李:
“难得他认可啊。” 歧义句。有点类似于 、但也不同于“难过” 的歧义:
(1)他认可,难得啊(已然);(2)得他认可,难啊(未然)。
前者可以骄傲,是正面信息;后者是负面的畏难情绪,不自信,或的确客观上难以达到。
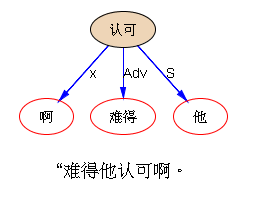
parse 的是 (1),如果想要(2),还是循“难过”的先例,去在语用层做休眠唤醒吧: “难过”(“小河很难过”)见 【立委科普:歧义parsing的休眠唤醒机制再探】
董:
我以前讲过,在实际语言交流中,人与人之间几乎没有歧义。如果真像nlp一步一个歧义,那还得了。类似范冰冰奶奶、咬死猎人的狗之类的句子是语言学家消遣自己的。上帝是为人准备的语言,不是为机器的。
白:
nlp大多数歧义是伪歧义。问题是,这些伪歧义,对人来说,是在哪个环节被干掉的。只要分析器在按照语言学家的思路做,语言学家消遣自己的把戏,就总有一天会消遣到机器的头上来。
雪:
common sense环节?人自身对于整个世界的建模
李:
CFG based parser,哪怕是 lexicalist 的语法 如HPSH,也有很多伪歧义 parses,可是多层的 parsers 就很少受到这个困扰。这个事实显而易见。可见 common sense 不该是 key,因为 多层系统里面 common sense 即便利用,也是零星带入的 不是主力。
我做博士的时候,导师的实验室里面有一个英语的 HPSG parser,parses 输出如此之多,如此地不能辨别真假,以至于最后在使用这个parser做MT实验的时候,我们不得不只选取第一个 parse,等价于随机选择。
层层递进的多层 parsing 虽然会偶然出现漏掉有效parses 的路径(过早删除),但比起其他 parser 的伪歧义成堆,还是境况好得多。此外,漏掉的有效 parses 在开发过程中,可以被重新补足,或被唤醒。
所以,白老师说 NLP大多数歧义是伪歧义,基本是针对单层搜索的 parsing 算法而言,而不是多层 cascaded parser 的真正缺陷。
梅:
可以说是“common sense”吧。人不是机器。
李:
一般来说,语言学的细线条知识 不划归 common sense 范畴。当然,细线条到一定程度,常识也就溜进来了,没有绝对界限。人类交流没有感觉到歧义,有几个原因:
(1)歧义休眠了,正常的场景不被唤醒,因此无感;
(2)有些歧义不影响大面的理解和主旨的交流,说的人也许本来自己就含混,听得人也没有理由去追究细节。保持某种语义模糊是人类交流相当常见的状态,但是一旦形式化,歧义就站在那里了,除非是做系统的人特地去把歧义中性化或模糊化。一个典型的 PP-attachment 的歧义是 for-PP,以前说过,在很多场合,这个 for-PP 做定语还是做状语,根本没啥大差别。
梅:
人要是想多了,说不定也有“歧义“,但人的“short term memory”是有limit的
李:
(3) 当然还有一部分所谓歧义是系统 “人造”的,本来无歧义,系统自扰之。譬如,在 HPSG 的数据结构 feature structure 的设计中,经常会出现这种歧义。由于过分强调 feature structure 的层次性、逻辑性和合一性,以至于当这个 structure 投入使用的时候,带来了大量的对于人没有区别意义,但对于结构具有区别的所谓歧义。这是与具体的系统formalism 的设计有关,是 system internal 的,与其他 formalism 无关,与人的理解无关,是模型化形式化过程中的产物。unification 是双刃剑,推向极端,系统就失之太过精巧,没有容错性。
刚才例行散步时仔细想了想了这个伪歧义的问题。为什么这么多 parsers,包括传统的 CFG-based 规则系统和统计训练出来的 parsers,陷入伪歧义的泥潭?
白:
没用盘外招呗
李:
得了 得了。我一肚子话还没说呢。白老师,I 服了 U!
白:
羊头+盘外招=狗肉
李:
白老师讽刺我是卖狗肉的
梅:
Spoken 和 written 应该有很多不同吧?@wei
李:
很多不同是对那些从 PennTree 训练出来的系统。对我们的系统,没有什么不同。spoken 的语言不太规范,transcribe 成 text 我一样 parse,质量会有降低,但那是与 spoken text 的随意性成比例的,绝对不会是直线下降。反过来,我以 degraded text 做我的数据制导,出来的系统一样对付正规文体。parse 新闻不会比专门从新闻训练出来的系统差。这是语言学家做系统的好处之一吧,我们是人,不是机器,不会被数据牵着鼻子亦步亦趋。
白:
光分层,不可能把伪歧义去的那么好。这里面太多只可意会 不可言传。有剪必有捡
李:
关于伪歧义,这么说吧:伪歧义太多是枝枝蔓蔓没有及时修剪的必然结果。理论上讲,修枝剪叶是危险的,实践中却不尽然。自然语言中的现象中有很多是相互依赖的,但也有很多现象是相互独立的。如果你设计的系统是以相互依赖作为基本的 assumption,祝贺你,你就跳进泥潭吧。跳吧,跳吧,不要往两边看。
如果你相信语言现象的 dependency 是有限的,可以调控的,即便剪错了也不是世界末日,你就可以在数据制导的开发环境里,逐渐把系统调适得恰到好处:该休眠的休眠,该保留的保留,该杀头的立即枪毙。你就不会为伪歧义所困扰。
白:
一个硬币的两面。靠剪对付标配,靠捡对付长尾。两手都要硬
李:
是的,可是怎么硬呢?硬必须要有语言学的sense,必须知道根据不同情况做不同的对待。缺乏语言学的人 把各种路径放在一个锅里炒,无论你有多大的数据,你也还是陷入泥潭。
雷:
@wei 不是秋后问斩,是斩立决
李:
白老师字字珠玑: 靠剪对付标配,靠捡对付长尾。
雷:
@wei 其实,即使没有歧义,语言理解也是如若有歧义,理解有多个
白:
把人际沟通中的各种暗示、言外之意都算进来,歧义不得了,但是核心的精神,剪与捡,是不变的。
雷:
每个人接受的模式决定了理解的样式
白:
比如站在严格逻辑的角度,从“该来的没来”,本不该推出“来的都是不该来的”;从“不该走的走了”,也不应推出“没走的是该走的”。但是人就是要听话听声。
李:
@雷,一码一码吧。语义落地到人或产品,那是 parsing 的后过程。
雷:
句法是语言学家的
李:
@白老师 盘外招 只可意会不可言传的 tricks 这些在学习系统中怎么去 model 呢?我怀疑学习算法不敌领域专家(对于 parsing 就是语言学家),根据的就是这个。我作为专家如果在迷宫里千辛万苦绕出来了,学习怎么恰好也能绕出来?
白:
@wei 同样的话,围棋高手们也问过。
李:
说的也是,围棋手也这么问过。不过,白老师其实只说了半句话。
白:
另半句,取决于学习模型长什么样。
李:
这个模型的定义至少不该排除领域专家的参与 无论以什么方式 除非设计者是个全才。
白:
标配是必然的,也不排除有个居高临下的模型,俯瞰N个领域,语言只是其中之一,但是人家从其他领域登顶了。就像控制论,把人、动物、机器里的反馈控制一网打尽了。生理学家、动物学家都买账的。尽管创始人是从机器出发登顶的
首发:【科学网:自动句法分析中的伪歧义泥潭】
【相关】
【立委科普:语言学算法是 deep NLP 绕不过去的坎儿】