What did Ilya see?
-- looking closely into his historical Berkeley talk
by Wei Li, Jia Gao

Introduction
When Ilya Sutskever left OpenAI and re-emerged with his new company, SSI (Safe Superintelligence Inc.), the move was both surprising and expected—he bypassed AGI and directly aimed at SSI (Safe Superintelligence). He confidently declared: Superintelligence is imminent, and establishing safe superintelligence (SSI) is the most important technological issue of our time.
Ilya, a legend in the field of deep learning and AI, and the former true soul of OpenAI, was at the center of the dramatic internal shift, addressing the issue—effective acceleration versus super alignment. Why was Ilya so steadfast about "super alignment" amid the underlying AI values and strategic path debate? Even after the storm settled, the outside world continued to speculate: what did Ilya see that compelled him to join the board in making the decision to oust CEO Sam Altman? Ilya remained hidden until recently, when he left OpenAI, leading to the dissolution of his super alignment team and the creation of his new company.
What did he see behind the push for "safe intelligence"?
Back on October 3, 2023, Ilya gave a talk at UC Berkeley titled "A Theory of Unsupervised Learning." Though obscure and known to few, it is destined to be one of the most significant moments in AI history. This talk was a theoretical reflection and summary by a top expert in deep learning on the GPT model he pioneered, now famous worldwide. Ilya revealed the core principles of large models and vividly described his obsession with, and excitement over, independently understanding the mechanisms of unsupervised learning. Despite the complexity, the talk was brilliant and enlightening.
Until recently, Leopold Aschenbrenner, a former member of his super alignment team, published a 165-page article, "Situation Awareness," preliminarily revealing the shock and concerns within OpenAI over the exponential evolution of GPT models. This partly answered the question of what Ilya saw, but Ilya himself remained silent until his official re-emergence not long ago.
Reflecting on his "confessional" talk at Berkeley, we might glimpse his "moment of enlightenment" when facing potential superintelligence and understand his original intent for safe intelligence. It was a rare deep sharing by Ilya, attempting to convey essential message to the world. But did the world hear him?
1. Machine Learning: Supervised Learning and Unsupervised Learning
To accommodate readers with varying mathematical backgrounds, this blog aims to explain Ilya's historical presentation in an accessible language. Purely technical explanations can be skipped by non-technical readers without affecting the understanding of the presentation's main ideas.
Before diving in, let's review the basic concepts of machine learning. Machine learning is like having computers as students and humans as teachers. By providing computers with numerous "practice problems" and "answer keys," they slowly learn to solve problems. This is supervised learning. But can computers really learn from practice problems instead of merely memorizing them? Ilya assures us there's theoretical proof of this.
Imagine a sea of problems before you, each paired with a standard answer. This is the model's training data. Model training is like diligently solving these problems until most of them are correct, meaning low training error. But even an extensive problem set has its limits. When new problems arise, can the model still get them right? These new problems are the test data, akin to exams. Whether the model performs well depends on its test error rate.
Mathematics tells us that as long as the problem set is large enough, far exceeding the model's size, excellent performance on training problems (low training error) ensures good performance on test problems (low testing error). In other words, if the model trains well, it will do well in exams! This is the mathematical guarantee for supervised learning.
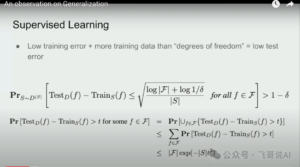
However, if the model merely memorizes without extraction, no matter how large its memory or how strong its "memory power," it lacks real adaptive learning ability (called "generalization ability"). Only when the model isn't too smart, it will be forced to extract the essence (called "compression"), learning real skills from the problem set.
This explains why the model size shouldn't be too large, to avoid giving the model too much room to cut corners. In short, Ilya wants to say that "big labeled data + low training error" is the winning formula for supervised learning, guaranteed by mathematics. This point has been confirmed both theoretically and practically. Since the deep learning revolution 12 years ago, countless successful cases have shown that as long as the training data is sufficient, neural networks can excel, at all sorts of AI tasks, from recognizing cats and dogs to machine translation.
But what about unsupervised learning? Can computers learn intelligence from a problem set without standard answers? It sounds far-fetched, but Ilya is about to explain how he managed to seek a solid mathematical foundation for unsupervised learning as well.

2. Distribution Matching: A New Approach to Unsupervised Learning
Everyone knows that machine translation was a typical win of supervised learning, in fact, the only win among various NLP tasks (such as dialogue, information extraction, sentiment analysis, question answering, docuent understanding, etc.) prior to the large language model's era. Why? Because we have a vast amount of historical bilingual data. It's like students having workbooks with English on the left and Chinese on the right—supervised learning thrives on this setup.
But what if the teacher suddenly stops providing aligned bilingual data and only gives you English books and unrelated Chinese books, leaving you to figure out how to align and learn automatic translation? That's the problem unsupervised learning needs to solve. Ilya says unsupervised learning can also handle various language machine translations (which we've seen today with large models—specialized translation software is no longer needed), and even any input-to-output transformation tasks. What's the catch?

Ilya discovered a new approach called distribution matching. Essentially, if the English and Chinese book collections are large enough, containing various sentence structures, their linguistic regularities will be learned "without supervision". For example, the context distribution of "I/me/my" in English should correspond to "我" in Chinese; adjectives near nouns in English with semantic compatibility should have a similar pattern in Chinese, etc. This provides the basic condition for potential language alignment.
Ilya points out that if two languages' native data is sufficiently rich, the input in one language can almost uniquely determine the equivalent translation in the other language. This principle applies not only to machine translation but also to tasks like speech recognition and image recognition.
Ilya independently discovered this approach in 2015, fascinated by the underlying mathematical principle—compression theory. If we can find a method that maximally compresses both English and Chinese data, this approach will capture the common patterns of the two languages, which form the basis of translation.
So, Ilya proposes that unsupervised learning is essentially about finding the optimal data compression method. This perspective not only sounds cool but also provides a mathematical explanation for the effectiveness of unsupervised learning. Although real-world tasks are not idealized, this principle gives unsupervised learning a solid theoretical foundation, making it as convincing as supervised learning.
Next, Ilya will delve deeper into the mathematical principles behind it. Although somewhat abstract, he promises it’s full of insights. We'll see how he uses the magic of compression to explain the mysteries of unsupervised learning.
3. Ilya’s Ultimate Theory: From Conditional Modeling to Joint Modeling
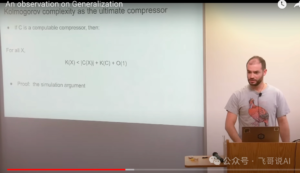
This is the final and most intriguing slide of Ilya's talk, worthy of thorough analysis and contemplation. The goal of unsupervised learning is often defined as "learning the internal structure of data." Ilya suggests understanding unsupervised learning from the perspective of data compression: a good unsupervised learning algorithm should maximally compress the data, representing its content in the simplest form. This introduces the concept of Kolmogorov complexity.
The Kolmogorov complexity of a data object is the length of the shortest computer program that can fully describe this object. You can imagine this shortest program as a "compressed package" containing all the information needed to reconstruct the original data. From this perspective, the goal of unsupervised learning is to find the optimal compressed representation of the data, which is the Kolmogorov complexity.
The Kolmogorov complexity of a data object is the length of the shortest computer program that can fully describe this object. Imagine this shortest program as a "compressed package" containing all the information needed to reconstruct the original data. From this perspective, the goal of unsupervised learning is to find the optimal compressed representation of the data, which is the Kolmogorov complexity.
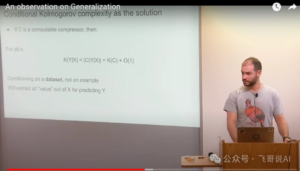
However, in practice, we often need to handle multiple related datasets. For instance, in machine translation, we have the source language dataset X and the target language dataset Y. We want to learn a model that can translate sentences from X to Y (or vice versa). Traditionally, this is viewed as a conditional probability problem: given X, what is the probability distribution of Y? Represented in terms of Kolmogorov complexity, this involves finding K(Y|X), the shortest description length of Y given X.
Ilya proposes a different approach. Instead of viewing X and Y as condition and result, like in supervised learning, he suggests viewing them as a whole and compressing them together within a massive model. Essentially, we seek the joint Kolmogorov complexity K(X,Y), the shortest program length that compresses both X and Y simultaneously. This approach must fully utilize the correlation between X and Y, using information in X to automatically align Y (or vice versa), much like how we use our native language knowledge to understand and remember foreign language expressions.
Ilya believes this joint compression idea is the true power of unsupervised learning. Real-world data is often interconnected, with numerous deep common patterns and regularities. If unsupervised learning can discover and utilize these regularities, it can significantly enhance learning efficiency and generalization ability. This explains the remarkable performance of large language models like GPT across various tasks: through massive unsupervised pretraining, they learn the deep regularities of the training data, and these regularities are transferable across related datasets.
Although Kolmogorov complexity is theoretically uncomputable, Ilya believes we can approximate this process using deep neural networks (like GPT). Through optimization algorithms such as gradient descent, neural networks can find the optimal compressed representation in massive data, capturing the essence of the data and its alignment patterns, even if not strictly in terms of Kolmogorov complexity.
Thus, Ilya’s theory can be seen as a new paradigm for unsupervised learning, elevating traditional independent modeling (like separate models for English and Chinese) to a unified associative modeling approach. In this paradigm, the goal of unsupervised learning is no longer just compressing individual datasets but finding the connections between them. This cross-modality learning represents an advanced form of artificial general intelligence (AGI).
Now, let’s closely examine this final slide. In it, X represents dataset 1 and Y represents dataset 2. The key point is extracting every bit of information from X (or Y) to help predict Y (or X). This is what Ilya refers to when he says training X and Y together yields the effect that unsupervised learning of X helps accomplish the task of transforming X to Y.
The crucial idea is: K(Y|X) becomes K(X, Y).
Ilya transforms the universally applicable functional AI task of "input X conditions output Y" into an approximate solving problem by jointly training X and Y without modal segmentation. This joint training approach is effectively the current multimodal unified training, abbreviated as K(X, Y).
Ilya aims to strengthen the theoretical basis, emphasizing his surprising discovery that self-learning of X has a strong predictive effect on Y.
The essence of unsupervised self-learning is that the self-learning of X is to compress X, and the self-learning of Y is to compress Y. This is straightforward because the essence of self-learning is involves only positive examples, without negative samples. Unsupervised self-learning lacks a specific task orientation; it learns language from language, images from images, music from music, and so on, continually abstracting various patterns from phenomena.
Ilya points out in the slide: conditioning on a dataset, not an example. The compression object is the dataset, not individual data points, which is crucial. This distinction separates superficial compression from content compression. Superficial compression is merely a mechanical process that does not produce intelligence. Only content compression can achieve artificial intelligence.
How do we understand the difference and connection between superficial lossless compression (e.g., digital music) and content lossless compression (e.g., Suno)? Compressing a specific song losslessly aims to ensure it can be restored to its original musical form (including noise and imperfections). This is traditional music compression, targeting individual sample, e.g., a specific song. Compressing a collection of music, whether using GPT or Diffusion, targets a group of samples, resulting in a large model like Suno.
When individual objects turn into group objects, formal compression naturally transforms into content compression. This is because, although the group comprises individuals, compressing the group is like "painting" a portrait of the group, outlining its characteristics. It may resemble an individual, but it is not a specific individual in the original data; otherwise, it would not be a model but a memory repository.
This is understandable because the purpose of large model compression is to identify the characteristics and regularities of the dataset. The text generated by GPT-4 might seem familiar; the music generated by Suno might sound familiar; the videos generated by Sora might look familiar; the images generated by MJ might seem familiar. However, they are virtual individuals "restored" based on prompts, abstracted or compressed from big data: derived from data, higher than data, mingling with data, indistinguishable from real and fake.
Given that the compression object is the entire dataset content, how do we measure its effectiveness after decompression? What is the gold standard?
This standard is each sample itself. However, this is not entirely accurate; the standard could have equivalent answers, as the same content can have various ways of expressions. The implementation method is "masking", and NTP simply masks the next token. Training involves calculating the loss for each sample, using backpropagation with gradient descent to adjust parameters continually, eventually lowering the loss in the group training of the dataset to an acceptable point, forming the large model.
This final slide and Ilya’s explanation emphasize a core point: Conditional Kolmogorov complexity K(Y|X) provides a theoretically optimal solution for unsupervised learning. K(Y|X) is defined as the length of the shortest program that produces the output dataset Y given access to the input dataset X. It represents the theoretical limit of extracting all valuable information from X to predict Y. An algorithm that can achieve K(Y|X) would be the best for predicting Y using unlabeled data X.
This can be seen as the theoretical basis for large models performing various language translations. Each language is potentially X and potentially Y. After self-learning with an huge amount of data, LLMs learn the relationships between languages, possessing the potential to translate from X to Y.
In practice, the machine translation task, like other tasks, initially involves few-shot examples in instruction-following fine-tuning to define the task, ultimately triggering the internal power of large models to translate various languages. This internal power of unsupervised learning for various tasks is the theme of his talk.
However, K(Y|X) is uncomputable in practice. Ilya proposes a feasible alternative, using joint Kolmogorov complexity K(X,Y) (joint compression of X and Y). He believes K(X,Y) can achieve the same effect as K(Y|X) in practical machine learning tasks.
Let us stop and think again: conditional modeling is now replaced by sequence modeling by Ilya. The widely known probability simplification in traditional machine learning, such as the Markov chain, has a similar effect.
Conclusion
Ilya's historic presentation at Berkeley on the theory of unsupervised learning reveals the secret behind the mainstream of self-learning large models, especially GPT. It seems that Ilya, after long contemplation, finally disclosed this "heavenly secret" in a cryptic manner at Berkeley. Although the theory and its proof appear complex, it is crucial for understanding why GPT's sequence learning method ("next token prediction") has become a universal simulator for AI tasks.
Ilya exudes a genius prophet aura, with a lonely invincibility and high-altitude isolation, blending a sense of deep realization, compassion, and the pure, focused, and idealistic earnestness of a graduate student nerd.
He claims to prefer compression but does not emphasize so-called lossless compression. He leaves room for himself and the mainstream, proposing the concept of "no regret"—though GPT may not achieve lossless or perfect compression, it theoretically proves there is no better way: GPT is the closest to lossless, "no-regret" modeling.
When Ilya officially re-emerges to establish SSI, emphasizing a single focus, a single goal, and a single product—to use technology to ensure the superintelligence brought by large models is safe for humanity—he asserts: AI will be eternal, its birth akin to the creation of heaven and earth. As Ilya passionately discusses AI's progress, he is most qualified to declare and lead the "exciting yet dangerous journey towards AGI."
References
Ilya's presentation:
Related Links:
https://www.youtube.com/live/AKMuA_TVz3A?si=7dVfcBUv3rHBHtyT
https://situational-awareness.ai/