白:
“他蔬菜要用清水泡过的才敢吃。”
这里面,“泡”的逻辑主语是不是“他”?保险策略:不做定论,悬在那里。激进策略:是,如有必要,拓展对“逻辑主语”的解释。“他”主导了“泡”的启动或者“泡过”的选择,即便不是亲手“泡”,也算是逻辑主语了。落地时可以有个开关,决定“算是”的逻辑主语是否映射为真实的施事或当事语义角色。个人认为激进策略也是可行的。
董:
我的语感是“他”是topic。说的是他这个人。而不是一个行为动作的事件。
白:
“他衣服总是穿得笔挺。”
“他衣服总是要穿得笔挺才敢出门。”
里面的“他”也不和“穿”挂钩吗?
这里的“穿”和那里的“泡”有何不同?
李:
转了弯的逻辑主谓
白:
董老师框架下要直接确定语义角色,我和伟哥是分阶段的。
李:
解析的目的何在?
能想到的好处是可以提供更多的案例 帮助挖掘本体知识。对于语句的语义 其实没啥意义。语句要表达的语义 大多不绕大弯。这也是为什么非谓语动词 常常有坑没萝卜,或者即便有萝卜 填坑不填坑无关宏旨。事实上即便填上了,也大多不是事实,不是发生的事儿的语言表达,而只是本体的潜在逻辑关系的语义相谐的一种体现,此所谓“非谓语”。
白:
绑上了放掉很容易。放掉了再绑上有点返工的感觉。在没有竞争候选的情况下,建议绑上。这是依据封闭世界假设。如此填上的萝卜,如果语境中有其他活跃萝卜,可以override。
李:
顺手的话 当然绑上。
白:
把link标记为“可覆盖”,就可以兼得。
李:
如果知道不十分确定,绑的时候做个标记,说这是个 candidate 不是绝对的。
白:
就是这样:soft hypothesis,遇到更hard的candidate,立马让贤。
“他衣服要烫得笔挺才肯穿出门。”
fallible reasoning,“僵尸萝卜”和“鲜活萝卜”结为兄弟
李:
这句子很绝。各种坑。可以列数一下
(1)possessive:他-衣服
(2)aux-V: 要-烫
(3)动宾:烫-衣服
(4)主谓:衣服-笔挺
(5)计划类V带动词宾语(也可以看成是 aux-V):肯-穿
(6)candidate 主谓:他-烫(衣服)
(7)主谓:他-肯穿
(8)主谓:他-出(门)
(9)动宾:出-门
(10)动宾:(肯)穿-衣服
(11)述补:穿-出(门)
还漏掉啥填坑关系?总之,短短一句,各种纠缠。
最后这个【述补】好像随机性强一些,预示性弱,就好比 【得字结构】 的补语:
“烫-得(笔挺)”,它们更像 adjuncts 不像 args。
白:
parser都要做,补语不是填坑,是坑共享萝卜,是动态确定的
李:
不需要词典subcat驱动,而是一般性规则。
白:
不是词典化的。坑共享萝卜的另一个说法就是坑的合并
李:
好,parse parse:
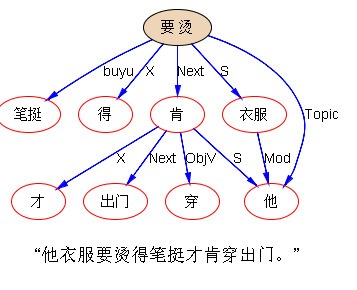
做到一半了没有?论句法,约莫八成;论全体逻辑语义,也就做了一半吧。
今儿较真一次,列数一下,看到底做了几层关系出来:
(1)Mod (possessive): 他-衣服
(2)句法主谓(其实是逻辑动宾:算是做了一半吧):要烫-衣服
(3)aux-V(表现在 vg chunking 里了): 要-烫
(4)大主语,又名 Topic(其实是逻辑主谓,也算做了一半吧):他-要烫
(5)主谓:他-肯
(6)V带动词宾语:肯-穿
(7)Next 耍了个流氓(算是做了一小半,至少直接联系是搭上了):肯-出门
(8)补语:要烫-笔挺
白:
很牛了
李:
自评: 是八成熟的 parser 吧,差强人意。偶尔露峥嵘。
关键是,这句没做任何微调,所见即所得。隐式的逻辑语义,譬如 “衣服-笔挺” 就没顾上了。隐式逻辑语义目前在语义模块只是做了个样子,没细究。
白:
我说的僵尸萝卜和鲜活萝卜,就是分别指“穿”和“出门”。
李:
句法细化为逻辑语义,也没做全。譬如,流氓 Topic 和 Next 还没教化。
白:
坑者有其萝卜,是NLPer的共同理想,就像耕者有其田一样
李:
哈。
为顺口,可以提这个口号:坑者有其苗。 跟植树造林似的。一个坑一棵苗,终成句法森林。双音语素 “萝卜” 不知怎么个来历 居然是黑匣子 无法缩略为单音节。还不如 “蝴蝶”, “蝴蝶” 略为 “蝶” 没啥问题。
【v者有其n】,这种成语句式 要求 v 和 n 都是单音节才好:
耕者有其田。
劳者有其工。
行者有其车。
食者有其鱼。
学者有其书。
棋者有其go (不是 alpha go)
nlp者有其tree
坑者有其萝卜??
赌者有其麻将??
“麻将” 也是双音节黑匣子 不好。牌九呢,也是双音语素,但似乎可缩略为 “牌”:
赌者有其牌
共产大同了 哈。
白:
“一切不拿自己当大数据入口的端设备都是耍流氓。”

董:
AI,也是智者千虑必有一失。
白:
拿……当……,句式没搞定。把“当”翻译成“when”,后面的都失去准星了。
白:
“机器人送快递还有多远?”
怎么知道这里的“远”实际指的是时间而不是空间?
宋:
时间空间常混淆。
梁:
时空一体
李:
词汇总是有歧义,有不歧义的。
“机器人送快递还有多久?”
多久 无歧义; 多远,有歧义,但标配是空间。结构也是如此,有歧义的,有不歧义的。形态丰富的语言,结构起来,就较少歧义。汉语就显得到处都是歧义。所以那些争论语言优劣的口水仗,缺少的是一个双方公认的测量标准。常常鸡同鸭讲。如果从较少歧义,以显性形式为主要手段来避免歧义这个角度看,汉语是劣质的,这个应该没有多少疑问。但是,歧义也好不歧义也好,现存语言都达到了人类交流的工具目的。不过是,歧义多的语言,人类在交流中下意识利用了常识或领域知识的帮助而已,而这种下意识,对人类一般不构成负担。既然知识在语言理解中的引入不够成负担,那么比较优劣当然还可以有其他的标准。譬如语言表达的灵活性、丰富性、微妙性,甚至模糊性。从这些角度考量,可以 argue 说汉语是世界上最牛逼的语言。
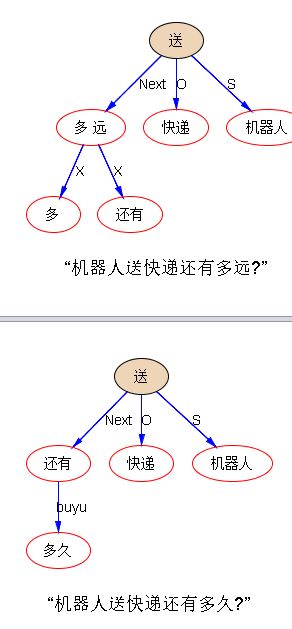
词汇的歧义(wsd)属于 hidden ambiguity,通常不影响结构分析。wsd 真要解决的话,绝大多数都可以在句法后的语义模块或语义落地模块去做。
wsd 和 hidden 歧义 通过上下文消歧 可以利用句法结构的帮助 也可以不用。但既然绝大多数这类歧义都可以留到句法后进行 不利用白不利用 两条腿走路总是更踏实。其所以wsd 研究 利用结构不为多数 不是因为大家不愿意两条腿走路 而是因为多数研究者缺乏得心应手的 parser 的支持 我以为。另一个原因是为模型的纯粹。两条腿一起来,在学习模型中,等于增加了另一维度的 heterogeneous 的 evidence,难缠。
从休眠唤醒的角度看 wsd 的多数都休眠了 常常也不用唤醒 如果落地语义无需聚焦到那里的话。到了需要唤醒的情形 譬如某个应用需要解读 多远 可不可能是说时间的话 结构条件加语义或常识就可以出场了。
“机器人 - 送外递” 这个主谓关系的行为 是一个热炒的话题 现实中很多家在尝试 但还没有成熟。这个知识介入了,才好确定 “多远” 是指向时间的。可这个知识如何搜集、表达和恰到好处地代入,目前看来还有不少挑战。
梁:
汉语比英语更高层次,你更简洁。
李:
简洁的另一说法就是裸奔。
本来穿衣主要不是避寒 而是为了体面,为了百分之五不到的避寒需求 每天都要穿得笔挺 的确显得麻烦。譬如 欧洲语言的一致关系在形态上的表现,主谓一致、形容词与头名词的一致(agreement),性数格人称等形态,看着就眼晕。 这些一致的形式有如西装革履,百分之九十五的场景就是摆设,因为没有穿戴它们 语义的相谐也不会让我们产生误解。但的确有不到百分之五的场景 就好比坏天气来了一样 没有穿戴 就会冻坏;没有一致关系 理解就发生困难。 汉语的简洁和裸奔,是以牺牲百分之五的理解畅达性作为代价的。这就是为什么汉语不如欧洲语言严谨,突出表现在写合同和法律文书的场景。欧洲语言之间 严谨性也有不同 大致都可以用穿衣的繁琐程度来度量。国人能省就省 很多小词(功能词)说没就没了,常裸奔到无语。
梁:
Okay, 更裸奔更放任自己,更让 Wei哥难受。
詹:
我常听到这样的说法,说英语的parsing都百分之九十多了,汉语差十个百分点云云。如果方法相同,分析结果总是差着这么多,是不是可以推测,汉语的模糊度就比英语高着十个百分点呢(相当于试题难度高了十个百分点)?
白:
连parse结果长什么样都糊涂呢,说什么多少个百分点?
李:
那天在linkedin上 有人建议:你不是parsing牛吗 打败谷歌 为什么不去用标准集做大规模测试对比?我说 你要说服CEO给我资源 我不妨一做。 往标准集上靠 工作量不小。本来那集就走歪了,非得把走正的 往歪去靠 。
宋:
不止是时空混淆,其他度量空间也有问题:“机票从7折变成8折”,折扣是升了还是降了?“人民币汇率从7.0升到6.0”,居然是升。纽约时间比北京时间早13个小时还是晚13个小时?
李:
宋老师对语言 眼真毒。
回@梁 汉语裸奔对我不是难受 而是福气。太好受了 人皆可做 我如何寻找存在感呢?语言不幸语言学家幸啊。
宋:
@wei 不是我眼毒,真的是说不清楚。涉及到出国的事情,解释两地时间差别,只能具体说:北京现在是25号凌晨1点,纽约是24号中午12点。各位老师,你们如何表达这个关系?也许可以这样说:北京时间减去13个小时是纽约时间。反正不能说早晚。
梁:
真是好问题,北京和纽约时差13个小时。我有时跟朋友说,"北京在纽约前13个小时。"我真不知道怎么说。
李:
自然语言会有些莫名其妙的表达 gap 存在的。譬如 汉语是 第几 和 老几 ,在英语就没有简明的对等物。理论上 不就是序数词的wh疑问式吗?应该是 *how many-th
但就是没有。遇到这类翻译 英文总是转弯抹角:
What is your place in blah blah 这类
梁:
不可翻译,只能解释的情形挺多的。
董:
什么测试集、标准集,什么召回、精确,还没玩够呀?汉语分词现在似乎没人玩了?那个正确率是怎么算的? 语言不是可以这么玩的。看看这个分词:中国力避朝鲜遭到致命打击。
百度翻译:China in stead of North Korea was a fatal blow.
Google翻译:China's efforts to avoid North Korea have been fatal blows.
对于这个句子,这个分词的错误率,就是100%。
汉语什么是“词”,词频统计能像英语一样吗?还要计算分词的正确率,还要测试,比赛,如何能靠谱?老外玩他们的语言,我们不一定要跟着玩。你玩扑克,我推牌九。
李:
如果没有标准集的话 可能一多半玩parsing的专家就抓瞎了。其中看不起或看不懂语言学的 不为少数。带标数据是他们的命根子,至于这个“标”合适不合适,靠谱吗,有多少用,他们不管。雾里看花,只要有个花的模样,就可以绘画比赛了。就是如此。
董:
前些日子,机译群在聊,说今年的ACL,是深度学习的一统天下。我想起了20年前,如今统计似乎已经风光不再了。30年河东,用不了30年就河西了。
张:
坚持原则的勇气是智慧的全部就是崇拜中
【相关】