梁:
记得以前阅读,有人说,人在语言里玩,就像鱼在水里游,鸟在天上飞一样自然。
李:
结巴和哲学家除外。前者器官障碍,后者思想太过微妙,语言不逮。
白:
“原因被李四冷落多年的张三找到了。”
“张三被李四冷落多年的原因找到了。”
前几天抛出的句子,还没有回应。
李:
一个都不对,各有不对的缘由:
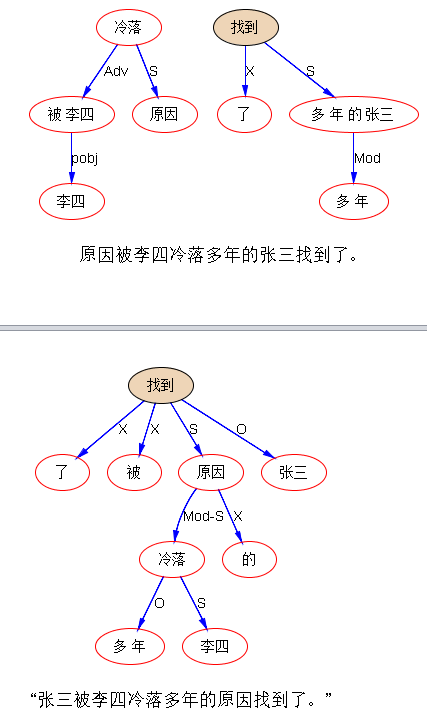
后一句不难debug,也值得 debug,前一句也许就拉倒了吧。
白:
“多年”也可以是人名
但即使是人名,也没有体现“被”
梁:
白老师,"原因被李四冷落多年的张三找到了" 是 “原因被张三找到了”,我看了半天才看懂。
李:
白老师出那种句子,我老怀疑有 hidden agenda,就是误导大众,坐收渔利。
那样的毛刺刺的句子应该从测试集刻意排除出去的。否则积累效应,可能留下后患。
白:
模型对头,都是顺手的事情
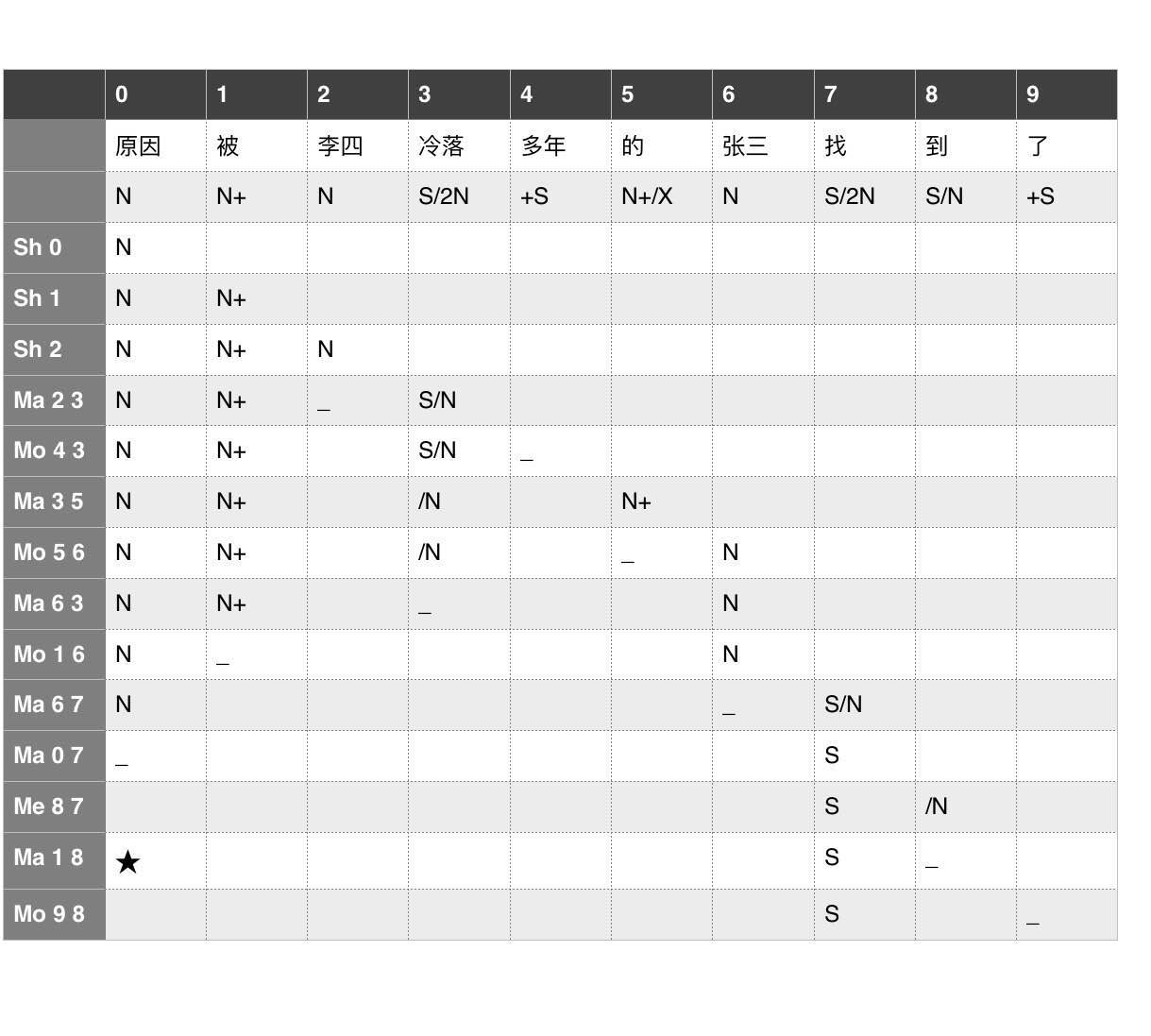
李:
那类句子最多算毛毛虫的毛刺。不仅灰色,而且罕见。strech 的不仅仅是系统的弹性限度,也是人类表达和理解的限度。
李:
这大概算 debugged 了吧:
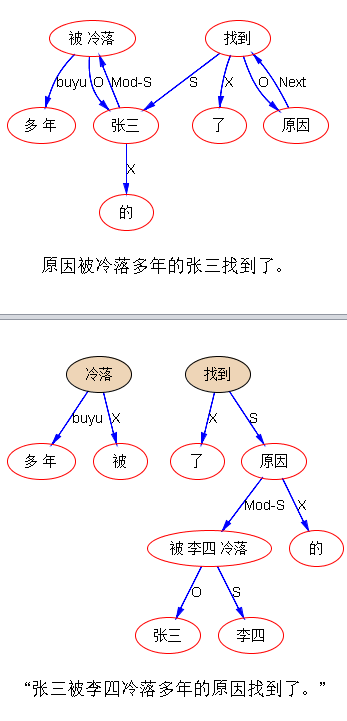
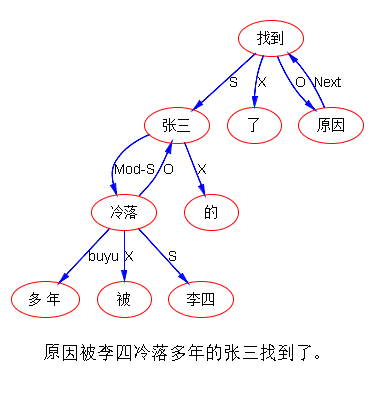
顺带把毛刺也抹平了。
白:
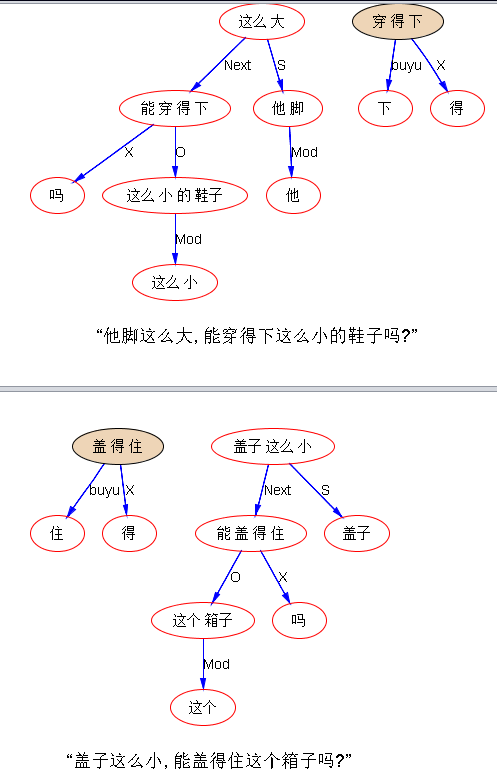
“他脚这么大,能穿得下这么小的鞋子吗?”
“盖子这么小,能盖得住这个箱子吗?”
李:
白:
做理解,原则上不需要考虑排斥性;做生成,最保险的方法就是问大数据。实际上,文学家的功底往往在于,既和大数据构成显著差异,又和大数据训练出来的神经网络不冲突。就是“人人心中有,人人笔下无”。就是说,假如“大数据中的裸出现”是初一,“基于大数据的推荐”是十五,文学家就是典型的“躲得过初一,躲不过十五”。
躲过十五,就是前卫作家了。
李:
理解和生成 我的理解是:理解单位之间是有区别性特征的。不需要克斤克锚地给一个语言现象画圈 不需要画得恰如其分。只要在需要区分的现象之间划线(大多可以模型成非常多的种种 classification 的问题)。因此 确定标配很重要,因为标配是娄底的 本身不需要条件 是 free ride 的大路货。也因此 数据驱动是开发的正道,因为在非标配的现象之间划线 没有数据 没法确定一个中庸的全局最优的边界。也因此 没有一成不变的系统 系统总是随着数据逐步逼近。
白:
这就是毛毛虫。
句法解决毛毛虫的“包络”,大数据解决毛毛虫的细节。
李:
所以一个适合 debug 的模块化而且不太纠缠(譬如 弯不过三)的系统架构,极端重要。
生成不同。生成可以回避灰色地带 回避鸡零狗碎。如果一个思想有n个表达,其中m是规范清晰的,没必要去管 n-m。 在 m 中排序选优就够烦了 根本不用淌混水。一般来说 生成比解析难度低一个量级。以前的mt系统,生成的代码量比 parsing 的代码量,小太多了。分析完 目标语词汇代入以后,拼拼凑凑也生成了不赖的译文,特别是中文是目标语的时候。由于中文无形态 加上表达上的裸奔性灵活性,生成与分析完全不成比例。如今大数据了,nmt 生成根据数据决定,就显得更顺畅了。鸡零狗碎的那些表达,分析要对付的长尾,到了生成,根本浮不上水面。
白:
鸡零狗碎在理解可以中粗线条应对,在正儿八经的生成中可以粗线条绕行。只有在刻意求变的文学创作尝试中才会触碰到毛毛虫真正的毛刺的微妙所在。
朱德熙先生有一次跟我们讲,他的小孙女偶然说出一句“花灭了”,被他听到,顿感特有诗意。虽然当时说者处在对语言还未熟练掌握的阶段。这就在毛刺的微妙部位了。
消岐、纠(容)错、修辞三者的关系很有文章可做。更何况有一种修辞就叫将错就错。话说,有些组合,比如“烧脑”,不会是早就静静地等在那里供大家飙新词的,中间一定经历了若干铺垫,使得“推荐”已经到位了,但是语言实践还差临门一脚的状态。谁能破译这个推荐的密码,谁就有了创造新词的主动权。机器写作如能成功创造流通度很高的新词,才算真正的“写作”。目前只能算“套路”。在歧义资源没有用尽之前,修辞和纠错浮不上水面。在语用环境许可范围内,修辞资源没有用尽之前,纠错浮不上水面。如果语用环境排斥修辞或者修辞资源用尽时,才能引入纠错。纠错用早了,会让用户觉得系统“自作多情”。
李:
比较明显和容易的是词法纠错 对于形态语言 这个功能有助益
另一个有助益的是 习惯用法和搭配的纠错
这些都是很实用的。
白:
词法纠错是浅层技术就可以解决的。
记得一个有意思的案例。我输入“南摩”(“南京摩托罗拉”的简称),百度偏要把很多“男模”的搜索结果推给我。再不济,来自上海本地的搜索对“南模”(“南洋模范中学”的简称)也应该偏向程度更高吧?
鲁迅用搭配习语的纠错得气死:“屠戮妇婴的___”
李:
如今的纠错已经很友好了 都是交互式 而且一点儿也不 intrusive ,全自动纠错基本没有人买账。半年前装了英语的 Grammarly ,很实惠。虽然用的时候总在想,这玩意儿我要是有时间做,肯定做得更好更贴心。中文的 Grammarly 这样成熟的对等产品,还没见到,将来应该是个巨大的市场。虽然由于中文的毛毛虫更难缠,文法更弹性,纠错难度大很多,但是只要有 resources,这个工作是有把握做好的,只是有很多很多细活要磨。不知道 Grammarly 目前的盈利模式到我大唐可以不可以维持,来 justify investments。当然,帮助人写作,像 Grammarly 那样的 plugin 装了,可以随时随地,无处不在,做得好的话,这是惠及几亿人特别是几千万学生的功德无量的事儿,不仅仅看钱。我会关注这个领域的机会,最不抵,也可以退休以后做。
【相关】