又是什么结论?- |
|
四川省纪委与厅纪委过去有结论吗?王书记上任后又是什么结论?- |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
每日大盘走势预判和盘中分时高低点的实时分析 |
|
各国《宪法》中几种《权利法案》之比较 |
|
除了移民我们还有什么更好的选蔡慎坤 |
|
家属最大的交代和安慰 |
|
雷某嫖娼案最终结果的终极预测-第2页- |
|
很奇怪,没抓现行,雷洋已死,警方是怎么锁定雷洋所嫖失足女的? |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
民主到底能不能当饭吃? |
|
[原创]雷洋死亡案,已经形成死结 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
民主到底能不能当饭吃? |
|
雷洋事件引发更深刻的社会问题 |
|
蔡慎坤:雷洋之死真相早己大白于天下 |
|
民主到底能不能当饭吃? |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
蔡慎坤:雷洋之死真相早己大白于天下 |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
[原创]三点详析雷洋事件严重亏空损耗了XX公信力! |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
蔡慎坤:我們為什麼恐懼為什麼憤怒? |
|
童大焕:中国人开始追求免于恐惧的自由|洛阳城事 |
|
蔡慎坤:我们为什么恐惧为什么愤怒? |
|
雷洋是否嫖娼和怎么死亡证据链暴光 |
|
童大煥:中国人开始追求免于恐惧的自由- |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
赏析《还原雷洋之死》(续) |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷剧大反转之二:让子弹飞一会儿(ZT) |
|
国资委官员嫖娼死的“春秋笔法”- |
|
程序正义高于实质正义的理念,规则重于道德的理念,生命高于一切的理念_胜利社区_东营论坛_油城茶座 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
雷洋事件需要真相而非真像 |
|
雷洋之死真相早己大白于天下 |
|
几乎所有关注雷洋之死的舆论和公 |
|
雷洋,你能否为暴力执法敲一个警钟?_新浪杂谈_历史论坛_新浪网 |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
雷洋之死真相早已大白于天下【猫眼看人】- |
|
[原创]雷洋家属有责任立即单方面公布解剖真相 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
老徐:雷洋事件需要真相而非真像 |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
下一个雷洋是谁? |
|
律师从法律角度看雷洋案:警方认定嫖娼的事实不能成立_中华论坛_中华网社区- |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
力瑾:還有多少國人在意雷洋案的真相? |
|
国资委官员嫖娼死的“春秋笔法”——雷洋事件再反转_中华论坛_中华网社区- |
|
“友邦人士,莫名惊诧,长此以往,国将不国”:是不是鲁讯的文章?!_汽车时代_天涯论坛 |
|
“友邦人士,莫名惊诧,长此以往,国将不国”:是不是鲁讯的文章?! |
|
雷洋“嫖资收据”铁证如山_胜利社区_东营论坛_油城茶座 |
|
让子弹飞一会:人大硕士涉嫖身亡(集中讨论)(第2页)_国际观察_天涯论坛 |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
人大硕士雷洋真的嫖娼了吗?十三省 |
|
下一个'雷洋'是谁? |
|
雷洋之死击碎了中产阶级的优越感! |
|
雷洋嫖娼,谁嫖了法治? |
|
为北京警方的“嫖资收据管理”叫好 |
|
通过雷洋案,都要洗干净自己的灵魂,多一份正能量,就少一份阴暗 |
|
我服了雷洋家人了,到底要闹哪样?没见过这么无赖的(第5页)_天涯杂谈_天涯论坛 |
|
雷洋之后谁会成为替补 |
|
蔡慎坤:雷洋之死真相早己大白于天下 |
|
【普欣夜话】拿嫖娼说事,最终谁会被嫖娼?(第3页)_天涯杂谈_天涯论坛 |
|
雷洋猝死政府忙公关:雇水军、删贴、掉包视频 |
|
[原创]雷洋嫖娼,谁嫖了法治?【猫眼看人】- |
|
昌平警方说明其实暗示了真相宽带山KDS-宽带山社区-第一城市消费门户 |
|
[原创]雷洋嫖娼,谁嫖了法治?【猫眼看人】- |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
端宏斌:国资委官员嫖娼死的“春秋笔法” - 警务探讨 |
|
雷洋案:检方已出手,“涉嫖死”真相,在这 |
|
讨论:雷洋案应抓重点,不然就被人给误导了 |
|
汪剛強:從鄧玉嬌到雷洋 |
|
昌平警方说明其实暗示了真相 |
|
'嫖娼者'雷洋的安全感要不要保护 |
|
成年男子安全路过洗脚屋行动指南 |
|
妻子不关心嫖娼 '雷洋之死'还存疑点真相究竟是什么妻子不关心嫖娼,'雷洋之死'还存疑点。硕士雷洋死亡之夜到底发生了什么?雷洋死了,意外地死在一起嫖娼事件当中,揪住全社会的心。今日,有协调处理此事的警员感叹舆论发酵到这般程度,受到伤害最大的是家人…… |
|
雷洋案中警方存在'钓鱼'抓嫖的可能 |
|
人大硕士雷洋之死 |
|
对“如果雷洋没有死”的一些推论 |
|
端宏斌:国资委官员嫖娼死的“春秋笔法”_上海汽车论坛_XCAR |
|
再次重复:雷洋死后谁是下一个? |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
国资委官员嫖娼死的“春秋笔法”- |
|
雷洋事件引发更深刻的社会问题 |
|
童大煥:中国人开始追求免于恐惧的自由- |
|
中国人开始追求免于恐惧的自由 |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
新华社连发两篇评论追问 |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大法学院就雷洋案举行研讨会案情惊动联 |
|
昌平警方的行为完全合法! |
|
嫖娼釣魚執法,坐地分贓 |
|
深度剖析雷某嫖娼案… |
|
姜杰律师:雷洋案件管辖权的法律分析 |
|
雷洋案件之疑点-第4页- |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
嫖就嫖了,何必美其名——“被嫖娼”?|【新鲜茶馆】 |
|
雷洋案真相不难搞清,但很多人打死也不愿相信 |
|
央视:足疗女帮雷洋打飞机,帮助他射精你怎么看? |
|
看“嫖资收据”雷洋嫖娼铁证!(图) |
|
雷洋之死背后的阴谋论- |
|
雷洋案真相不难搞清,可怕的是有人就是打死也不愿相信 |
|
雷洋之死背后的阴谋论 |
|
人大部分88级校友就同学雷洋身亡声明:对恶我们不会忍太久全文 |
|
不成为下一个雷洋:就要围观不悲观 |
|
蔡慎坤:血与泪的控诉还原雷洋遇害真相 |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
雷洋惊天大推论——喊假警察居然为报信 |
|
觀察:徹查雷洋案誰是獨立方? |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
雷洋妻子正式报案:嫖娼是栽赃,致命处睾丸异常肿大_中华论坛_中华网社区- |
|
转发雷洋案刑事报案书:描述死亡过程(真相即将到来)-衡阳 |
|
血与泪的控诉还原雷洋遇害真相- |
|
雷洋事件:有百姓的信任危机,或许也有被利用!_中华论坛_中华网社区- |
|
雷洋死亡当晚到底发生了什么?央视专访当事警察 |
|
雷洋妻子正式报案:嫖娼是栽赃,致命处睾丸异常肿大 |
|
雷洋家属向北京市检报案要求侦查涉事民警湖南人在北京-常德 |
|
雷洋家属向北京市检报案要求侦查涉事民警- |
|
雷洋案「刑事報案書」細述雷洋之死經歷 | 刑訊逼供 | 暴力執法 | 大紀元 |
|
'他沒有嫖娼時間' 家屬報案指雷洋被無辜毆死 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
血与泪的控诉还原雷洋遇害真相 |
|
雷洋事件:有百姓的信任危机,或许也有被利用! |
|
'刑事报案书'细述雷洋之死:外力伤害所致 |
|
雷洋是不是嫖娼不重要?扯淡!笔者用十点给某些人普法 |
|
雷洋死有余辜! |
|
雷某的家人实在太不要脸了! |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
血与泪的控诉还原雷洋遇害真相 |
|
雷洋妻子报案,事件最新爆料!嫖娼是栽赃,雷洋被打死-休闲侃吧- |
|
质疑雷洋案件十大疑点 |
|
[原创]雷洋遗孀之报案书等于官媒的死刑判决书 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋最新情报:“刑事报案书”描述雷洋之死经历 |
|
关于要求北京市检察院立案侦查雷洋被害案的刑事报案书(转载) |
|
我们为什么要关注雷洋之死? |
|
雷洋案刑事报案书- |
|
雷洋案刑事报案书,警方涉嫌故意伤害(致人死亡)罪、滥用职权罪、帮助伪造证据罪- |
|
转帖:雷洋妻子向北京市检察院报案:嫖娼是栽赃,雷洋被打死 |
|
雷洋死有余辜! |
|
1) 雷洋家属告控告警方 2) 雷被殴打致死当日是雷结婚纪念日 3)尸检结果延迟到60天出结果 |
|
一个昌平“嫖娼者”为何引燃了全国公众的怒火?(转) |
|
陈有西律师曝雷洋案发现最新一个重要疑问 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
别忘了雷洋案中被抓的另五名嫌疑人 |
|
雷洋父母看完遗体向专家证人痛哭下跪 |
|
四川省纪委与厅纪委过去有结论吗?王书记上任后又是什么结论?- |
|
求助帖:别忘了雷洋案中被抓的另五名嫌疑人 - 有啥说啥 |
|
那些声嘶力竭认为雷洋嫖娼该死的人,他们是些啥人? |
|
雷洋事件昌平警方两份通报比较出的问题 |
|
别忘了雷洋案中另五名被抓的嫌疑人 |
|
父母看完遗体向专家证人痛哭下跪-常德 |
|
[原创]雷洋死亡案,已经形成死结 |
|
[原创]警察蜀黍为何喜欢抓嫖? |
|
崔家楠律师认为:确定雷洋死亡的时间,比确定死亡的原因更重要! |
|
歐陽南山:下一個雷洋是誰? |
|
童大煥:中国人开始追求免于恐惧的自由- |
|
[原创]雷洋,愿你的名字叫做公正与法治【猫眼看人】- |
|
我们追问雷洋是怎么死的,他们却要证明他是怎么嫖的! |
|
雷洋没有抗拒执法,铁证如山!证据就在此 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
哀悼环保烈士雷洋|龙虎文苑 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
雷洋案:守住私德的底线,恢复人性的的良知(第7页)_关天茶舍_天涯论坛 |
|
雷洋案件的焦点应该回归到如何死亡的问题上_文学论坛_中华网社区- |
|
雷洋案件的焦点应该回归到如何死亡的问题上_社会热点_中华网社区- |
|
小区内现蛇窝:5条大蛇吓得消防员直冒汗(图) |
|
程序正义高于实质正义的理念,规则重于道德的理念,生命高于一切的理念_胜利社区_东营论坛_油城茶座 |
|
雷洋的父母下跪为哪般?(原创) |
|
明天就是5.16,大家还是说点什么吧 |
|
[原创]雷阳事件肯定不是跨区执法 |
|
雷洋案中,当事警察说谎了没有? |
|
雷洋案中,当事警察说谎了没有? |
|
天啊——这位律师是在为雷洋鸣不平吗?!_中华论坛_中华网社区- |
|
童大焕:中国人开始追求免于恐惧的自由- |
|
童大焕:中国人开始追求免于恐惧的自由- |
|
童大焕:中国人开始追求免于恐惧的自由- |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
雷洋案件的焦点应该回归到如何死亡的问题上 |
|
雷洋案件的焦点应该回归到如何死亡的问题上 |
|
关注小人物的命运!就是关注自个命运!小人物之死网友理应关注 |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
律师:事后搜集卖淫女的供词根本不能作为证据! |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
天啊——这位律师真是在为雷洋鸣不平吗?! |
|
中国人开始追求免于恐惧的自由 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
我们关注雷某事件的重点:执法人员滥用职权、非法拘禁致人死亡_娱乐八卦_天涯论坛 |
|
律师从法律角度看雷洋案:警方认定嫖娼的事实不能成立-常德 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
雷洋之死击碎了中产阶级的优越感! |
|
力瑾:还有多少国人在意雷洋案的真相? |
|
人大硕士之死果然反转了,这小脸,抽得啪啪的响!(转载)(第35页)_娱乐八卦_天涯论坛 |
|
雷洋之死击碎了中产阶级的优越感! |
|
致人民大学88级部分校友:看了你们的声明我很无语(转载)(第2页)_网罗天下_天涯论坛 |
|
律师从法律角度看雷洋案:警方认定嫖娼的事实不能成立_中华论坛_中华网社区- |
|
雷洋案中案和常州毒地案有關係 ?? |
|
雷洋死于无知 |
|
雷洋嫖娼,谁嫖了法治? |
|
【话题】关于垒洋之死的问答 |
|
通过雷洋案,都要洗干净自己的灵魂,多一份正能量,就少一份阴暗 |
|
如果雷洋案发生在美国 |
|
再次重复:雷洋死后谁是下一个? |
|
人大法学院就雷洋案举行研讨会案情惊动联合国 |
|
狗哥评论雷洋事件!_天涯杂谈_天涯论坛 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
朋友圈骂交警“擦亮狗眼”被拘2日是执法滥权 |
|
雷洋之死或可推动社会三大进步 |
|
议雷洋之死 |
|
看了这么多人关心雷阳事件,我感觉警察存在钓鱼执法行为。_新闻众评_天涯论坛 |
|
雷洋屍檢釐清死因 校友發聲明轟警違法瀆職 - 東網即時 |
|
再次重复:雷洋死后谁是下一个? |
|
戴套打飞机 |
|
雷洋怎么死的? |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
雷洋这事,关键看标题 |
|
雷洋之死牵动人大校友上百人联署声明要真相 |
|
雷洋案中案神秘便衣牵出常州毒地案 |
|
雷洋家属指警方误导公众 |
|
雷洋案新证据浮现:警察有问题 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
“雷洋嫖娼”案惊动联合国 |
|
立此存照:雷阳的事情经过 |
|
BBC:雷洋之死背后中国人对中国没信心(图) |
|
雷洋死后的人血馒头,不知道网上各位公知吃的好不好? |
|
张鸣:雷洋之死 |
|
观察:雷洋事件舆论风暴眼中的盲点 |
|
朱征夫:卖淫嫖娼收容制度违宪,早该废 |
|
雷洋嫖娼案的所有证据都是事后补上? |
|
为什么雷洋案这么高的社会关注度能持续一周时间? |
|
重要质疑:就雷洋案请教昌平警方几个问题-常德 |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
人大校友声明是粗暴干涉司法的恶劣行为 |
|
关注雷洋,也关注人民警察 |
|
”这份“公平正义”,雷洋听不到了,但我们必须感受到! |
|
[原创]细思极恐,雷洋之死或有更深内幕 |
|
[原创]就雷洋案请教昌平警方几个问题 |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
对雷洋家属说几句话 |
|
橫河:雷洋案為什麼應該懷疑警方 |
|
贪官雷洋嫖娼被抓,畏罪拘捕逃跑未遂身亡 |
|
雷洋死亡案铁证如山,雷洋没有白死 |
|
雷洋父母看完遗体向专家证人痛哭下跪 |
|
雷洋是不是嫖娼不重要?扯淡!笔者用十点给某些人普法_中华论坛_中华网社区- |
|
【江西卫视】北京昌平的警方 |
|
雷洋尸体应严加监控,以防M帝下手 |
|
童大焕:必须全面还原并公开雷洋案执法过程 |
|
对不起,我并不想知道雷洋如何嫖娼-邵阳 |
|
大反转:目击者详述雷洋事发过程:警察没打人!请火速扩散! (转载)_婆媳关系_天涯论坛 |
|
[原创]警方塑造出神一般的雷洋 |
|
雷洋案尸检初步结果出炉:等待病理结果警方回避不在现场 |
|
雷洋之死的看法_北京_天涯论坛 |
|
【调查】探访雷洋案'神秘'专家证人张惠芹 |
|
雷洋用牺牲捍卫一个公务员的尊严!!!!! |
|
雷洋尸检超12小时家属请她全程监督 |
|
“雷洋事件”终于开了个好头 |
|
雷洋之死真相早己大白于天下(转帖)- |
|
雷洋之死击碎了中产阶级的优越感! |
|
滨州刑警支队原副支队长张惠芹,作全程见证雷洋尸 |
|
雷洋案:尽管真相还在路上,三种共识可以先到 |
|
雷洋没有抗拒执法,铁证如山!证据就在此 |
|
雷洋尸检超12小时警方回避家属坚持请她全程监 |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
下一个雷洋是谁? |
|
“雷洋嫖娼”案惊动联合国 |
|
十日谈;我想说几句了,关于何新的两篇文章_中华论坛_中华网社区- |
|
雷洋案蹊跷中国官方的处理手段令人心寒 |
|
郭宝胜呼吁海内外人大校友都来关注雷洋案, 为雷洋讨取公道 |
|
[原创]雷洋没有抗拒执法,特证就在此。 |
|
雷洋是否嫖娼不重要?怎么就不重要了?!很重要好吗!_天涯杂谈_天涯论坛 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
看“嫖资收据”雷洋嫖娼铁证!(图) |
|
警方续昌平涉嫖男子在查处过程中突发死亡通报有无问题 - 第2页 - 警务探讨 |
|
【麻辣舆情】人大硕士雷洋非正常死亡舆情分析-麻辣棱镜舆情通- |
|
从目击者证言和记者调查的报道看被忽略的雷洋事件关键点 |
|
人大硕士涉嫖身亡死因蹊跷背后真相》给人民一个交代 |
|
应当理直气壮的为“暴力执法”正名! |
|
他嫖不嫖娼关我屁事,我只关心他到底是怎么死的 |
|
雷洋“打飞机”能把自己打死吗? |
|
家属澄清雷洋调查常州毒地等三传言 |
|
雷洋被强押致死案,槽点多多,警方说辞漏洞百出 |
|
时代尖兵:雷洋的官方背景值得关注! |
|
雷洋案的焦点就是有没有受到粗暴对待? |
|
雷洋真嫖娼了吗? - 第2页 |
【相关】
韩春雨事件
http://blog.sciencenet.cn/blog-362400-977111.html
上一篇:【deep parsing:“对医闹和对大夫使用暴力者,应该依法严惩"】
下一篇:【新智元笔记:巨头谷歌昨天称句法分析极难,但他们最强】
12 许培扬 武夷山 蔡小宁 魏焱明 黄永义 汤伯杞 徐晓 苏德辰 张阳阳 侯成亚 gaoshannankai aliala
发表评论评论 (14 个评论)

- 删除 回复 |赞[12]liudongshen
- 警察为什么热衷这项事业?因为这项事业在中国首先具有道德制高点。违法不违法只是技术问题。莫须有的道德污点却在中国更具备杀伤力

- 删除 回复 |赞[11]张阳阳
- 和某个教授一下,是恶法杀人。
这个嫖娼条例,压榨了失足妇女(她们都要直接或变相的缴纳保护费或罚款),恐吓了嫖娼者(如解决生理需求的雷洋同学),肥了某些部分的腰包,增加了社会的不安定因素(如强奸)。这样的恶法,还不能废除,大抵是披着道德的外衣吧。

- 删除 回复 |赞[10]dafwlg
- 围观此事件人群有各种心态:
1、哇!嫖娼!看看有图没?看看真正的嫖娼现场什么样的!满足一下猎奇心理,我还没嫖过呢!
2、哼!硕士也嫖娼吧!学习好怎么了,我当年一直学不好,一直被你们排挤,很自卑!
3、嫖娼被打死也活该!
4、嫖娼也不应该打死啊!

- 删除 回复 |赞[9]gaoshannankai
- 雷洋一案-嫖娼问题是关键问题
http://blog.sciencenet.cn/blog-907017-976650.html
核心是 嫖娼

- 删除 回复 |赞[3]junkscience
- 当最后的结论与大数据不符合时, 就是对大数据最不可靠,最不科学的审判

- 删除 回复 |赞[2]魏焱明
- 我刚刚写了一个呼吁,欢迎好友及时推荐。
《“雷洋事件”是催生文明徭役抵罚和发展慈善机构的大好契机!》http://blog.sciencenet.cn/blog-2339914-977077.html
|
|
大数据淹没下的冰美人(之二)(屏蔽留存)
大数据淹没下的冰美人(之二)
屏蔽 |||


女神 or 妖精,总之不似人类
好,我们开始范冰冰的社媒深度挖掘,看看网友都怎么说她。
先看网友的赞美(绿字体)和吐槽(红字体)等情绪化评语的词云分布,显然是东风压倒西风:
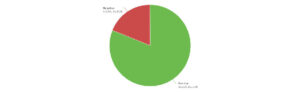

分类总结前五类情绪评语如下。
先看赞誉,毫无悬念,迷恋她、惊艳其美和粉丝的溢美之词占绝大多数,见(1)(2)(3):
(1) 喜欢, 爱,迷恋, 羡慕, 中意, 享受, 怀念, 惊喜,飞吻,?,相中, 看中
(2) QQ, 粉丝,给力,成功,最强,很火,不错,很好,最佳,可爱,受欢迎
(3) 美, 美爆, 绝美, 女神, 传奇, 完美,逆天,耀眼, 精彩, 更胜一筹
(4) 倾国倾城,性感,威武,强大,厉害,独特, 优雅, 经典, 华丽
(5) 支持, 欣赏, 赞, 夸赞, 看好, 期待, 关注
有意思的是(4)中系列形容词所发出的信息:把倾国倾城、性感厉害、优雅华丽与威武强大等集合起来,在当今华裔女星中是不多见的,她反映冰小姐的御姐女皇范儿给观众留下的印象,她是独特的。冰美人绝不是传统的温婉贤淑小家碧玉类的女子。
各花入各眼,萝卜青菜各有所爱,她这一款自然不会人人喜欢。作为娱乐界耀眼的公众人物,在排山倒海的网友和粉丝的赞誉中,自然也不免被吐槽,也分五类如下:
(1) 不喜欢, 吐槽, 讨厌, 抱怨,烦, 骂, 恨, 气,不爱, 不欣赏, 不羡慕,失望, 无语, 受不了,无法忍受,
大跌眼镜,大失所望
(2) 质疑, 怀疑, 鄙视, 讽刺, 嘲讽, 不接受, 批评, 不关注, 抵制, 看不上, 看不惯,不看好,看不起
(3) 不美, 不好, 差, 破, 不怎么样,不完美, 不行, 没多美,没有我美,算不上一流,一无是处, 不给力
(4) 低能儿蠢货, 不要脸,我操,垃圾,变态,傻逼,坑爹,这么狗血,最不要脸, 恶心,鸡肋,操, 吓人,
美个屁,挖鼻屎,白痴,二货
(5) 还不如现在的张馨予,还不如穆婷婷可爱,太胖,臃肿,
第一类表达各种程度的不喜欢不欣赏,第二类是各种鄙视看不惯,第三类酸溜溜的多少带有嫉妒的不屑,这些大多是口味问题,或者源于人皆有之的某种小小的嫉妒之心。第四类竟是破口大骂了,这是社会媒体作为许多匿名网虫无遮挡发泄负面情绪的一个反映,你美了就骂你蠢,你急智就骂你丑,总之是无冤无仇也要骂娘,特别是要骂名人。倒是第五类的负面信息最为具体,说她不如张美人穆美人(张穆都是啥妖精,怎么从来没听说过,演过啥,没有一丝印象),说她太胖臃肿,虽然明显有偏见,却也不是空穴来风。
为了过来看看
@素颜锦诗 350938楼 2014-05-07 19:46:10 萝莉粉真不爱范爷这款长相的, 我觉得也许在萝莉看来, 范爷还不如穆婷婷可爱...
人总是健忘的 RT @zmt0516: 记得当年范冰冰的名声还不如现在的张馨予,现在已经被公关团队刷成女神之神了。。。
#freedom #民主 范冰冰黄裙现身体态臃肿 群众爬墙头睹芳容 组图 http://t.co/xprlcS1RdE
总体来看,情绪化用语无论正面负面,大都当不得真,只是反映了舆情的好恶分布而已。真正有价值的舆情挖掘是情绪背后的理由,为什么喜欢或者不喜欢她?这类细线条的深度舆情挖掘,我们留待下一篇博文给您提供。
【大数据淹没下的冰美人】的系列博文链接:
社会媒体舆情自动分析:马英九 vs 陈水扁(屏蔽留存)
社会媒体舆情自动分析:马英九 vs 陈水扁
屏蔽 |||
Different social images and social media sentiments for Ma Yingjiu, Taiwan President, and Chen Shuibian, Taiwan former president.
不同的社会媒体评价,截然不同的民间形象,台湾现总统马英九 vs 台湾前总统陈水扁,社会媒体自动分析的初步结果凸显二者的不同形象和风格。
(1) 高频情绪性词的词频分析的对照图示

(2) 高频褒贬描述性词的词频分析的对照图示

相关篇什:
http://blog.sciencenet.cn/blog-362400-617870.html
上一篇:两种啤酒罐的开口结构
下一篇:评《有关太阳内光子想到一个类比——金属导电》
1 王芳
【『科学』预测:A-股 看好】(屏蔽留存)
【『科学』预测:A-股 看好】
屏蔽 |||
有什么大众话题想要测试我的中文系统么?
作者: 立委
日期: 12/03/2012 17:40:25
RE: 老李,你这玩意儿能不能用来炒股啊?要是能预测股票走向,哪怕一点点,就牛大了。
能啊。见图:

自动舆情监测分析表明:A-股 看好 哎!!!
那谁谁,还不进场!据说外资已经陆续到位抄底了呢。股市应该不久会反弹。
【免责声明】舆情检测虽然大数据,很客观,无人为干扰,但是过去和现在的舆情不能成为未来预测的保证。有网友听信陪钱,概不负责。
但有听信而赚钱者,务请捐款1/10至:大数据NLP立委基金,c/o 通天塔委员会 @ 牛市。
【立委名言】总统人气犹可预测,况股市走向乎?
想起前不久总统竞选辩论来。两位总统候选人比着对中国强硬。这是美国政客惯用的竞选伎俩。由于种种原因,起飞中的中国在美国选民中隐隐成为某种威胁,对中国强硬有利于吸引选票。在野总统候选人打中国牌比较有利,因为他不必顾忌对中国现实贸易的相互依赖和利害关系。于是,罗姆尼一直批评奥巴马对中国太软弱,宣称他一旦当选,就立即宣布中国是汇率操纵国,列入操纵者黑名单意味着贸易制裁的强硬态度。奥巴马反守为攻,辩论中告诉听众,千万不要相信罗姆尼的口头激进。他指着罗姆尼说:他对中国最不可能强硬,因为亿万家财的罗姆尼有大笔投资在中国呢。罗姆尼急了,反驳说,你奥巴马回去查查你自己的退休基金的流向,我担保里面有中国概念股,这么说你也有中国投资,因此影响你对中国的政策,笑话嘛。
确实,资本唯利是图。投资理财的美国资本顾问,一个个猴精,一方面不断唱衰中国,一方面绝不会放过中国经济这块蛋糕。一边把中国概念股系列弄得垃圾似的,一方面又不失时机进来抄底。总统候选人怎么可能摘得清呢。
【相关】
http://blog.sciencenet.cn/blog-362400-639090.html
上一篇:三代 “大跃进”
下一篇:【凡事不决问 social:切糕是神马?】
尝试揭秘百度的“哪里有小姐”(屏蔽留存)
尝试揭秘百度的“哪里有小姐”: 小姐年年讲、月月讲、天天讲?
屏蔽 |||
一个偶然的系统测试,暴露出百度与“哪里有小姐”身影相随。这个发现在朋友间立即引起轩然大波,有称妙的(way to go, u r onto sth),有调侃的(曰:百度本来就源自“众里寻她千百度”嘛),有怀疑的(the results are not faked?)。阴谋论者伊妹儿我,指责此云有侮辱百度之嫌。
我跟老友说:我没有结论。有牢骚的话也是借题发挥(讽刺据传是平西王当年以扫黄为名打压挤走谷歌,为百度开道),不是正经“结论”,不足采信。但是我有数据,怎么解读这个数据见仁见智。要想发现背后的真相,还需要一番深入调查的功夫。
先谈数据:
百度在所调查的一年跨度的社会媒体统计中共出现近 227 万次,其中“哪里有小姐”与它共现 50 万次,是关联度最高的 term (占据与其共现的 top 100 关联词语之首,share:22%),这就是词云出来的背景数据:
什么是词云呢?
A word cloud displays the frequently occurring terms surfacing from a topic's text.
从一年到半年、三个月、一个月、一周、一日,永远是小姐为主题,邪门了
是不是百度上的某种广告,这么黏糊,百度甩也甩不开。竞价排名惹的祸?
请看六个月 的词云数据图:

三个月 的词云数据图:

一个月 的词云数据图:

一周的词云数据图:

一天 的词云数据图:

再看对同样的社会媒体同样的一年时段的“谷歌”的调查结果
谷歌 出现的总次数远不如 百度,只有 73万4千,但也足够多 到可以观察其关联词了

Let US Drill down: 百度小姐的真相在这里
是什么样的推手把 小姐 与 百度快照 弄得满世界都是
日期: 12/14/2012 17:40:43
一定是有人编制了程序,到各网站(包括宠物网站)张贴小姐的广告及其百度快照。


Drill down 发现很多链接,Spam 一样,点了链接进去大多已经失效了,大概已经被网管删除。
大概是删不胜删。

最后在百度直接做了一下“哪里有小姐”的搜索,果然是东土最响亮的广告词。
最后在百度直接做了一下“哪里有小姐”的搜索,果然是东土最响亮的广告词。
前一篇博文:
http://blog.sciencenet.cn/blog-362400-642614.html
上一篇:社会媒体测试知名品牌百度,有惊人发现
下一篇:“我们为什么选择在学校学习”的思考
圣诞社媒印象: 简体世界狂欢,繁體世界分享。(屏蔽留存)
圣诞社媒印象: 简体世界狂欢,繁體世界分享。
屏蔽 |||
狂欢 vs. 分享
狂欢也应该,劳苦一年了。


不过,当然是分享高出狂欢一头。
狂欢没有问题,狂到找哪里有小姐就有些过了。


大众心理里,圣诞节的 pros and cons 呢?
商品社会嘛,离不开打折!

http://blog.sciencenet.cn/blog-362400-646437.html
上一篇:手表的价值观
下一篇:WordClouds: Season's sentiments, pros & cons of Xmas
【社会媒体:现代婚姻推背图】(屏蔽留存)
【社会媒体:现代婚姻推背图】
屏蔽 |||
立委按:哈,【爱情推背图】甫问世,一个小时点击1000多次,编辑MM有立马加精,风助火势,风靡理呆成疾的科网。原来埋头基金和论文的理呆们也食人间烟火,对人性的探究兴趣一样盎然。好,再接再厉,来个姐妹篇【社会媒体:现代婚姻推背图】。
【大众心理探究:婚姻】
日期: 01/09/2013 16:39:34
所挖掘的数据源:来自中文世界社会媒体过往一年的档案,繁体约五千五百万文档,简体文档达三亿五千万。大约有一亿论坛帖子来自百度(贴吧等),两千多万来自搜狐,两千五百万来自天涯论坛。
婚姻(简体)被提及390万次;繁体被提及约 41 万次
繁简体的分别调查可以透露出大陆社区与台湾社区对待几乎永恒的话题“婚姻”的有所不同的社会认知。首先值得注意的差别在对于婚姻的总体评价上,简体世界基本是负面的,净情绪指数为-5%,而繁体世界是正面为多,净情绪指数为+5%。这正负5%共10个点的对照,虽在意料之中,仍让人嗟叹无语。祖国大陆经济起飞,社会巨变,带来的是社会的两极分化以及婚姻关系的不稳定等系列问题,从而影响了普罗百姓对婚姻的信心和评价,这是意料之中。而台湾呢,虽然生活在夹缝中,整体社会情绪还是向上的,乐观的,这在对“爱情”观念的调查中也得到印证。另一点对照就是所谓热情强度的指数,简体世界高出繁体世界五个点(21-16=5),说明海外华人社区比起国内,更加平和一些。
1. 婚姻的关系概念
可以提出的看点有:
(1)婚姻是男人与女人之间的事情(貌似废话。本来不是事儿,可如果调查美国社会媒体,可能就是事儿了:不同州法律不同,同性婚姻是敏感的热点话题,其合法化似乎有蔓延全国之势。)
(2)爱情与婚姻关联度极高(那自然)
(3)除了男女爱情老公老婆结婚证外,与婚姻概念最相关的不外乎是 家庭、父母 和 孩子,对了,还有房子(至少在大陆很多城市,房子对结成婚结不成婚至关重要)。
(4)有意思的是,婚姻问题总是与 岁月 和 时间 不可分(所谓n年之痒?)
(5)浮出水面的其他与婚姻有瓜葛的人和事包括:霍启刚(是不是那个与我们奥运之花搞世纪婚礼的大款?)、还没结婚儿子越来越多(这又是谁?有几房?)、姚晨(谁?婚姻怎么啦?)、婚纱照、婆婆、裸婚、剩女(错过了?)、假证(假结婚证还是假房产证?待查)。

看看以臺灣社會為源頭的繁體世界中婚姻的社會形象如何吧
(1)婚姻最大的concern似乎是 歲月(誰經得起歲月?樹猶如此,婚何以堪),其次就是 愛情 問題(愛情枯萎、愛情褪色?婚姻難道真是愛情墳墓?)
(2)跟愛情生活一樣,繁體世界特別重視 星座 在婚姻生活中的影響,什麽 處女座、金牛座、雙魚座,不亦樂乎,星座不同,就不能婚麽?同胞,你們也太迷信了吧。
(3)不像愛情馬拉松,婚姻的核心是行動:結婚結婚結婚,聽上去很像【義勇軍進行曲】,赴湯蹈火呢?

2. 与婚姻有关的情绪分析
情绪上,无论简体社会还是 繁体社会,围绕的核心问题就是幸福和不幸福,大多源于婚姻的破裂和失败。
似乎美满婚姻只是一个传说。婚姻需要支持,尽管如此,不幸福、不看好,破裂和失败的婚姻仍然像一个幽灵,在华人社区徘徊。以前都说西方社会乱象丛生,满大街都是陈世美,离婚率高达50%,如今起飞中的中国据说也快赶上来了。
婚姻带来的情绪对立看下图一目了然。总体来看,大陆社区正不压邪,缺乏正能量,负面情绪如病毒一样在蔓延:厌倦、烦恼、悲惨、不如意、不美满、不愉快、太荒唐、太难熬、出状况、有名无实、不能忍受。海外社區也有很多矛盾情緒和牢騷,可總體上還是東風壓倒西風,相信婚姻,渴望婚姻,享受婚姻,感到婚姻 甜蜜美滿 的也大有人在。


3. 探幽婚姻的是非得失
1. 无论繁简,婚姻世界映入眼帘都有两个大字 问题. 外交无小事,婚姻大问题。婚姻最大的问题就是问题。啥问题呢?本来我们系统是非得失的挖掘着眼于发现具体的缺点或优点,而不是抽象的问题。大概婚姻的是非太难缠了,清官难断婚内事,结果就是大大的问题,却搞不清问题所在。保不准啥问题都有。
2. 問題之外,繁體世界顯然比較美好,甜蜜、合法、穩定/固 占了主流,建議欲享受婚姻的同胞,一定要找臺灣女生,移民到臺去做乘龍佳婿,那裏似乎還有一片美滿婚姻的綠洲!简体世界可就惨了,婚姻不但 没有浪漫色彩,而且总是 不顺,不稳定,不容易。
3. 把婚姻比作 沉重的枷锁,不是首创,是很多人的真切感受。可彼岸同胞,却有称它为 一種甜蜜的負荷,行啊,同胞,服了您,简直太可爱太乐观了。


朋友,您从这些从成千上万人思想言谈中真实发掘出来的推背图系列里,又发现什么呢?您的婚姻观与大众的婚姻认知有差距么?在婚姻这古老的制度和观念上,对于您自己的切身环境以及未来社会,您是乐观派、悲观派,还是绝望族?
从爱情到婚姻,种种纠结啊,好比面对一个蜜罐转成的火坑,跳也不跳?
婚姻就是围城:颠扑不破的宇宙真理。
【立委名言】归纳是预测之母
姐妹篇:【社会媒体:现代爱情推背图】
这两天在看非诚勿扰,感觉人类迄今对于婚姻最深刻的认识就是围城论
作者: 立委
日期: 01/09/2013 13:14:24
真的是在城外的一个个拼命要钻进去
城内的呢, 隐隐约约多多少少又想出来(太累啦)。
城内的呢, 隐隐约约多多少少又想出来(太累啦)。
所谓“进化论”,其实就是对“稳态”的否定。当然不是说个体的不稳定,
作者: mirror (*)
日期: 01/09/2013 18:03:39
而是说要有“鲁棒性”。嫁 鸡随鸡嫁狗随狗,用个学术词儿的表达其实就是鲁棒性。
鲁棒性好,就可以象昆虫、寄生蟹那样拖着盔甲、房屋跑。鲁棒性不好,只有推到重建了。
----------
就“是”论事儿,就“事儿”论是,就“事儿”论“事儿”。
1 杨华磊
【社媒挖掘:臺灣政壇輿情圖】(屏蔽留存)
【社媒挖掘:臺灣政壇輿情圖】
屏蔽 |||



今天測試我們中文輿情挖掘的繁體系統,想何不借此了解一下臺灣政客的社會形象。好在臺灣是亞洲民主化程度較高的社會,並非老蔣時代,議論政客惹不了麻煩,也不會被禁聲。藍也好綠也好,不議白不議,就是剝掉皇帝的新衣,他奈我何?

說來慚愧,我對臺灣政壇並不熟悉,所熟知的政治人物不到一打。好,那就把能想到的幾位調查一下,得輿情圖一張如上。請臺灣朋友看看,靠譜不靠譜。
一眼看去,臺灣的藍綠政客幾乎全部擠在輿情圖的左下角(弱+反感),說明什麽?說明他們在民眾中的形象都不咋樣。不僅如此,大家對他們的情感也不強烈,大概是失望已久,又沒有其他備選項,已經疲怠了,無所謂了。
仔細比較,可以看出,蘇貞昌名聲最佳,毫無疑問是這次自動民調中的矮子叢中的將軍。謝長廷緊隨其後,然後才到蔡英文和馬英九。蔡(指數19)比馬(指數18)略高,但由於是當選總統,馬的議論最多(泡泡最大)。從圖上看,馬英九幾乎把蔡英文整個兒攬於懷中(滑稽不?簡直成了絕妙的政治諷刺漫畫了)。老總統李登輝的聲望則日落西山,更在馬蔡之下。
至於阿扁前總統嘛,名聲太臭,凈情緒指標-12,處於地下冰窖第18層,根本浮不上輿情圖的臺面。連戰、蕭萬長、宋楚瑜也未能浮現輿情臺面,原因不是被民眾唾棄,而是被民眾遺忘,他們根本就沒有多少議論,泡泡太小,非置於放大鏡之下不得見也。其實,論褒貶指數,連戰的凈情緒 36 才是冠軍,蕭萬長也有 33,二者均高出蘇貞昌的28一頭。詳細數據比較見下圖。

資料來源及分布:迄今一年的社會媒體檔案(正體)

【立委名言:政治輿情圖旨在計量社會公仆在社會媒體中的被關註度、褒貶度和愛憎情緒強度,反映其公眾網絡形象】
【預告】
下期【社媒挖掘】繼續比較臺灣的政治人物,顯示民眾的正反情緒,比較政客們的得失。敬請留意。
2. 【社媒挖掘:社会媒体眼中的臺灣綠營大佬】
【社媒挖掘:馬英九施政一年來輿情晴雨表】(屏蔽留存)
【社媒挖掘:馬英九施政一年來輿情晴雨表】
屏蔽 |||


【馬英九施政一年來輿情晴雨表】

看點及分析:
(1) 一年來馬英九的總體形象偏低,凈情緒指標在零度以下居多,他一直試圖改善形象,但總也不大成功。究其原因,凡臺上的政客,除非社會經濟出現奇跡般改善,作為常規,總是招致的批評遠多於贊揚。民眾總是憤怒的,而在野黨不會放過任何一個機會推波助瀾。
(2)不過一年來也有10多次短暫的亮點,聲望處於零度以上(褒大於貶),雖然都好景不長:從圖上看,去年七月初到九月初之間是正面聲望持續最長的區間(只在八月短暫跌入零度以下),不知道有什麽亮麗的政治表現還是由於團隊公關得力,有興趣的讀者可以查證一下。馬總統宣誓就職的五月中,凈情緒指標尚在零下30度左右徘徊,怎麽到了七月就迅速回暖至零度以上,持續約兩個月,直到九月2日的+35的峰值。我對臺灣政治不熟悉,也沒有精力去探究 data 和證據鏈(盡管我們的工具提供了多項 drill down 的功能),但這個區間似乎確是馬總統二度當選以來得到民眾認可的最佳時期。此後就一蹶不振,只在十月、十一月與今年元月短暫回升。一年來的最低點在三月四日的-44,十二月16日也很慘,一度跌入-42,冰凍刺骨。總而言之,馬英九自從去年初當選以來,不是很順,民眾的失望抱怨情緒彌漫網壇。
我們來看看針對馬英九的公眾情緒的雲圖,鐵桿支持相信他的藍營很搶眼,與罵他笨蛋反對他的呼聲針鋒相對。但從數據點上看,還是紅色負面情緒更多。

網民眼中馬英九之榮辱得失究竟如何?
先看馬的支持者的理由
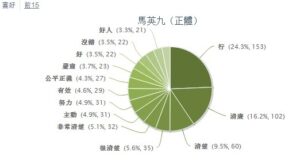
再看馬的批評者的指責
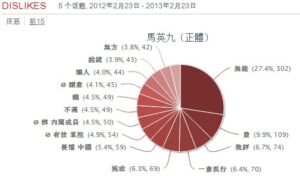
對比一下馬施政一年來的得失榮辱:

正面評價中最大的亮點是清廉,負面評價除了無能外,最大的批評就是一意孤行和畏懼中國(嫌他在兩岸關系中對大陸不夠強硬,在我接觸到的臺灣朋友中,這是一個相當普遍的抱怨)。
立委的觀感是,臺灣民眾比較煩,比較煩。馬總統要想贏得民心,光靠已有的清廉形象遠遠不夠。他要青史留名,改變無能總統的批評浪潮,扭轉其頹勢,今後三年一定要交出一份更大的成績單。
正所謂:
總統輪流做,明朝到誰家?
帥俊小馬哥,憔悴如明蝦。
【立委名言:民主總統不好玩,當家五年狗都嫌】
【相关篇什】
测试粤语舆情挖掘:拿娱乐界名人阿娇和陈冠希开刀(屏蔽留存)
测试粤语舆情挖掘:拿娱乐界名人阿娇和陈冠希开刀
屏蔽 |||
【研发笔记:粤语文句的情报挖掘】实现之后,没顾上在应用层面做测试。前两天想要做测试,但对广东香港不熟,不知道什么是他们的热点话题 。于是决定拿娱乐界名人开刀,他们的八卦永远是网民的兴奋点,不妨挖掘一下他们的网络形象。


首先想到的是阿娇。做她准粉丝已经几年了,不为别的,只为她长相让人看着舒服。华裔女演员比她名气大的多得很,但是看着比她养眼的极少。远的如巩俐大妞儿,太村姑了,长相很平,似有苦相。据说是魔鬼身材,可盘儿不靓,身材也就不作数了。大红大紫的张子怡有些小家子气。范冰冰长得怪怪的,艳丽有余,不像是真人。真正看得让人舒服的,台湾以前有一个徐若萱,大陆曾有一位邻家女孩徐静蕾,香港就数阿娇了,名如其人,娇美细嫩。对了,大陆1989年前有一位央视女主播杜宪,那是亿人迷,怎么看怎么舒服。养眼到什么程度呢,可以形式脱离内容。当年看央视新闻,内容别提多八股了,可是因为有杜宪,还是愿意看。至于阿娇,是偶然在一部武打片中发现的。从来不爱看那些打打杀杀的武打片,可是阿娇让人眼前一亮,再荒诞的内容也就剥离了。后来据说她受陈冠希之累,牵扯进艳照门负面新闻中。也难为她了,在那样的压力下,还不得不硬着头皮出来开记者会做一些澄清。记者会上一出场,依然是楚楚动人,确如她说的,太傻了,真地不值。话说回来,一辈子不做荒唐事者鲜见,她就是运气不好而已。扯远了,回到舆情挖掘上来。


除了阿娇,粤语文化圈里陈冠希据说是议论最多的一位了。他的艳照门事件很让整个华人世界兴奋躁动了一阵子。据说他是那种“坏”男人的典型,温哥华富豪华侨家出身的花花公子,party animal,讲一口流利的英语,开豪华车,酷而有型(除了泡妞,从来搞不清他擅长什么,音乐、舞蹈、演技、写作?)。那就看看舆论怎么说他吧。
下面的社交媒体挖掘,来自中文世界社交媒体过往一年的档案中被系统识别为粤语的部分。香港娱乐圈名人鍾欣桐(阿嬌)和陳冠希为挖掘对象。对不起了,只能拿名人做小白鼠了。从净情绪(net sentiment,一种褒贬比例的指数)来看,两位的社交媒体形象仍为负数,陳冠希更是低到-22%,说明网民对他的评论明显贬多于褒。
![]()
阿娇褒贬指数不高估计还是受到以前负面新闻之累(算她倒霉,碰到了陈冠希),其实粤语地区喜欢阿嬌的粉丝并不少,喜欢的理由见下图:主要是她长得年轻甜美(年轻/甜美/甜蜜:17.1%),人同此心啊。有意思的是,喜欢她的人很多具体提到她漂亮的手(18.9%)、眼睛和脸,甚至声音(其实她的皮肤也是没治了,怎么没人提?),总之她是以外在条件取胜,此乃尤物,足以移人。
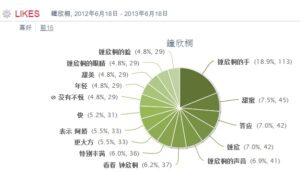
至于陈冠希,不管多少负面新闻缠身,女粉丝“喜欢”(“爱”)他的仍然不少,见下面红多绿少的【情绪云图】中的“喜欢”两个大字。真是应了那句古话:男的不坏,女的不爱。(红贬中的“如此绝情”不知是他的哪一桩孽债。)

具体的不满集中在【褒贬云图】中大大的那个“搅”字。

我们把部分网友议论陈冠希的粤语帖子附在最后。
【相关】

关于转基因及其社会媒体大数据挖掘的种种问题 (屏蔽留存)
关于转基因及其社会媒体大数据挖掘的种种问题
屏蔽 |||

没想到转基因话题这么热,随手做了一个自动调查发在博客上( 【西方怎么看转基因:英文社交媒体大数据调查告诉你】),一天多就达到 7000 点击,40 多评论。先把我对问题的回应整理如下。
【西方怎么看转基因:英文社交媒体大数据调查告诉你】),一天多就达到 7000 点击,40 多评论。先把我对问题的回应整理如下。
1. 关于数据问题
你这个数据是有问题的,想想看,美国加州、华盛顿州的公民投票结果都是不同意转基因标识,大多数民意连转基因标识都不要了,对转基因食品安全性的担心能有多少呢?这个样本比你那个说明问题吧?
博主回复(2013-12-24 10:04):这个数据是没有问题的,因为我们对于最近一个月的社交媒体是不做品牌针对性筛选的,是普适的。对于一个月之上的数据,可以根据 GM Food 这样的主题词去筛选也可以一网打尽,但是有数据成本的问题。至于数据挖掘有没有偏差?文本挖掘技术当然不可能是完美的,但是统计上没有问题,因为第三方多次测试精确度都是接近90%。
2. 关于结论的对错
转基因的安全性靠调查研究难以给出正确评价。
博主回复(2013-12-24 12:47):两码事。
安全性是科学问题,假以时间应该由科学解答,或者有些已经回答并得到权威部门认证。
舆情调查反映的是普罗百姓对事物的方方面面(包括安全性)的看法而已。
还有一点, 博文中说的Gluten引起的各种那个过敏症。 我一直都不理解美国曹氏中标识的gluten-free的食品为何就那么重要? 因为gluten就是我们中国人飞铲喜欢吃的面筋, 各位都喜欢吃油面筋塞肉, 北方人吃面要“筋”, 都是gluten含量很高的食品, 跟转基因毫无关系。
而且超市中真正gluten-free的食品货架上很少的,现在美国飞机航班上不提供花生, 只有那个非常难吃的 pretzel 据说是因为有些人对花生过敏, 所以航班不供应花生了。
博主回复(2013-12-24 17:55):听我的专家朋友说,Gluten 确实与转基因无关,是有公认的科学结论的。
那为什么舆情中,这一项作为转基因的主要问题呢?
没办法,这就是舆情,我不能改变它,只能反映它。
也许这正说明,科普还没做到家,还没能让老百姓了解和信服。任重道远。
3. 关于阴谋论
菜老师有奇文 http://blog.sciencenet.cn/blog-789923-752383.html,说:“李维先生说,该英文社交媒体大数据调查反映了民间的真实态度,这个观点看来要打个问号了。” 这个“该”字从何谈起,我们对社交媒体是一网打尽(因为企业用户要求如此),其组成和来源都在文中有交待。他下面的推测充满了细节,实在太异想天开了。蔡老师怎么不询问一下就这样胡乱猜测呢,描述了一个天大阴谋似的。
“搞这个调查的英文社交媒体的完全可能是反转基因团体控制的,其调查的人群经过了特异的选择,或者说该英文社交媒体的读者主要以反对转基因人士为主。这样的数据即使是“大数据”,又有什么意义呢?”(下划线是立委加的)
蔡老师哎,你这样善于胡乱猜测还怎么做学问呢。这是我自己主持开发的软件,用的是未经任何人控制的原始数据(英文叫做 firehose,就是直接从社交网站流出来的),没有人工干预,靠的是自然语言挖掘技术自动生成的。这样说,应该够清楚了吧。我的本行就是舆情自动调查,这只是针对热点问题,从系统输出结果而已,供大家做舆情分析时候一个参考。
说明一下,所用的软件本来是为企业用户做客户情报调查用的。社交媒体一网打尽是指在我们的 index (库存)里面,我们包括所有够得着的社交媒体,英文社交媒体从比重上看,twitter 为主,Facebook 其次,其他论坛上百万个来源只占少数,这是当今社交媒体的自然现状。
我自己是系统架构师和主要实现人,所以不时用系统挖掘热点话题,一来可以看看系统还有什么可以改良的地方,而来也算是对社区做一些大数据语言挖掘的科普展示。阴谋论简直匪夷所思。
蔡老师(2013-12-24 16:24):我的推测是否正确,不是关键。关键是你的舆情分析软件结果与公民的投票结果相反,必须做出解释,否则这样的舆情分析只会造成更大的认识混乱;如果领导据此决策了,更加有误导嫌疑。
(2013-12-24 16:15):我不怀疑你的数学分析能力,你的数学模型包括软件应该是不错的。但是,出色的数学分析能力并不能保证你的结果是正确的。牛老师比我说得更全面,还有其他网友对此也有分析。
我再将我当年的生物统计学老师说过的话告诉你,让我们共勉吧:数学模型应当建立在具有生物学意义的基础上,离开了这个基础,哪怕数据再充分、模型再漂亮,也是没有意义的。
博主回复(2013-12-24 18:07):您的思维很怪异:说什么领导据此决策错误,我就更加有误导嫌疑。
这是什么话。领导面对这么多志愿免费提供的不同侧面的信息源,依然决策错误,那就是狗屁领导,没有领导能力、决策能力,领导应该下台,这个决策错误与信息提供者有一毛钱的干系?
又:说什么数学模型要建立在生物学意义上对于我们文本挖掘媒体调查领域完全是瞎掰。我一个语言学家懂什么生物学,我做语言文本调查要什么生物学的基础?我的对象是自然语言(社交媒体),不是生物啥的。我的模型建立在语言学(语言分析,parsing)基础上,这才是我们这个领域的基础。你隔行传授的经验没有一丝的适应性和可行性。
博主回复(2013-12-24 16:44):喂,喂,我为什么要为我的自动调查与公民投票的差异做出解释?
我只是提供一个信息源而已。这个信息源是大数据高技术的结果。投票那是另外一个信息源。二者吻合还是不吻合,可能有一千个因素,我有什么责任和义务解释?
我也从来没关心过那次投票。
博主回复(2013-12-24 16:38):
您如果质疑“调查反映了民间的真实态度”,完全没有问题,因为同样的数据可能有不同解读和 interpretation
如果质疑质量或操作过程中的误差,也还不算离谱。
可您凭空从头脑想出来并 描述了我的数据被操纵的过程和细节,就让人跌破眼镜了。
4. 关于噪音处理
至于博主和蔡晓宁先生说的大数据处理的技术我不会, 还得在学习了。 不过google或百度上的绝大多数数据是垃圾数据。 如果要使用大数据处理来统计, 我建议博主把CA或Medlines或 Bological abstrct里的数据做个大数据处理,看看你能得出一个什么结论。 这些可就是科学的结论了。
至于垃圾过滤,这是任何大数据系统都必须要做的工作,我们也有这个过滤,经过几年的不断改进,测试证明英文大数据的垃圾已经不再是大问题了。
不过中文媒体的垃圾过滤还有很多工作要做,有国内微博水军和僵尸的问题。不过对于热点话题,可以只选取带 V 的样本,也就杜绝了水军和僵尸。但对于冷门话题就不好办了。
另外一个工作是避免过量重复(de-dup),英文也已经做得很好。
对于大数据处理, 我完全是外行, 现在说几句外行的话, 不对就当垃圾处理
1. 任何数据的输入的前提是数据的可靠性, 不分青红皂白的把所有数据输入, 输入的数据就没有科学性, 可靠性, 由此而来的结论当然就没有任何意义了
2. 现在网络上有所谓的大V, 用定贴机为某一个题目专门不断发帖顶贴, 所以不分青红皂白的输入这种数据, 实际上是被其他人所误导。
3. 所以要用大数据, 必须界定你的大数据来源。 否则同一事物, 被不同人选择来源, 完全就有不同的结论。
以上是外行的话。
博主回复(2013-12-24 18:35):当然你的担心是有理由的。做大数据的人当然要过滤垃圾(包括无处不渗入的色情),而且要 detect 僵尸、水军和数据的过分重复(机器人发贴)等。
大数据挖掘有没有价值很多时候是可以验证的。因此上述问题的严重程度,可以从过往的验证中得到一个大概的置信区间。细节就不谈了。
总之是,由于大数据的存在以及大数据处理能力的不断完善,舆情挖掘提供了一个难以取代的情报源,在决策中有参考价值。这是可以基本肯定的。
5. 有比较才有鉴别
其实这些问题只要放在比较的框架中就不是严重问题。虽然具体语言中褒贬比例和分布可能不同,但是如果一个对象的褒贬指数放在其他对象的褒贬指数的 reference frame 里面来阐释,其解读就比较真实。比如,在过往的许多调查中,我们知道褒贬度降到零下20以后就很不妙,说明媒体形象差,老百姓很多怨气。有了这样一个历史积累,新的品牌或话题如果达到类似的指标,解读就不大会离谱了。
特别是,我们做一个行业的多品牌调查和比较的时候更是如此。品牌A与品牌B的在舆情中的相对位置非常说明问题。系统的误差,质量的不完美,语言数据的不完整,以及语言现象的分布不匀,所有这些统统不再成为问题,除非这些差异是针对特定品牌的(这种现象基本不出现)。
这一点毛委员早就说过:有比较才有鉴别。
有比较才有鉴别,这是铁律。任何指标单看,其意义就很悬。包括我说转基因不受美国人民喜欢(零下29度),也是因为有过往的褒贬指标平均值作为 reference frame 才说的。
6. 大数据是忽悠么?
是的,有很多忽悠。但是立委论大数据不是忽悠。
》》这篇博文充分说明,“大数据”并不是神仙,完全可能得出错误的结论,“大数据”只是一种工具,要看使用者如何使用它了。
博主回复(2013-12-25 00:30):说大数据是神仙的,多半是忽悠。
今天忽悠大数据,明天其他东西流行了,就忽悠其他东西。
但是大数据给决策人(政府、企业或者犹豫如何选择的消费者)提供了一个前所未有的方便工具,去纵览有统计意义的舆情。这在以前只能通过小规模误差很大的人工问卷调查来做。如今自动化了,而且样本量高出好几个量级。拜科学技术所赐。
7. 关于系统可靠性
任何一门新的方法的建立,都需要首先用对照验证其有效性。这种抓取网络关键词,有没有与大样本的问卷调查等传统方法进行对比,验证过有效性?看到fear,就下结论说是人民害怕,也许是有人说不用fear呢?至于英文网络的数据,为什么下结论时认为只是美国人的意见,把欧洲人等排除掉了?
博主回复(2013-12-25 07:09):你提到“抓取关键词”,怀疑系统不能处理否定式(“也许是有人说不用 fear 了”),那是你不了解我的背景,虽然我在100多篇科普性博客已经多方面描述过系统的能力。简言之,我们的舆情挖掘不是通常的关键词技术,而是建立在高级得多的深度语法分析(deep parsing)之上的信息抽取和挖掘。不仅可以对付否定式,否定之否定等更复杂的语言现象也能处理。
博主回复(2013-12-25 00:59):至于意见中是不是只有美国?
这个还真可能不准确。我说的不严谨。英文社交媒体从分布上看,美国网民比重很大,但这个世界是地球村了,当可能包括西方其他国家的舆情夹在里面了。
其实很好解决,系统有地理过滤器,我可以只挖掘美国来源的社交媒体。但这样数据量就需要超过一个月的积累才好挖掘,有成本的。今后高兴了,再做吧。博主回复(2013-12-25 00:53):有没有与问卷调查以及用其他方式验证过这个系统的有效性?
有过。很多次。而且还在不断定期进行中。为什么要这样做?因为质量是系统的生命线,否则怎么取信于客户。
大数据挖掘热点话题(冷门话题数据量少,就不好说了)作为舆情的反映,基本可信,至少不比传统手工问卷差。作为决策参考没有问题。
你不必相信我的 claim。我也不必提供验证细节。你也不是我的客户。我免费提供信息,权当 raise awareness 和科普。
我的论点,您可能只看到了其中一部分。我再多说一点,人们的用词习惯在这个比较里面没有被考虑到。比如,说一个人很丑可能多数人用单词A,而说她美可能会有十种表达方式。假定认为美的有十个人,用词个不一样,说她丑的只有三个人,但看起来是显然的高频词。这不是误导吗?这种现象往往在理性精细思维和随意发泄情绪两种情况下对比很明显。
博主回复(2013-12-24 17:45):要想做这种矫正,你先得研究清楚这种现象在真实语料中确实存在,严重程度,分布如何。听上去,这一步你还停留在假说层面上。这时候说系统误导是欠公允的。
另外,一个概念有多少词来表示只会影响 Word Cloud 图示中的 fonts 的大小(其实即便在那里,我们对比较严格的同义词还是做了合并处理的,因此问题没有想像的严重),但并不影响最重要的 net sentiment (褒贬度)的指标,因为后者是根据褒贬两大类来计算,而不问具体的用词。
很多事情都是这样的:赞成的人不怎么发声,而反对的人则会闹出很大的动静。从国人对待转基因的态度到泰国黄红两派的斗争死结,这种现象在社会中普遍存在。这可能有社会心理学的解释。
因此,所谓相对客观的大数据,也许本身就已经预设了立场。博主回复(2013-12-25 11:08):这种情况是可能的。所以我说,同样的数据结果可以有不同的解读。
你可以打折来看褒贬指数。譬如,指数为零表面上似乎是褒贬民意旗鼓相当,你可以打个折扣,理解成其实是褒多于贬,只不过很多满意的人不言声而已。
这个折扣怎么打,可以根据经验法则,多一些实验也许慢慢可以显现出来。
8. 我只做民意,不介入转基因的争论
老师可以写得更简洁些,并且有学术数据支撑,而不仅仅是民意支撑么?
从学术原理上来讲风险,用数据说话,现在大家抄来抄去,感觉不专业.
博主回复(2013-12-25 00:39):我只做民意。别的你们做,或谁爱做谁做。
我不反对转基因,也不大关心转基因因为没感觉有什么危险。我的不少懂行朋友也持拥抱态度,我没有理由不相信这些专家。但是民意也需要一定程度的尊重和引导,不能强迫人们吃转基因,或任何东西。在民意有很多顾虑的时候,给民众选择的权利是合理的(除非标识成本太高:其实高成本只要转嫁给要求标识的消费群体就合理了)。
题外话:我的转基因立场
我其实没有什么立场,也没有相关的生物知识背景,转基因从来不是我关注的对象(因为是热点话题才选它当小白鼠做舆情挖掘的试验,而不是对其感兴趣)。通过朋友的争论和综述, 觉得两边的极端派掐架很难看,都有误导和蛊惑。(By the way,我觉得挺转人士当年犯了致命错误,他们不该把 GM 翻译成转基因,要是翻译成生物高科技最新改良食品伍的,就会减少很多阻力和疑虑。名不正则言不顺,言不顺则事不成。现在好多百姓听到转基因就跟听到癌症似的,你说说这个术语翻译是不是害死人。后来金大米起的名字就很好,无奈受转基因的牵累,还是遭到很多人的排斥。)
我本人不介意吃转基因食品,因为从来没有感受到有危险。我去肯德基最喜欢买的就是他们的烤玉米。从来不问出处。但事已至此,转基因就不单是科学的问题了。要上老百姓餐桌的话,老百姓的感受不能不顾及。作为一种过渡,我觉得在中国有必要给转基因食品做标识(或给非转食品做标识,one way or the other),给人民选择的权利。这个不必要循美国不标识的例,原因是国情不同,老百姓为食品安全困扰太久,井绳之忧是自然的反应。转基因的最终胜出,应该靠自己的实力,譬如价格的低廉,日益显示出来的安全性等。标识以后,科学人士和我等无所谓(畏)人士会自然成为其消费者。最后会争取到其他中间用户。至于反转死硬分子,就让他们一辈子多花冤枉钱去消费“纯天然”食品也蛮好的。
最后来点 fun,转发老友的一个评论。
浅谈立委大数据利用的局限性
作者: 田牛
1。没法评估和预测股市,黄金走势
2。看不出钓鱼岛的归属依据
3。比较不出社会主义或资本主义的优越性
4。 对国际贸易的趋势做不出专家评论
5。完全忽视不上网不用手机的(或上网用手机但不进入他搜索网络)人群的话语权,比重
6。对测量(不是影响)湾区华人选票的帮助不大
7。依然无法用大数据得出吃一顿简单中餐得到的卡路里
2。看不出钓鱼岛的归属依据
3。比较不出社会主义或资本主义的优越性
4。 对国际贸易的趋势做不出专家评论
5。完全忽视不上网不用手机的(或上网用手机但不进入他搜索网络)人群的话语权,比重
6。对测量(不是影响)湾区华人选票的帮助不大
7。依然无法用大数据得出吃一顿简单中餐得到的卡路里
暂时想到现在,希望立委有突破,我们LBC可以近水楼台先得月。
【相关篇什】
小数据和个案分析:个人在美国对转基因的感觉 2013-12-26
既然大家感兴趣,圣诞没事在家,就继续做一点转基因的大数据挖掘 2013-12-26
关于转基因及其社会媒体大数据挖掘的种种问题 2013-12-25
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24
17 陈安 刘旭霞 孙根年 强涛 蔡小宁 杨宁 常顺利 武夷山 周雄伟 薛宇 郑小康 孙平 陈儒军 周洲 卢长明 bridgeneer biofans
发表评论评论 (17 个评论)

- 删除 |赞[9]苏晓慧
- 哈哈,这个技术很好,我现在也很着迷,可惜数学不好不会玩。回归正题,我的疑问是,怎么就没有学生物的尤其是分子生物学的出来发博客说说呢,除了植物所的蒋高明,但是一家之言不可尽信。那些生物大博主们都避开了这个话题啊


- 删除 |赞[8]mirrorliwei
- 【转BT基因的BT蛋白是否引起过敏是FDA/EPA必须检测的项目】就表明了有这个担心。
这里不需要讲什么“转基因的蛋白会引起面筋过敏的实例和原理”,只要相信墨菲的定律(http://zh.wikipedia.org/zh-cn/摩菲定理):“凡是可能出错的事均会出错。”(Anything that can go wrong will go wrong.)。可引申为“若缺陷有很多个可能性,则它必然会朝着最坏、最可怕的方向发展”。
- 删除 |赞[7]王大元
- [3]mirrorliwei 2013-12-25 09:06
镜女士(李薇): 请你讲讲转基因的蛋白会引起面筋过敏的实例和原理?转BT基因的BT蛋白是否引起过敏是FDA/EPA必须检测的项目, 所有批准了的转BT基因的玉米, 其BT蛋白都没有致敏性, 你去查EPA/FDA的批准报告, 每一个批准报告在250页以上, 其中有关过敏性的试验数据大概在1-2页。
如果美国有个别人的试验报告说转BT基因的BT蛋白恶意造成面筋过敏, 那么这种试验结果先要被FDA/EPA采用, 一个在自己国家的权威部门都不采信的试验结果, 我们中国人没有必要为这种垃圾结果张灯结彩作为根据

- 删除 |赞[6]cuixiangmi
- 大数据挖掘还是比较有意思的,但分析应该要更科学。比如来源同样是News,大报和小报,应该乘不同因子。
- 删除 |赞[5]王大元
- 博主先生: 在你上一篇博文中我做的第一个评述,得到你的同意。 后来我发现那是你自己用大数据工具统计的资料, 由于我不懂大数据统计, 所以我又提出了几点疑问。我现在正在学习大数据的基本知识, 以便对大数据作为工具来调查舆情或者其它领域的应用前景。 现在还是作为外行向你求教几个问题?
1. 你能举几个例子来说明在那几个重大问题上, 大数据的统计结果被政府采纳了的, 或者做出了正确的预见的重大例子
2. 你能用大数据工具预言明天的那个股票会涨和跌吗?
3, 你能用你的大数据统计预测朝鲜1年后是什么样吗?
4. 你能用大数据统计预测中国明年的房地产涨还是跌, 涨幅或跌幅是多少?你的这个预测与其他不用大数据人做的预测有多大区别?
4. 你的转基因大数据的统计的结果能肯定现在的舆情结果将来肯定是对的或错的吗?
5. 如果我不用你的大数据统计,而是用科学杂志的数据来统计可以预测比你大数据的结果更准确的结果, 那么大数据的统计结果有什么意义 ?
我最基本的观点就是不管你的数据有多大, 但最关键的是你输入的数据是否正确和准确。 尽管你说了有删选数据的软件把关, 但我感到你的转基因那篇的大数据输入的数据的可靠性是有疑问的,你的软件似乎没有管好这个关, 例如与转基因无关的面筋竟然作为最主要的指标。 我建议你把转基因致癌那一部分, 单独拿出来用大数据统计一下, 其中输入持这种观点(致癌)的人的各种身份群体的比例:例如没有文化的老大娘, 小学, 中学程度的群体, 非专业人士群体的比例,科学家的比例, 统计一下, 看看中学学历以下和非科学家的群体比例的意见占多少, 我估计你可能会有完全不同的结论。 在这样的前提下输入你的数据, 看的人心里就踏实了: 哦!原来猪转基因致癌的是这么一部分人。

- 删除 |赞[4]huluhuluhulu
- 看了“浅谈立委大数据利用的局限性”,真欢乐啊。我还以为大数据能得到一顿西餐的卡路里呢。哈哈
- 删除 |赞[3]蔡小宁
- 感谢李老师将我的观点列入博文!在这里我做点解释。
我的博文是在刚刚看到李老师那篇大数据舆情调查博文出来的时候,当时的感觉是为什么结果与加州、华盛顿州的公民投票不符?于是推测了一种可能性,并不是说一定是那样的。后来,随着我们讨论的深入,对李老师的认识也在加深,现在可以确信,“阴谋论”的可能性可以排除,在此特别声明。另一点就是,我不怀疑李老师的数学能力,做软件的水平肯定很高。我想要说的是,一个好的工具需要人们正确地使用,一个好的工具仍然可以继续改进。软件实际使用得出的结果要尽可能与事实相符,如果出现不符合的情况就要考虑是否参数设计出现了错误或不够完善;或者有其适用范围,超过这个范围,结论可能就是相反的了。可以适当做点解释,以减少误会。
- 删除 |赞[2]mirrorliwei
- 【我一直都不理解美国曹氏中标识的gluten-free的食品为何就那么重要? 因为gluten就是我们中国人飞铲喜欢吃的面筋, 各位都喜欢吃油面筋塞肉, 北方人吃面要“筋”, 都是gluten含量很高的食品, 跟转基因毫无关系。】的说法镜某以为不妥。因为很多所谓专业人员都不知道“gluten”是什么!所以他们直接用了洋文表述此概念。这个说法的依据是来自饭桌上的谈话。镜某的饭桌上,以为是所谓的专业人士(本科教育名牌生化),一个是正在复习考试这门功课。“gluten”就是中国人喜欢吃的面筋不假。而面筋又是什么????就言语不详了
面筋就是面粉里面的蛋白质!!一种巨大的分子。转基因的风险就是可能会引起蛋白质的结构变化,带来新的过敏因子。
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么 (屏蔽留存)
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么
屏蔽 |||
既然大家感兴趣,圣诞没事在家,就继续做一点转基因的大数据挖掘。
这次挖掘仍然是最近一个月的英文社会媒体,区间为:
|
GM food, 11/25/2013 - 12/25/2013
|
Query 增加了一些同义词,GM Food 定义如下(漏掉重要的没有?):
-
GM food
-
genetically modified
-
transgenic
-
transgene
-
genetically engineered food
-
GMC
-
GMO
-
GMF
-
Franken-food
从下述共现主题词发现,GMC (for GM crop)有严重歧义,它更多用来作为 GM 汽车品牌:

因此加了以下限制词:
{ car, chevy, truck, covercraft, Sierra, model, Yukon, display aspect, buick, driver }
(也许下次试验干脆扔掉 GMC 这个害群之马? 想来也不会损失多少 coverage)
Anyway,在上述定义的 query 下,搜索挖掘的结果如下。
共现主题:

总览:
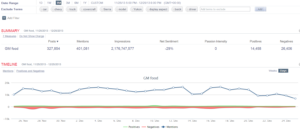
值得注意的是,与上次初步的调查的褒贬指数零下40度不同,这次更加 refined 的调查显示其褒贬指标为 零下29 度,转基因食品形象仍然很不佳,老百姓仍然很多疑虑和抱怨,但是不像 -40% 那样恐怖。这次调查做得更加细致,query defined 更周全, 个人认为应该更加真实可靠。
喜欢和厌恶转基因的理由云图如下:

社交媒体的地理分布:
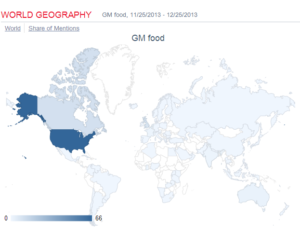
从数据分布看,确实是美国网民的帖子占压倒多数。这就回答了以前网友的疑问,究竟是美国人民(网民)还是西方英文世界网民的民意。(我从善如流,为保险起见把前一篇博客的题目从“美国人民”改为“西方”,现在看来,我有依据再把标题改回去了。无需地理过滤,最近一个月英文社会媒体谈论 GM food 的话题,几乎全部集中在美国。)
美国国内的分布呢?
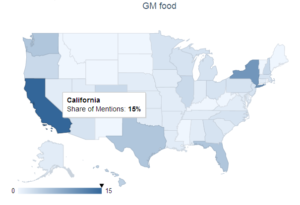
从颜色的深浅可以看出,这些议论主要集中在加洲(15%)和纽约州(9%),其次是德克萨斯(5%)和佛罗里达(5%)等。
其他信息图示:
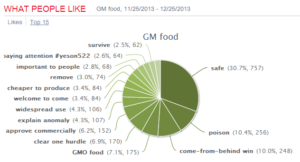
网友一定奇怪,为什么挺转人士把 poison (毒药)列为理由呢?我也很好奇,就 drill down 到数据里面看,原来是这样的样例:
我们英文分析器当然知道 poison 是强贬义词,但是议论中的 poison 有否定词 no,因此处理器就转贬为褒。但是,遗憾的是,还是错了,可以算是一个质量的 bug,我这就去修改系统。错误在于,这不是简单的否定式,而是祈使否定句(NO 也用了大写),意思是“坚决不要孟山都的转基因毒药”,显然应该归入反转人士的意见去,现在弄反了。自然语言蛮复杂,除了否定,否定之否定,还有祈使,以及它们的混杂,这就是一个活生生的例证。再举一例,请看下面的 minimal pair:
(1) GM food is safer
(2) Be safer,GM food
同样是 “be safer”,(1)是褒义描述,而(2)是祈使句,带有贬义(义为 “拜托,你能安全一点,成不?”)
对这些 tricky 复杂的自然语言现象,我们做了不少工作,但肯定有漏洞。不过也不要由此担心结果的可靠性。没有自然语言系统是完善的,社会媒体的表达又很不规范。好在我们有不间断的质量检测(QA)流程, benchmarks 利用第三方 crowd-source 人工监测,四个判官,至少三个判官一致才作为标准。统计下来,英文系统精确度一直保持在90%上下。这样的精确度比流行的关键词技术为基础的同类系统至少要高出30-40个百分点。由于大数据对于个体质量不完美有补偿作用(以前我有几篇科普专文谈论这个),因此有信心说,总体结论是靠谱的,反映了社会媒体真实面貌的。
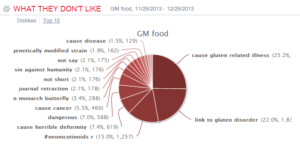
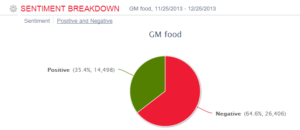
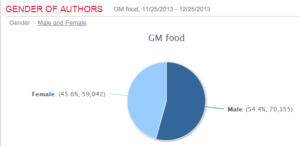
最后给一些社会媒体的samples
【相关篇什】
小数据和个案分析:个人在美国对转基因的感觉 2013-12-26
既然大家感兴趣,圣诞没事在家,就继续做一点转基因的大数据挖掘 2013-12-26
关于转基因及其社会媒体大数据挖掘的种种问题 2013-12-25
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24
27 陈安 李伟钢 徐磊 武夷山 曾泳春 孙根年 刘全慧 周洲 韦玉程 薛宇 李兵 周雄伟 曹俊 李冰 赵凤光 崔小云 文克玲 李宇斌 王荣林 赵一玮 lbjman frake tuner dachong99 ncepuztf bridgeneer yunmu
发表评论评论 (16 个评论)
- 删除 |赞[10]tuner
- 今年美国通过了转基因食品强制标识法案的州有3个:Vermont, Connecticut, 和Maine。都是东北部的州,看来孟山都等转基因公司想用金钱左右所有的民意,还是不可能的。
明年应该有更多的州会对转基因食品强制标识法案进行公投,看结果吧。博主也许可以再做一下同比,即前几年同一个月在这个话题上的民意,看变化情况,应该能进一步说明问题。
- 删除 |赞[4]dangping
- 民间的争议和学术界的争议是两码事。反转人士也可能比挺转人士更乐意发表意见,媒体也有可能更倾向于转载一些负面的报道和意见,所以这些分析结果能不能代表人民的意见还很难说。

- 删除 |赞[3]husselfist
- 有点意思。

- 删除 |赞[1]张能立
- 中美数学名师解题方法之比较 http://blog.sciencenet.cn/blog-39840-753017.html 敬请科学网师生批评指正。
|
|
只认数据不认人:IRT 的鼓噪左右美国民情了么?(屏蔽留存)
只认数据不认人:IRT 的鼓噪左右美国民情了么?
屏蔽 |||
套用北韩最近流行的歌颂红太阳金正恩的红歌,数据,数据,《除了它我们谁也不认!》
当然,还有上帝:In God We Trust. In everyone else we need data.
大数据时代更是如此,只认数据不认人。道理很简单,在信息爆炸的时代,任何个人的精力、能力和阅历都是有限的,所看到听到的都是冰山一角。小崔如此,其他大V也如此,大家都在盲人摸象。唯有大数据挖掘才有资格为纵览全貌提供导引。
当然,这不是说,大数据挖掘就是完美的解决方案。但是,正如一人一票的民主选举也不是人类社会完美的体制,而只是最少犯错误的机制一样,大数据挖掘比任何其他个人或利益集团的分析,较少受到主观偏见的干扰。这是由大数据本性决定的。
不过,挖掘本身也有可能有 bug(但即便是 bug 或者其他不完善之处,它们对所有搜索的话题也是一视同仁的,是独立于话题的,因为系统的编制针对的是开放话题),挖掘的结果可以从不同角度验证或质疑。值得注意的是,即便被认为是真实反映的同一组数据结果也完全可能有不同的解读(interpretations),人们就是在这种解读的争辩中逼近真相。一个好的大数据系统,必须创造条件,便于用户 drill down 去验证或否定一种解读,便于用户通过不同的条件限制及其比较来探究真相。
上篇转载博文([转载]ZT: 为啥立委的报告认为GMO造成gluten intolerance 2013-12-28)就是老友在质疑和解读这方面做出的有意义的努力。老友指出,其所以造成 gluton intolerance 成为反对转基因的主要理由,是由于美国反转极端组织 IRT 的鼓噪的效应。从时间上看,IRT 确实在上个月的大数据调查区间内制造了反转新闻,似乎影响颇大(drill down 显示 twitter 在很短时间里对 cause gluten related illness “新闻”有 700 多条大同小异的微博或转发,下面是“鼓噪”及其社媒传播样品)。
RT | @tree_details http://t.co/i8PV0y3Ev2 Future Epidemic? Monsanto GM foods cause gluten-related illnesses. econ/food/soci- gmo.
Monsanto GM foods cause gluten-related illnesses (silveristhenew.com) [...]
GM foods cause gluten-related illnesses --
I added a video to a @YouTube playlist http://t.co/rywMnDKtlU Future Epidemic? Monsanto GM foods cause gluten-related illnesses.
Future Epidemic? Monsanto GM foods cause gluten-related illnesses.
Future Epidemic Monsanto GM foods cause gluten related illnesses: Published on Dec 7, 2013 18 million of Ameri... http://t.co/86SnUlUmxv.
Monsanto GM foods cause gluten-related illnesses http://www.youtube.com/watch?v=VyV001qX2i4 7 December 2013 , RT.
Monsanto GM foods cause gluten-related illnesses http://www.youtube.com/watch?v=VyV001qX2i4 7 December 2013, RT.
Monsanto GM foods cause gluten-related illnesses • 'March of Millions': Ukraine braces for massive anti-govt rally • Spiritual Journey: Valaam monastery in Russia's far north (RT Documentary).
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/qceiGYiPWM. #RT
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/qceiGYiPWM. #RT
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/leNyyCI1G4. #RT
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/kZlxQso6T4. #RT
.........
RT @LuminatedSlave: Future Epidemic? Monsanto GM foods cause gluten-related illnesses https://t.co/purlWn3ztO.
RT @LuminatedSlave: Future Epidemic? Monsanto GM foods cause gluten-related illnesses https://t.co/purlWn3ztO.
Future Epidemic? Monsanto GM foods cause gluten-related illnesses https://t.co/purlWn3ztO.
RT @RT_com: Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/FbJhDufXzn. @portnayanyc
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/lknWlC2CP2
..........
Future Epidemic? Monsanto GM foods cause gluten-related illnesses: http://t.co/XOJYHwyci4 via. @youtube
Future Epidemic? Monsanto GM foods cause gluten-related illnesses: http://t.co/EUYyOsnFyV via. @youtube
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/mAPr2RkyLL. #FutureEpidemic #GM #GMO #RT
Future Epidemic? Monsanto GM foods cause gluten-related illnesses http://t.co/MwzyJkqjLI. #FutureEpidemic #GM #GMO #RT
.........
有了上述解读,我们有两个问题需要解答:(1)一小撮 IRT 分子的 “鼓噪” 可以左右舆情么?影响度如何?(2)反对转基因的理由除去 gluten intolerance 后是怎样分布的?
于是我们继续做转基因的大数据自动挖掘来寻求答案,以便看清西方当今舆情和民情的真相。根据老友们的建议,我们可以设置条件,做一个对照调查。下面就是这次对照调查的条件和结果。
(1) Baseline:为做到 apple to apple 式的 minimal pair 对照比较,我们先把最近一个月的自动调查重复一次(除去了原 query 中的害群之马歧义词 GMC,因为发现它绝大多数是与 GM 品牌汽车相关,而不是指转基因谷物),结果拷贝如下:
这是 baseline,没有加限制词的结果,似乎没有多大改变
作者: 立委 (*)
日期: 12/29/2013 02:08:05






(2)在上述自动挖掘中加入限制词 “cause gluten” 以屏蔽由于 IRT 鼓噪事件带来的反转中最大,据专家认证也最不靠谱的理由:
嗨,我加了一个限制词 ”cause gluten“,舆情面貌变了哎
日期: 12/29/2013 08:16:59
不过褒贬指数还是很低:零下 33 度(比零下 37 度稍微升温 5 度)。似乎说明网络舆情对转基因还是充满抱怨的情绪。





【相关博文】
[转载]ZT: 为啥立委的报告认为GMO造成gluten intolerance 2013-12-28
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么 2013-12-26
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24
http://blog.sciencenet.cn/blog-362400-754053.html
上一篇:与理发师的交谈
下一篇:"科学里说法的‘短命性’不是好事情吗?"
10 武夷山 孙根年 郑小康 陈儒军 陈筝 鲍得海 李宇斌 bridgeneer liyouxi tuner
发表评论评论 (15 个评论)

- 删除 |赞[10]李维
- 新年将至,打个戳:
已有 3507590 人来访过
积分: 670威望: --金币: 665活跃度: 44665好友: 548主题: 2博文: 3618相册: 6分享: 343
stamped
- 删除 |赞[9]lmnnml
- 再来指出你这个大数据统计的随意性。 你可以说“据专家认证gluten也最不靠谱的理由”从而把gluten删除, 从而提高了其它项目(例如致癌)的比例, 请问你从几个专家的意见得出了gluten不靠谱? 这不是跟你的标题“只认数据不认人”完全相反, 变成了“只认专家不认数据”了吗。 再反过来问你, 现在的大多数专家都认为已经批准了的转基因食品与常规的一样, 不致癌, 你为什么在致癌问题上,不加一个限制词 ”cause cancer“,你这不是按照自己的意愿和观点,随意操作大数据, 达到你自己的观点来误导舆论吗? 如果你有理的话, 请你不要删除我的观点, 正面回答
- 删除 |赞[6]liyouxi
- 博主能否利用大数据手段证明或者证伪下述的据报道?
====
非营利性组织“国际食品信息委员会”(IFIC)在进行2013年《美国食品安全调查:消费者对食品安全、营养、健康的态度》调查时,依据2012年美国官方人口普查,以调查人群的性别、年龄分布、学历分布、族群分布和地区等变量配属统计权重,对1,006 名年龄18—80岁的美国人进行问卷采访。问卷结果显示,对于“你担心食品安全的哪些方面”这一问题,29%的消费者担心病菌和污染问题,21%的人担心制作过程,13%的人担心添加剂和化学品,只有2%的美国消费者表示担心转基因食品。当调查者进一步提问“你会避免哪些食品”时,消费者更多关注的是食品中“糖”和“脂肪”的含量,只有0.5%的人表示会避免转基因食品。对于现有的食品标签,仅有3%的消费者希望标注转基因信息。而在对消费者购买行为的调查中,87%的消费者表示生物技术(包括基因工程)不影响他们的购物选择。
- 删除 |赞[4]liyouxi
- 大数据能反映民意,这一点是没有太大问题的,只要收集数据的手段客观可靠即可。但是一个科技政策这样的专业判断问题,民意不能代表正确,且现代科学观念从来都是从少数人的探索开始的,社会大众事先不可能先行进行判断认定,即使成为科学知识之后,要一般老百姓(包含其他专业人士)来进行判断是强人所难。因此,我想博主可以做这样一个研究:美国民众在对待未知事物表达担忧的同时,是否主观想替代专业人士进行判断?或者在制定政策的层面上,是否对自己的非专业意见有足够的信心?还是,虽然有担忧,但是信任国家有关部门专家及科学共同体做出的决断和政策?他们老百姓有直接冲到最前线,推翻zf(FDA,AAAS等)的现有政策的意愿么?等等等等。
【大数据挖掘:转基因英文网络的自动民调和分析】(屏幕留存)
【大数据挖掘:转基因英文网络的自动民调和分析】
屏蔽 |||
前不久做过几个转基因在英文社交媒体的自动民调,引起广泛兴趣。不过,那几次民调都是用的最近一个月的社媒数据。很多朋友希望做一个较长时期的调查,看看西方(主要是美国)社交媒体中转基因的媒体形象及其口碑民意的演变趋势。超过一个月的数据会产生额外的数据费用,因此甚至有热心网友提出愿意筹款资助这项调查。
既然转基因是大众如此关心的热点话题,我们就拿它当小白鼠,继续做系列大数据自动调查,用海量数据粉碎少数匿名极端分子散布的大数据调查涉嫌“输入伪数据”的谣言。博主保证在话题定义和输入给系统以后,相关的原始数据搜索及其自动分析全过程没有任何人工干预。这一点是由我们的大数据产品的性质决定的。产品允许以不同的 filters 来做对比研究,博主保证对比调查中的任何 filter 都明确标示,默认为不使用。各位谨记的是,大数据是客观的存在,大数据不会说谎,但是对数据的下列解读(interpretation)不可避免有主观的成分。欢迎百家争鸣,对这些数据做出不同的解读,也欢迎对数据挖掘的条件和过程提出建议和质疑。(但不欢迎任何极端分子的胡搅蛮缠无理取闹,博主保留对任何极端或不雅留言杀无赦不解释的权利。)
转基因一年来英文社会媒体口碑的自动民调和分析如下。
(1)话题的定义和输入:GM food | GMO | genetically modified | transgenic | transgene | genetically engineered food | GMF | Franken-food
与前同(删除了歧义严重的害群之马 GMC)。
(2)自动民调结果总览
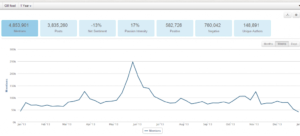
尝试解读:一年的自动调查提及转基因485万,调查了383 万多社交媒体的帖子,涉及近 15 万网民。这是真正的大数据民调,比传统手工民调最多几千份问卷,数据量和调查对象要高两到三个量级。转基因的一年大数据的平均褒贬指数为零下13度,比前几次的一个月数据的调查要好(虽然仍然是负面评价为主)。转基因的话题在西方社会媒体中,的确很有争议。
尝试解读:一年的提及转基因话题的帖子,有 28% 的帖子(134万)含有褒贬评价或情绪,其中贬(57%)略大于褒(43%)。褒贬的幅度区间在 6 度最高点(见上图最高红点旁 tooltip 小框)到 零下 32 度(上图最低谷的红点处)之间。值得注意的是 2013 年六月是转基因网络热议的最高峰,而这场热议却使得转基因褒贬指数跌入最低点零下32度。
下面是最近半年的数据,褒贬度为零下10度,略好于一年的指标。
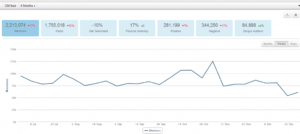
(3)共现话题:

尝试解读:多次挖掘都是如此,与转基因最密切的主题永远是 Monsanto (孟山都)。说转基因纯粹是科学问题,那是 too simple and naiive,只要背后有企业,就一定有利益因素。
(4)挺转反转的理由词云:

尝试解读:正反理由旗鼓相当的样子,这比以前一个月数据的调查大为改善。反转的最大理由不再是 gluten 相关的疾病,而是死亡(Die)和癌症(Cause cancer)。挺转声音强调的是安全(safe),也是很自然的。
(5) 挺转反转的情绪词云:

尝试解读:wow,情绪云图中挺转的分贝(那些大大字体的 love,good,great)似乎比反转的(bad,not want,concerned,fear,hate,fuck)更高(表现为更大的字体),不过后者的表达更加多样化。
(6)挺转反转的行为:

尝试解读:挺反双方不仅仅是情绪发泄,还有行动,有吃的用的买的(eat,use,buy),就有拒吃拒买甚至要求禁止的(not eat,not buy,reject,ban)。
(7) 挺转反转的比例

(8)社媒样例:还是贬大于褒嘛。

【转基因大数据挖掘系列博文】
【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】 2014-01-03
【大数据挖掘:转基因网络口碑的自动民调和分析】 2014-01-03
只认数据不认人:IRT 的鼓噪左右美国民情了么? 2013-12-30
[转载]ZT: 为啥立委的报告认为GMO造成gluten intolerance 2013-12-28
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么 2013-12-26
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24
 大数据崇拜要不得
大数据崇拜要不得【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】(屏蔽留存)
【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】
屏蔽 |||
中文,中文社交媒体里的转基因。与英文民调迥然不同哎,挺转声音似乎很大,主要来源呢?
终于,我们来到据说为转与非转掐架掐到天昏地黑问候父母的中文世界。为了避免陷入泥潭,咱们这次只提供数据,不提供解读。爱挺爱反,请便,爱咋解读,听便。
这次自动民调是最近一个月的中文社交媒体数据,具体来源和比例后面交待。
接着来中文社媒的民调:挺转派明显占上风,疑似媒体正面为主?
作者: 立委 (*)
日期: 01/02/2014 19:26:23











【转基因大数据挖掘系列博文】
【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】 2014-01-03
【大数据挖掘:转基因网络口碑的自动民调和分析】 2014-01-03
只认数据不认人:IRT 的鼓噪左右美国民情了么? 2013-12-30
[转载]ZT: 为啥立委的报告认为GMO造成gluten intolerance 2013-12-28
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么 2013-12-26
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24
【大数据挖掘:中国红十字会的社会媒体形象】(屏蔽留存)
【大数据挖掘:中国红十字会的社会媒体形象】
屏蔽 |||

在当今的信息社会,一个机构的社会形象很大程度上决定于其网络形象。维持和增强网络形象需要对社会媒体的挖掘追踪,以便及时应对危机,调整其公关举措。我们以去年几度陷入公关麻烦的“中国红十字会”为例来展示社会媒体大数据挖掘的这种监测和警示作用。了解自我是改进自我提升形象的前提。面对混沌的大数据,人们往往见木不见林,难以把握总体趋势和全貌。而自然语言技术可以帮助我们自动阅读分析海量信息,从中挖掘任何话题的舆情以及机构或个人的媒体形象,从而从一个角度为决策提供依据。
一般而言,红十字会总是与各种慈善活动紧密相关,因此如果不出意外,红十字会的社会形象是非常正面的。但是,中国红十字会却不尽如此。用我们中文大数据挖掘系统(beta)对最近一年的社会媒体(完整的微博数据仍然在与内容商协商之中)的自动民调显示其形象起伏颇大,但一年平均指数 36 并不很低。
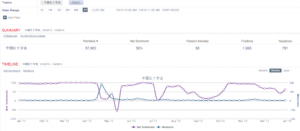
从上图看过去一年(2013元月13至2014元月14)的社会媒体趋势,社会媒体的相关议论的数量除了去年四月五月之间突然出现一个高峰以外(出了什么状况?),一直很平稳。随着这个热议的是其形象一跌千丈,直至五月12号到谷底零下56度。随后的发展表明,虽然议论量趋于平稳,但去年七月中与九月末还是出现两次形象受损,疑似公关失当?这里面的故事,一直追踪网络事件的记者和网友应该有所可言。
,
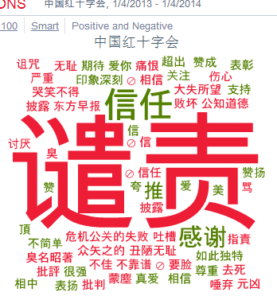
网友表达的情绪中最显眼的是“谴责”,远远超出正面的情绪(“信任”)。

上图展示了具体的褒贬理由。下面是其比例的饼图,如何解读这些数据还是留给了解事件发展过程的人士吧。总之是遇到了丑闻和麻烦。
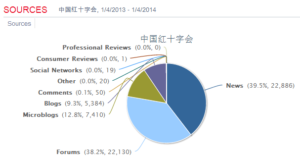
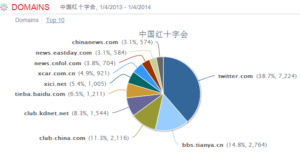
5 蔡小宁 郑小康 王秀玉 徐晓 bridgeneer
发表评论评论 (1 个评论)

- 删除 |赞[1]王秀玉
- 读李维老师《大数据挖掘:中国红十字会的社会媒体形象(2013)》后感 地址:http://blog.sciencenet.cn/blog-817414-755900.html