Xi:
@wei , 评论一下李明教授的机器翻译。我纳闷这年头这么多人跨界来和你抢食啊?
我:
评论啥,我对MT无感了,都。
我现在是,胸怀知识图谱,放眼世界大同。早翻过MT那一页了。
不过话说回来,学自然语言的人如果入行做的就是规则机器翻译,那是上天的赐福。新一辈这种人没有了,所以很多入行多年的人,看到的语言世界,还是井底的一线天。
如果你在没有平台支持下被逼着去做机器翻译,你有福了。你必须从头开始做词典、做 tokenization,做 POS,做短语,做 SVO 句法,你还要做双语结构转换、WSD 词义消歧,最后还有目标语的生成,包括形态生成、调序,修辞上的一些 final touches。
总之 方方面面 你必须全部做到 如果没有平台 没有专用语言 像我们做硕士论文那样用 general purpose language (COBOL,ALGOL,BASIC,甚至汇编)做,那就是在太上老君八卦炉里炼 没得不炼成火眼金睛 后去做 NLP 任何一个方面和应用 都洞若观火。
现在的 CL 硕士博士呢 动不动就下载一个软件包,瞅准一个子任务 譬如切词,譬如 sentiment,譬如WSD,哪怕是做 MT, 也不用涉及那么多的层次和模块。
老老年文:【立委科普:机器翻译】 但并没完全失效。还有这篇:【立委随笔:机器翻译万岁】。
SMT 不用涉及那么多层次 是因为迄今的 SMT 基本是在浅层打转 从来就没有做到深层,论深度和结构 远远不及我们 30 年前做的 规则MT。
马:
但是比规则的系统实用啊
我:
河东河西啊。
如今董老师的系统等也打磨经年了,很难说谁更实用。论精度 则绝对是后者强,甩出一条街去。
smt 的先驱应该是 ibm ,从加拿大议会英法双语语料开始的。
Guo:
Translation memory 算什么?
我:
说起这个概念,我还有掌故呢。以前记过,差不多也成了 MT 野史或外传了,见《朝华午拾:欧洲之行》,Victor 称作为 translation unit (TU)。他们的所谓的 Chinese Week,当时董老师也去了,我和刘老师也去了。傅爱萍大姐派人领我们参观了红灯区以后,并没有随着我们去参加这个活动。这个活动的设立与我当年为他们做的“汉语依存文法”的工作密切相关。
QUOTE 研究组的骨干还有国际世界语协会的财务总监,知名英国籍世界语者 Victor Sadler 博士,我在71届国际世界语大会上跟他认识。作为高级研究员,他刚刚完成一项研究,利用 parsed (自动语法分析)过的双语对照的语料库(BKB, or Bilingual Knowledge Base)的统计信息,匹配大小各异的翻译单位(translation unit)进行自动翻译,这一项原创性研究比后来流行的同类研究早了5-10年。显然,大家都看好这一新的进展,作为重点向我们推介。整个访问的中心主题,仍然是解答他们关于汉语句法方面一些疑难问题。他们当时正在接洽欧洲和日本的可能的投资人,预备下一步大规模的商业开发,汉语作为不同语系的重要语言,其可行性研究对于寻找投资意义重大。
索性把怀旧进行到底 《朝华午拾:一夜成为万元户》: 这是我为这个DLT项目所做的 Chinese Dependency Grammar 的故事。这篇汉语形式文法的原始版本有链接可以下载:Li, W. 1989. “A Dependency Syntax of Contemporary Chinese”, BSO/DLT Research Report, the Netherlands. 我的工作应该是中国做依存关系最早最完整的作品了。所谓 【美梦成真】 就是这么个来历,跨越近 30 年,纸上谈兵的 syntax 终于化为现实的 deep parser。
刚才一边吃晚饭,一边琢磨这段MT外传,觉得还是有几点可以总结的,笔记如下,各位指正。
(1) 荷兰这个多语 MT 计划本来是规则系统起家,用世界语作为媒介语,用的是依存关系文法的框架,实现的机制是 ATN (Augmented Transition Network),技术领头是德国语言学家舒伯特。
(2) 可是做着做着,剑桥出身的 Victor 博士想出了统计的路线,定义了一个在句法分析基础上、根据统计和记忆决定的可大可小的 Translation Unit (有点像我们用的“句素”的概念),做了实验验证了这条路线的创新,把整个项目在收尾阶段翻了个个儿。而这时候(1989年),其他的MT研究虽然也有 IBM 等开始的统计 MT,但没有一个达到这样的深度。
(3)事实上,直到今天,回顾这个科研创新可以看出,根据 parsed 以后的双语数据库的平行对比,从统计去找 Translation Units,比起后来多数缺乏结构、本质上是 ngram 记忆的 SMT,还是远高出一筹。
(4)在 SMT 中加入 parsing 并不是每个人都有这个条件,DLT 赶巧是先做 parser 做了四五年,有了这个基础。现在和今后的方向从宏观上来看是,SMT 应该重温类似 BKB 双语parsed平行语料库的尝试,走带入结构的道路,才有希望克服现在显而易见的结构瓶颈,譬如定语从句翻译的错误。
mei:
语言学家做MT注重语言的结构,深的浅的。我是ai出生,注重“知识“,互相通融的,但侧重点有区别。
Guo:
一谈到统计和规则,总不免让人想起,库恩的科学革命的结构。根本说来,统计和规则,对于什么是nlp,是有完全不同的定义的。站在统计的角度,古埃及文的解读,作者和鹰品的辨识,错别字的检查和矫正,文章可读性的分类,还有很多很多这样的,都是历史悠久的成功故事。说历史悠久,是因为他们早于乔姆斯基太多年了。但是从规则的角度看,这些大概都不属于nlp。
我:
规则也并非一定要是句法的规则,任何 patterns 包括 ngrams 都可以是规则。学习派用的是 ngram 的分布统计,规则派很难量化这些 ngrams 的统计数据,只好把“gram”定义为从线性序列到句法单位的一个动态 unit,用结构化的深度 弥补统计性的不足。
Guo:
其实对于mt,统计这一派也更多的是从"机助"翻译甚至阅读来看问题。不管大佬们怎么吹牛,统计这一派从来不以理解人模仿人为目标。他们是非常工程性,实用主义的。
我:
当 gram 被定义为我导师刘倬老师所阐述过的“句素”以后,产生了两个飞跃:
第一是距离从线性走向平面,甚至远距离现象也可以被这种 “ngram” 抓住了: 这类例证我此前显示过很多。第二是 gram 本身从直接量 (literal) 提升为一个具有不同抽象度的 features 的语言学单位总和,连ontolgy亦可带入。这两个飞跃使得应对自然语言错综复杂的规则,变得切实可行。
smt 我们迄今看到的流行成熟的系统,譬如大投入造就的百度和谷歌MT,其缺乏结构和parsing支持的缺点是如此显然,结构瓶颈随处可见。可反过来看董老师在群里显示出来的传统规则+知识 的系统,结构的优势不言而喻。
也许从 scale up,从对付鸡零狗碎的成语性的 ngrams,董老师这类系统目前还无法匹敌百度谷歌 smt,但是假如以董老师系统为核心,给以同等的资源投入和维护,我觉得百度系统无法打得过规则 MT。当然 最佳的办法是二者的某种结合,取长补短。我想说的是,如果硬要硬碰硬的话,在同等投入的基础上,谁敢拍胸脯说主流 smt 一定会胜过规则 mt 呢?
现在是不平等比较,根本不是 apple to apple 较量。历史把 规则mt 推下了主流舞台,但是 smt 的人无论多么傲慢 也还是应该看得见自己的短板和规则mt的亮点。
Guo:
统计这一派,其实有很多人试图引入结构,但鲜有能够有效减少perplexity的。核心的争论,就是问题到底出在哪儿?一种观点是,结构,并不承载太多的附加信息。另一种就是,我们还没有发现更好的更有效的数学模型。这就是为什么,好些人对深度神经就像打了鸡血。
我:
heterogeneous features 引入后的 evidence overlapping 以及 perplexity 等,是研究课题,不过说结构不承载太多附加信息等价于说 ngram 线性的 model 无需改变,这个 model 在20多年中已经被推向了极致,没有多少油水了。白老师说话,model 不对,语言长得啥样框架上就没留下空间,再多的数据,再deep的学习,也是必然遭遇瓶颈的。
的确在某些粗线条任务中 譬如 document classification,一袋子词的ngram模型已经足以满足应用的需要,精度已经够高,结构即便加入也改进余地不大了:这不是我们需要讨论的。我们关注的都是那些显然遭遇瓶颈的任务,包括 MT、包括 IE、包括 Sentiment Analysis,这些任务,显然统计的路线在没有结构助力下,深入不下去。
到目前为止 纵然有一些带入结构的尝试,但很可能是浅尝辄止,还不到结论的时候。
深度神经是一种训练的算法,与语言的结构深度没有必然联系。事实上 迄今为止 对于 text NLP 的深度神经的尝试,除了专门做中间件 parsing 的 research 如 SyntaxtNet 外,对于 NLP 应用方面的任务,基本上还是在语言浅层进行。带入结构的深度神经用于 text NLP, 到底有几家在做?如果没做 或还没做出结果来 那么所谓 Deep Text 就是有意无意的误导(见 【遭遇脸书的 Deep Text】 )。
杨:
我理解:深度学习主要是可能在语意理解领域 可能会有所改变
我:
譬如?
哪些任务是深度神经擅长、文法工程短板的语义理解呢?
凡是条分缕析的细线条任务,想不出来深度学习可做,文法工程不可做的,无论语义如何落地。
杨:
比如文字到图像的映射搜索呢?我不懂,瞎说的。当然 这个目前远远不成熟 只是猜想
我:
这个还真是没想到,因为其中一端是 text (captions?),可另一端是 image,对于学习,无论神经的深浅,这个任务只要有大量的 data (带有 captions 的 图片集),就是一个很自然的学习的任务。而对于规则,这种形式化的语义落地(映射到图像)在图像那边如何处理并integrate 到规则系统中来对接,似乎没有显然而见的自然接口。
杨:
不过 图像这块就不够成熟 要做这个且早呢。
我:
好。短板不怕,只要心里有数就好。早就知道规则的“经典”短板了:
【手工规则系统的软肋在文章分类】 。
QUOTE 人脑(规则)可能顾不上这么多细微的证据及其权重,但是人脑往往可以根据不同状况抓住几条主线,然后在其中调控,达到解决问题。在 deep parsing 这个 NLP 的关键/核心领域,规则系统的优势更加明显。
再有就是搜索。关键词检索的鲁棒、对付长尾 query 的能力,是规则系统难以匹敌的。
但是如果把关键词搜索作为 backoff,那么加入结构的精准智能搜索(我们叫 SVO search)就顺理成章了。
【相关】
【立委科普:机器翻译】
【立委随笔:机器翻译万岁】
《朝华午拾:欧洲之行》
《朝华午拾:一夜成为万元户》
【美梦成真】
【手工规则系统的软肋在文章分类】
【遭遇脸书的 Deep Text】
Li, W. 1989. “A Dependency Syntax of Contemporary Chinese”, BSO/DLT Research Report, the Netherlands.
【置顶:立委科学网博客NLP博文一览(定期更新版)】
《朝华午拾》总目录








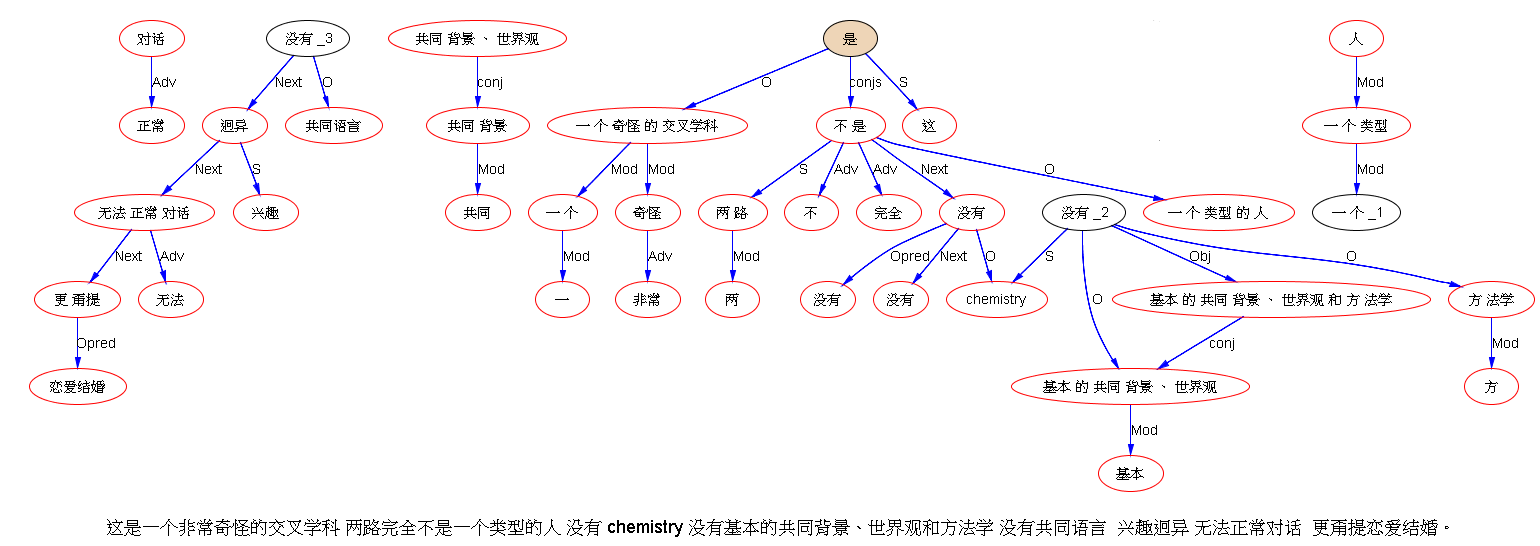
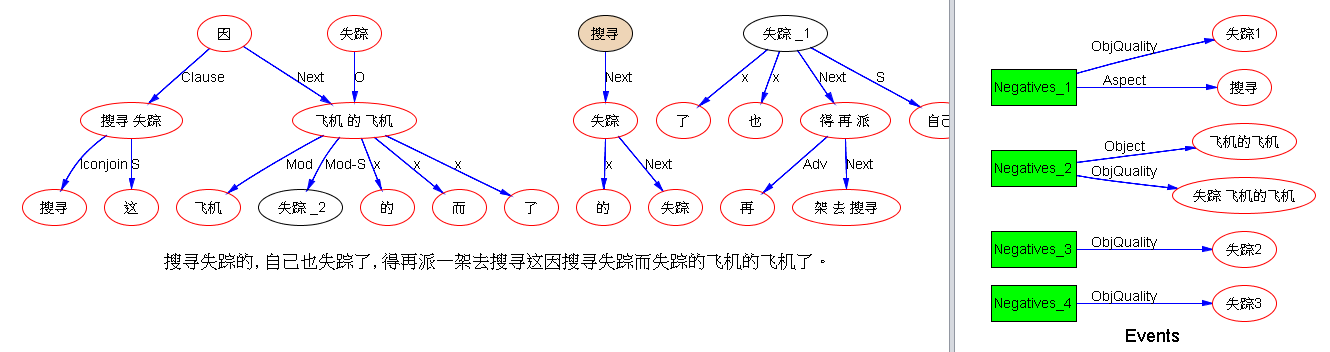
 下面是笔者对两条路线斗争的总结,也 parse parse see see 吧,QUOTE:
下面是笔者对两条路线斗争的总结,也 parse parse see see 吧,QUOTE: