我:
朋友终于装上了赫赫有名的谷歌 SytaxNet 中文自动分析器。随手试了一个例子。From syntaxnet, we have this parse:
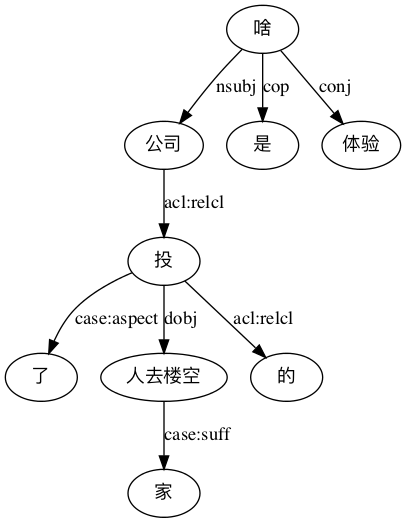
From yours truly, this is the result:
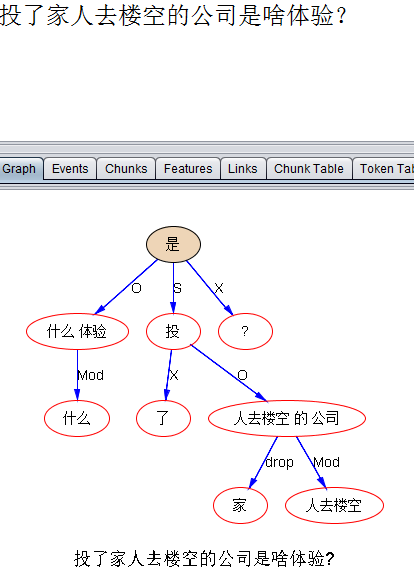
To laymen's eyes, they look alike. They are both dependency trees. Of course. They seem to have used the same or similar tools for drawing trees. But beyond these, they are so different. 天壤之别 in data quality.
For the SyntaxNet:(1) the link between 啥 and 体验 is wrong: it is not conj;(2) subject is also wrong,公司 should not be subject, subject is 投; (3)object of 投 is wrong, it is not 人去楼空, it should be 公司; (4) 投-VP is 定语从句,where syntaxnet is wrong too. Out of 8 dependencies, only 2 can be judged as right (了 is linked right; 的 might be judged as right as it is linked to 投 as relative clause marker) and they only involve 小词, all notional words are linked wrong and the function word 家 is also incorrectly attached, it should be linked to 公司. This is from the parsing system which claimed most accurate a few months ago.
白:
这里涉及几个细节:1、凭什么断定“家”是量词而不是名词?在扫一个处理一个的工作模式下这很有些勉为其难,因为真正强关联的词“公司”可能隔着远距离才能看到。要明确大家的工作模式都是可以等到不管多远的距离才出现的,大家一起比才公平。
1、凭什么断定“家”是量词而不是名词?在扫一个处理一个的工作模式下这很有些勉为其难,因为真正强关联的词“公司”可能隔着远距离才能看到。要明确大家的工作模式都是可以等到不管多远的距离才出现的,大家一起比才公平。2、“投”和“体验”各空出一个未填充的坑,但这两个坑是有关联的----谁投,谁体验。两种分析结果都没给出这个结论。
2、“投”和“体验”各空出一个未填充的坑,但这两个坑是有关联的----谁投,谁体验。两种分析结果都没给出这个结论。3、“是”接受谓词主语时,对宾语(表语)进行了一次约束,即宾语要么也是谓词,要么是对谓词有概括能力或者收束能力的名词。最后进入宾语位置的,到底是动词“体验”还是名词“体验”,是有讲究的。
3、“是”接受谓词主语时,对宾语(表语)进行了一次约束,即宾语要么也是谓词,要么是对谓词有概括能力或者收束能力的名词。最后进入宾语位置的,到底是动词“体验”还是名词“体验”,是有讲究的。“什么”可以把动词强制名词化,也可以自然修饰一个本色名词。但这对“是”语义是有区别的。谓词 是 什么 + 谓词,说的是两个谓词在时间上的叠合、因果上的联系。谓词 是 什么 + 名词,说的是用后面的名词对前面的谓词进行分类。“投”与作为名词的“家”,有那么格格不入吗?如果语料中投张三家、投李四家、王家赵家都OK,这里仅看到“投了家”就断定不OK,也太武断了点。既然不能断定不OK,起决定作用的还是与“公司”的强连接。对于静态文本处理的场景,一次吃进一堆,把强关联的量名搭配挑出来不难,对于语音或动态文本处理的场景,确实需要等。即使是静态文本处理,如果确定pos和做match是两个分离的步骤,pos的确定不依赖于match的阶段性成果,那么确定pos需要用到的窗口就必须足够大——大到可以把远距离的量名搭配容纳进来。否则,“家”的名词义项会在概率上占优,同时在局部找不到推翻这种优势的硬证据。
wang:
白老师,这里引出了2个问题 1),POS 和match ,如何走的问题? 2)不同情形下,窗口多大要拉多大的问题?
本人的主张,是POS和match协调走 。或说是WSD和Parse协同进行。若不依赖match阶段性结果,单靠pos自己,可能窗口再大,效果也不见得好,除非支撑的语料能足够大。
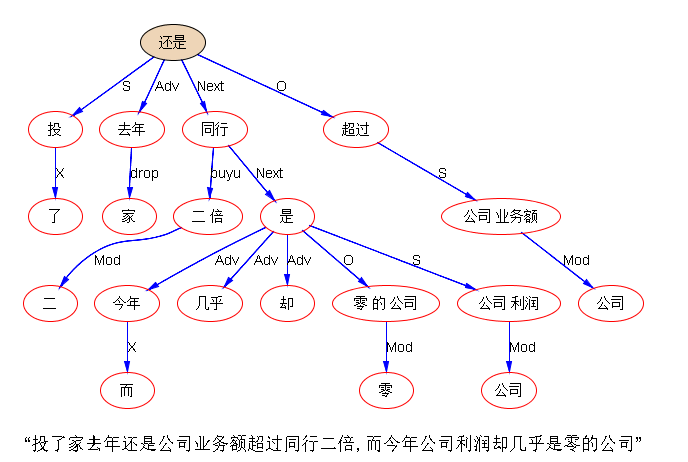
“投了家去年还是公司业务额超过同行二倍,而今年公司利润却几乎是零的公司”
这里的“家”与最终的关联的“公司”,实在距离太长,而且其中还有干扰型的两个“公司”。要支撑这样的窗口长度的数据,--太难白硕:
白:
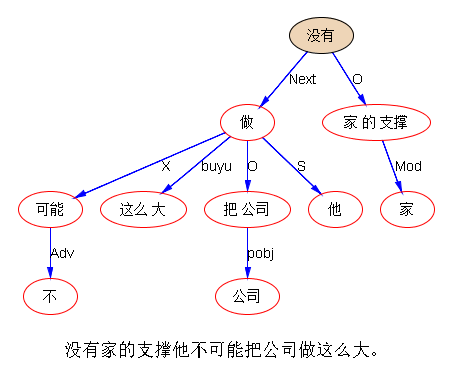
有“公司”出现就可以被wsd加分,真正修饰哪一个“公司”,只能靠matcher独立判断。除非构造一个受“公司”干扰、后面居然还不取“家”的“量词”义项的例子。比如,“没有家的支撑他不可能把公司做这么大。” 或者再离近一点,“没有家的支撑公司不可能被他做到这么大。”wei wang:
wang:
窗口长了,内容的处理只好粗糙些了白硕:
白:
如果是纯粹基于规则,可以耍个流氓,把“家”归入一个变色龙词类,见人说人话 见鬼说鬼话。但是基于关联,耍不得这样的流氓。N+和N不能用X来做wildcard。wang:
wang:
嗯,明白。基于关联的方法,虽然有点难,但走远还是有望的。白老师的例子,“没有家的支撑公司不可能被他做到这么大。”,感觉“家”也不能被“公司”挟持着
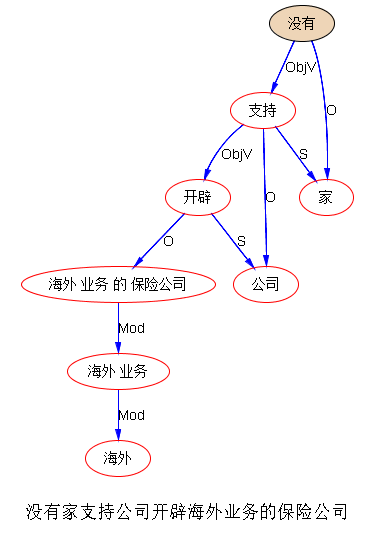
想了一下“没有家”做特征也不妥,“没有家支持公司开辟海外业务的保险公司”
这里“家”--又变了“量词”。解析不决问谷歌,或百度:Without the support of the company can not be done by him so much.
Without the support of the company can not be done by him so much.
wei wang:
谷歌解析,--把“家”弄丢了No home support company can not be so big.
No home support company can not be so big.
百度,家倒是出现了,“家”字面翻译wei wang:
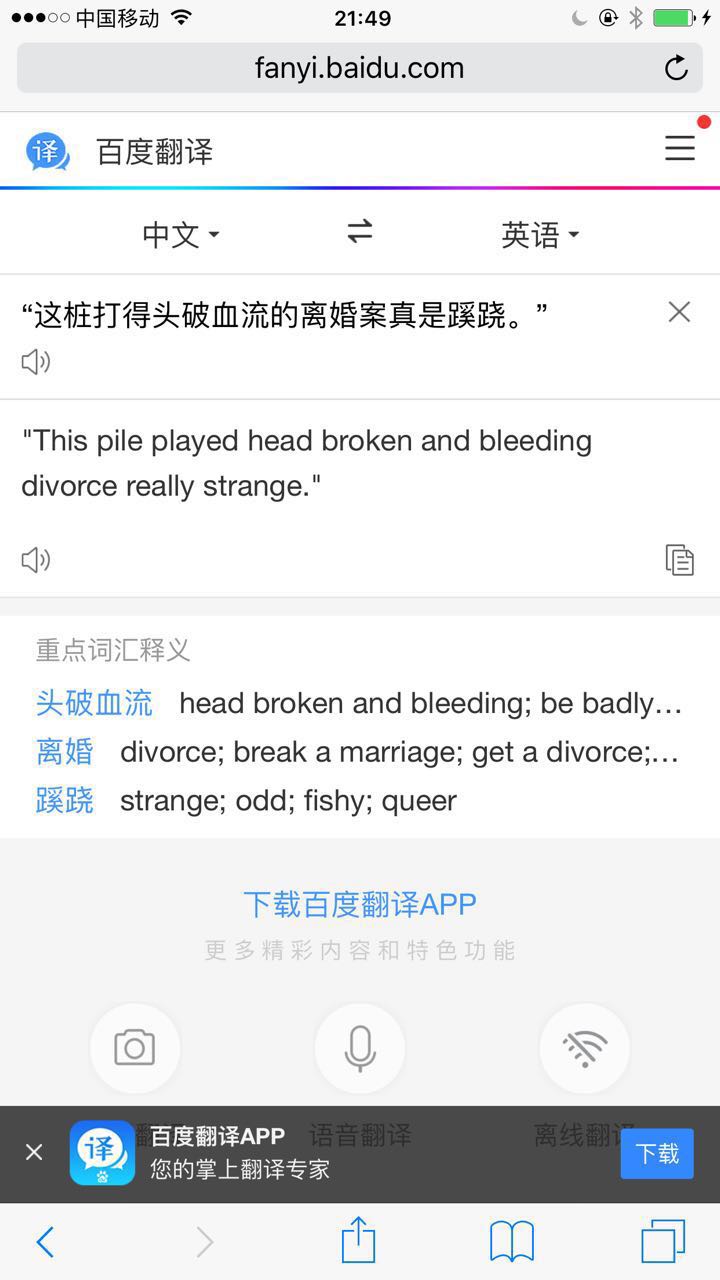
“投了家人去楼空的公司是啥体验?”
百度:The family went to the floor of the empty company is what experience?
wei wang:
谷歌:Voted to empty the company is what experience?似乎,谷歌对量词“家”还是可以的
似乎,谷歌对量词“家”还是可以的
-----看来“家”是量词和名词,结果也是不尽人意
我:
@wang 你造句的时候能不能普罗一点儿?不带这样的。
wang:
李老师,第一个句子分析不错。第二句子是为了拉长“家“和关联的“公司“的距离,而造的,确实有点难为机器了。只是说明,距离长可很长。
我:
我是说你缺乏同情心, :=)
wang:
第三个句子,那个“家”没处理出来,有点遗憾。
认错,同情心对机器。“开辟海外业务的保险公司” 独揽了,导致断链。
白:
还没有见到用干扰项“公司”把“家”成功引走的例子。
wang:
说明这抗干扰能力,不是一般的强啊。
这家早就成为公司的临时办公室了。
刚才仔细模拟机器分析句子,“没有家支持公司开辟海外业务的保险公司” 分析出“家”为量词,这个确实太难了。好几处匹配都几乎坐实了“家”为名词,而翻盘的力量实在太微弱。当然基于规则的方法,可能会另有春天。
谷歌的翻译确实了!
There is no insurance company that supports the company's overseas business
以上这是百度的翻译
No home support company to open up overseas business insurance company
以上是谷歌翻译。百度的表现,真心不错
白:
本群就有百度的好几位大牛哦。
“难道就没家给公司提供像样的办公用品的公司吗?”
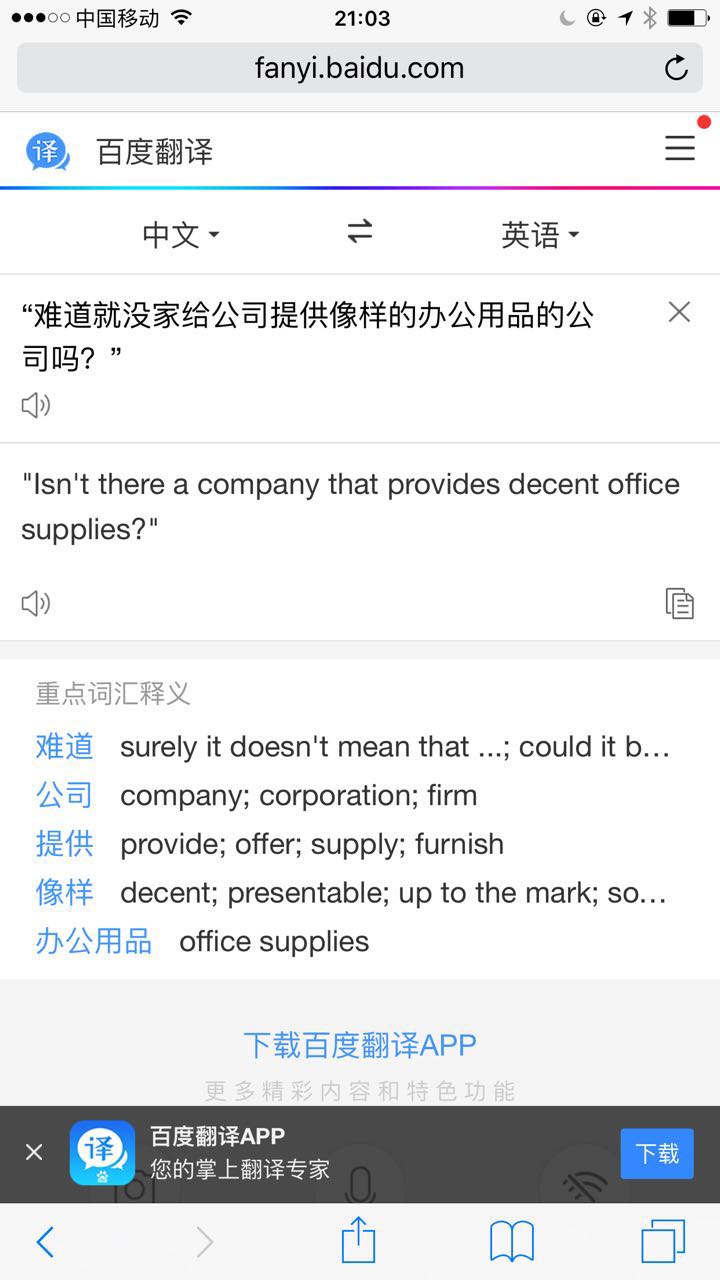
很赞!
wang:
向百度大牛学习!
白:
好几位百度从事NLP的专家在本群潜水。
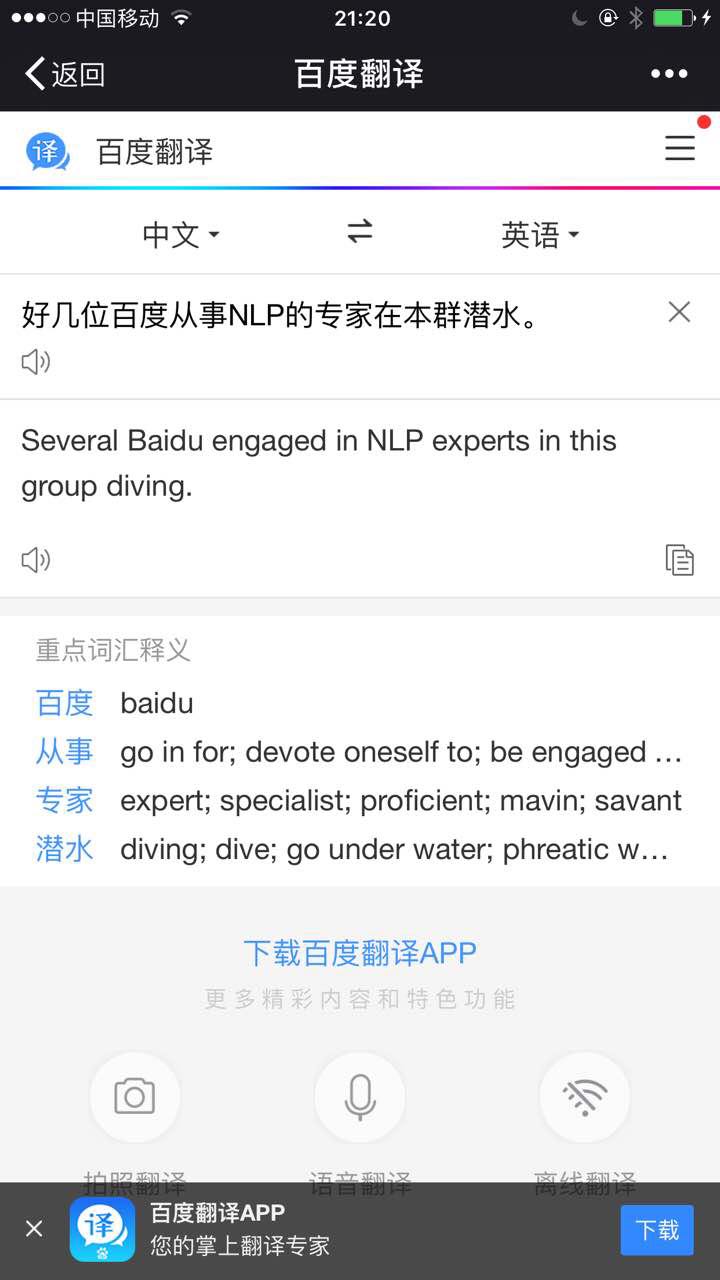
“百度”没逃过去这个远距离相关的陷阱。
1024位素数作为模,应该够安全了。

digits没翻出来,prime也没用复数,捣浆糊啊。
模翻成model, 数学上也不算对。
三位整数做密码,太不安全了
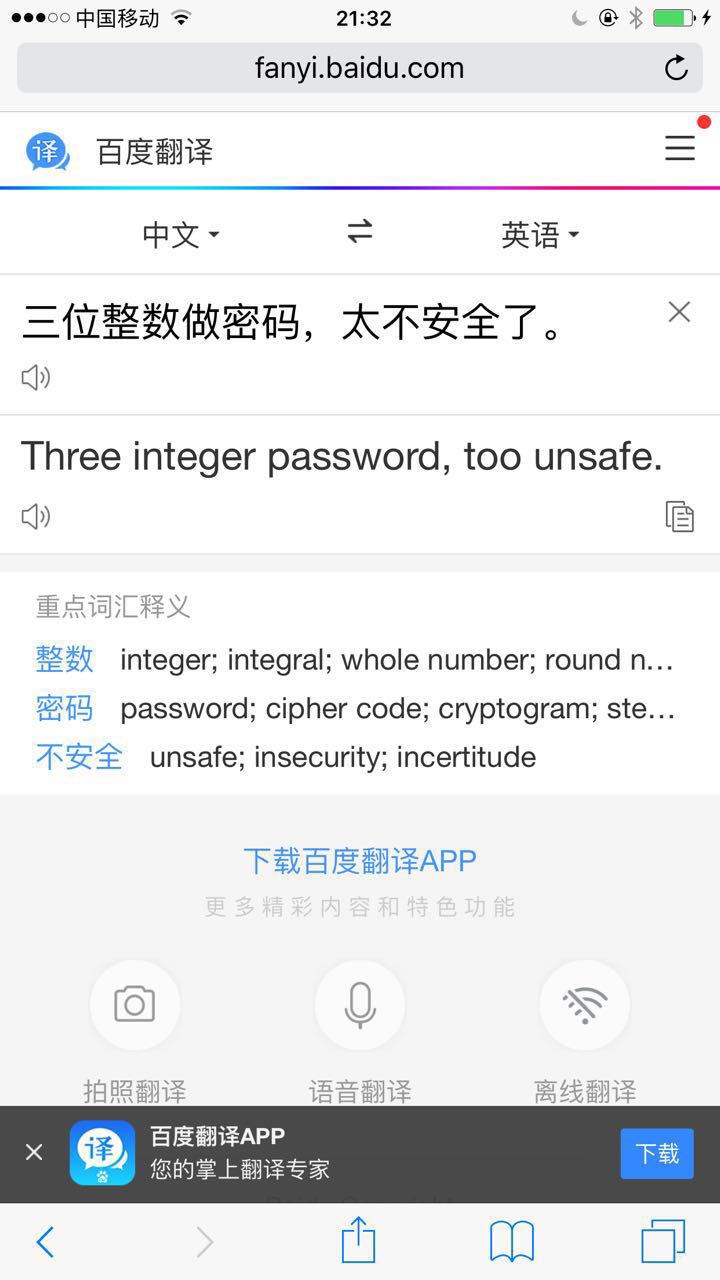
又是捣浆糊。
但这里明显是三“个”整数的意思,只不过语法错了。原文是一“个”整数,有三个十进制位。
量词兼其他词类的情况,是很细的细活儿。
调戏完毕。
【相关】