白:“让机器学习思考的人”
wang:1.让 机器 学习 (思考的人) 2.(让 机器 学习 思考)的 人 3. (让 机器学习 思考)的人
李:你的2是hidden ambiguity,里面其实还有两条hidden路径,“学习”的对象或目标是“思考”,还有一条,“学习-思考” 并列,逻辑上是,“让机器-学习、让机器-思考”。但面对专业术语“机器学习”的紧密性和高频度,那些 hidden ambiguity paths 都被掩埋了 ...... 也应该掩埋,除非遇到必须唤醒的时候。
parse parse 看:
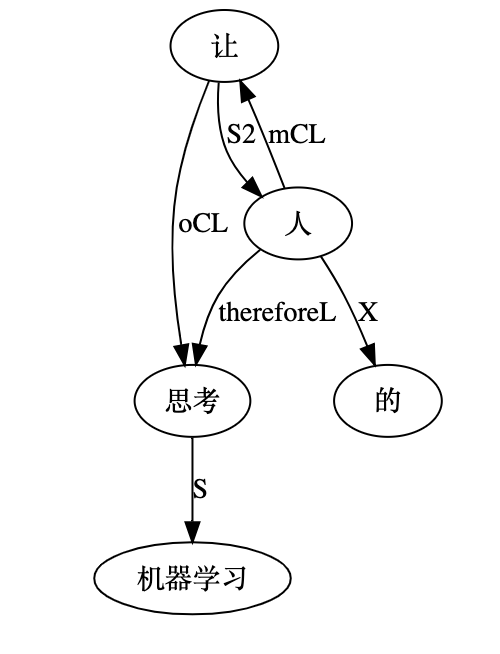
这个 therefore 可能是个 bug,语义模块做因果关系过头了,走火入魔了?深度解析其他该有的关系都在 though。
wait a minute,好像也对,说的是,因为 X 促成了 event,X 是因,event 是果。这就是语义模块本来的因果关系逻辑,落在这句就是,thanks to “人”, (therefore)ML thinks now。这符合 “有多少人工 有多少智能,人是一切机器学习的原始发动机” 的因果本质。乍一看有点绕,是因为赶巧这一句不是一个 statement,而是一个定语从句修饰的NP。其结果,这个因果关系虽然不错,但实际上是隐含的因果(hidden causal links)。如果是一个NE,更加容易理解一些“”让机器学习思考的图灵大师“。因为图灵, 所以机器思考。我思故我在,图灵在故机器思。
白:“坛坛罐罐走不齐”正好可以借这个例子现身说法。当“机器学习”和“机器/学习”同时进入parser的视野时, 下一步优先级最高的动作却不长在“机器学习”和任何其他成分之间,而是长在“学习”和“思考”之间。换句话说,非最佳分词方案在这个局部激活了最佳句法方案,梦游了。
“学习S/NX”和“思考S/N”之间,有三种结合途径:一是填坑,二是合并,三是不作为。各自优先级不同。在外部,“让-机器”、“机器-学习”、“思考-的”、“的-人”也同时参与竞争。最后结果是“学习-思考”合并最优先。就是“并列结构”那一个解读。
“学习”和“思考”能不能组成并列结构,这个事情是有不同做法的,可以白名单制,也可以黑名单制。个人主张白名单制。但是无论黑白名单,我都不主张做成同一层内部的细化规则,而主张把细化规则折合成优先级的调整量(增量或减量),统一纳入一个优先机制处理。也就是说,当条件不满足或不那么满足时,你不应该再赖在原来的优先层级不走,你落草的凤凰就是可能不如鸡,不是高高在鸡上面的“亚凤凰”,而是货真价实的“不如鸡”。
但是如果外部没有“鸡”竞争,落草的凤凰也还有机会折桂。就像colorless ideas,虽然被相谐性打了折扣,依然是四顾茫茫无对手。这个时候,机会还是它的。所谓的“句法自治”和“语义的反作用”在这种“坛坛罐罐走不齐”的策略下完美地统一了起来。不是“亚凤凰”跟“真凤凰”比,而是“亚凤凰”跟“?”比。鸡厉害,鸡就先走一步,坛坛罐罐于是就走不齐了,体现了包容不确定性的差异化前进。不同的解读不等速推进,可能一本道,也可能此起彼伏,明争暗斗,柳暗花明。
梁:@白硕 赞同!或许不同解读(歧义)在彼此争斗,此消彼长,最后一种解读胜出(消歧)。
李:多种因素综合决定消歧的理解过程,模型的时候 主要有这么几个对策。得出不确定性中间结果 就是带着瓶瓶罐罐往下跑。希望在下跑的某些阶段 条件成熟 可以帮助消歧。这里面又分白老师所谓“走不齐” ,就是说不需要把不确定性结果积聚到最后的消歧模块统一消歧。而是一边下行 一边伺机消歧 使得雪球不是越滚越大。
其实HPSG这类合一文法 就是这么做的,短语结构的任何结合 都是在对自然语言建模的数据结构里面“合一”。一旦任何一点合一失败 那条路就堵死了。句法的约束 语义的约束 还有种种其他的 constraints 全部定义在一个为语言符号建模的名字叫做 sign 的复杂特征结果里面,在同一个平面 同时起约束作用。这与传统句法先建立句法结构关系 然后留到语义模块去过滤减枝的瓶瓶罐罐一路带下去的做法显然不同。但实践证明 合一文法的做法 并未解决伪歧义泛滥成灾的问题 实际上还加剧了这个 PSG 学派所共有的历史难题。原因出在复杂特征结构的设计上。以前论过。
除了完全的非确定性和“走不齐”外,第三种办法就是所谓休眠唤醒。这是确定性路线。原则上不带瓶瓶罐罐跑 坚持确定性的中间结果表示。起码是看上去是确定性结果的数据结构,等待后期唤醒、改正。(这个里面还有很多技巧,譬如可以违背逻辑 利用确定性数据流承载非确定性结果 然后配备一些逻辑清理tricks 来为非逻辑性擦屁股 不好看 但很管用 以后可以细论。)
白:基于合一的消岐,错不在what,而在how,不在带着坛坛罐罐跑,而在“剪枝”。谁说带着坛坛罐罐跑就一定要“剪枝”?难道不可以“生芽”?
李:what?PSG呀,特征结构怎么定义 也还是 PSG,大的框框在那儿,复杂特征结构的做法加重了病情。
白:“生芽”的意思是,过河不拆桥,但也无需一下子搭建所有可能的桥。不达到当前最高优先级的渡口,绝不搭桥,但渡口的优先级是随着建起来的桥而动态变化的。这些达到当前最高优先级的渡口,就是“芽”。
渡口和渡口之间不是绝对互斥、你死我活的。一切按照优先级的指挥棒走,优先级要你保留歧义,你就保留;优先级要你梦游,你就梦游。没有谁绝对醒着,大家都有权睡觉,也都有权梦游。但是必须按优先级排队。
李:动态变化决定优先级和成熟度 对于多层系统是自然而然的事儿。第10层不愿意勉强的事儿 到20层的时候就很坦然了。同样一个句型规则 可以化成宽窄不同的变体 部署在多层。以前做模块是根据功能做,说是这是 NP,这是 PP,这是VP,这是 Clause。这样表面上清晰,实际上应对不同歧义及其出现的不同情势的能力,降低了。没有多少真正的理据必须把同一种功能放在一起做。这样做的问题是,如果遇到相互依赖的现象,就真没辙了。根据功能做模块,模块排队,这样的pipeline无法应对相互依赖。这是多层经常遭遇的经典批判。无解,还是回到单层吧。
但是,如果同一个功能,可以散开来,譬如VP中的动宾关系,做它一二十层,相互依赖的现象就逐渐消解了。大不了就是冗余。没有冗余,怎么能滴水不漏?
wang:顺便一提,@wei 我对你的海量规则对系统的comment,回复一下写得有点多,发微博上了。
李:很好,拷贝留存如下:
昨晚在一个群里就李老师说的内容提了一些问题,今天看到李老师详细回复,本想简单写写再发回群里,写完一看,这篇幅好像不适合放微信群里了,不如单发微博作为回复。李老师若觉不妥,告知我则立删。
@wei 中午看到李老师的后续回应, 现在正好有空这里回复一下。
看了李老师的后续内容,很是详细,而且前前后后已经考虑到很多方面,说明早有备货。大体勾勒一下:虽规则总量数万条,但通过分层(分组),就可以每组千条左右,规则之间的博弈也就在一个组内范围,即便组内的内斗激烈也不会引发组外的群组混战,这的确是“局部战役隔离解决”的最经济策略。另外,既然已经见识了规则系统的越大越不好对付的教训,想必肯定是避开了这个陷阱。一个组内至少再采用了共性+个性的两种及以上分支处理,先个性(词典)规则先前拦截,然后再共性来兜底,这样以来,一个组内可能内斗的程度又减轻不少,从走向来看,基本上是走大词典+小语法的组合路线,词典虽大但有索引方式来保速。如此以来,就把庞大的规则库,通过条块分割,把规则有序执行限制在了一个狭小的隔离河内,维护者在这样一个窄河里“捉鱼”确实容易得多。当然还有若干辅助策略,通过控局堵漏来进行加固。当然也看到“我是县长派来的”和“我是县长蹲点来的”有了不同的解析。这肯定不是一个简单“V”解决的,想必一定是词典策略起了作用。这词当然有丰富的语义信息了,我认为采用合适的语义范畴比词会有更好的覆盖性,尽管采用词准确性更高。
下面说下感受,必须承认之前本人还停留在规则系统教训的层面,另外,就是顾虑要扯入的人工工作量大的问题。若是李老师通过这样的俯瞰语言,化繁为简,调整规则能达到信手拈来,那么在机器学习满天飞的当下,这存量稀少的规则派之花,自有它的春天。如今是个多元的世界,允许各路英雄竞技,只要有独到之处,更何况人工智能皇冠上明珠,尚无人触及,怎下定论都是早。也曾闻工业界很多可靠的规则系统在默默运行,而学术界则只为提高小小百分点而狂堆系统,专挑好的蛋糕数据大把喂上,哪管产业是否能现实中落地。当然对于人工规则系统 VS 机器学习系统,能有怎样的结局,我确实没有定论,要么一方好的东西自然会好的走下去,要么两方都走得不错而难分输赢,或者发现只有结伴相携更能走远,那谁还能拦着么!
百花齐放,百家争鸣,各自在自己的路上,走出自己的精彩就好!世界本身就不是一种颜色,也不是一直就一种颜色
李:很赞。工作量大是所有专家编码、程序员编程的短板,自不必说。在一个好的机制平台架构下,规则应该可以非常容易编写和调试。规则应该看上去简单、透明,而不是需要玩精巧。像集成电路一样,能力不是每个单元的精巧,而是大量单元的组织集成。其实,半个世纪的持续探索,这种类似人海战术的规则海量快速编码迭代的路子是有了端倪了。说到底是数据制导,可以半自动进行,这与机器学习的海量数据训练,理据是相同的。昨天说自然语言是猫矢,应该学猫咪目标导向,反复迭代,不在一时一地的得失,不怕冗余,也不怕零星的中间错误。说的就是要创造一个环境,把小作坊的专家编码,变成可以工业化的规则流水线。以规则量取胜,而不是靠专家的精雕细刻。这条半自动的海量规则路线还在探索之中,但是前景已经相当清晰。
最后,符号规则不必争雄,游兵散勇也无法与正规军打遭遇战,但差异化总是优势与短板并存。寸有所长就是这个意思。大家在同一条路上跑,遇到困境与天花板都是类似的。这时候有人在另一条路上,保不准在最痛的某个部分,突然会有突破。原因无他,因为这力气使得角度不同,世界观不同,设计哲学不同。
据说,NLU是AI皇冠上的明珠,是珠穆朗玛峰。老友周明一直在为NLP鼓与呼,认定今后10年是NLP的黄金10年。AI似乎每天都在翻新,每周都有新闻,每月都有突破,浪头一个赶一个,新的算法、突破的model层出不穷,很多人惊呼“奇点”就要来临。为什么周老师还要提10年,对于AI进步主义者,这听上去简直是宇宙尺度了。为什么?无他,皇冠自有皇冠的难处,登顶珠峰绝非儿戏。唯此,有什么招使什么招吧,武器库还嫌武器多吗?
【相关】