Written for my linguistics and symbolic NLP peers — a reflection on my journey to leverage computational linguistics in undersranding modern AI LLM.
Breaking Through the Jargon Barrier
For linguists bewildered by large language models (LLMs), the confusion often stems from terminology and implementation details obscuring shared foundational principles. Let’s cut through the noise and focus on self-attention — the beating heart of the Transformer architecture.
As a computational linguist and lifelong NLP practitioner, I’ve spent years dissecting symbolic grammars and, more recently, tracking the rise of LLMs. Here’s my attempt to "translate" the core design of multi-head Query-Key-Value (QKV) mechanisms into a framework linguists already know.
QKV: A Linguistic Reinterpretation
Query as Subcategorization (Subcat)
First, I would like to point out, Query mirrors Subcat in symbolic grammar: the slots a head word "digs" for its dependents. Take a transitive verb (vt) as an example: it creates two syntactic "slots"—a noun subject (pre-verbal) and a noun object (post-verbal). Similarly, the predicate eat defines two semantic slots: an animate agent (e.g., animal) and an edible patient (e.g., food). These constraints — syntactic roles and semantic selection restrictions — are bread-and-butter concepts for linguists.
Key as Ontological Features
Key represents ontological attributes: nounhood, animacy, action, state, time, descriptive, etc. Value is the filler—the "carrot" that occupies a slot. When I first read Attention is all you need, the QKV triad felt alien. No one explained that this was just dynamic slot-filling.
Why LLMs "Get" Language
LLMs thrive because their "slots" and "fillers" align perfectly across linguistic hierarchies. Every token carries QKV information because every word can both be a seeker (Query) and a target (Key/Value). When a Query (e.g., eat) finds a compatible Key (e.g., apple), their dot product sparks a high attention weight. The Value (the token’s semantic essence) is then passed forward, blending into the next layer’s representation of the token.
Contextual "Polygamy"
Tokens in the context window engage in group marriage, not monogamy. Each token 'flirts' with all others via Query-Key dot products. Relationships vary in intensity (weights), and the resulting "offspring"—the next layer’s tokens—inherit traits from multiple "parents" through weighted summation. Stronger relationships dominate; weaker ones fade. This crazy yet efficient "breeding" compresses linguistic structure into dense vector spaces, a process conceptually equivalent to parsing, understanding, and generation in one unified mechanism.
The Database Analogy (and Why It 'Misled' Us)
QKV borrows terms from database systems (Query for search, Key-Value for retrieval), but early attempts to map this to linguistics fell flat. We thought: "Databases? That’s just dictionary lookups — isn't it already handled by embeddings?!" The breakthrough came when we realized: Self-attention isn’t static retrieval—it’s dynamic, context-aware slot-filling.
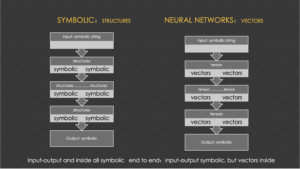
For decades, we built bottom-up parsers using Subcat frames. Transformer layers do the same, but with vectors instead of symbolic representaions. See the 2 slides I made 3+ years ago when GPT3 playground was launched when I compared the parallel archtectures and approaches from two schools of AI, grammar school and multi-neural network school. Symbolic grammars, though, despite their transparency, pale in scalability:
- Granularity: LLMs leverage hundred or thousand dimensional vectors; we relied on only hundreds of one-hot features.
- Generalization: Transformers parse text, audio, video—any modality. Symbolic grammars, at best, aspire to universal grammar across languages.
A Convergence of Paths

My colleague Lü Zhengdong once mapped the evolution of attention: Seq2Seq (Google Brain) → Auto-alignment (Mila) → Transformer (Google) → Pre-trained LMs → LLMs (OpenAI)...
To this, I chuckled: "You pioneers see the trajectory clearly. But for us symbolic refugees, diving into Attention is all you need felt like drinking from a firehose." Without fully understanding the historical context, the concepts overwhelmed us—until one day, it clicked: Subcat-driven parsing and self-attention are two sides of the same coin.
Symbolic methods are obsolete, yes—clunky, rigid, and modality-bound, with the only merit of full transparency of symbolic logic. Yet understanding their parallels to Transformers suddenly made LLMs feel familiar. The difference? Scale and ambition. Linguists seek cross-linguistic universals; AI aims for cross-modal universals.
Postscript: Simplifying the Transformer
The original Transformer paper (Attention is all you need) is not an easy-read at all, bogged down by encoder-decoder specifics for machine translation. Strip away the noise, and the core is simple:
1. Self-attention layers (dynamic slot-filling).
2. Feedforward networks (nonlinear transformations).
GPT’s decoder-only architecture reveals the essence: next-token prediction (NTP) is the key to general intelligence. The so-called "decoder" isn’t just about decoding or generation—it’s also analysis and understanding fused into one stream.
Closing Thoughts
Dr. Bai, Shuo once remarked:
Language processing demands a unified ‘currency’—a mechanism to reconcile syntax, semantics, pragmatics, and world knowledge. Only neural networks (imperfect as they are) managed to have achieved this, probabilistically. Attention is that currency.
He’s right. Attention isn’t just a tool—it’s the universal metric we’ve sought all along.