众所周知,作为符号系统,自然语言与电脑语言的最大差异和挑战在于其歧义性,有两类,结构歧义(structural ambiguity)和一词多义(相应的消歧任务叫WSD,word sense disambiguation)。如果没有这些随处可见的歧义,自然语言的自动分析就会与电脑语言的编译一样做到精准无误。因此,一般认为,自然语言parsing和NLU(自然语言理解)的核心任务就是消歧。至少理论上如此。
有意思的是,尽管自然语言一词多义极为普遍,结构歧义也颇常见,人类用语言交流却相当流畅,很多时候人根本就没有感觉到歧义的存在。只是到了我们做 parser 在计算机上实现的时候,这个问题才凸显。与宋老师的下列对话显示,计算语言学家模拟结构分析常遭遇歧义。
宋:
“张三对李四的批评咬牙切齿”,这是两可。
“張三对李四的批评不置一词”,这里有第三种可能。
“張三对李四的批评保持中立”,另一种两可。
“張三对李四的批评态度温和”,这是三可了。
我:
宋老师 我已经晕了。您是计算语言学家的敏感或敏锐,绝大多数 native speakers 是感觉不到这些句子之间的结构歧义及其不同之处的。
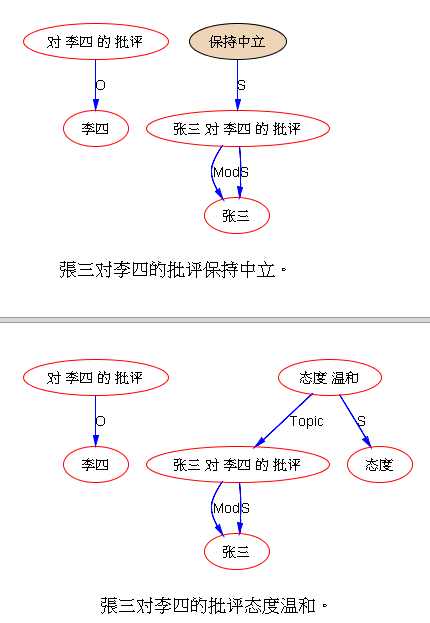
目前的 parsing 结果,“保持中立” 的主语(S)是“批评”,这个解读不是不可能(批评意见的保持中立,可以间接指代给出这个批评的“张三”),但很勉强;多数人的解读应该是:“张三” 保持中立,“张三”不是“批评”的主语,“李四”是,不仅如此,“批评”隐含宾语回指到“张三”。第二句的parse倒显得更合理一些,关于这个“批评”(Topic),(其)“态度"是"温和"的,指代的是“张三”,而“批评”“李四”的正是“张三”。
宋:
“张三对李四的批评”+谓语,就批评者和被批评者来讲,有3种填坑的可能:
(1)批评者是张三,被批评者是李四。(2)批评者是李四,被批评者是张三。(3)批评者是李四,被批评者是第三者。
“置若罔闻”与“不置一词”不一样。对于这个V的主体A来说,一定是有一个评论,“置若罔闻”是说该评论是针对A的,而且是负面的;“不置一词”则没有这两条限制。
我:
两个逻辑谓词(句末的谓语和前面的“批评”)抢同一个PP(对),计算上总会遇到 scope 纠缠。再加一个 “对(or 对于)” 歧义就没了。“张三【‘对于’【‘对’李四的批评】 保持中立】。” 可是两个 “对” 听起来别扭,很少人这么用。
结构歧义其实没有我们想象的可怕。如果目标是语义落地 需要调整的不是追求落地前消灭一切歧义,而是反过来思维,如何让语义落地能够容忍歧义的保留,或者歧义的休眠,或者任意的某个 valid 的路径。其实人的理解和响应 也不是在 ambiguity-free 的前提下进行。现代医学有一个概念,叫带病生存。语言理解也应该有一个概念,带歧义落地。适度的歧义作为常态来容忍。
这是结构歧义,WSD 更是如此。绝大多数语义落地 可以容忍或绕过 WSD 的不作为(【NLP 迷思之四:词义消歧(WSD)是NLP应用的瓶颈】)。MT 可能是对 WSD 最敏感的一个语义落地的应用了。即便如此,也并非先做好 WSD 然后才能做好 MT 落地(MT中叫 “lexical transfer”)。有亲戚关系的语言对之间 有很大的 keep ambiguity untouched 的空间 自不必说。即便在不相关的语系之间,譬如英汉的MT中,实践证明,全方位的 WSD 也是不必要的。细线条的 WSD 则更不必要。细线条指的是 词典里面的那些义项, 或 WordNet 中 synsets,其中的很多本义和引申义的细微差别 没有必要区分。
还有那些那些 hidden 的逻辑语义,是不是要挖掘出来呢?迄今为止,我们在句法后的语义中间件中做了部分这样的工作,但一直没有全力以赴去做全,虽然因为句法结构树已经提供了很好的条件了,这个工作并不是高难度的。
今天思考的结果是,其实很多 hidden links 没有必要整出来。如果一个 hidden link 本身就很模糊或歧义,那就更应该置之不理。自然语言带有相当程度的模糊性,语言本身也不是为了把每个细节都弄清白。人的交流不需要。如果一个细节足够重要,但这个细节在表达上是 hidden 的,省略的,或模糊的,那么人的交流就会在接下去的句子中把它 explicitly 用清晰无误的句法结构表达出来。
从语义落地的实践中也发现,大多数的 hidden links 也是不必要的。背后的道理是:信息流动的常态是不完整,不完整在信息交流中起到了减轻记忆负担、强化信息核心的重要作用。
理论上,每一个提到的谓词都有自己的 arg structure,里面都有潜在的坑,需要信息的萝卜来填。但语言的句法会区分谓词的不同地位,来决定是否把萝卜显性地表达出来,或隐去萝卜。常见的情形是,隐去、省略的萝卜或者不重要,或者不确定,都是信息交流双方不太 care 的细节。譬如一个动词 nominalize 后,就往往隐去 args (英语的动名词,汉语利用“的”的NP句式)。这种自然的隐去已经说明了细节不是关注点,我们何苦要硬去究它呢?
当然,上面说的是原则。凡原则一定有例外,某个隐去的细节如果不整明白,语义就很难落地到某个产品。能想到的“例外”就是,很多 hidden links 虽然其语义本身在语用上不是重要的信息,但是至少在 MT 的产品中,这个 hidden link 可以提供结构条件,帮助确定更合适的译词: e.g. this mistake is easy to make:make 与 mistake 的 hidden VO link 不整出来,就很难确定 make 的合适译法为 “犯(错误)”
关于隐去或省略的大多是不重要的,因此也 NLU 通常不 decode 出来也 OK,可以举个极端的例子来说明:
Giving to the poor is a virtue
Giving is a virtue
give 是一个 3-arg 的谓词,who give what to whom,但是在句法的名物化过程中,我们看到第一句只显性保留了一个萝卜(“to the poor”)。第二句连一个萝卜也没有。
我们要不要从上下文或利用标配去把这些剩下的坑都填上呢?
不。
白:
从陈述性用法“降格”为指称性用法的时候,对坑所采取的态度应该是八个字:“来者不拒、过时不候。” 比如,"这本书,出版比不出版好。"
我们没有必要关心谁出版,但是既然提高了这本书,填坑也就是一个举手之劳。
我:
很同意。就是说,一般来说对于这些有坑近处没萝卜的,我们不要觉得愧疚和心虚,who cares
【相关】