
立委:从语言与语言学角度,chatGPT 的的确确证明了自己万能的语言能力。千百年来的人类巴别塔之望终于美梦成真。巴别塔建成了,建成日期2022年11月。这个成就超出了一般意义的里程碑。这是划时代的进步。
南山:我看不懂它是鹦鹉学舌还是真的掌握了语言。我比较认同一个说法:语言是思想的表象。计算机掌握语言与计算器做计算,也许没有本质区别。
毛德操:对。和蒸汽机胜过人的臂力也没有本质区别。
詹卫东:一个机器是否具备人类的语言能力,本身就是一个比较难判断的问题吧?按照语言学区分competence和performance的考虑,机器和人,在测试语言能力方面的范式是一样的,总是用performance去估计competence。所以,真正的“语言能力”,大概也只能是一种“感觉”吧。chatgpt现在的表现,应该是让很多人“觉得”它掌握了语言。人们似乎还没有想出比图灵测试更高明的方法,来判断机器是否具有语言能力。
邬霄云:图灵测试 is not for language only, it is end to end “common sense “ test, human intelligence via language.
詹卫东:是的。它包含了语言能力。
南山:所以纠结机器是否智能在可预见未来是无解的,相关的判别标准和概念大家都没有清晰、一致,对于chatgpt、alphzero这类,看疗效才是王道。
邬霄云:单独测 language 是不是 翻译 或者别的 normalization 就可以? @詹卫东
詹卫东:不知道。我想不清楚语言跟其他能力是怎么分开的。简单的区分,比如语言考试,语文考试这类的。具体的题目,像是近义词辨析。我测了100题。chatgpt的表现跟LSTM的水平差不多。但是这类考试,并不是真实的语言应用场景。实际上是教师凭空想象的。题目形式是选择题,就是把一个句子中的一个词拿掉,给两个近义词,让它选一个填回去。100题得分不到60分。
南山:有唯一正确答案的题目吗?判断正确的标准只针对句法还是要结合语义和常识?
詹卫东:从出题的角度考虑,是有唯一正确答案的,但语言题还是跟数学题不同,总会有“更多的视角”和“更开放的标准”隐藏着,导致答案很难唯一。 近义词组是考虑了很多因素挑选的,包括句法、搭配、语义协同、常识等。
立委:语言理解能力可以看 同样的意思 你变着花样不同问法,然后看他的回应。体验下来 结论是 它是真理解了 不比人差。
詹卫东:差不多是这个体验。我测试它对不及物动词的反应。故意不在“引语句”打引号。但它准确地识别出引语句片段。不过,线性符号串接续层面形成的“结构”意识,似乎还是不能跟树结构完全重合。这就让人担心它的理解能力。我的感觉是人的智能有一个突出的特征,就是“整体性”。如果没有“整体性”,就是工具智能,不是“通用智能”。
Li Chen:整体性其实是神经网络的强项,毕竟最后都变成向量了。难的反倒是细节。
詹卫东:我说的整体性比较含糊,大概是这个意思:一个智能实体,不应该能做奥赛的数学题,但却在算24点的时候犯“低级”的错误。就是chatgpt在给人感觉很厉害的同时,又表现出存在犯低级错误的能力。
Li Chen:我觉得这个现象可以理解。因为像24点这种东西,某种意义上讲就是一个特殊的游戏,需要说明规则,理解规则的基础上来玩。chatgpt真的理解这个规则了么?这个感觉也就是toB难的地方,不同行业的规则不一样,通用模型没见过这么多具体的规则。即便是人,有很强的学习能力,换个行业也得学习工作一段时间才能玩得转。
南山:对于一个有阅读能力的人,将一段话打乱之后,ta仍然可以把整体意思掌握了。chatgpt可以吗?一个有阅读能力的人不需要特殊训练就可以读懂这段话

立委:可以测试一下。应该没问题,因为汉字本身就是形义结合的词素。
詹卫东:这个可能是chatgpt的强项,我之前测试不及物动词“见面”的句子中就包含了这类乱序的句子。它理解得非常准确。
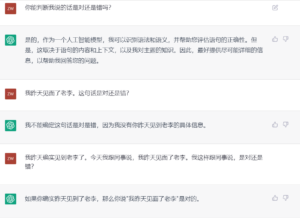


立委:这个实验好。语言理解从效果上看就是要鲁棒有包容,同一个语义可以有多种不同的表达形式,表达形式不规范也没关系,只要上下文的关键词及其相谐性可以让语句的意义有区别性就好。chatGPT 这方面游刃有余,总是可以把同义的不同说法映射到语义空间的同一个区域。

詹卫东:100分!
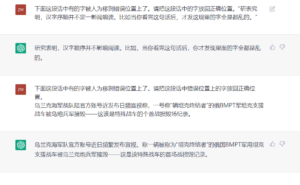
原文是今天新浪网一段新闻。
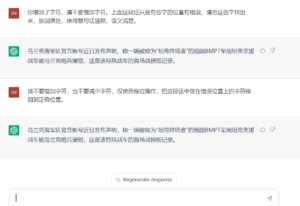
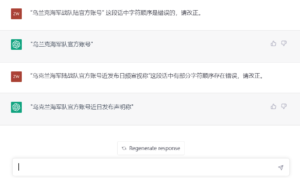
南山:你不用提醒它顺序被人为打乱了,它怎么理解
詹卫东:
南山:这么说可以认为它的语义理解能力是没有问题了。
詹卫东:是的,感觉可以“跳过语法”,直达语义。
白硕:乌兰克
南山:可以理解为它的常识或常识运用有问题吗?
詹卫东:其实很难评判应该是“乌兰克”还是“乌克兰”。chatgpt不改也不能认为是错。
Li Chen:是的,也许真有个国家地区或者可以当主语,修饰语的确实叫乌兰克。
詹卫东:从我受到的语言学训练角度讲,chatgpt的汉语语言学知识(人类假设的那些知识,可能对,也可能不对)还是比较贫乏的,按照这个标准,它应该还不算掌握了语言。一个典型的表现是,语言学比较重视打*号的句子的分析,也就是所谓“不合语法”的句子。但实际语料中这样的句子极少。应该是训练数据缺乏。chatgpt对这样的句子的判断能力就不太灵。不过,这似乎也不太影响它进行语言信息的分析和处理。从这个角度讲,chatgpt对语言学的刺激是:句子结构的分析,包括对正例和负例的结构分析和解释,到底意义是什么?
立委:关于文法书上强调的带有星号 * 的反例,那不是为了语言理解,主要是从语言生成的角度,实践中追求的是合法和地道(nativeness),理论上追求的是 internal grammar/language,需要防止反例出现。
从语言生成角度,LLM 的大数据回归的属性天然实现了 nativeness,反例不仅少见,即便出现,统计上也沉底了。语言生成能力的效果观察,可以让它生成几次,看回应是不是还在同类水平上,是不是走题或掉链子。这一关表现不错。除了特别的风格输出(例如洋泾浜:这种“风格”可以看成 sub-language,里面的正例恰好是规范英语的反例)外,它是不会出现低级文法错误和违背习惯用法的笑话的。所以 native speakers 听着也觉得舒服。
说到底还是图灵,如果不告诉你背后是谁,你是不是会觉得对象是人。
从语言理解角度,文法书上的绝大部分反例都在包容的范围之内。语文老师让学生改正反例的那些练习题,其出题的前提就是这些所谓反例其实同样承载了正句一样的语义。没有这个预设,人怎么知道如何改正才能保留原有的意义呢。反例不过就是形式上的违规而已,通常不影响内容。
当然,在 input 较短 context 不足以确定内容完整性的的时候,有些反例会呈现歧义或甚至与原意相左的语义,这时候形式的违规的确与内容的混乱或不确定发生关联了。这时候,句法手段的修正(例如次序的调整、功能词的使用以及西方语言中的形态的正确应用等)才会有实质性意义,而不仅仅就是为了 native speaker 听上去顺耳而已。
解析和理解的能力,LLM 特别宽容鲁棒,主要是它的 embedding(编码嵌入,成为其内部的向量表示)可以容纳很长的 input,在 context 相互邻近的关键词之间相互制约下(我们叫篇章中的 semantic coherence,包括词义之间的搭配关系),形式上的偏离规范已经不影响它在语义空间的意义定位,从而“它”可以轻易与“非它”区分开来。
一个符号串 吃进去就是向量空间的某个或某组位置 其意义表现在与其他位置的距离和区别。因此 位置偏差一点 不影响意义 只要它与其他的不同意义的符号串映射可以区别开来。鲁棒性根植于此。换个角度 意义不是要问是什么,更要紧的是 不是其他(什么),只要能维持这种意义空间的区别性,规范不规范就都可以包容。区别之间有足够的空间/距离,即可容忍局部的种种口误 错误。
邬霄云:Llm 的 position encoding is linearly attached not cross product,so it is a weak form
立委:词序影响意义的机会不大。当年 一包词模型用了很久 也是因为 词序是较弱的约束,构成区别要素的场景并不频繁。
我把一句话,完全反过来,从:explain quantum computing in simple terms 映射成类似回文:terms simple in computing quantum explain,它毫不迟疑。


人家训练的是next token,现在是处处反着来,本想让它找不着北,但实际上一点也不影响它的“理解”。就是说,当一个模型可以对较长的 input string 做编码嵌入的时候,次序的约束已经很弱了。因为那一小袋词之间的物理距离(proximity constraints)加上它们语义的相谐性(semantic cosntraints)已经足够让这个整体的语义表示与其他对象区分开来,这时候纯粹语言学意义的句法约束(syntactic constraints,包括严格的词序)就可以松绑。
我怀疑 position encoding 即便不做,LLM 也不见得性能会下降很多。
邬霄云:Could be, popular code base all use it still
立委:换句话说,在 bigram / trigram 建模的年代,词序是重要的 (“我爱她”与“她爱我”,“打死”与“死打”,可不是一回事)。到了ngram 中 n 可以很长的时候,ngram list 与 ngram set 已经语义相等了。
句长不够,词序来凑。长度足够,序不序无所谓。句法地位急剧下降。
论鲁棒,人如何与模型比,差了不止一个段位。
Li Chen:想想确实是这个道理,在有很多词的情况下,还要能组成符合语法的句子的可能性是有限的,也就意味着语义差异不大了。所以这个时候顺序确实已经不重要了,估计这个也是为什么即便是最简单的bag of words也能用来做相似度计算,一用就是几十年的道理。
詹卫东:跟ChatGPT逗个乐。

总的感觉就是chatgpt对语言的嵌套理解能力和指代关系理解力非常强。
川:LLM 没问题,ChatGPT is evil
Who is the master, machine or man?
立委:那是因为 chatGPT 太 human like,搞定了自然语言形式。
川:搞定是假象,现在就下结论太早。
立委:机器都是假象,AI 本性。Artifical 与假象可以看成是同义词。就本质而言,人工智能就是智能假象,这个论断没有问题,但这应该并不妨碍人类深度使用AI。
搞定的判断是,跟他说话感觉它听从指令、善解人意,而且回应也很顺溜贴心,不走题。
三个月玩 chat 下来,我在它生成的英语中,没有发现过语言的问题(内容的毛病不算),一例也没有。但在其中文的生成中,偶然还是会发现它有语言的瑕疵(不符合规范或习惯的用法),虽然它的中文生成能力已经超过多数同胞。这说明,目前 chat 语言训练的中文语料还可以进一步扩大,从爱挑剔、追求完美的语言学家视角,它还有一点点剩余的进步空间。
结论还是: ChatGDP 搞定了人类语言,无论听还是说,妥妥的。万能的语言巴别塔是真滴建成了。
说到chat里程碑的意义,盖茨比作电脑、互联网后的第三大里程碑,显然有点夸张了。可是我们进入计算机博物馆看里程碑展馆,有 1. 第一次下国际象棋打败人类 2. IBM 沃森问答打败人类,后面的还该有一系列打败人类的里程碑吧,例如围棋。

不得不佩服它条理化的能力,只有一个不妥:医学并入了教育。其余的综合 总结能力强过一干人,自然包括在下。在这一长串中,AI明星 chat 可以成为 top 几?
top 10 有点高抬了,top 20 似乎有余:就凭他建成了巴别塔,搞定了人类语言。



文字 应该是 语言/文字。宗教不该漏。
我是从语言角度。它的的确确证明了自己的万能的语言能力。语言能力其所以特别重要,不仅仅因为我是语言学家,难免强调它,更因为这是规模化机器能力的敲门砖,否则机器只是少数人的玩具。机器学会人话的意义,比人去适应机器,用程序去给它指令,意义大得多,这是人机接口的革命。