随着深度学习在图像识别、语音识别及其他感知智能领域大放异彩,人们对深度学习在自然语言处理(NLP) 的价值也寄予了厚望。再加上 AlphaGo 的成功,人工智能的自然语言研究和应用变得炙手可热。NLP 作为人工智能领域的认知智能,成为目前大家关注的焦点。
李维博士是 Simon Fraser University 计算语言学博士,中国社会科学院研究生院机器翻译硕士,现任京东硅谷研究院主任研究员,领导 Y 事业部硅谷 NLP 团队,研发自然语言深度解析(deep parsing)平台及其 NLP 应用,目前聚焦于大数据情报和舆情挖掘,以及电商智慧供应链的应用。加入京东前,李维在硅谷社交舆情公司 Netbase 任首席科学家,Cymfony 任研发副总。在 NLP数据挖掘领域有丰富的经验。
我们很荣幸能邀请李维博士到 12 月 8-9 日在北京国际会议中心举办的 ArchSummit 全球架构师峰会上就NLP做主题演讲。在此之前,我们对李维博士进行专访,一起聊聊他在 NLP 上的研究和应用成果。
NLP入门
自然语言很复杂,自然语言处理(NLP)没有捷径。所谓NLP 技能速成训练,除非指的是浅尝辄止,或所面对的是浅层的粗线条任务,否则基本上是自欺欺人。我有一个五万小时成精的定律,是这样说的:
“NLP 这玩意儿要做好(精准达到接近人的分析能力,鲁棒达到可以对付社会媒体这样的 monster,高效达到线性实现,real time 应用),确实不是一蹴而就能成的。这里有个 N 万小时定律。大体是:
- NLP 入门需要一万小时(大约五年工龄);
- 找到感觉需要两万小时;
- 栽几个有意义的跟头需要三万小时;
- 得心应手需要四万小时;
- 等你做到五万小时(入行 25 年)还没被淘汰的话,就可以成精了。”
摘自我的博客《聊聊 NLP 工业研发的掌故》:http://t.cn/RW5nxq4
对于急功近利的人,这仿佛天方夜谭,但我想说的是,这是一条非常漫长的道路,然而并非深不见底。作为“励志”故事,《梦想成真》描述了我的真实经历和心路历程。我曾自嘲说:“不知道多少次电脑输入 NLP,出来的都是‘你老婆’。难怪 NLP 跟了我一辈子,or 我跟了 NLP 一辈子。不离不弃。” 其他关于我自己与 NLP 的故事,我有个专门系列,可以在【立委 NLP 频道】查看《关于我与 NLP》。那里还有 NLP 历史上的一些有趣掌故,有兴趣的同学也可以浏览。
《梦想成真》:http://t.cn/RW5n5bl
《立委 NLP 频道》:https://liweinlp.com/
《关于我与 NLP》:http://t.cn/R5E62tn
《关于 NLP 掌故》:http://t.cn/R5E6USF
NLP 要做深做透,要接近或达到类似人的深度解析和理解是一个艰难但并非不可能的历程,但我并不否定速成培训的功效和可能。毕竟并不是每一位想做点 NLP 的 AI 后学或同好,都有那个时间条件和需要去成为 NLP 的资深专家,很多时候就是要解决一个具体的浅层任务,譬如粗线条的分类(classification)和聚类(clustering)。
这时候,通过开源资源和标准测试集自我培训的方法至少可以训练一个人使用开源工具的能力,如果赶上面对的任务相对简单,而且不乏大量带标数据(labeled data),也可能会很快做出可用的结果。典型的例子有对于影评做舆情分类,这种限定在狭窄领域的任务,利用开源工具也可以做得很好。
事实上,18 年前我的两位实习生,现在也都是业界非常有成就的人物了,他们的暑期实习项目就做到了非常漂亮的影评舆情分类结果,当时用的就是基本的贝叶斯机器学习算法。对于后学,除了拿开源练手外,也不妨浏览一下我开设的 《NLP 网上大学》,或可开阔一点眼界,看到一些潮流以外的 NLP 风景。
《NLP 网上大学》:http://t.cn/R4ys9Jp
NLP 架构
这次大会是全球架构师峰会,咱们可以多从 NLP 架构角度说说。
对于自然语言处理及其应用,系统架构是核心问题,我在《立委科普:NLP 联络图》里面给了四个 NLP 系统的体系结构的框架图,从核心引擎直到应用。
《立委科普:NLP 联络图 》:http://t.cn/zjPxKKp
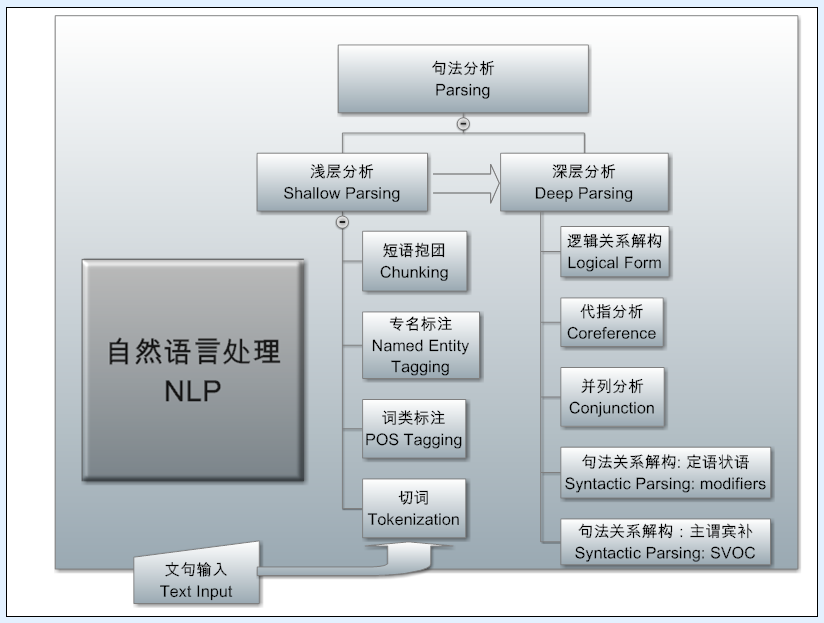
最底层最核心的是 deep parsing,就是对自然语言的自底而上层层推进的自动解析器,这个工作最繁难,但是它是 NLP 系统的基础赋能技术。解析的关键是把 非结构的语言结构化。面对千变万化的语言表达,只有结构化了,句型(patterns)才容易抓住,信息才好抽取,语义才好求解。这个道理早在乔姆斯基 1957 年语言学革命提出表层结构到深层结构转换的时候,就开始成为(计算)语言学的共识了。
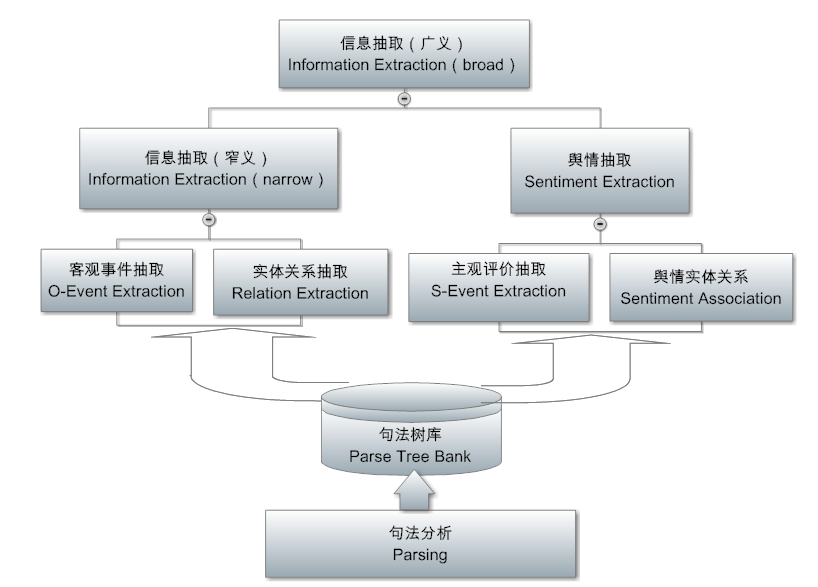
接下来的一层是抽取层(extraction),这一层已经从原先的开放领域的 parser 进入面向领域应用和产品需求的任务了。值得强调的是,抽取层是面向领域语义聚焦的,而前面的解析层则是领域独立的。因此,一个好的架构是把解析做得很深入很逻辑,以便减轻抽取的负担, 为领域转移创造条件。
有两大类抽取,一类是传统的信息抽取(IE),抽取的是事实或客观情报:实体、实体之间的关系、事件等,可以回答 who did what when and where (谁在何时何地做了什么)之类的问题。这个客观情报的抽取就是如今火得不能再火的知识图谱(knowledge graph)的技术基础,IE 完了以后再加上下一层挖掘里面的整合(业内叫 IF: Information Fusion),就可以构建知识图谱了。
另一类抽取是关于主观情报,舆情挖掘就是基于这一种抽取。细线条的舆情抽取不仅仅是褒贬分类,竖大拇指还是中指,还要挖掘舆情背后的理由来为决策提供依据。这是 NLP 中最难的任务之一,比客观情报的抽取要难得多。抽取出来的信息通常是存到某种数据库去。这就为下面的挖掘层提供了碎片情报。
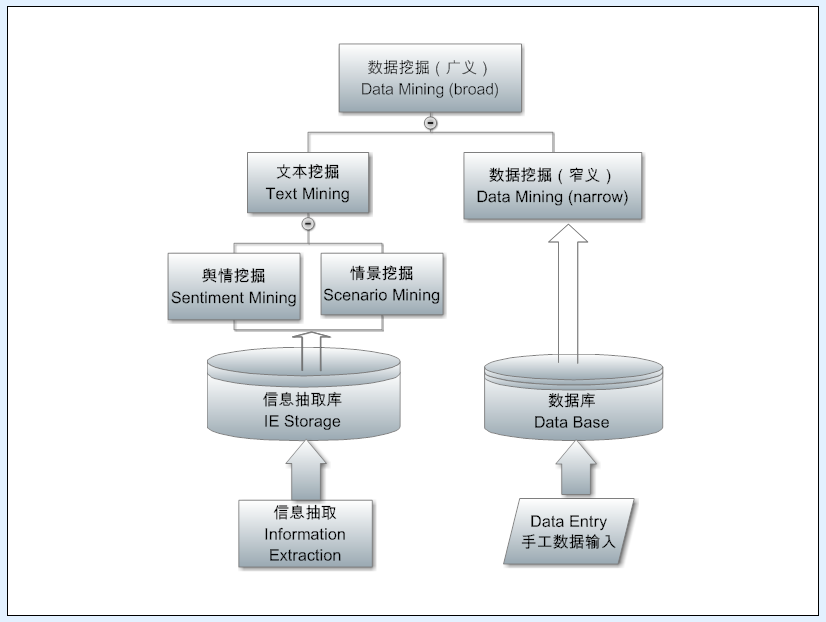
很多人混淆了抽取(information extraction) 和下一层的挖掘(text mining),但实际上这是两个层面的任务。抽取面对的是一颗颗语言的树,从一个个句子里面去找所要的情报。而挖掘面对的是一个 corpus,或数据源的整体,是从语言大数据的森林里面挖掘提炼有统计价值的情报。
挖掘最早针对的是交易记录这样的结构数据,容易挖掘出那些隐含的关联(如,买尿片的人常常也买啤酒,原来是新为人父的人的惯常行为,这类情报挖掘出来可以帮助优化商品摆放和销售)。如今,自然语言也结构化为抽取的碎片情报在数据库了,当然也就可以做隐含关联的挖掘来提升情报的价值,这也是我们京东 NLP 在电商领域着力要做的任务之一。
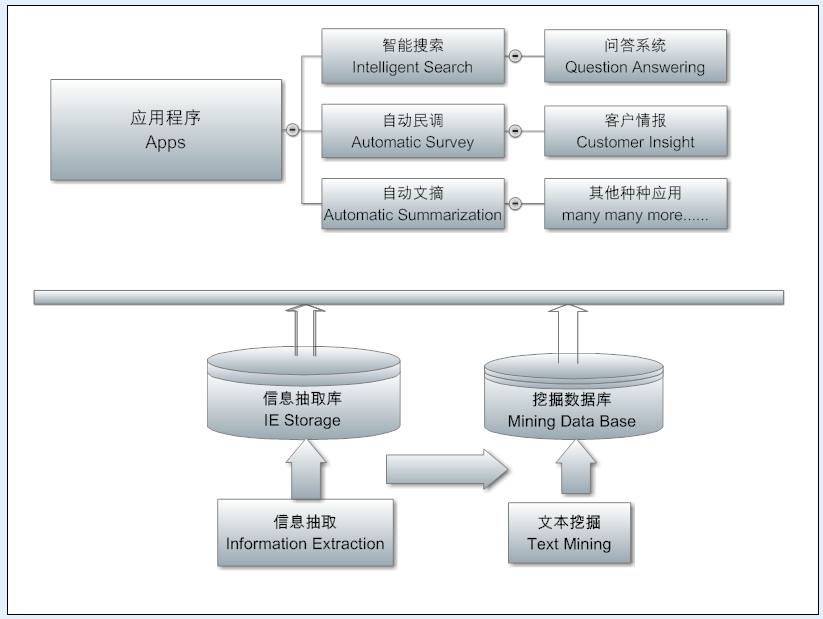
第四张架构图是 NLP 应用(Apps)层。在这一层,解析、抽取、挖掘出来的种种情报可以支持不同 NLP 产品和服务。从问答系统到知识图谱(包括对于电商领域具有核心价值的产品图谱和用户画像及其之间的关联),从自动民调到客户情报,从智能助理到自动文摘等,这些都是 NLP 可以发力的地方。
摘自《立委科普:自然语言系统架构简说》:http://t.cn/RW53AH0
NLP 团队
具体到目前的工作,我领导的京东硅谷 NLP 团队还是有很多与众不同的特色。
我们的主核是把语言结构化然后支持应用,而不是主流 NLP 的绕过显性结构解析来做的端到端深度学习。为此我们结合了人工智能领域的两大流派,以创新的多层符号逻辑(包括利用本体知识和常识的 ontology)和语言学模块作为精准分析的基础,以统计学习作为 backoff,使得两种方法互补,取长补短。
这样设计的好处不仅照顾了 NLP 的精准(precision)和召回(recall)两方面的需求,而且使得系统调控变得比较透明,容易 debug。相较端对端系统,结构化的最大优势是不依赖海量的带标数据,因为深度解析的 NLP 应用是在知识和结构理解的基础上进行的知识工程项目,而不是从表层的标注好的冗余案例中学出来的模型。
这对于京东的一些场景有特别的意义。京东不乏业务场景和 各种NLP 应用的领域需求,这些场景和领域往往没有现成的带标数据,为这些多方面的场景组织人力进行深度学习所需要的海量标注,常常不是一件现实的事情。我们的目的就是打造具有核武器威力的 NLP 深度解析平台,克服这个带标数据的知识瓶颈,为 NLP 多方面的电商场景的应用落地开辟道路,尤其是京东智慧供应链对市场需求客户情报的洞察挖掘以及产品舆情的意图挖掘,构建对于电商智能化至关重要的商品图谱(product knowledge graph)和用户画像(user profile)的知识引擎。
这条道路初期比较艰辛,需要深厚的计算语言学的功力和大数据驱动的研发,但 NLP 深度核心引擎打造出来以后就是另一番天地,这是一个赋能的核心技术(enabling technology)。你想想,千变万化的语言表达一旦有规模的结构化以后,那会是一种什么情形:各种 NLP 任务在结构的显微镜下变得有迹可循,模式清晰并逻辑化,无论是情报挖掘还是其他应用都可以做到以不变应万变,以有限的句型把握无穷的语言现象。这就是我说的 “深度解析是 NLP 应用的核武器” 的本意。我在演讲中会通过多方面的 NLP 应用场景来展示和论证这一主题。
深度解析
所谓深度解析(deep parsing),就是把非结构的文本语句(unstructured text)自动解析成为深层的结构化数据(学界也称为 logical form),就是在自然语言与数据库之间建立自然语言理解(natural language understanding)的桥梁。
主流的文本情报挖掘(text mining)是绕过结构和理解的,依靠的是端对端的自动抽取挖掘的机器学习和深度神经。在具有海量带标大数据的情况下,由于数据的丰富和冗余,端对端的有监督学习系统也可以达成很好的挖掘效果。然而,一旦领域挖掘任务变了,必须重新标注和重新学习,这里面临一个巨大的知识瓶颈,就是说,领域带标数据往往严重不足,为每一个领域的每一个挖掘任务组织人力标注一个大数据训练集来克服稀疏数据的困难往往是不现实的。这是当前 AI 和 NLP 主流面临的一个巨大挑战。
我们的对策就是融合深度解析(deep parsing)和深度学习(deep learning),结合人工智能的理性主义和经验主义方法论,各取所长,利用深度解析来保证数据挖掘的精准度(precision),利用深度学习来提高数据挖掘召回率(recall)。
以社会媒体舆情挖掘为例,面对以短消息作为压倒多数的开放领域(open domain)社媒大数据,缺乏结构分析的主流舆情分类方法面临一个精准度瓶颈(业界公认 65% 是难以逾越的天花板),而利用深度解析的结构化舆情挖掘,我们可以达到 85% 以上的精准度,整整 20 个百分点的差距,这样的精度才真正能为舆情挖掘基础上的决策和智能化应用提供可靠的保障。
在智慧供应链的选品环节,从全网数据挖掘出可靠的用户需求及其对于产品的舆情反馈(点赞抱怨及其背后的理由)是非常重要的决策情报。这是我们目前的深度分析平台落地的主要目标之一。
NLP 作用
语言的奥秘在于,语句的呈现是线性的,我们人类说话或写文章,都是一个词接着一个词表达出一个一个的语句;但语言学的研究揭示,语句背后是有语法结构的。我们之所以能够理解语句的意思,是因为我们的大脑语言处理中枢能够把线性语句下意识解构(decode)成二维的结构:语法学家常常用上下颠倒的树形图来表达解构的结果,这个过程就是深度解析(deep parsing)。
深度解析被公认为是自然语言处理和理解的核心任务,但长期以来大多是科学家实验室的玩具系统(toy systems),其速度(speed)、精准度(precision)、覆盖面(recall)和鲁棒性(robustness)都不足以在真实语料的大数据场景应用。而这一切已经不再是梦想,高精准度和高召回率(作为指标,精准召回的综合指标 F-score 要达到 90% 以上,接近语言学专家的分析水平)、符合线速要求的鲁棒的深度自动解析已经得到验证和实现,这是大数据时代的 NLP 技术福音。
再强调一遍,语言为什么要结构化?盖因语言是无限的,但结构是有限的,只有结构化,有限的模式才能捕捉变化多端的语言。话句话说,结构化是语言理解应用之本,现代的 deep parser 就是结构化的核武器。
总体而言,我们面对的是不断变化的 NLP 任务,变化中的不同业务场景和情报需求。靠谱的深度解析结果反映在语法语义的结构图上,它离领域的信息抽取和情报挖掘只有一步之遥,离情感分析或舆情挖掘可以说是两步之遥(深度舆情的确需要一些苦功夫,舆情语言的复杂多变和模糊不确定,使得舆情挖掘比起传统的以事实作为抽取对象的情报挖掘要困难)。
结构化信息抽取的作用是巨大的,有多少产品的想法,就可以定义多少种不同的抽取任务。但万变不离其宗,只要抽取面对的是自然语言,它就必然总体上服从这个语言的文法,因此深度解析成为核心引擎的系统就顺风顺水。知识瓶颈因此被很大程度地克服了,不再需要那么多的带标数据。有了 parser,只要一些示意性的带标数据就够了,开发者可以根据示意举一反三。大多数信息抽取的开发任务,在有靠谱 parser 的支持下,可以在 2-4 周内开发完成,满足应用的基本需要,后面就是维护和根据反馈的 bugs 报告,做增量修补而已。
所以说 deep parser 打开了通向应用的大门和无限可能性。对于京东的智慧供应链和电商平台的业务场景,我们的愿景是让深度解析落地开花在多个 NLP 方向上,包括提升自动客服的语言理解水平,构建商品的知识图谱和用户画像,这当然也包括客户需求和商品舆情的挖掘和应用。
中文与 NLP
比起英语和其他欧洲语言,中文的语法具有相当程度的灵活性,成为自动分析的难题。与业界同仁的交流中,我们把中文叫做“裸奔”的语言,就是说中文的表达缺乏显性的形式标志,因为中文没有形态(词尾),常常省略功能词(譬如介词),而且词序其实也相当灵活。
这些语言学的特点,加上不同地区的人的不同语言习惯,再加上社会媒体中反映出来的大量别字以及语言不规范,使得很多人对中文自动分析有很深的怀疑。这是好事儿,正因为它看上去如此复杂多变,才更需要对语言学的深刻认识和对语言工程的架构和方法有独特的创新。中文自动处理和理解提高了技术竞争的门槛。
这对我们而言,就意味着要突破乔姆斯基理论为基础的传统流行的上下文自由文法(CFG)的单层 chart-parsing,代之以自底而上的多层管式语言处理系统,从而穿越乔姆斯基层级体系(Chomsky hierarchy)的围墙,在机制上有所创新(formalism innovation)。这一切需要深厚的计算语言学的素养和积累,才有希望。这方面的理论和实践,可参见白硕老师的《白硕 – 穿越乔家大院寻找“毛毛虫”》以及我的《乔姆斯基批判》和《语言创造简史》。
《白硕 – 穿越乔家大院寻找“毛毛虫”》:http://t.cn/RW5BfvW
《乔姆斯基批判》:http://t.cn/R2HCmtg
《语言创造简史》:http://t.cn/RAVTyiu
举例就举老友转来挑战我的所谓“2016 年最佳语文组词能力”,他给我发微信说:“钱是没有问题”,就这六个字的组词成句,可以变成不同意思的句子!哈哈,伟大的语文能力!parsing 请:
钱是没有问题;问题是没有钱;有钱是没问题;没有钱是问题;问题是钱没有;钱没有是问题;钱有没有问题;是有钱没问题;是没钱有问题;是钱没有问题;有问题是没钱;没问题是有钱;没钱是有问题。
老友说的是中文词的不同的组合产生不同的意义,给人感觉是如此微妙,机器如何识别?其实仔细研究可以发现,这样的语言事实(现象)并非想象的那样玄妙不可捉摸。先看一下机器全自动分析出的样子吧!

这里面的 know-how 的细节就不赘述了,总之结果虽然仍有少数不尽如意尚有改进空间的结构分析,但几乎每个 parse 都可以站得住,说得出道理。作为设计者,我自己都有点吓倒了。(摘自《一日一 parsing:”钱是没有问题”》,更多参见【立委科普:自动分析《伟大的中文》】,关于中文自动分析的很多有意思的案例和深入的讨论,也可参看白硕老师与我就中文NLP的华山论剑似的《李白对话录系列》)。
《一日一 parsing:”钱是没有问题”》:http://t.cn/RW5rADs
立委科普:自动分析《伟大的中文》:http://t.cn/RW5rJhE
《李白对话录》:http://t.cn/RW5rNLM
NLP 场景与未来
有问是技术驱动业务,还是业务来驱动技术?我们坚持业务驱动,毕竟 NLP 是一个应用学科,再深的分析研究最终还是要落实到业务场景,解决业务痛点才能显示其价值。
在这个基础上,我们尝试从业务场景的点开始,逐渐借助深度解析的 NLP 平台技术,扩展到多项业务场景,发挥结构化技术的跨领域核武器的作用,帮助克服领域数据的不足,以期快速领域化。
我这个小组的成员在业界有多年的 NLP 和机器学习专业经验,但成立迄今才刚半年,一切还是刚刚开始。随着深度解析平台的建立和打磨,在京东电商的各个场景只要找准 NLP 的切入点和大数据的场景,就会有实际的效益,对这一点我们充满信心。
大数据时代的信息过载,使得人类个体消化和利用信息的能力受到严重限制,只有借助电脑的自动分析和挖掘,情报才能从噪音的海洋中被有效挖掘和利用。
那么 10 年后 NLP 会怎样呢?
回顾 NLP 的历史,语言技术真正落地开花结果还局限于少数几个方向,如机器翻译、语音系统和文本分类。今后的 10 年才真正是 NLP 的黄金时代,全面开花结果可以期待,尤其在情报挖掘、知识图谱、人机交互和智能搜索方面。NLP 是人工智能从感知全面进入认知的桥梁。
我这么说不是廉价迎合多少已经带有泡沫的 AI 现状,而是作为第一线 AI 从业人员的真实的有感而发。为什么这么说?我的根据主要有四点:
- 深度解析技术业已成熟,接近或达到人的水平;
- 深度解析与深度学习的融合和合力可以取长补短;
- 大数据可以弥补 NLP 技术的不够完善之处。
- 信息过载的大数据时代,不缺乏NLP的用武之地。
我的观点是,NLP 面对大数据时代,想不乐观都不成。深度解析是 NLP 应用的核武器。