白:
定义subcat很有讲究的,后面有强大的数学。什么类型填什么类型的坑,结果是什么类型,数学早给我们准备好工具了。不知道这种数学,只能“自发”地做。知道了,就有条件“自觉”地做。type theory,带类型的lambda演算,早就给我们准备好了工具。为什么说小词也可以负载结构,原理是同样的。不是心血来潮,不是头疼医头,不是工程上的取巧,是有数学支持的。
李:
以前流行的那些 unification grammars or constraint based grammars 都是建立在 typed feature structures 之上的: CFG GPSG HPSG. 对于 type hierarchy and it's inheritance, 对于 attribute value 的 type appropriateness 都有说法, Typed feature structure 是这些文法的形式化基础。不知道这是不是就是所指的背后的数学或逻辑。
白:
type化最彻底的就是categoral grammar,但是CG最大的问题就是不实用。我已经把CG改造成了非常实用的程度,但是底子还是CG的底子。十多年前,我的学生@赵章界 (也在本群)的博士论文已经对中心词的继承特性在CG当中的形式化机制做了刻画。我最近的工作,进一步把这种继承性和修饰关系做了无缝对接。
李:
CG 没钻研过。其他那些文法的 typed feature structure 主要就是一种表达语言信息的数据结构,与软件工程里面 object-oriented class hierarchy 有很多相通之处。涉及到“演算”的似乎主要在表达语义的那部分feature structure (SEM)。自然语言的语义有一个总的原则是composionality, 就是用有限的语言材料(词,成语)组合成无限的句义。于是当一个单位与另一个单位在parsing中结合的时候,就有个怎样从简单的词义一步步“演算”成短语和句子语义来的课题。但这个演算过程,也带有浓厚的自己跟自己玩逻辑的成分。那些精心构造出来的句子的“语义”表达,显得繁琐、繁复,逻辑上好看,但实际语义落地其实并不一定需要这种。
白:
一眼看现状不中用就扔掉是一种策略。把它改造成中用是另一种策略。
李:
在feature structure unification based的系统中,这种演算就是通过structure sharing 让信息在feature结构中跳来跳去。跟玩游戏似的。如果某个语义在SEM整体的表达中没安排妥帖,或者缺乏合适的地方去表示,就挖尽心思改造那个 SEM structure,结果弄得越来越烦琐哲学。眉毛胡子一把抓,为语义而语义,忘记了语义落地的初衷。玩过一遍这类游戏以后,就开始删繁就简。
白:
化腐朽为神奇,有窍门的。单子化(singleton)是关键。废弃多层结构,把萝卜和坑摆到同一个桌面上。世界顿时清明。这里面藏着一个大秘密。
李:
你这也是删繁就简。那些复杂feature结构,都是那么的侯门深似海。错综复杂,各种嵌套,逻辑上能讲出很多道道来。
白:
但是singleton这是一个最有意思的子集。逻辑上一样有道理。只不过躲开了复杂结构而已。但那些复杂结构本来就是添乱的。本质上有用的,singleton足够了。
李:
同意应躲过复杂结构。我的系统是基于 atomic features 的。
白:
在毛毛虫假设下,singleton is enough,所以,叠床架屋的结构已经事实上废掉,但数学上仍是严谨的。去掉其他冗余,只剩下唯一一种可以还原为singleton的结构。这是毛毛虫的最大贡献。所以我面对的不是通用的CG,不是通用的复杂特征集,而是专为毛毛虫准备的singleton类型演算。好像人类的语言从遗传上就是只为singleton准备的。换了任意定义的一个CFG,还不一定能占到这个便宜呢。
singleton就是萝卜和坑只有一层,不嵌套。所有嵌套都可以简化为修饰和合并。修饰是继承的简化形式,合并是括号下分配律的简化形式。还原了都是填坑。本质上只有填坑一种运算。但是通过用修饰和合并来重写(rewrite)某些填坑,整个体系就完全扁平化了。这个工作,写论文也是拿得出手的,不过我目前还真顾不上。
李:
白老师有时间举几个例子就好了,说明怎么扁平化。
白:
李:
怎么讲?
白:
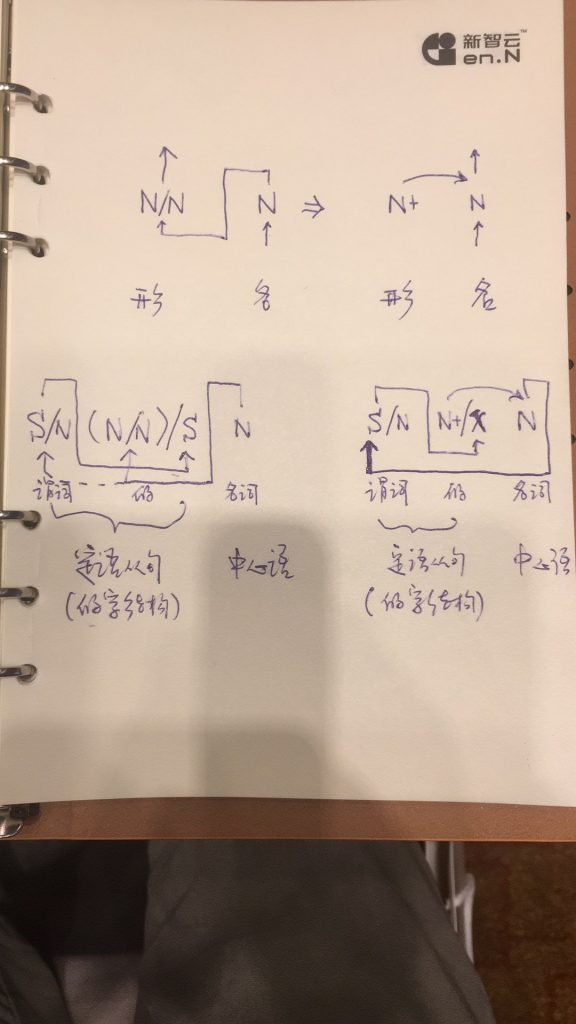
左面是CG,右面是我的简化
李:
上面是:形+名。逻辑上,形是谓词,名填坑:beautiful(girl)。结构上,形在前,修饰名。形被名吃掉:[(beautiful) girl]。
白:
在CG,是 名 被 形 吃掉,再吐出一个 名。在坑论,是 名 吸收掉 形。
关键是输出的路径,一个在形,一个在名。
李:
名是head。逻辑上,名被形吃掉没有问题。但是结构上的head怎么办呢?吐出一个名不能解决head的问题,因为head涉及的不仅仅是POS,而是一套 head features(包括本体及其taxonomy)以及head token,包括词形。
beautiful girl == girl (who is) beautiful
白:
当初为了解决这个矛盾,设计了CG输入输出之间的绑定机制,但是仍然不够直接。
李:
修饰与填坑的关系不是在一个平面。
白:
现在的表示最直接:修饰是填坑+绑定的简化。简化以后,就都变成singleton了,俗称“捋直了”,
李:
修饰是句法关系(是反映结构上的主与次),而填坑是逻辑关系,反映的是谓词与arg?左边CG的表达,没看明白。右边倒是显得简单了:作为 singleton , N+ 就是一个 atomic POS,等价于JJ,他右边遇到N(就是POS NN),就被吃掉。JJ被NN吃掉,算是绑定?那NN填JJ的坑,表现在哪里呢?
白:
已经重定向了。JJ可以认为没有坑了。
李:
这种逻辑关系与结构关系在语义表达上的纠缠,在ING词表现更明显:
ING做修饰语的时候,譬如 running dog,一方面是一个被吃掉的可有可无的修饰语,另一方面 running 作为逻辑谓词,需要一个逻辑主语来填坑。结构上的 head 这时候屈尊成了填坑的萝卜(arg)。
白:
了,也是一样。逻辑上,了 是(S/N)/(S/N),但我们把它简化成+S
李:
+S 就是吃一个S 吐一个S?
吃一个 Aspect unspecified S,吐一个 Aspect=Perfect的S。
白:
@wei 然
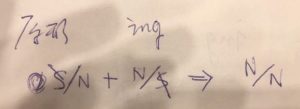
刚才ing,如图:两个S消掉了,剩下两个N。在汉语里,如同“这本书的出版”。
李:
ing怎么就成了 N/S
可以把词尾看成小词,所谓小词负载结构。
白硕:
上图是CG:吃一个S,吐一个N。我现在的做法见下图:
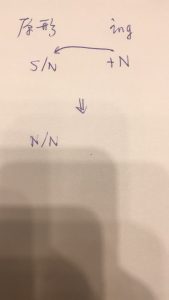
+N结构强制分子上的S到N,分母上的N不变。填动词的坑变为填名词的坑了,因为被修饰语被修饰语强制了。
李:
N/N不就是 N+吗?N+ == JJ
白:
不是。二者不等价。这是一个真的坑,没有绑定机制。
这本书的出版,输出的是出版,不是这本书
李:
这本书 结构上是可有可无的修饰语,“的”来引导,逻辑上是arg,这双重身份(mod and arg),赶巧挂靠的都是相同的老子。“出版”的arg(宾语)是“这本书”;“出版”的mod也是“这本书”。比较:“这本书的出版” vs “出版的这本书”。
白:
我在说英语的ing,谈到“的”只是类比。英语的ing,从右侧修饰动词原形,把动词强制为名词,把动词带的坑也强制转为名词带的坑:their publishing the book
李:
这个CG好玩,吃啊吐啊的,当年怎么没注意它。
白:
没有绑定机制的CG,语言学意义是有限的,更像是数学而不像语言学。我的学生@赵章界 引入绑定机制后,才像语言学了。但是赵的工作许多人没有注意到它的核心价值。
李:
当年看过一点那啥 蒙氏文法,形式语义,这个演算那个演算的,被绕糊涂了。没看懂。
白:
Montago
李:
对,里面有Lambda演算啥的,对我太抽象了。记得Montago看不懂,就找中文的来看。原文看不懂的,中文就更看不懂了。就拉倒了。
什么叫绑定机制?
白:
就是吃的和吐的,具有同一性。如果将来吐的参与任何操作,都要把吃的带上。吃的所携带的任何语义特征,也都被传导给吐的。绑定机制基本就是这个意思。
李:
这个听上去就是HFP(Head Feature Principle)。大白话就是一个短语,头词是其代表,头词决定一切。坚持党的一元化领导不动摇。真正实现的时候,根本就不需要像HPSG那种,把 features 定义到嵌套的HEAD结构去,然后上下传来传去的。麻烦。还是我导师刘老师简单直接,head就是直接把修饰语吃掉,是真地吃掉了,看不见了。这么一来信息,就无需传送了。
白:
但是用原教旨的CG,即使引进了绑定机制,仍然是叠床架屋。我现在的方案就极为简单了,就是吃掉。但是理论上它是CG的简化形式。CG的所有严谨性都包含在里面。但是省去了传递。
李:
那些叠床架屋,主要是为了鸡零狗碎的一些边边角角的所谓 non-head features,为此不得不把 HEAD features 嵌套起来。真是为了芝麻,挤压了西瓜。
白:
叠床架屋的缺点去掉,优点保留。毛毛虫的毛刺。很多可以通过中间件摆平,就不需要这些边边角角了。
李:
这个中间件相谐,的确是个好东西。动态隐含地引进了常识,却没有了常识管理的负担。这是亮点和创新。以前的优选语义学(Preference Semantics)一直就困扰在尺寸无法掌握,现在用大数据解决了这个困扰。
白:
而且中间件只管二元关系,不需要涉及复杂结构。所有复杂结构都被singleton填坑化解了。只剩下扁平的二元关系。
李:
常识的基础形式就是二元的,即便牵连到多元,也可以用多个二元来近似:【animate】吃【food】,这个三元常识,不就是两个二元关系吗。
白:
用我的话说,就是“吃”挖了两个坑。两个坑和萝卜摆在一个货架上。这就是singleton。
李:
蛮好。
当然二元近似可能不完全等同它,但实践中的些微偏差,从效果上看,已经可忽略不计了。
白:
所以,我的方法,贯穿着CG的原理,但外部表现很像DG。在对小词的处理上比DG更为彻底,所有小词都纳入二元关系。而二元关系的背后有类型演算的数学作为基础。绝不是随意的或者为了工程而武断设定的。
李:
其实我们的做法和策略,有很多殊途同归的地方。不是高攀。都是各自思索多年,不约而同的决定舍弃什么,采纳什么。我现在缺的是大数据中间件,你那边还是单层,当然,你在单层里面加了优先啥的,近似了多层。
白:
有算符优先,单层也相当于多层
李:
但我还是觉得单层伸展不开,有点凑合事儿的味道。多层符合软件工程的标准做法,模块化。真正是把语言学当工程去做。
白:
但是如果引入kick of,单层+优先更轻便。
李:
对于复杂结构的舍弃或扬弃,我们思路是一致的:atomic features or singlton
当然严格说,singlton的subcat标注,比起复杂特征的SUBCAT 的精细描述以及里面体现的句法语义一体化,也显得有些伸展不开。但问题不大了,得大于失。
白:
语义那边自有知识图谱来承担更加复杂结构的表示。对接的途径都在,不会跑到途径外面去。句法的目标极为有限。伸展得开与否,要相对于这个有限目标来评估。不存在绝对的标准。这无非是二楼和三楼的分工问题。
李:
还有一点风格上的差异或美感因素在。
据说写 Unix 的人与写 Windows 的人,是两种人。互相看不上。后者嫌前者小家子气,前者不能忍受后者的挥霍。
白:
都很伟大。
【相关】