李:白老师新作【白硕:闲话语义(7):事件】最后一段 “5、元关系·关系类型·裸关系” 蛮深奥,但很重要。看我理解对不对。想请教@白硕 的是,ontology 里面的概念节点,相当于词典里面的词。这些节点之间的关系都是“裸关系”吗?我一直把本体知识库 ontology 里面的一切关系看成“元关系”,对照于实体之间的“关系”,前者是后者的抽象,是人类世代积累的常识积淀。
ISA 与 “关系-判断”类型(譬如 partOf)不同样是“语义知识体系内部的关系”吗?当然感觉上 ISA 是 ontology 的核心骨架,单列出来也是合理的。 作为落地实现工具的知识图谱里的“关系”,是实体知识库,感觉不能与 ontology 混杂。前者是动态的“世界知识”(对于形势、趋势、身边事、国家大事的感知),后者是静态的常识(元知识)。
白:我们的目标,最后是要把与HowNet在表达能力上至少相当、在计算能力上更胜一筹的ontology写在知识图谱里。
李:是的,HowNet 很丰富细腻,但不好用,因为没有图谱的“技术栈”。
首先,实体和本体是分开的吧?怎么建立二者的联系是另一回事儿。作为知识库管理,应该是分开的。本体是封闭的、可以穷尽的知识体系。实体是完全开放的世界知识,而且每时每刻都在演变。
白:这个语义知识库只是应用的一部分。或者说,借助知识图谱的技术栈让语义知识库落地。怎么用,后面还有很多种可能性。
李:partOf 这类“关系-判断”类型的输出是“布尔”即逻辑真值。ISA 不也是吗?
“抽屉”是“橱柜” 的 part:TRUE
“动物” ISA “生物”: TRUE
“橱柜” ISA “生物”:FALSE
白:如果解析句子“他过去是单身汉,现在不是了。”
李:那是实体知识,不是本体知识。
白:本体要提供表示手段。
李:相关的本体知识是:“单身汉”是关于 “男人” 的属性,或一个子集。
白:这是经过一层解析了。单身汉首先是一个节点,他是另一个节点(男人节点的实例)。先要说这两个节点是怎么连的,再说根据单身汉的定义怎么“重写”他的属性。
李:解析是落地到实体,真还是假。本体是说类型合适不合适(相谐否):“类型”不合适的连真假都谈不上(记得以前的一个名句:his argument is not true,it is not even false,说的就是“不着调”的论辩)。
白:在“怎么连的”这个问题上,我的意思是,不是在“他”和“单身汉”之间连一个标签为ISA的飞线(裸关系),而是把二者都作为输入(一个实例、一个类型),连到一个“属于判断”节点的实例。语义解析不只是判断相谐性,还要构造一系列实例。
有两个“属于判断”事件。二者都是实例,一个指向“单身汉”,另一个排除指向“单身汉”。二者的时间标签不同。第二个事件“刷新”逻辑主语在实体知识库中的婚姻状况属性,但事件本身是log,当我们需要replay或者进行时序有关的查询时,就必须借助之。
李:对,“构造实例”本来就是“信息抽取”的核心目标。语言解析是支持信息抽取的。
张三:前-单身汉;现-已婚。
假设 已婚 == !单身汉(在西方不成立:在美国填有些表可复杂呢:在个人关系栏目里面有一长列关系:同居、异性婚、同性婚、变性婚、单身、丧偶 ........)
实体知识图谱“通常”不收入“非”:排除单身汉的常规不收,除非换个特征名/维度(譬如:从“单身汉”换成“已婚”)。因为定义一个实体,定义是什么,比定义不是什么,边界清晰多了。
白:这个观点,和人机对话系统不支持回答否定句的那件事,互相锁定了现状。
李:回到前面的问题:“属性类型” 说的就是 ISA 元关系吗?
白:属性类型之间可以存在ISA元关系,但那不是给“构建实例节点及其相关的边”用的。
李:的确如此。当然不是“构建实例节点”。本体里面,by definition,根本就没有“实例”。实例是实体知识的范畴。本体里面说的关系,大多是“潜在”的关系。悬在空中没有落地的那种,才叫本体。这是人类把握世界,人脑给世界分类的概念化结果。
关于本体和实体,最有意思的例子可以追溯到“白马非马”论。这个悖论(?)中,“白马” 在理解中是落地到实体的(就是那个说话者和听话者你知我知的那匹白马);第二个 “马” 则是没落地的本体(概念/类型)。对于朴素唯物主义者来说,任何表达或判断,都必须“唯物”,不落地就无从辨真伪,辨别不了真伪的东西,一律不承认,因此 “(此)白马非(类型)马”。这是把元关系 ISA 也从 ontology 拉出来,非要让它落地。也不能怪他,本来这种关系就是内在的(存在人类共同体的脑瓜中,或集体记忆中),可以认为是一种给定的无需证明的公理,是你知我知的“真理”。把没有信息量的“公理”表述出来,哲学家可以借此反思本体论的形而上特性,表现朴素唯物论的反智。如果我们把“知识”默认为实体的种种(知识就是了解世界发生了什么),“元知识”的本来意义就是悬在空中,没有落地(到实体)的意思。
白:我们在本体里就区分元知识和潜在知识。潜在的关系也不是元关系,比如比较大小:
<quantity>大于<quantity>
语义解析不构造元关系的实例,但会构造潜在关系(我们叫关系类型)的实例。
李:不太明白。数量可以比较大小,这不就是元知识、元关系吗?到了实例,就是:
pi > 3 : TRUE
pi > 4: FALSE
这就落地了,成为实体知识(实际上是数学常识)。
白:大于,是关系类型,不是元关系。元关系是我们推理用的,不是理解用的。元关系永远留在本体里,关系类型可以实例化。
李:有点晕了,主要是术语概念先要有个统一的定义。“潜在关系(我们叫关系类型)”,举个例子。
白:刚才说的“大于”就是啊。大于是关系类型。
李:“构造潜在关系(我们叫关系类型)的实例”,上面的 pi > 3 就是。ISA 不也是关系类型?
白:ISA不是。关系类型用节点实现,不用边实现。节点带论元,也就是态射。节点还带属性。关系类型节点可以带时态属性。
李:“节点” 就是 “词/概念”。节点带论元的典型例子是谓词。
白:纯粹的边不带属性。大于,就是谓词。大于,不处理成纯粹的边;ISA,处理成纯粹的边。ISA没必要带时态属性。
李:这是本体的 ISA,确实谈不上时态,是超时间的,恒真。因为概念世界就是这么定义和抽象的。
实体的 ISA 是有时间变化的:人曾经是猴子,很多年以后,人成为政治动物。
白:属于判断,是另外的事情。我们不用跟ISA混淆的表示,而且必须用带论元的节点表示。
李:对,实体判断的 ISA 与本体内部的 ISA 不是一回事。
白:这也不算是实体,只是可落地为实体而已。“人曾经是猴子”。这个“人”,用的既不是全称量词,也不是存在量词。是那个时候活着的人全体。
李:上面的“人”(人类)感觉是“半实体”。显然早已不是纯粹的本体了。
白:不是本体。是“实例化+泛化”。
李:嗯。
<quantity>大于<quantity> 如何在 ontology 里面体现?有什么用处?<quantity> 是一个节点(类型/概念)。
白:两个quantity是输入节点。“大于”是输出节点。它的类型继承路径可以一路走到event/static/boolean……。event再往上,就是thing(root)了。
要说用处,自然是为实例化提供了模板,同时也为相谐性检验提供了门神。一个向左一个向右。
李:就是说,看到 “5 大于 3” 甚至 “3 大于 5” 这样的说法,本体知识“门神”说,对,类型靠谱。看到 “品性大于知识” 的说法,本体知识说:类型不符合,可能是引申或比喻。如果这就是“用处”的话,不能说没用。但也说不出对语言理解有啥真用。
<quantity>大于<quantity> 在以前的谓词句型词典里面是这样的:
大于:Subject:CD;Object:CD
这是所谓 SUBCAT 句型对潜在填坑的萝卜做了限定:是期望一个数词。它与其他及物动词的 SUBCAT 标注是一致的,如:
EAT:Subject:Animate;Object:Edible
白:“5大于这三个数的平均数”
对parsing的作用是逆向选择,对语义解析的作用是顺向构建。
李:我好奇 "<quantity>大于<quantity>" 与 "大于:Subject:CD;Object:CD" 有什么区别?提供了哪些额外的价值?
“平均数” 虽然不是 CD, 但它是可以兼容的类型 (CD 的本体类型)。这就好像要求【human】,不仅仅实体 “张三” 合格(合乎预期类型), “演员” 也合格。
白:“平均数”也是一个态射,输入类型是quantity的集合,输出类型是quantity。这就实现了符合相谐性的“组装”。
李:对,“平均数” 也是某种 谓词:
平均数:【Arg1:CD】【Arg2:CD】 (......[Argn:CD])
如果用传统 SUBCAT 标注的话,大体如上:它期望至少两个数作为输入。还是不大清楚这种知识在实际语言解析和落地中的价值。有了 SUBCAT,解析感觉就够了。除了要做逻辑推理,譬如,验证某三个数的平均数是不是像语言表述中的那样,是真的还是错的?(这在文档核对、质检的场景似乎有用。)
白:针对类型的检查和针对值的推理/计算不是一回事。关键是,延展到领域知识,只需要做加法,不需要改动顶层设计。通用语义知识和领域知识可以无缝衔接。解析的输出物是自带螺钉螺母并经过装配的义素。领域知识中的实体和事件,也是如此这般地装配,没有其他。
李:“元关系永远留在本体里,关系类型可以实例化。” 这句话好,把 ontology 中两种关系区分开了。
“解析的输出物是自带螺钉螺母并经过装配的义素。” 这就是语言学中的 semantic compositionality。就是把珍珠串成项链。
白:朝着“构成”这个方向看去,应用潜力巨大无比。
李:潜在知识就是为落地的。元知识不需要落地,因为它本来就是从无数历史实例中抽象出来的“真理”。潜在知识虽然也是从历史实例中抽象出来的(“趋势”),但不是恒定的“永真”。“构成”/“组装” 就是 "compositionality",这是语义学中的最核心的概念了。
白:但是它可以一定程度上超脱于“语”。
李:“类型(type)” 就是超越 “语(词)”,是“概”念之间的东西。所谓本体是“元”知识,也就是说的这种超越,不仅仅超越“语”(这种表达体系),而且超越“实体”(客观世界),构成的是概念世界,是人这种物种所特有的范畴。当然,概念世界是从客观世界抽象来的,不是凭空来的。这些应该算哲学了。
白:不仅如此。语言表述可能比较细粒度,有情报价值或其他应用价值的事件粒度更粗,由細到粗,事件长的样子没变,但是已经脱离了字面意义的解释,进入事件驱动的推理、模拟、重演甚至数字孪生了。一个公司的几项人事变动后面隐藏着的粗粒度事件,可能是清洗。财务指标变动的后面是啥,也都有主儿。
李:有意思。这是从碎片化信息 event instances 推导其背后的情报。不过这种推导、预测或形势判断,开始进入“雷区”。就好比前几天我的公司让我重发当年对特朗普的大数据分析预测(《弘·扬 | 首席科学家李维科普:大数据告诉我们,特朗普如何击败希拉里》),我说,不要提“预测”,那是雷区:
把:“预测了特朗普的胜选” 改为 “大选前夕及时提出警示,各种自动数据分析表明,希拉里选情告急,特朗普胜算大增”。留点余地。当时的确是胶着,任何预测都冒风险。但选情变化之快,没有大数据,很难及时提出预警。主流民调就没有来得及预警,因为他们被信息压倒了。
白:我们的核心思想是,语言解析得到细粒度的事件,细粒度的事件imply粗粒度的事件,粗粒度的事件驱动其他粗粒度的事件或与之互动。对错另说,但事件长什么样不用另起炉灶了。如果粗粒度的事件完全是另一套,两张皮,就是NLP的失败。
李:两张皮怎么讲?以前的NLP怎么到了应用就两张皮了?
白:比如游戏,对命令的解析结果是一种数据结构,执行命令的战争进程是另一种数据结构,这就是两张皮。
李:不懂游戏。不过如果是两种数据结构,应该是一种映射到另一种。这也是常见的做法。譬如我们的 parsing 就是先造树结构,然后映射到图结构。以前也做过直接的图结构,不建树。这么多年实践下来,还是觉得建个树作为桥梁,感觉系统更加模块化,也更加方便。树虽然表达力不够,但作为桥梁是有便利之处的。过河拆桥,树在深度解析中最后基本是废弃了。
白:在金融领域也是这样。如果领域专家理解的事件、事件驱动,跟语言解析得到的事件、事件驱动,有很大的鸿沟,就没法玩了。一定有一个东西是统一的,而且是直接跨过去的。装配可不局限于树。在语义层面,树是没道理的。
李:顺便一提,图有种种好处,但是图规则不直观,难以理解,维护和调试都有挑战。这是因为图增加了维度,丧失或忽略了线性特点,结果就是面对一个图模式(graph pattern),在头脑里需要首先形成一种多维度的“图形”(picture),才感觉直观,才理解在节点之间穿行的模式,到底是干什么的。
本来我曾想尽量把更多的工作从句法树层次转移到语义图层次来做,感觉更加合理,但几年下来发现,句法是精简了,漂亮了,但语义这块越来越看不懂了。可是句法的东西即便是N年前做的,却一看就懂。接地气,容易维护。
再提一点:句法树 --》语义图 --〉实体知识图,这个 pipeline 的确有一个理由在:有情报价值的实体知识图谱与语义图是“同质”的,与句法“树”是不同质的。因此经过语义模块以后再做抽取,显得更加合理,很多时候所谓落地实用不过就是把图里面的“边”改个名称而已(甚至可以让用户配置)。譬如。针对 HIRE 这样的谓词,把 “S”(逻辑主语)这个边改为 【雇佣者】,“O” 改为【受雇者】,这就完成了“雇佣/HIRE” 这个 event 的抽取(逻辑语义图到事件图的映射)。这个事件的其他特征,譬如时间、地点、条件 等情报,常常可以照搬过来,连改都不用改(改就是映射),直接从图上继承下来即可。这里描述的语言技术的实践,感觉是呼应了白老师说的“无缝连接”。而共同体使用的宾州树(Penn Tree)结构,就很难做到“无缝连接”,由于表示体系的“鸿沟”。
还是回到 ontology 来。
白:前面说的“张三的小说没有散文写得好”,其实有两个“写”事件的实例,逻辑主语都是张三,逻辑宾语一个是小说,一个是散文,两个事件都通过“副作用”把自身的输出类型藏起来,而让各自的逻辑宾语带着其输入类型进入“好”获得quantity类型,再把两个quantity送进“大于”事件。
李:这个非常有意思。哦,“大于”事件不仅局限于数量,也可以是其他度量比较(包括质量)。
白:
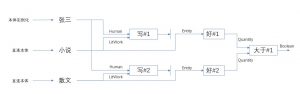
这个图大概就是装配的结果。“没有”还有一层否定,在Boolean的右面。“没有”还有一层否定,在Boolean的右面。或者其实应该使用“小于”关系。主要以此说明义素装配出来长啥样。没有装配就没有语义理解。
李:虽然大作最后一段文字也不长,开始感觉是,每个字都认得,每句话都不大认得,LOL:
5、元关系·关系类型·裸关系
在事件的表示中,我们使用了态射。事件有多种类型,其中有一种就是静态事件,它又細分为属性类型和关系-判断类型。这里的“关系-判断”类型的输出是“布尔”即逻辑真值。因此,它构成集合论和数理逻辑含义下的“关系”。这种语义知识体系内部的“关系”和IS-A这样的“元关系”是什么“关系”呢?它们和作为落地实现工具的知识图谱里的“关系”又是什么“关系”呢?我们看到一些语义知识表示框架的相关文献在这个问题上有些含糊。在这里,我们要做一些基本的约定。
把语义表示单元(类型)作为研究对象,探讨它们之间的“关系”,这是元关系。
作为语义表示单元(事件)之一个细分类别的“关系”,这是关系类型。跟元关系不是一回事。“部件(PartOf)”关系就是一种关系类型,而不是元关系。
在知识图谱体系内,无论是元关系,还是关系类型,都可以用知识图谱显性定义的“二元关系”来实现。我们把知识图谱里显性定义的二元关系称为“裸关系”,并约定,元关系在知识图谱里一律直接实现为裸关系,关系类型在知识图谱里一律间接实现为事件节点,哪怕关系类型就是二元关系,也必须通过事件节点来实现。具体来说就是:设事件A有n个输入类型一个输出类型,那么事件A就必须拆分成n个裸关系,其中每一个裸关系的开始节点都是这个事件节点本身,目标节点则是对应的输入类型节点,而边上的标记就是角色名,包含角色名由粗到細、由抽象到具体的整个继承路径。
这样做的好处,就是对元关系和关系类型做出严格区分,既避免了因开发团队个人理解的差异而将本体定义引向歧途,又给类型作为统一的语义知识表示对象留出统一的数据结构模型,便于定义方式的整体把握。举一个明显的例子,无论实体类型还是事件类型,其特征K-V对都是定义在自身节点上的,不会因为事件类型恰巧是二元关系就把它实现为裸关系,因为把一些类型对应的特征K-V对加载到节点上、把另一些类型对应的特征K-V对加载到裸关系上,不仅架构上是很不协调的,而且也给实现带来不必要的难度。
白:这一段憋了我不少天呢。
李:就像吕叔湘先生批评乔姆斯基一样,说他什么都好,就是说话艰涩,不懂得科普。白老师也可能有同样的问题。不知道,这段话有多少人能看明白。当然,肯定比爱因斯坦的相对论要强,据说很长时间,全世界只有三个半人看得懂相对论。
白:这个系列,不是严肃的学术论文,更像是整理阶段性思路的随笔。至于科普写作,还早着呢。
李:不拘一格。没必要用学术论文的那种格式。探寻语义结构和理解认知的奥秘,也是AI的前沿了。无论主流的热潮怎么走来走去。
关于这一小节的最后,你说:
"举一个明显的例子,无论实体类型还是事件类型,其特征K-V对都是定义在自身节点上的,不会因为事件类型恰巧是二元关系就把它实现为裸关系,因为把一些类型对应的特征K-V对加载到节点上、把另一些类型对应的特征K-V对加载到裸关系上,不仅架构上是很不协调的,而且也给实现带来不必要的难度。"
我的问题是:“事件类型恰巧是二元关系就把它实现为裸关系” 这种做法不大可能在 ontology 里面的呀,譬如 HowNet,所有的潜在关系的预示全部是以节点为单位的。我的理解是,只有到了实体知识图谱,才会有实现为裸关系的“边”来表示的(当然也可以不用裸关系来表示)。
白:不限制,就有可能。所以作为一条铁的纪律。
李:顺便提一句:白老师所谓 “特征 K-V 对”,在HPSG这类 constraint based formalisms 中叫做 AVM(Attribute-Value Mattrix)。而且这些 formalisms 中的 AVM 是严格的 typed AVM(typed data structure),每一个AVM图示为一个框,type作为框的下标。AVM 中的 V 可以是原子,也可以是另一个 typed AVM。从表示形式的统一性、操作的单一性(合一)以及逻辑严谨性和丰富性来看,这种formalism 是非常令人印象深刻的。
白:借助数据结构的type和本体的type是一回事?我表示谨慎怀疑。
李:这类系统的根本缺陷不仅仅是繁复,还有就是unification(合一)无法应对“顺杆儿爬”。另一个就是这种formalism提供了使用者相当程度的任意性,你可以把任何一个子结构(sub AVM)用 合一(实现的时候叫 structure sharing,实际上就是子图匹配和融合)的手段,放到任何一个 Attribute 里面去。
白:顺杆儿爬是句法适应语义。到了语义哪有顺杆儿爬,都是严格的类型检查。该脑补的都得在前面做掉。
李:“该脑补的都得在前面做掉。” 这个可以商榷。更多也更便利的做法是,脑补留到最后。
白:比如,“张三的小说没有(张三的)散文写得好。” 那个括号里面的东东就是顺杆儿爬出来的。到了语义层面,另一条边就得乖乖地画出来。句法的最后,相对于语义仍然是“前”。最多是内部名字有了,挂什么外部名字留到最后。但是内部名字跟事件的连线,必须有。而且必须符合类型约束。
李:严格的类型检查是一面,检查的另一面是,根据犯规的程度,来决定如何松绑或输出另外的解读或者输出 nonsense 的判断。
关于连线(linking),觉得也可以反过来想。在一个局部环境里(local context,say 5-gram),把默认的不连线,因此必须“做功”(句法解析)才能连线,改为默认就连线,因此找一些条件去不断剪枝。当然这蕴含着组合爆炸。但爆炸不爆炸是随着计算条件的不同,而有不同的抗压力的。如果反过来思维,上面的办法就是把句法、语义和语用等等的约束,全部统一看成是“剪枝”的过程。这个思路我感觉有突破性的潜力。因为实际上所谓的 compoasitionality 其实根本不需要真地去组装每一个原子(义原)部件,而是可以组装“预制件”。local context 都连然后通过词典或其他模块去剪枝,就与预制件的思想比较一致了。
白:这就是我说的统一优先级啊。语义、情感、事理、大数据,都可以给优先级加分或者减分。最后还是调整后的优先级说了算。不调整就相当于按句法default装配。
李:统一优先级的最大问题在怎么统一?
白:回到机器学习啊。加分减分不就是一个待定的参数么。神经做这个最擅长了。
李:这是机器学习里面说的 heterogeneous evidence 如何对付的老问题,这个挑战,学习里面一直困扰了好多年,到深度学习以后也不能说就解决了。譬如特斯拉内部人员透漏的最大难点也是在这上面,说上百个模型弄出那么多东西出来。最后的输出就是 x(速度)和y(方向)两个赋值。面对那么庞大的输入参数,和这么小的输出,老是在 “杂乱的(heterogeneous)” 输入因素之间摆不平。自动驾驶的质量控制因此成为一个非常大的挑战。一不小心就有了 regressions:明明上一个版本在一个急转弯控制得很好,版本更新后,突然就失控了。这种事情,很多用户有反馈。
他们现在还是学 Lidar(激光雷达),把各种 cameras 的感知数据,先整合成统一的三维模型,然后去 feed 给系统。这样来减少“杂乱度”,说这种模拟激光雷达的软件模型解决办法,比以前的系统,好多了。
白:对于NLP错误结果不会那么致命,就是正确的解析早几个回合出来还是晚几个回合出来的事儿
李:谢谢 @白硕 老师,大作的最后一段总算看得有些明白了,一开始觉得是天书。期待语义系列的下一篇。
【相关】
【弘·扬 | 首席科学家李维科普:大数据告诉我们,特朗普如何击败希拉里】