越来越喜欢语音交互 这两天玩 Siri,Google Assistant,感觉还是搜索公司做语音交互更有前景。
为什么?因为搜索公司的知识源积累雄厚,不是其他 players 可比(不知道百度是不是以自己的积累优势 推出啥 assistant)。这是问题的一面,搜索公司做交互从回答开放问题方面,有天然优势。问题的另一面是,从问题解析角度看,搜索公司传统的优势不再。这给社交媒体公司和NLP创业公司留下了机会。以前做文本NLP,虽然可以 argue NLP 赋能的SVO搜索,可以大大提高关键词搜索的精准,但总体上感觉NLP想进入搜索,是针插不进的。
白老师说:这是商业模式问题。关键词作为标的,太成熟。
商业模式之外,还有个重要原因。很多年来,受众都被搜索公司潜移默化了,通过query log 可知,搜索框里面的 queries 绝大多数不是“人话”,就是几个关键词,而且搜索的人,越来越不管语言的词序与小词,因为经验教训都是词序和小词没用。这就使得NLP失去了合适的对象,优势发挥不出来。这边厢 关键词技术以鲁棒和长尾见长,NLP 真地是难以实现价值。可是,语音交互时代不同了,人开始越来越多学会直接跟机器对话,这时候,自然语言回归“自然”,被搜索公司洗脑的坏习惯 在语音交互中难以持续。
这给了 NLP 以机会。
以前老觉得NLP做文本比较成熟,来了语音转文字,多了层损耗。可现在语音技术成熟了,这点损耗不算啥。考察现有的交互系统,卡壳的地方多出现在 NLP 而不是语音转文字方面。
看目前 Siri 的水平,相当不错了,蛮impressed,毕竟是 Siri 第一次把自然语言对话推送到千千万万客户的手中,虽然有很多噱头,很多人拿它当玩具,毕竟有终端客户的大面积使用和反馈的积累。尽管如此,后出来的 Google Assistant 却感觉只在其上不在其下,由于搜索统治天下20年的雄厚积累,开放类知识问答更是强项。
最近测试 Google Assistant 的笔记如下。可以说,道路是曲折的,前途是光明的。
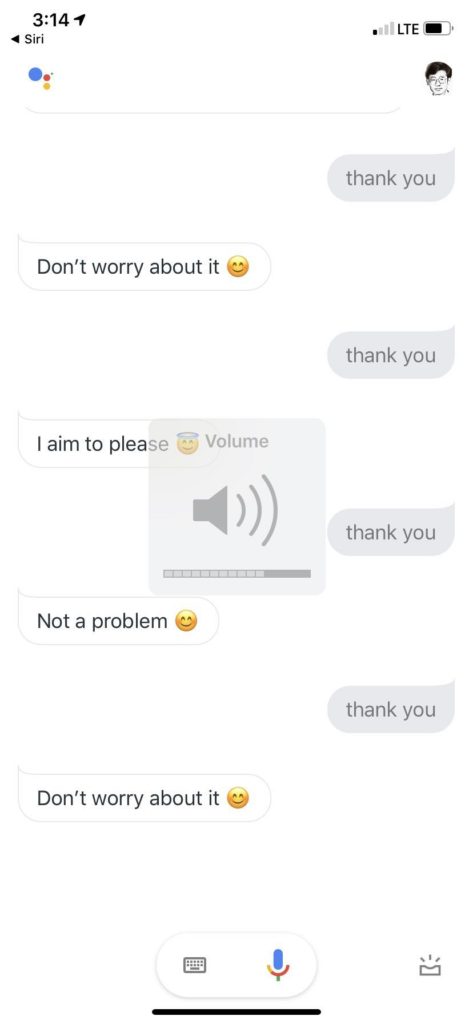
对于相同的刺激 回答不同 感觉是随机在同义词话术中挑选。
哈 nlp 卡壳了。搜索公司的backoff法宝就是搜索,卡壳了 就改成搜索结果。
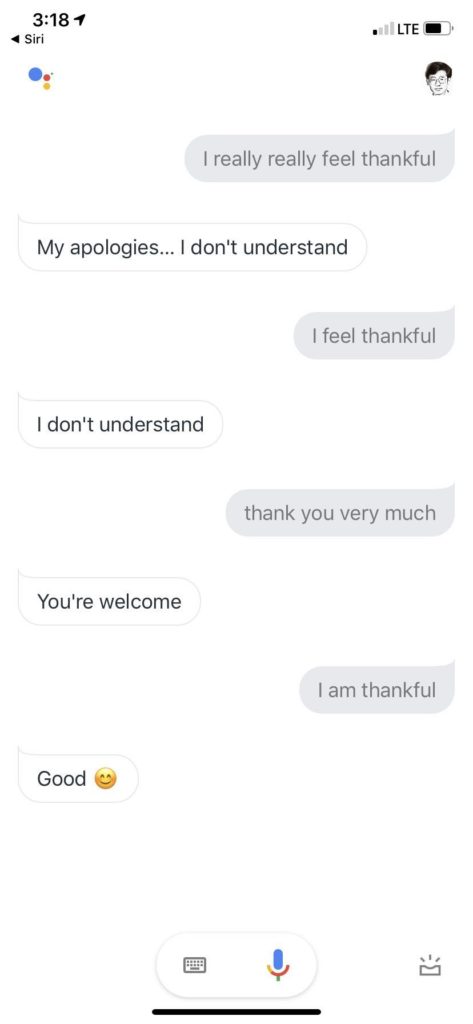
卡壳以后 退到搜索以后 搜索结果有个质量控制,可能的结果做了排序。如果觉得搜索质量不高 或找到其他痕迹发现问题不适合做搜索。就用话术装傻:My appologies ... I don't understand(对不起 先生 我没听懂)。所谓“话术”,人工智能历史上称为“巧妙的欺骗”(artful deception,见《Church:钟摆摆得太远》)。这种欺骗是实用系统的永不过时的法宝之一。
thankful 的表述今天没听懂 但迟早会通过 bug 积累反馈过程 被听懂的 所以只要系统持续维护 机器对于日常会话 就会越来越应答自如 这一点没有疑问。语音交互虽然不像AI泡沫期望的那样立马改变我们的生活 但人机语音交互越来越渗透到我们和我们下一代的生活中 是一个自然而然 不可逆转的趋势。
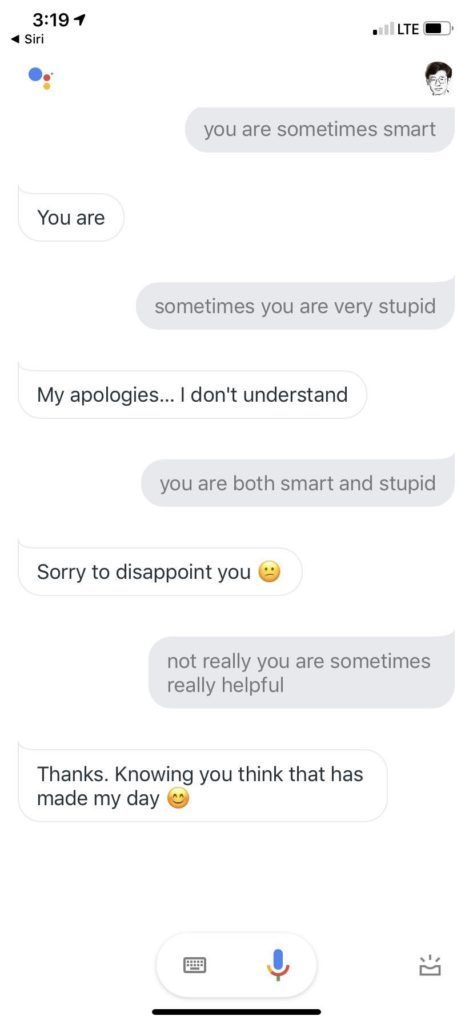
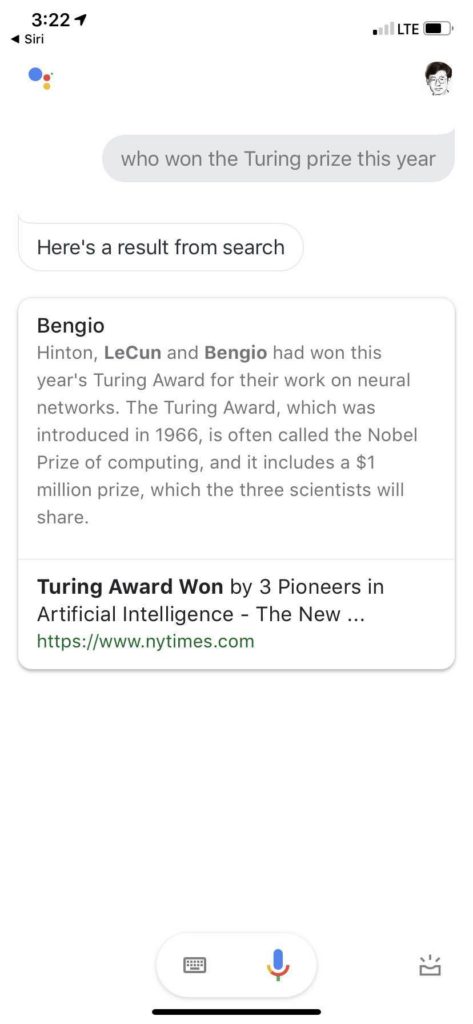
知识问答 特别是开放类新闻查询 搜索的拿手好戏 这种搜索回应 不是退而求其次的后备应答 而是首选的答案。
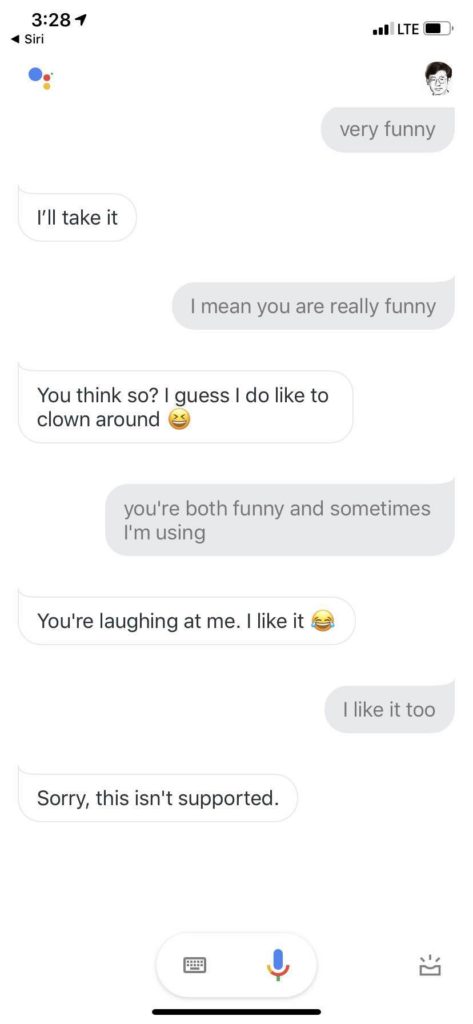
所有话术都那么具有可爱的欺骗性,until 最后一句,莫名其妙回应说 this isn't supported.
(顺便一提,上面终于发现一个语音转写错误,我跟 Google Assistant 说的是,you are both funny and sometimes amusing. 她听成了 and sometimes I'm using. 从纯粹语音相似角度,也算是个 reasonable mistake,从句法角度,就完全不对劲了,both A and B 要求 A 和 B 是同类的词啊。大家知道,语音转写目前是没有什么语言学句法知识的,为了这点改错,加上语言学也不见得合算。关键是,其实也没人知道如何在语音深度神经里面融入语言学知识。这个让深度学习与知识系统耦合的话题且放下,以后有机会再论。)
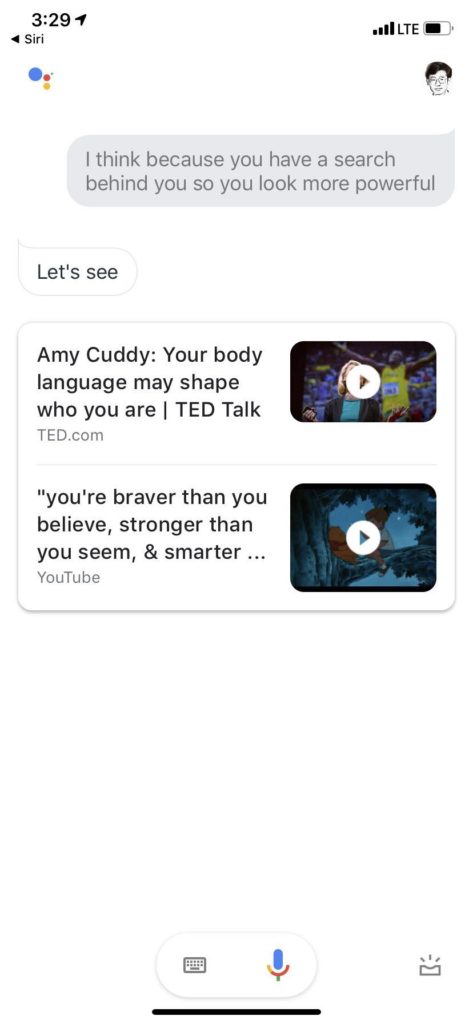
这就是胡乱来了。测试下来 发现句子一长 系统就犯糊涂。10个词以上就进入深水区,常常驴唇不对马嘴。
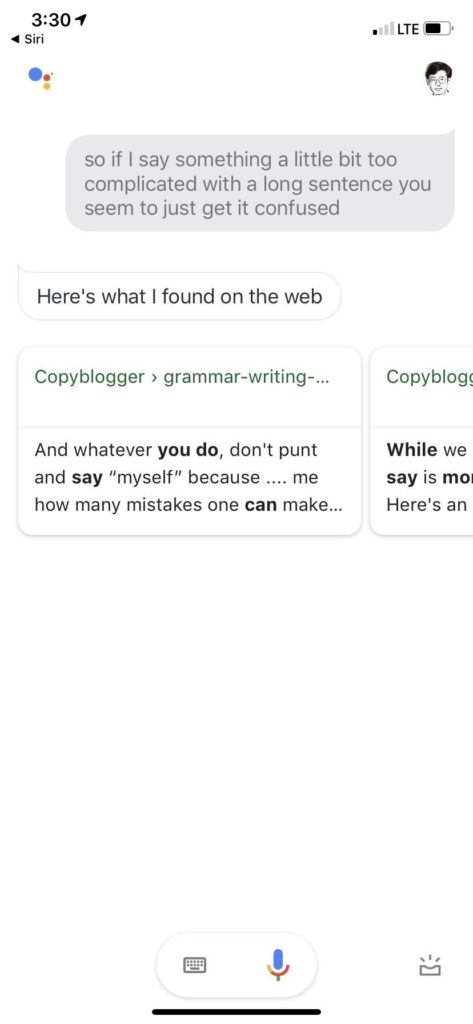
可是 即便后备到搜索 也不至于如此不堪啊 一点 smoothing 都感觉不到 整个一个白痴。再一想,估计是我原话中提到 long sentence 它给我找来一个讲 grammar writing 的博客。
所谓语音门户之战,看样子是个拉锯战,可能是持久战。呈两极三角态势。一极是搜索巨头,谷歌、百度,手里有海量知识和答案。另一极是社媒或零售巨头,离用户近,腾讯、脸书、苹果、亚马逊等。他们可以把端口部署到千家万户去。这两极各有优势,可以长期对抗下去。三角方面,似乎还有一个角,是给NLP技术或创业公司留着的。谁知道呢,也许在用户和知识源都不具备优势的时候,技术型公司会以NLP的亮丽表现异军突起,帮助或联合其中一极成就霸业,也未可知。
haha LOL,简单即王道。
王道是要有出口。上面的乱套是系统设计的毛病,不是AI自身的问题。
又看了一遍上列“简单为王”的反AI宣传片,又笑了半天。前后两个问题,其实是两种解决方案:前一个是产品层面的。产品设计需要有个 accessibility 的机制。当主人因故说不出话或说不清话的时候,应该有个类似为残疾人准备的后备机制。这方面苹果 iPhone 做得很好,它的 accessibility features 非常丰富 考虑到很多场景和小众残疾或不残疾的另类用户。第二个问题的解决方案是技术性的,机器人应该识别主人的声音,默认只听主人的指令。从产品层面看,起码应该是个可以 configure 的选项,不应该听到声音就去执行。
总结一下自动解析所依据的语言形式是什么。主要是三种:
1. 语序
2. 直接量(尤其是小词和形态)
3. 特征
前两种叫显性形式,特征是隐性形式。语言形式这么一分,自然语言一下子就豁然开朗了。管它什么语言,不外乎是这三种形式的交错使用,比例搭配和倚重不同而已。所谓文法,也不外是用这三种形式对语言现象及其背后的结构做描述而已。
摘自《自然语言答问》(to be published)
被搜索巨头20年潜意识引导/洗脑,人上网搜索的 query,第一不讲究语序,第二扔掉了小词(知道小词是 stop words 基本上被关键词索引忽略 有它无它不 make difference)。这就使得 query 其实不是自然语言,不过是一小袋词的堆积。作为显性语言形式,小词和词序很重要,因为自然语言很大程度上依赖语序和小词这样的语言形式,来表达句法结构和逻辑语义。这么一来,query 不是自然语言技术施展的合适对象。
在不知不觉就会到来的语音交互时代,query 被语音的 question 所取代,自然语言复归“自然”,这就为NLP/NLU发挥作用,创造了条件。人会不会把上网用的 query 坏习惯带到语音交互的现场呢?考察语音交互现场,可以发现,基本上人机对话的时候,有意识背离自然语言规范的做法,是很少见的。人说话虽然并不总是特别规范,但是从学会说话的时候就开始积累的语言习惯是难以人为改变的。至少不会像 query 那样“变态”和偏离自然语言。
这是NLP的福音。
回顾一下,历史上看NLP走出实验室的落地历程,大多是遇到特殊的机遇。第一个机遇是信息抽取(IE)。在IE诞生之前,NLP面对大海一样的语言,漫无目标,是 IE 让 NLP 瞄准实际的领域需求,预定义一个狭窄的清晰定义的情报抽取范围和种类。第二个机遇是大数据,不完美的NLP技术遇到了大数据,使得信息的大量冗余弥补了引擎质量的不足。第三个机遇深度学习,仍在进行时,现在看来海量语料的预训练可以帮助模型捕捉千变万化的语言表达方式。第四个机遇就是移动时代和物联网的到来,这使得语音交互开始渗透到人类生活的方方面面,反过来促进了NLP技术充分发挥其潜力。
有意思的是,与其说搜索巨头用一个小小的搜索框“教育”或误导了用户的查询习惯,不如说是用户在不断的搜索实践中适应了关键词技术。其结果就是那不伦不类的搜索 queries 的出现和流行。既然用户会通过正向反向的结果反馈,来慢慢适应关键词搜索不懂自然语言的短板,可以预见,用户也会慢慢适应不完美的自然语言语音交互。
怎么讲?
如果同一个问题有100个问法,其中80个问法是清晰无误的,20个是有歧义的,用户会慢慢学会回避有歧义的问法,或在第一轮被误解以后,会迅速返回到更加清晰的80种问法范围来。如果这 80 种问法,机器只涵盖了 60 种比较常见的,久而久之会出现这样的情形:一方面,只要机器还在持续维护和bug fix 的反馈回路上,所涵盖的边界会慢慢扩大,从 60 往上走。另一方面,用户也会学乖,慢慢倾向于越来越多使用更加常用的,已经被反复证实的那些问法中去,回到 60 的边界内。除了恶作剧,没人存心为难自己的助手,毕竟交互的目的是为达成目标。这样来看不完美的NLP技术,面对真实世界的场景,我们是有理由乐观的。
所有的软件系统,一个最大的好处就是可以确定地说,明天更美好。除非是非良定义或设计,同时开发维护过程也是非良的操作规程,软件的质量永远是上升的,最多是爬升趋于缓慢而已。因此,今天我们取笑的交互实例,我们为机器的愚蠢所困扰的方方面面,明天后天一定会逐步改良。
唯一感到有些可惜的是,语言工程本来是一个打磨数据的过程,很多工作应该可以共享的,避免重复劳动。但实际上,这种重复劳动还在大面积进行中,而且很长时间内,也看不到资源共享的理想平台、机制和架构,虽然预训练的资源共享看上去是在这个方向上迈进了一步,但有效利用第三方的预训练资源,帮助落地到本地产品和场景,依然是一个挑战。
【相关】
《Church:钟摆摆得太远》