
大模型(LLM)很多人有共识,LLM主要是数据中心的AI(Data-centric AI)的产物。
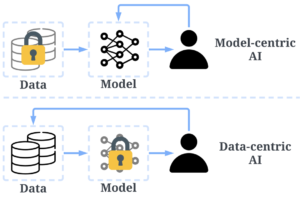
采自:GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?
上图对照了模型为中心到数据为中心的转变:模型为中心的研发框架和流程中,数据不变,模型变;而数据为中心的框架里,数据变,模型不变。
在前LLM时代,AI 都是专项的智能任务,针对这一任务通常有研究社区定义并准备了固定的标注数据集(可用来作为训练集和测试集)及其测试程序(scorer),各 AI 团队通常是利用同样的数据集在不同到算法上去测试。现在不同了,模型和算法比较成熟和恒定,主要是数据的不同来驱动模型的迭代发展。具体来说,根据 GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?一文,数据中心的 AI 具体内容包括:
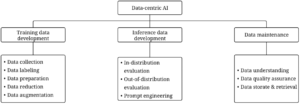
采自:GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?
今天咱们聚焦讨论一下数据测试及其与数据工作的关系。
系统性全面测试 LLM 的数据质量( QA,quality assurance)成为一个非常重要的主题和挑战。这不仅仅是要为多个功能类似的 LLMs 比较排序,帮助营销或推荐,更重要的是,在 data-centric AI 的研发趋势中,提供及时靠谱的QA反馈,并根据QA的指引,加强数据工作,弥补短板,帮助模型迭代提升。
挑战性在于:
1. LLM 本性是多功能和开放功能,如何建立合理、具有代表性(反映多数应用场景的需求)、可配置的一系列功能盲测集
2. LLM 生成具有随机性,如何让功能盲测标准化、流程化和(半)自动化,以提升QA效率,以便在给定的时间和资源条件下及时得到QA结果
3. 如何建立 QA 结果与数据工作之间的对应关系,揭示出 数据-模型 的质量某种因果关系,从而指导数据工作。
4. 如何最大限度收集、吸收和利用网络上爆发式群众测试的案例,取其精华,为我所用。
群众测试虽然很多是盲人摸象(研究者除外,例如 @詹卫东 教授的测试就非常有深度和章法),但草根积极性和创造性导致了下列可能的好处:
(1)有助于测试模型的鲁棒性:各种自发的无花八门的挑错,比任何专门的测试员都更具有想象力,可以为试探模型的边界和极致情形提供线索和思路。
(2)草根测试反映民意:这对任何品牌的 LLM 都会造成正面的或负面的舆情影响力,从而一定程度上决定了一个模型的用户接受度。专家评测并不能有效改变用户从舆情而来的印象。其实,将来被市场“自然”淘汰或用户抛弃(无人问津)的模型,更大可能受到草根测试的影响。
(3)不用白不用:来自草根的积极性和创造性会产生很多散落的但精彩的高质量数据本质上都是开源的,包括LLM下万众创业尝试阶段的数据副产品,尤其是提示词工程的种种数据表现。这比闭门造车式的数据创造更具活力和源头。常规性的调查、收集和善用这些资源,是增强数据工作的重要一环。
5. 数据工作中的研发和突破:针对LLM的短板,例如 “一正胡八”,与模型算法的研究平行,数据工作方面也需要有定力去深入钻研,协助寻找破解之道。 例如,知识库如何转化为有益的数据,可行性如何?回顾一下,GitHub 的代码在作为训练数据之前,人们并不把它看成是能与自然语言数据等量齐观的对象,但其实它是更高品质的序列数据,并对这场认知AI革命起到了重要的作用。
总之,LLM牵涉到的数据量太大,训练过程涉及各种工程优化的因素,环节长,moving parts 较多,这为全面及时的QA 提出了进一步的挑战。千头万绪,需要有那个 sense 抓大放小,收放自如。重中之重是要确保模型研发迭代的健康,防止模型质量下滑而不自知引发的时间和资源浪费。
在信息过载的时代,不被数据淹没并能善用数据,这需要宏观视野,也需要不怕 dirty work 的精神。不过,数据也与矿藏类似,富矿和浅层的矿藏都先被开采光了,越到后来挖矿要保证品质就越难,这是肯定的。例如 web 数据很杂乱 肮脏,Open AI 经过各种清洗和去重,实际上最后只用了 web 数据的一个零头:Common Craw 的 45TB 的纯文本进行质量过滤后仅选择了 1.27% 的数据。
类似于Web 网页数据中更加动态活跃的社会媒体也是数据非常 dirty 和混乱的所在,GPT 很看重 Reddit 数据(推特数据也应该是重要来源,但报道说马斯克在 ChatGPT 一炮打响以后感觉不爽,切断了 Open AI 的推特数据特权)。怎么筛选社媒数据?他们的做法是利用用户点赞作为过滤指标,点赞三次(3个karma)以上的才算是品质帖子。也还是巧妙带入人工反馈。
放眼未来,真正的品质数据的出路不是靠野蛮增长、垃圾如山的 web 数据,也不能指靠人类精雕细刻缓慢增长的电子书、编辑过的各种出版发行物,这些品质数据只是一个小的源头,它们没有信息时代的增长性。更有可能的是要靠大模型自己的“反哺”。为了保证自己跟自己的生成品去学,会使模型不断增强,肯定不是简单的把自己输出直接用来做训练的输入。
quote:如今当模型足够强大后,模型成为了一种「数据」或者说是数据的「容器」。在需要的时候,我们可以设计适当的提示语,利用大语言模型合成我们想要的数据。这些合成的数据反过来又可以用来训练模型。这种方法的可行性在 GPT-4 上已经得到了一定程度的验证。
摘自:GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?
这里提到的是提示词技巧来激发具有目标性的高品质数据。应该还有个过滤机制或快速人工审核制度,来保证品质。
《AI浪潮博客目录》
GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?